 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Self-Reconfiguration for Fault-Tolerant Control of Modular Aerial Robot Systems
Mar 12, 2025



Modular Aerial Robotic Systems (MARS) consist of multiple drone units assembled into a single, integrated rigid flying platform. With inherent redundancy, MARS can self-reconfigure into different configurations to mitigate rotor or unit failures and maintain stable flight. However, existing works on MARS self-reconfiguration often overlook the practical controllability of intermediate structures formed during the reassembly process, which limits their applicability. In this paper, we address this gap by considering the control-constrained dynamic model of MARS and proposing a robust and efficient self-reconstruction algorithm that maximizes the controllability margin at each intermediate stage. Specifically, we develop algorithms to compute optimal, controllable disassembly and assembly sequences, enabling robust self-reconfiguration. Finally, we validate our method in several challenging fault-tolerant self-reconfiguration scenarios, demonstrating significant improvements in both controllability and trajectory tracking while reducing the number of assembly steps. The videos and source code of this work are available at https://github.com/RuiHuangNUS/MARS-Reconfig/
Robust Fault-Tolerant Control and Agile Trajectory Planning for Modular Aerial Robotic Systems
Mar 12, 2025Modular Aerial Robotic Systems (MARS) consist of multiple drone units that can self-reconfigure to adapt to various mission requirements and fault conditions. However, existing fault-tolerant control methods exhibit significant oscillations during docking and separation, impacting system stability. To address this issue, we propose a novel fault-tolerant control reallocation method that adapts to arbitrary number of modular robots and their assembly formations. The algorithm redistributes the expected collective force and torque required for MARS to individual unit according to their moment arm relative to the center of MARS mass. Furthermore, We propose an agile trajectory planning method for MARS of arbitrary configurations, which is collision-avoiding and dynamically feasible. Our work represents the first comprehensive approach to enable fault-tolerant and collision avoidance flight for MARS. We validate our method through extensive simulations, demonstrating improved fault tolerance, enhanced trajectory tracking accuracy, and greater robustness in cluttered environments. The videos and source code of this work are available at https://github.com/RuiHuangNUS/MARS-FTCC/
Relightable Full-Body Gaussian Codec Avatars
Jan 24, 2025



We propose Relightable Full-Body Gaussian Codec Avatars, a new approach for modeling relightable full-body avatars with fine-grained details including face and hands. The unique challenge for relighting full-body avatars lies in the large deformations caused by body articulation and the resulting impact on appearance caused by light transport. Changes in body pose can dramatically change the orientation of body surfaces with respect to lights, resulting in both local appearance changes due to changes in local light transport functions, as well as non-local changes due to occlusion between body parts. To address this, we decompose the light transport into local and non-local effects. Local appearance changes are modeled using learnable zonal harmonics for diffuse radiance transfer. Unlike spherical harmonics, zonal harmonics are highly efficient to rotate under articulation. This allows us to learn diffuse radiance transfer in a local coordinate frame, which disentangles the local radiance transfer from the articulation of the body. To account for non-local appearance changes, we introduce a shadow network that predicts shadows given precomputed incoming irradiance on a base mesh. This facilitates the learning of non-local shadowing between the body parts. Finally, we use a deferred shading approach to model specular radiance transfer and better capture reflections and highlights such as eye glints. We demonstrate that our approach successfully models both the local and non-local light transport required for relightable full-body avatars, with a superior generalization ability under novel illumination conditions and unseen poses.
SplatFormer: Point Transformer for Robust 3D Gaussian Splatting
Nov 12, 2024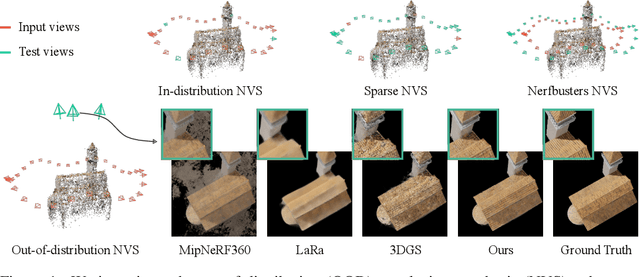
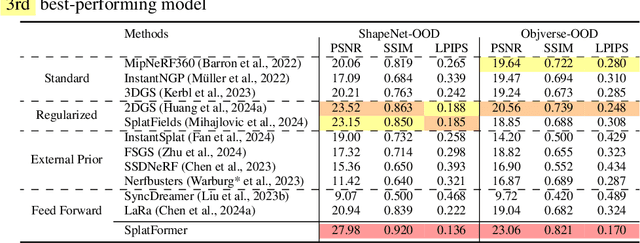
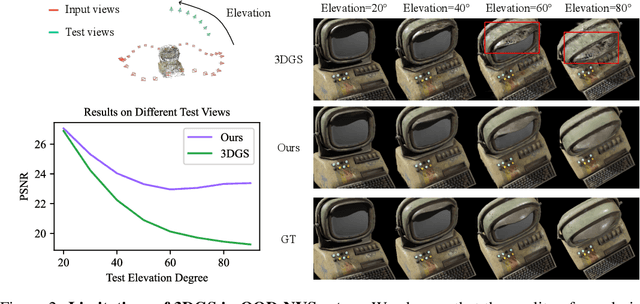
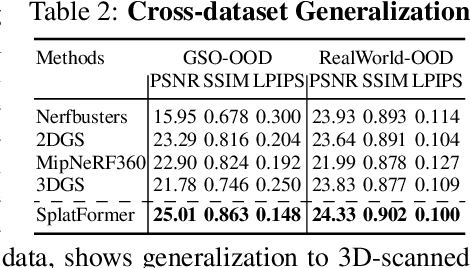
3D Gaussian Splatting (3DGS) has recently transformed photorealistic reconstruction, achieving high visual fidelity and real-time performance. However, rendering quality significantly deteriorates when test views deviate from the camera angles used during training, posing a major challenge for applications in immersive free-viewpoint rendering and navigation. In this work, we conduct a comprehensive evaluation of 3DGS and related novel view synthesis methods under out-of-distribution (OOD) test camera scenarios. By creating diverse test cases with synthetic and real-world datasets, we demonstrate that most existing methods, including those incorporating various regularization techniques and data-driven priors, struggle to generalize effectively to OOD views. To address this limitation, we introduce SplatFormer, the first point transformer model specifically designed to operate on Gaussian splats. SplatFormer takes as input an initial 3DGS set optimized under limited training views and refines it in a single forward pass, effectively removing potential artifacts in OOD test views. To our knowledge, this is the first successful application of point transformers directly on 3DGS sets, surpassing the limitations of previous multi-scene training methods, which could handle only a restricted number of input views during inference. Our model significantly improves rendering quality under extreme novel views, achieving state-of-the-art performance in these challenging scenarios and outperforming various 3DGS regularization techniques, multi-scene models tailored for sparse view synthesis, and diffusion-based frameworks.
DART: A Diffusion-Based Autoregressive Motion Model for Real-Time Text-Driven Motion Control
Oct 07, 2024



Text-conditioned human motion generation, which allows for user interaction through natural language, has become increasingly popular. Existing methods typically generate short, isolated motions based on a single input sentence. However, human motions are continuous and can extend over long periods, carrying rich semantics. Creating long, complex motions that precisely respond to streams of text descriptions, particularly in an online and real-time setting, remains a significant challenge. Furthermore, incorporating spatial constraints into text-conditioned motion generation presents additional challenges, as it requires aligning the motion semantics specified by text descriptions with geometric information, such as goal locations and 3D scene geometry. To address these limitations, we propose DART, a Diffusion-based Autoregressive motion primitive model for Real-time Text-driven motion control. Our model, DART, effectively learns a compact motion primitive space jointly conditioned on motion history and text inputs using latent diffusion models. By autoregressively generating motion primitives based on the preceding history and current text input, DART enables real-time, sequential motion generation driven by natural language descriptions. Additionally, the learned motion primitive space allows for precise spatial motion control, which we formulate either as a latent noise optimization problem or as a Markov decision process addressed through reinforcement learning. We present effective algorithms for both approaches, demonstrating our model's versatility and superior performance in various motion synthesis tasks. Experiments show our method outperforms existing baselines in motion realism, efficiency, and controllability. Video results are available on the project page: https://zkf1997.github.io/DART/.
RISE-SDF: a Relightable Information-Shared Signed Distance Field for Glossy Object Inverse Rendering
Sep 30, 2024



In this paper, we propose a novel end-to-end relightable neural inverse rendering system that achieves high-quality reconstruction of geometry and material properties, thus enabling high-quality relighting. The cornerstone of our method is a two-stage approach for learning a better factorization of scene parameters. In the first stage, we develop a reflection-aware radiance field using a neural signed distance field (SDF) as the geometry representation and deploy an MLP (multilayer perceptron) to estimate indirect illumination. In the second stage, we introduce a novel information-sharing network structure to jointly learn the radiance field and the physically based factorization of the scene. For the physically based factorization, to reduce the noise caused by Monte Carlo sampling, we apply a split-sum approximation with a simplified Disney BRDF and cube mipmap as the environment light representation. In the relighting phase, to enhance the quality of indirect illumination, we propose a second split-sum algorithm to trace secondary rays under the split-sum rendering framework.Furthermore, there is no dataset or protocol available to quantitatively evaluate the inverse rendering performance for glossy objects. To assess the quality of material reconstruction and relighting, we have created a new dataset with ground truth BRDF parameters and relighting results. Our experiments demonstrate that our algorithm achieves state-of-the-art performance in inverse rendering and relighting, with particularly strong results in the reconstruction of highly reflective objects.
SplatFields: Neural Gaussian Splats for Sparse 3D and 4D Reconstruction
Sep 17, 2024



Digitizing 3D static scenes and 4D dynamic events from multi-view images has long been a challenge in computer vision and graphics. Recently, 3D Gaussian Splatting (3DGS) has emerged as a practical and scalable reconstruction method, gaining popularity due to its impressive reconstruction quality, real-time rendering capabilities, and compatibility with widely used visualization tools. However, the method requires a substantial number of input views to achieve high-quality scene reconstruction, introducing a significant practical bottleneck. This challenge is especially severe in capturing dynamic scenes, where deploying an extensive camera array can be prohibitively costly. In this work, we identify the lack of spatial autocorrelation of splat features as one of the factors contributing to the suboptimal performance of the 3DGS technique in sparse reconstruction settings. To address the issue, we propose an optimization strategy that effectively regularizes splat features by modeling them as the outputs of a corresponding implicit neural field. This results in a consistent enhancement of reconstruction quality across various scenarios. Our approach effectively handles static and dynamic cases, as demonstrated by extensive testing across different setups and scene complexities.
Improving 2D Feature Representations by 3D-Aware Fine-Tuning
Jul 29, 2024



Current visual foundation models are trained purely on unstructured 2D data, limiting their understanding of 3D structure of objects and scenes. In this work, we show that fine-tuning on 3D-aware data improves the quality of emerging semantic features. We design a method to lift semantic 2D features into an efficient 3D Gaussian representation, which allows us to re-render them for arbitrary views. Using the rendered 3D-aware features, we design a fine-tuning strategy to transfer such 3D awareness into a 2D foundation model. We demonstrate that models fine-tuned in that way produce features that readily improve downstream task performance in semantic segmentation and depth estimation through simple linear probing. Notably, though fined-tuned on a single indoor dataset, the improvement is transferable to a variety of indoor datasets and out-of-domain datasets. We hope our study encourages the community to consider injecting 3D awareness when training 2D foundation models. Project page: https://ywyue.github.io/FiT3D.
Physics-Informed Learning of Characteristic Trajectories for Smoke Reconstruction
Jul 12, 2024We delve into the physics-informed neural reconstruction of smoke and obstacles through sparse-view RGB videos, tackling challenges arising from limited observation of complex dynamics. Existing physics-informed neural networks often emphasize short-term physics constraints, leaving the proper preservation of long-term conservation less explored. We introduce Neural Characteristic Trajectory Fields, a novel representation utilizing Eulerian neural fields to implicitly model Lagrangian fluid trajectories. This topology-free, auto-differentiable representation facilitates efficient flow map calculations between arbitrary frames as well as efficient velocity extraction via auto-differentiation. Consequently, it enables end-to-end supervision covering long-term conservation and short-term physics priors. Building on the representation, we propose physics-informed trajectory learning and integration into NeRF-based scene reconstruction. We enable advanced obstacle handling through self-supervised scene decomposition and seamless integrated boundary constraints. Our results showcase the ability to overcome challenges like occlusion uncertainty, density-color ambiguity, and static-dynamic entanglements. Code and sample tests are at \url{https://github.com/19reborn/PICT_smoke}.
LaRa: Efficient Large-Baseline Radiance Fields
Jul 05, 2024



Radiance field methods have achieved photorealistic novel view synthesis and geometry reconstruction. But they are mostly applied in per-scene optimization or small-baseline settings. While several recent works investigate feed-forward reconstruction with large baselines by utilizing transformers, they all operate with a standard global attention mechanism and hence ignore the local nature of 3D reconstruction. We propose a method that unifies local and global reasoning in transformer layers, resulting in improved quality and faster convergence. Our model represents scenes as Gaussian Volumes and combines this with an image encoder and Group Attention Layers for efficient feed-forward reconstruction. Experimental results demonstrate that our model, trained for two days on four GPUs, demonstrates high fidelity in reconstructing 360° radiance fields, and robustness to zero-shot and out-of-domain testing.