 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLOW-BENCH: Towards Conversational Generation of Enterprise Workflows
May 16, 2025Business process automation (BPA) that leverages Large Language Models (LLMs) to convert natural language (NL) instructions into structured business process artifacts is becoming a hot research topic. This paper makes two technical contributions -- (i) FLOW-BENCH, a high quality dataset of paired natural language instructions and structured business process definitions to evaluate NL-based BPA tools, and support bourgeoning research in this area, and (ii) FLOW-GEN, our approach to utilize LLMs to translate natural language into an intermediate representation with Python syntax that facilitates final conversion into widely adopted business process definition languages, such as BPMN and DMN. We bootstrap FLOW-BENCH by demonstrating how it can be used to evaluate the components of FLOW-GEN across eight LLMs of varying sizes. We hope that FLOW-GEN and FLOW-BENCH catalyze further research in BPA making it more accessible to novice and expert users.
Activity and Subject Detection for UCI HAR Dataset with & without missing Sensor Data
May 10, 2025



Current studies in Human Activity Recognition (HAR) primarily focus on the classification of activities through sensor data, while there is not much emphasis placed on recognizing the individuals performing these activities. This type of classification is very important for developing personalized and context-sensitive applications. Additionally, the issue of missing sensor data, which often occurs in practical situations due to hardware malfunctions, has not been explored yet. This paper seeks to fill these voids by introducing a lightweight LSTM-based model that can be used to classify both activities and subjects. The proposed model was used to classify the HAR dataset by UCI [1], achieving an accuracy of 93.89% in activity recognition (across six activities), nearing the 96.67% benchmark, and an accuracy of 80.19% in subject recognition (involving 30 subjects), thereby establishing a new baseline for this area of research. We then simulate the absence of sensor data to mirror real-world scenarios and incorporate imputation techniques, both with and without Principal Component Analysis (PCA), to restore incomplete datasets. We found that K-Nearest Neighbors (KNN) imputation performs the best for filling the missing sensor data without PCA because the use of PCA resulted in slightly lower accuracy. These results demonstrate how well the framework handles missing sensor data, which is a major step forward in using the Human Activity Recognition dataset for reliable classification tasks.
NeuNetS: An Automated Synthesis Engine for Neural Network Design
Jan 17, 2019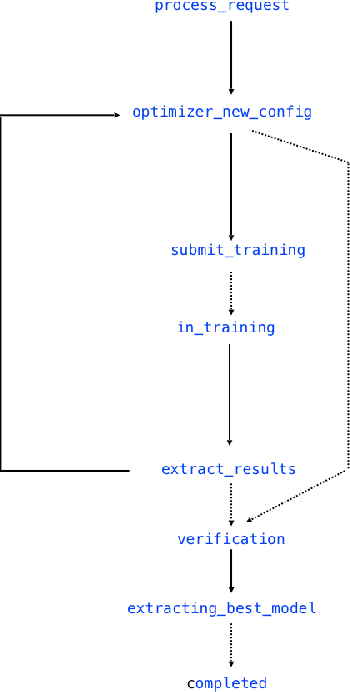
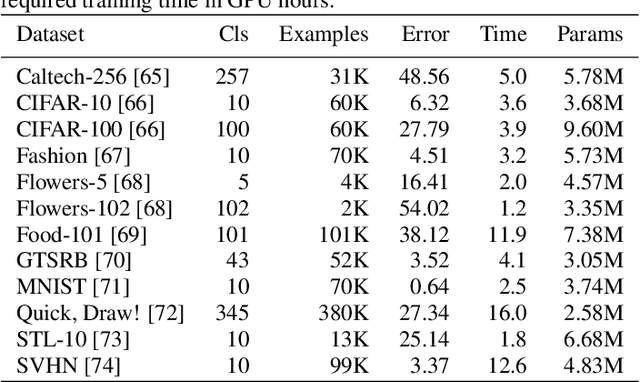
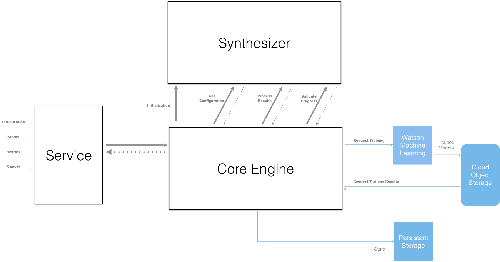
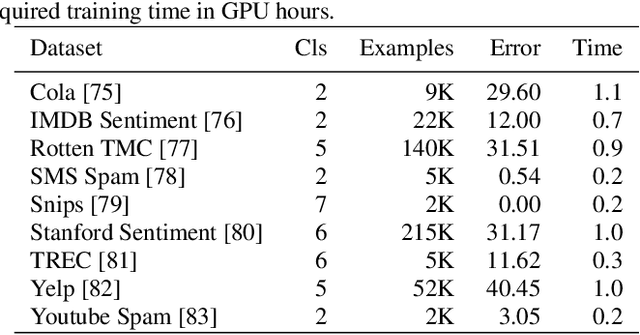
Application of neural networks to a vast variety of practical applications is transforming the way AI is applied in practice. Pre-trained neural network models available through APIs or capability to custom train pre-built neural network architectures with customer data has made the consumption of AI by developers much simpler and resulted in broad adoption of these complex AI models. While prebuilt network models exist for certain scenarios, to try and meet the constraints that are unique to each application, AI teams need to think about developing custom neural network architectures that can meet the tradeoff between accuracy and memory footprint to achieve the tight constraints of their unique use-cases. However, only a small proportion of data science teams have the skills and experience needed to create a neural network from scratch, and the demand far exceeds the supply. In this paper, we present NeuNetS : An automated Neural Network Synthesis engine for custom neural network design that is available as part of IBM's AI OpenScale's product. NeuNetS is available for both Text and Image domains and can build neural networks for specific tasks in a fraction of the time it takes today with human effort, and with accuracy similar to that of human-designed AI models.