 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Steerability 360: A Toolkit for Steering Large Language Models
Mar 08, 2026The AI Steerability 360 toolkit is an extensible, open-source Python library for steering LLMs. Steering abstractions are designed around four model control surfaces: input (modification of the prompt), structural (modification of the model's weights or architecture), state (modification of the model's activations and attentions), and output (modification of the decoding or generation process). Steering methods exert control on the model through a common interface, termed a steering pipeline, which additionally allows for the composition of multiple steering methods. Comprehensive evaluation and comparison of steering methods/pipelines is facilitated by use case classes (for defining tasks) and a benchmark class (for performance comparison on a given task). The functionality provided by the toolkit significantly lowers the barrier to developing and comprehensively evaluating steering methods. The toolkit is Hugging Face native and is released under an Apache 2.0 license at https://github.com/IBM/AISteer360.
Shift Happens: Mixture of Experts based Continual Adaptation in Federated Learning
Jun 23, 2025Federated Learning (FL) enables collaborative model training across decentralized clients without sharing raw data, yet faces significant challenges in real-world settings where client data distributions evolve dynamically over time. This paper tackles the critical problem of covariate and label shifts in streaming FL environments, where non-stationary data distributions degrade model performance and require adaptive middleware solutions. We introduce ShiftEx, a shift-aware mixture of experts framework that dynamically creates and trains specialized global models in response to detected distribution shifts using Maximum Mean Discrepancy for covariate shifts. The framework employs a latent memory mechanism for expert reuse and implements facility location-based optimization to jointly minimize covariate mismatch, expert creation costs, and label imbalance. Through theoretical analysis and comprehensive experiments on benchmark datasets, we demonstrate 5.5-12.9 percentage point accuracy improvements and 22-95 % faster adaptation compared to state-of-the-art FL baselines across diverse shift scenarios. The proposed approach offers a scalable, privacy-preserving middleware solution for FL systems operating in non-stationary, real-world conditions while minimizing communication and computational overhead.
Spotlight Your Instructions: Instruction-following with Dynamic Attention Steering
May 17, 2025



In many real-world applications, users rely on natural language instructions to guide large language models (LLMs) across a wide range of tasks. These instructions are often complex, diverse, and subject to frequent change. However, LLMs do not always attend to these instructions reliably, and users lack simple mechanisms to emphasize their importance beyond modifying prompt wording or structure. To address this, we present an inference-time method that enables users to emphasize specific parts of their prompt by steering the model's attention toward them, aligning the model's perceived importance of different prompt tokens with user intent. Unlike prior approaches that are limited to static instructions, require significant offline profiling, or rely on fixed biases, we dynamically update the proportion of model attention given to the user-specified parts--ensuring improved instruction following without performance degradation. We demonstrate that our approach improves instruction following across a variety of tasks involving multiple instructions and generalizes across models of varying scales.
FLOW-BENCH: Towards Conversational Generation of Enterprise Workflows
May 16, 2025Business process automation (BPA) that leverages Large Language Models (LLMs) to convert natural language (NL) instructions into structured business process artifacts is becoming a hot research topic. This paper makes two technical contributions -- (i) FLOW-BENCH, a high quality dataset of paired natural language instructions and structured business process definitions to evaluate NL-based BPA tools, and support bourgeoning research in this area, and (ii) FLOW-GEN, our approach to utilize LLMs to translate natural language into an intermediate representation with Python syntax that facilitates final conversion into widely adopted business process definition languages, such as BPMN and DMN. We bootstrap FLOW-BENCH by demonstrating how it can be used to evaluate the components of FLOW-GEN across eight LLMs of varying sizes. We hope that FLOW-GEN and FLOW-BENCH catalyze further research in BPA making it more accessible to novice and expert users.
OptiSeq: Optimizing Example Ordering for In-Context Learning
Jan 25, 2025Developers using LLMs in their applications and agents have provided plenty of anecdotal evidence that in-context-learning (ICL) is fragile. In addition to the quantity and quality of examples, we show that the order in which the in-context examples are listed in the prompt affects the output of the LLM and, consequently, their performance. In this paper, we present OptiSeq, which introduces a score based on log probabilities of LLM outputs to prune the universe of possible example orderings in few-shot ICL and recommend the best order(s) by distinguishing between correct and incorrect outputs resulting from different order permutations. Through a detailed empirical evaluation on multiple LLMs, datasets and prompts, we demonstrate that OptiSeq improves accuracy by 6 - 10.5 percentage points across multiple tasks.
Evaluating the Instruction-following Abilities of Language Models using Knowledge Tasks
Oct 16, 2024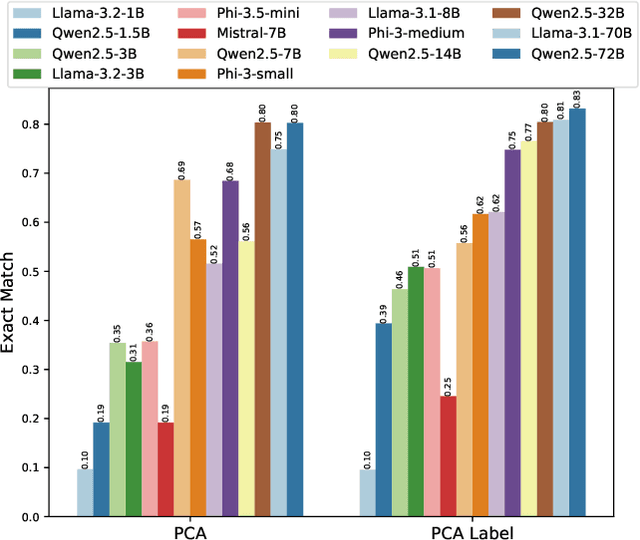
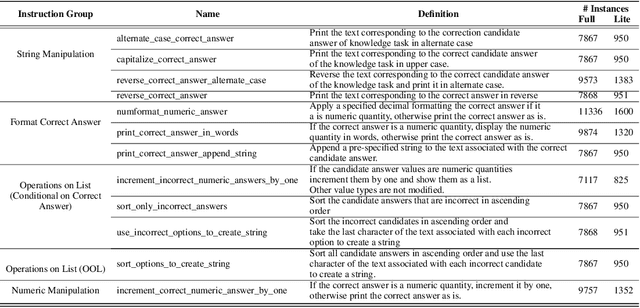
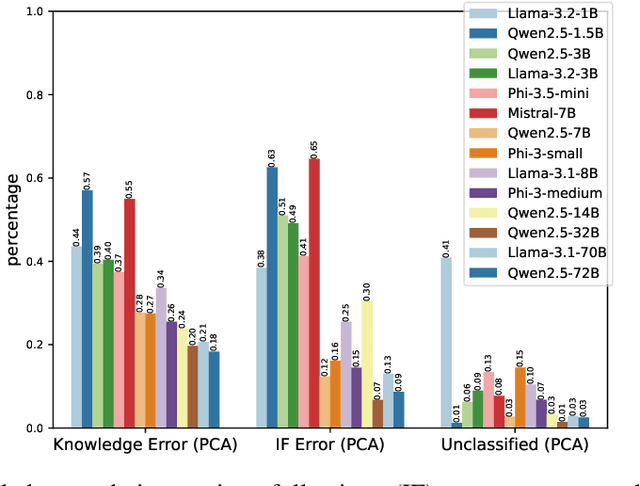
In this work, we focus our attention on developing a benchmark for instruction-following where it is easy to verify both task performance as well as instruction-following capabilities. We adapt existing knowledge benchmarks and augment them with instructions that are a) conditional on correctly answering the knowledge task or b) use the space of candidate options in multiple-choice knowledge-answering tasks. This allows us to study model characteristics, such as their change in performance on the knowledge tasks in the presence of answer-modifying instructions and distractor instructions. In contrast to existing benchmarks for instruction following, we not only measure instruction-following capabilities but also use LLM-free methods to study task performance. We study a series of openly available large language models of varying parameter sizes (1B-405B) and closed source models namely GPT-4o-mini, GPT-4o. We find that even large-scale instruction-tuned LLMs fail to follow simple instructions in zero-shot settings. We release our dataset, the benchmark, code, and results for future work.
Granite-Function Calling Model: Introducing Function Calling Abilities via Multi-task Learning of Granular Tasks
Jun 27, 2024



Large language models (LLMs) have recently shown tremendous promise in serving as the backbone to agentic systems, as demonstrated by their performance in multi-faceted, challenging benchmarks like SWE-Bench and Agent-Bench. However, to realize the true potential of LLMs as autonomous agents, they must learn to identify, call, and interact with external tools and application program interfaces (APIs) to complete complex tasks. These tasks together are termed function calling. Endowing LLMs with function calling abilities leads to a myriad of advantages, such as access to current and domain-specific information in databases and knowledge sources, and the ability to outsource tasks that can be reliably performed by tools, e.g., a Python interpreter or calculator. While there has been significant progress in function calling with LLMs, there is still a dearth of open models that perform on par with proprietary LLMs like GPT, Claude, and Gemini. Therefore, in this work, we introduce the GRANITE-20B-FUNCTIONCALLING model under an Apache 2.0 license. The model is trained using a multi-task training approach on seven fundamental tasks encompassed in function calling, those being Nested Function Calling, Function Chaining, Parallel Functions, Function Name Detection, Parameter-Value Pair Detection, Next-Best Function, and Response Generation. We present a comprehensive evaluation on multiple out-of-domain datasets comparing GRANITE-20B-FUNCTIONCALLING to more than 15 other best proprietary and open models. GRANITE-20B-FUNCTIONCALLING provides the best performance among all open models on the Berkeley Function Calling Leaderboard and fourth overall. As a result of the diverse tasks and datasets used for training our model, we show that GRANITE-20B-FUNCTIONCALLING has better generalizability on multiple tasks in seven different evaluation datasets.
TaskDiff: A Similarity Metric for Task-Oriented Conversations
Oct 25, 2023



The popularity of conversational digital assistants has resulted in the availability of large amounts of conversational data which can be utilized for improved user experience and personalized response generation. Building these assistants using popular large language models like ChatGPT also require additional emphasis on prompt engineering and evaluation methods. Textual similarity metrics are a key ingredient for such analysis and evaluations. While many similarity metrics have been proposed in the literature, they have not proven effective for task-oriented conversations as they do not take advantage of unique conversational features. To address this gap, we present TaskDiff, a novel conversational similarity metric that utilizes different dialogue components (utterances, intents, and slots) and their distributions to compute similarity. Extensive experimental evaluation of TaskDiff on a benchmark dataset demonstrates its superior performance and improved robustness over other related approaches.
DiSTRICT: Dialogue State Tracking with Retriever Driven In-Context Tuning
Dec 06, 2022



Dialogue State Tracking (DST), a key component of task-oriented conversation systems, represents user intentions by determining the values of pre-defined slots in an ongoing dialogue. Existing approaches use hand-crafted templates and additional slot information to fine-tune and prompt large pre-trained language models and elicit slot values from the dialogue context. Significant manual effort and domain knowledge is required to design effective prompts, limiting the generalizability of these approaches to new domains and tasks. In this work, we propose DiSTRICT, a generalizable in-context tuning approach for DST that retrieves highly relevant training examples for a given dialogue to fine-tune the model without any hand-crafted templates. Experiments with the MultiWOZ benchmark datasets show that DiSTRICT outperforms existing approaches in various zero-shot and few-shot settings using a much smaller model, thereby providing an important advantage for real-world deployments that often have limited resource availability.
FedGen: Generalizable Federated Learning
Nov 03, 2022Existing federated learning models that follow the standard risk minimization paradigm of machine learning often fail to generalize in the presence of spurious correlations in the training data. In many real-world distributed settings, spurious correlations exist due to biases and data sampling issues on distributed devices or clients that can erroneously influence models. Current generalization approaches are designed for centralized training and attempt to identify features that have an invariant causal relationship with the target, thereby reducing the effect of spurious features. However, such invariant risk minimization approaches rely on apriori knowledge of training data distributions which is hard to obtain in many applications. In this work, we present a generalizable federated learning framework called FedGen, which allows clients to identify and distinguish between spurious and invariant features in a collaborative manner without prior knowledge of training distributions. We evaluate our approach on real-world datasets from different domains and show that FedGen results in models that achieve significantly better generalization than current federated learning approaches.