 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEl Volumen Louder Por Favor: Code-switching in Task-oriented Semantic Parsing
Jan 28, 2021
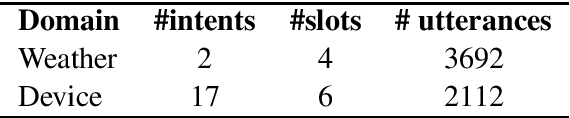
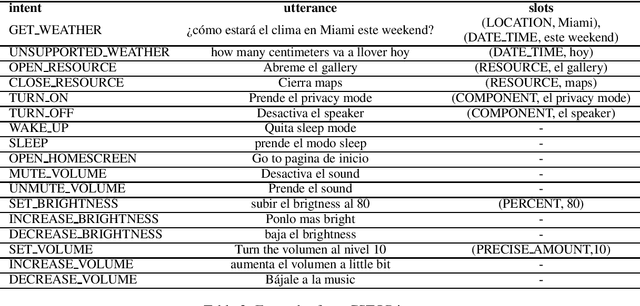
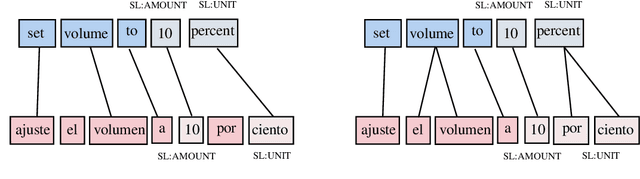
Being able to parse code-switched (CS) utterances, such as Spanish+English or Hindi+English, is essential to democratize task-oriented semantic parsing systems for certain locales. In this work, we focus on Spanglish (Spanish+English) and release a dataset, CSTOP, containing 5800 CS utterances alongside their semantic parses. We examine the CS generalizability of various Cross-lingual (XL) models and exhibit the advantage of pre-trained XL language models when data for only one language is present. As such, we focus on improving the pre-trained models for the case when only English corpus alongside either zero or a few CS training instances are available. We propose two data augmentation methods for the zero-shot and the few-shot settings: fine-tune using translate-and-align and augment using a generation model followed by match-and-filter. Combining the few-shot setting with the above improvements decreases the initial 30-point accuracy gap between the zero-shot and the full-data settings by two thirds.
Muppet: Massive Multi-task Representations with Pre-Finetuning
Jan 26, 2021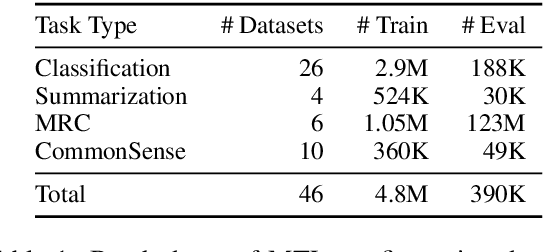
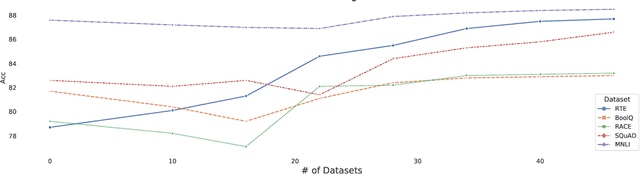
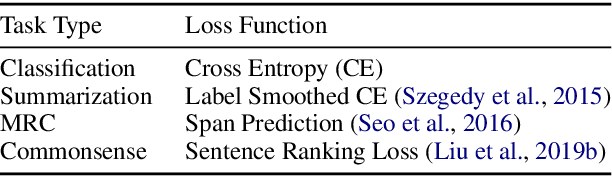
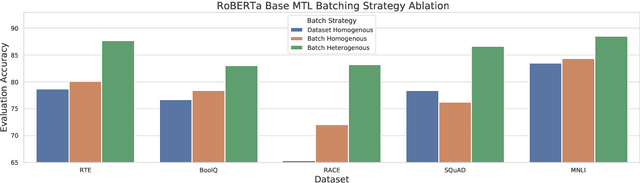
We propose pre-finetuning, an additional large-scale learning stage between language model pre-training and fine-tuning. Pre-finetuning is massively multi-task learning (around 50 datasets, over 4.8 million total labeled examples), and is designed to encourage learning of representations that generalize better to many different tasks. We show that pre-finetuning consistently improves performance for pretrained discriminators (e.g.~RoBERTa) and generation models (e.g.~BART) on a wide range of tasks (sentence prediction, commonsense reasoning, MRC, etc.), while also significantly improving sample efficiency during fine-tuning. We also show that large-scale multi-tasking is crucial; pre-finetuning can hurt performance when few tasks are used up until a critical point (usually above 15) after which performance improves linearly in the number of tasks.
NeurIPS 2020 EfficientQA Competition: Systems, Analyses and Lessons Learned
Jan 01, 2021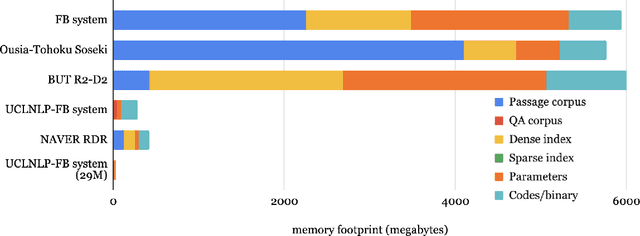
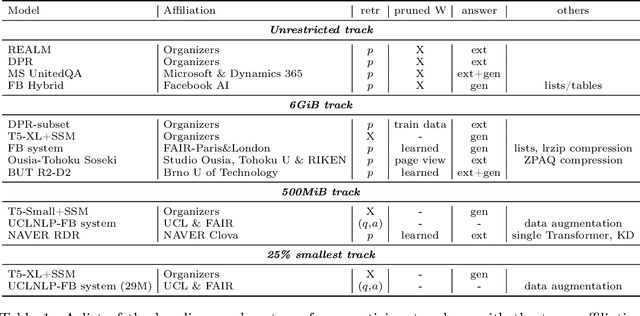
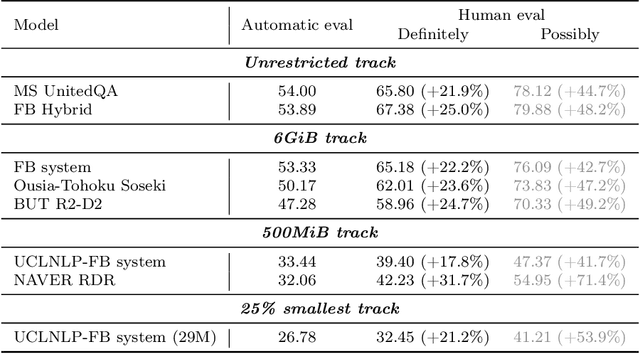
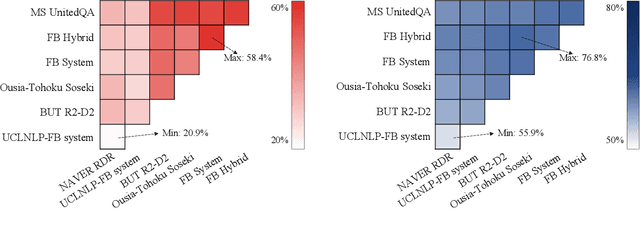
We review the EfficientQA competition from NeurIPS 2020. The competition focused on open-domain question answering (QA), where systems take natural language questions as input and return natural language answers. The aim of the competition was to build systems that can predict correct answers while also satisfying strict on-disk memory budgets. These memory budgets were designed to encourage contestants to explore the trade-off between storing large, redundant, retrieval corpora or the parameters of large learned models. In this report, we describe the motivation and organization of the competition, review the best submissions, and analyze system predictions to inform a discussion of evaluation for open-domain QA.
Unified Open-Domain Question Answering with Structured and Unstructured Knowledge
Dec 29, 2020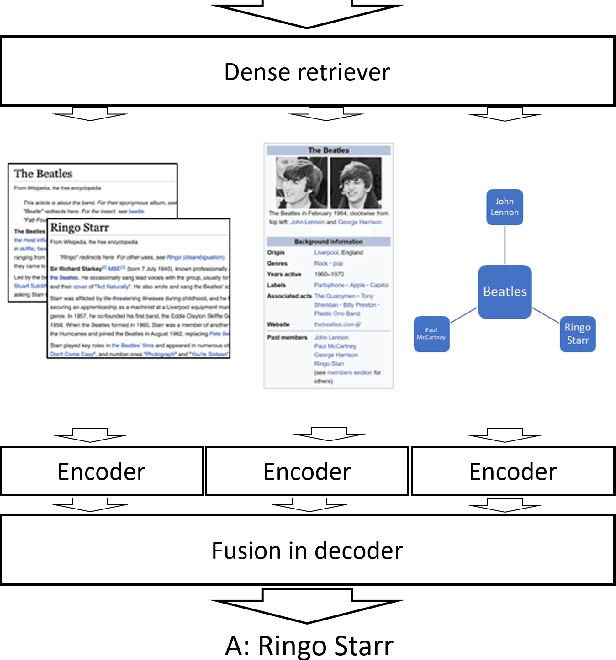

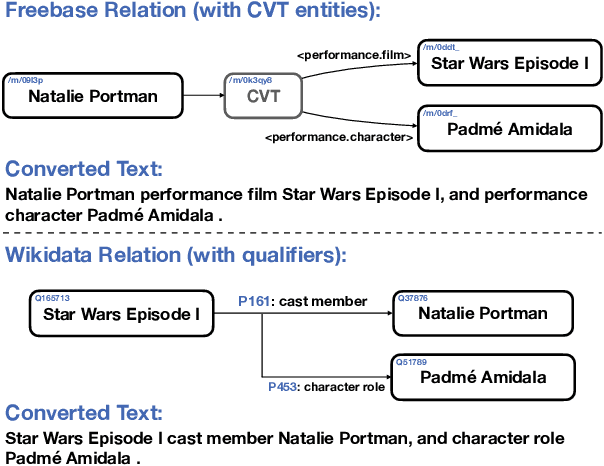
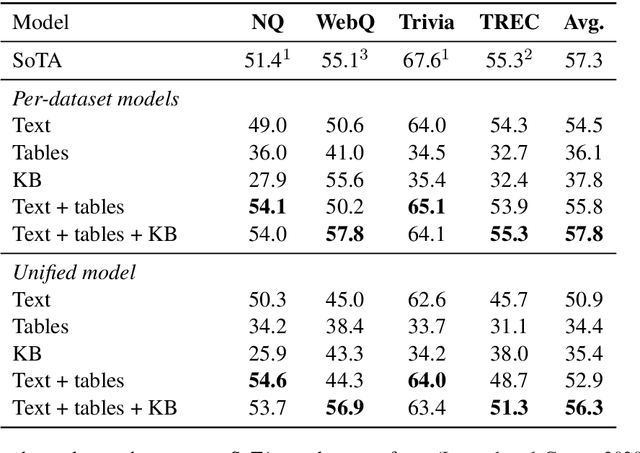
We study open-domain question answering (ODQA) with structured, unstructured and semi-structured knowledge sources, including text, tables, lists, and knowledge bases. Our approach homogenizes all sources by reducing them to text, and applies recent, powerful retriever-reader models which have so far been limited to text sources only. We show that knowledge-base QA can be greatly improved when reformulated in this way. Contrary to previous work, we find that combining sources always helps, even for datasets which target a single source by construction. As a result, our unified model produces state-of-the-art results on 3 popular ODQA benchmarks.
Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning
Dec 22, 2020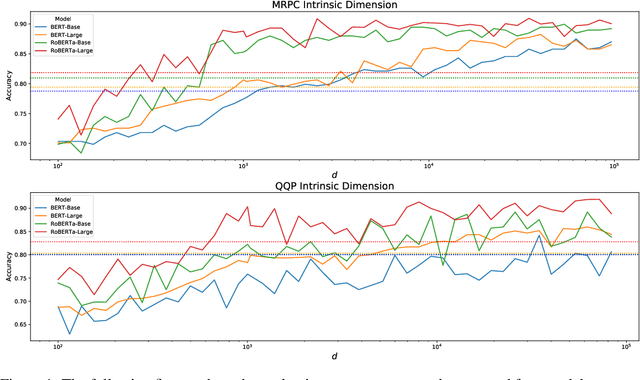
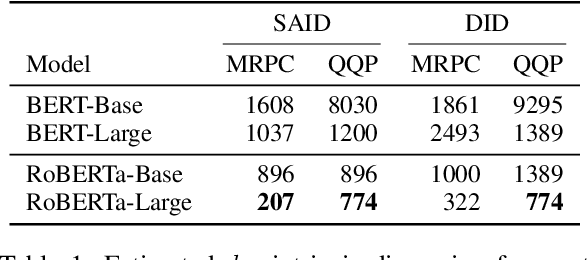
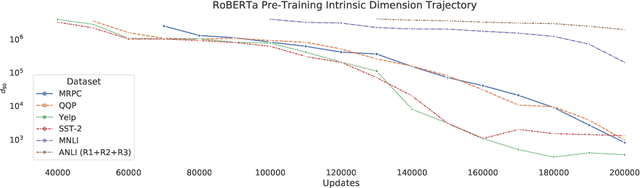
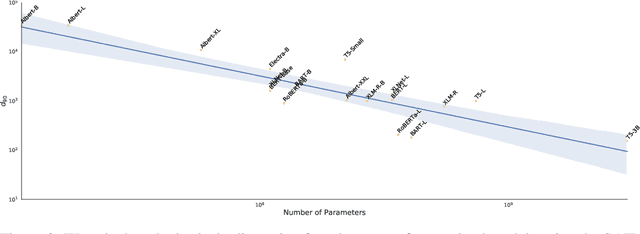
Although pretrained language models can be fine-tuned to produce state-of-the-art results for a very wide range of language understanding tasks, the dynamics of this process are not well understood, especially in the low data regime. Why can we use relatively vanilla gradient descent algorithms (e.g., without strong regularization) to tune a model with hundreds of millions of parameters on datasets with only hundreds or thousands of labeled examples? In this paper, we argue that analyzing fine-tuning through the lens of intrinsic dimension provides us with empirical and theoretical intuitions to explain this remarkable phenomenon. We empirically show that common pre-trained models have a very low intrinsic dimension; in other words, there exists a low dimension reparameterization that is as effective for fine-tuning as the full parameter space. For example, by optimizing only 200 trainable parameters randomly projected back into the full space, we can tune a RoBERTa model to achieve 90\% of the full parameter performance levels on MRPC. Furthermore, we empirically show that pre-training implicitly minimizes intrinsic dimension and, perhaps surprisingly, larger models tend to have lower intrinsic dimension after a fixed number of pre-training updates, at least in part explaining their extreme effectiveness. Lastly, we connect intrinsic dimensionality with low dimensional task representations and compression based generalization bounds to provide intrinsic-dimension-based generalization bounds that are independent of the full parameter count.
Sound Natural: Content Rephrasing in Dialog Systems
Nov 03, 2020


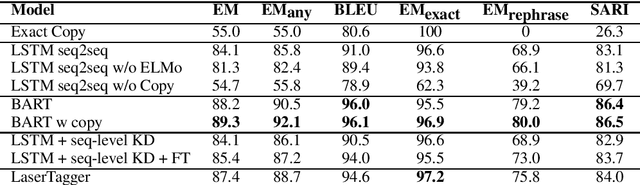
We introduce a new task of rephrasing for a more natural virtual assistant. Currently, virtual assistants work in the paradigm of intent slot tagging and the slot values are directly passed as-is to the execution engine. However, this setup fails in some scenarios such as messaging when the query given by the user needs to be changed before repeating it or sending it to another user. For example, for queries like 'ask my wife if she can pick up the kids' or 'remind me to take my pills', we need to rephrase the content to 'can you pick up the kids' and 'take your pills' In this paper, we study the problem of rephrasing with messaging as a use case and release a dataset of 3000 pairs of original query and rephrased query. We show that BART, a pre-trained transformers-based masked language model with auto-regressive decoding, is a strong baseline for the task, and show improvements by adding a copy-pointer and copy loss to it. We analyze different tradeoffs of BART-based and LSTM-based seq2seq models, and propose a distilled LSTM-based seq2seq as the best practical model.
Low-Resource Domain Adaptation for Compositional Task-Oriented Semantic Parsing
Oct 07, 2020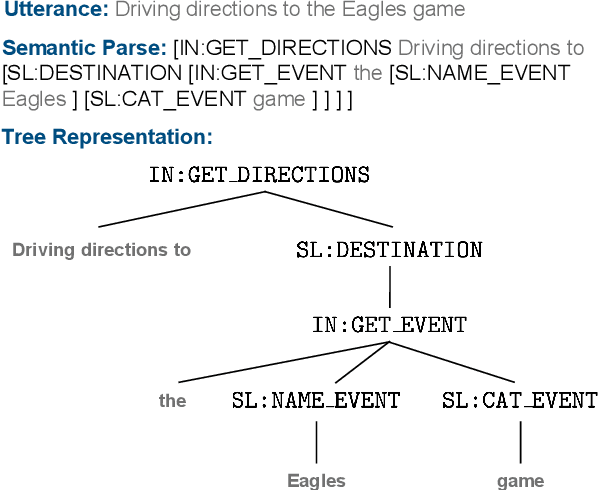
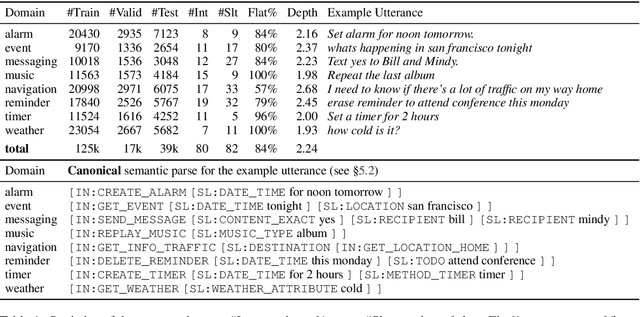
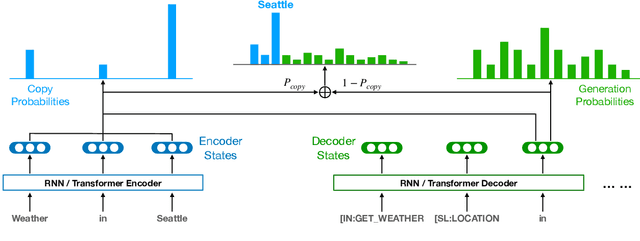
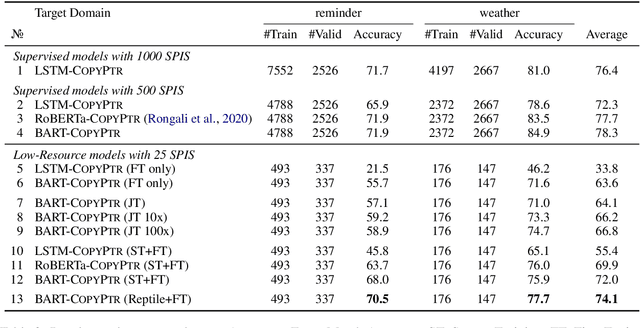
Task-oriented semantic parsing is a critical component of virtual assistants, which is responsible for understanding the user's intents (set reminder, play music, etc.). Recent advances in deep learning have enabled several approaches to successfully parse more complex queries (Gupta et al., 2018; Rongali et al.,2020), but these models require a large amount of annotated training data to parse queries on new domains (e.g. reminder, music). In this paper, we focus on adapting task-oriented semantic parsers to low-resource domains, and propose a novel method that outperforms a supervised neural model at a 10-fold data reduction. In particular, we identify two fundamental factors for low-resource domain adaptation: better representation learning and better training techniques. Our representation learning uses BART (Lewis et al., 2019) to initialize our model which outperforms encoder-only pre-trained representations used in previous work. Furthermore, we train with optimization-based meta-learning (Finn et al., 2017) to improve generalization to low-resource domains. This approach significantly outperforms all baseline methods in the experiments on a newly collected multi-domain task-oriented semantic parsing dataset (TOPv2), which we release to the public.
Conversational Semantic Parsing
Sep 28, 2020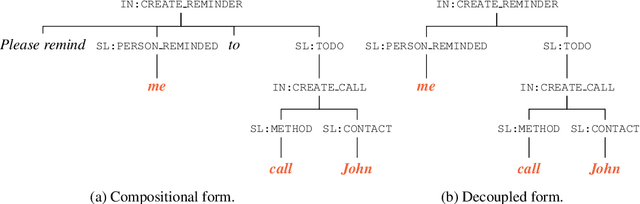
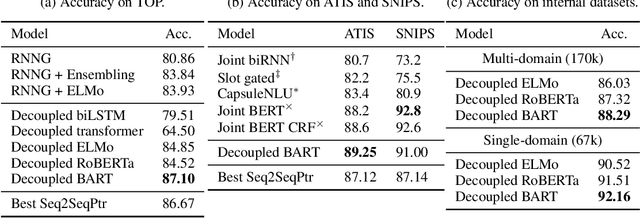
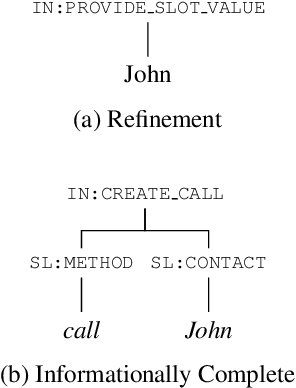
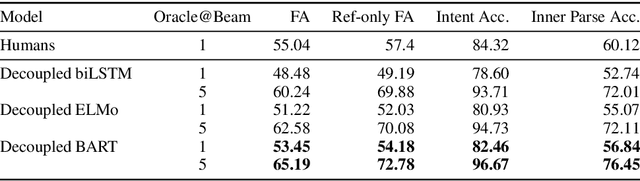
The structured representation for semantic parsing in task-oriented assistant systems is geared towards simple understanding of one-turn queries. Due to the limitations of the representation, the session-based properties such as co-reference resolution and context carryover are processed downstream in a pipelined system. In this paper, we propose a semantic representation for such task-oriented conversational systems that can represent concepts such as co-reference and context carryover, enabling comprehensive understanding of queries in a session. We release a new session-based, compositional task-oriented parsing dataset of 20k sessions consisting of 60k utterances. Unlike Dialog State Tracking Challenges, the queries in the dataset have compositional forms. We propose a new family of Seq2Seq models for the session-based parsing above, which achieve better or comparable performance to the current state-of-the-art on ATIS, SNIPS, TOP and DSTC2. Notably, we improve the best known results on DSTC2 by up to 5 points for slot-carryover.
MTOP: A Comprehensive Multilingual Task-Oriented Semantic Parsing Benchmark
Aug 21, 2020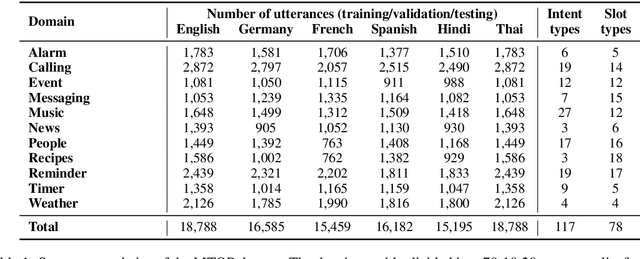
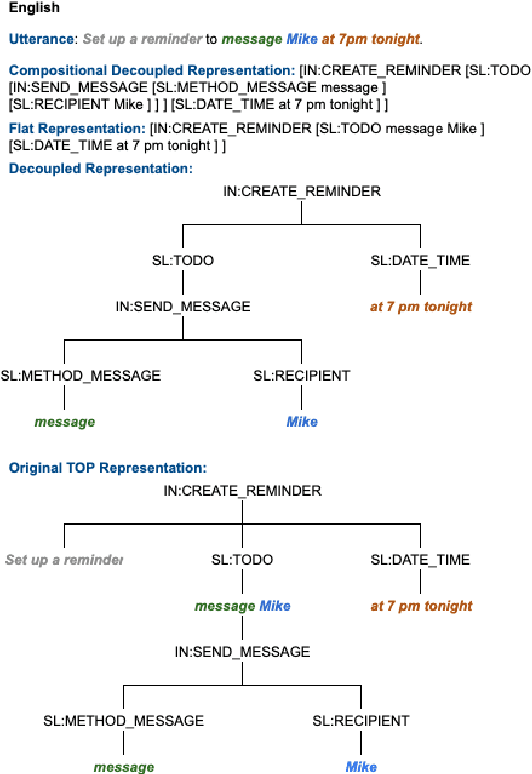
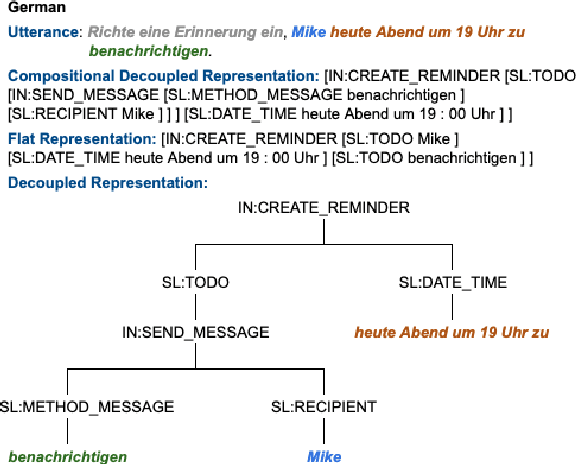
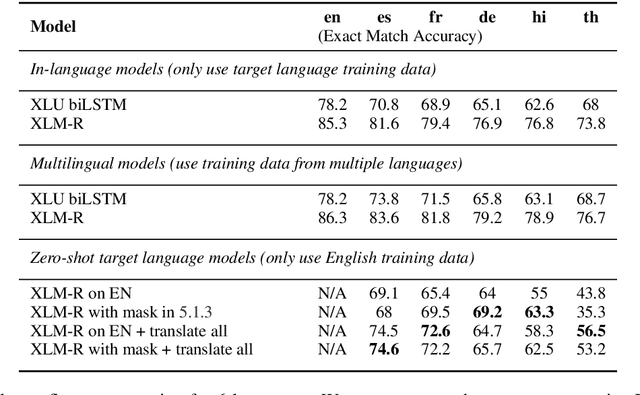
Scaling semantic parsing models for task-oriented dialog systems to new languages is often expensive and time-consuming due to the lack of available datasets. Even though few datasets are available, they suffer from many shortcomings: a) they contain few languages and small amounts of labeled data for other languages b) they are based on the simple intent and slot detection paradigm for non-compositional queries. In this paper, we present a new multilingual dataset, called MTOP, comprising of 100k annotated utterances in 6 languages across 11 domains. We use this dataset and other publicly available datasets to conduct a comprehensive benchmarking study on using various state-of-the-art multilingual pre-trained models for task-oriented semantic parsing. We achieve an average improvement of +6.3\% on Slot F1 for the two existing multilingual datasets, over best results reported in their experiments. Furthermore, we also demonstrate strong zero-shot performance using pre-trained models combined with automatic translation and alignment, and a proposed distant supervision method to reduce the noise in slot label projection.
Better Fine-Tuning by Reducing Representational Collapse
Aug 06, 2020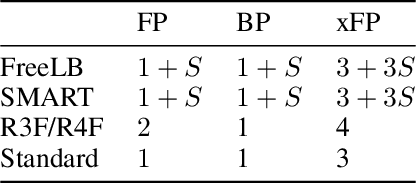
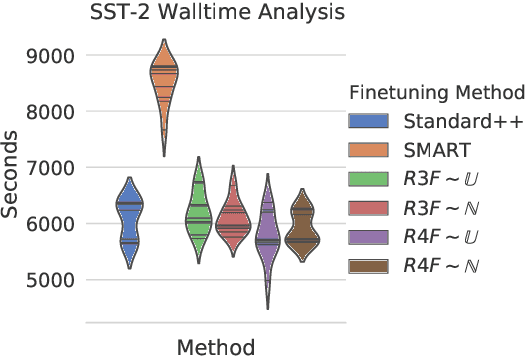
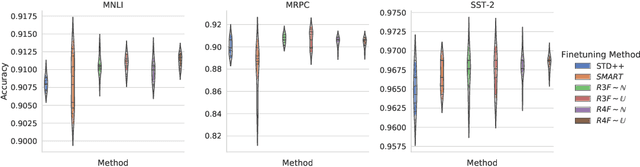
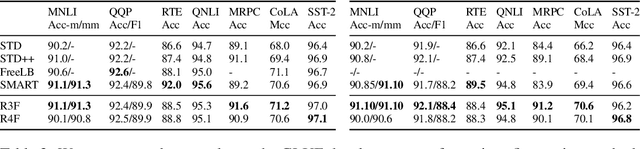
Although widely adopted, existing approaches for fine-tuning pre-trained language models have been shown to be unstable across hyper-parameter settings, motivating recent work on trust region methods. In this paper, we present a simplified and efficient method rooted in trust region theory that replaces previously used adversarial objectives with parametric noise (sampling from either a normal or uniform distribution), thereby discouraging representation change during fine-tuning when possible without hurting performance. We also introduce a new analysis to motivate the use of trust region methods more generally, by studying representational collapse; the degradation of generalizable representations from pre-trained models as they are fine-tuned for a specific end task. Extensive experiments show that our fine-tuning method matches or exceeds the performance of previous trust region methods on a range of understanding and generation tasks (including DailyMail/CNN, Gigaword, Reddit TIFU, and the GLUE benchmark), while also being much faster. We also show that it is less prone to representation collapse; the pre-trained models maintain more generalizable representations every time they are fine-tuned.