 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiqi Zheng
Exploring Speaker-Related Information in Spoken Language Understanding for Better Speaker Diarization
May 22, 2023
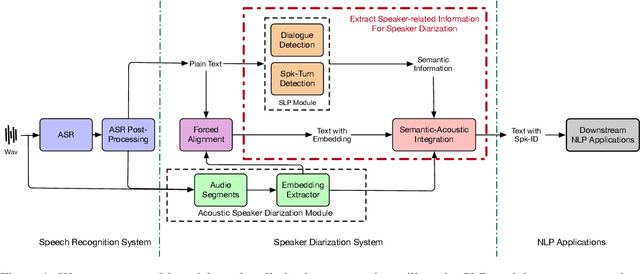
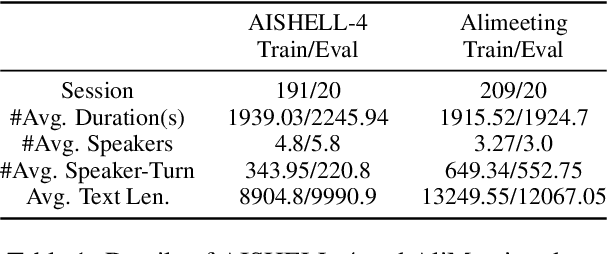
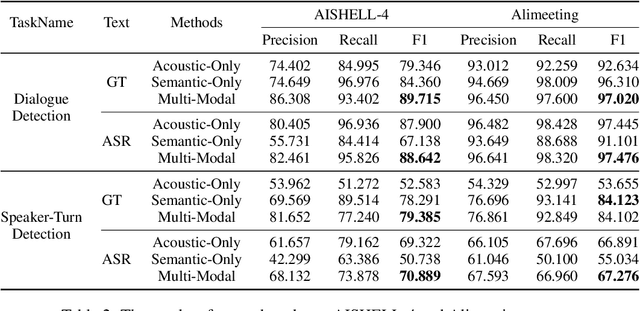
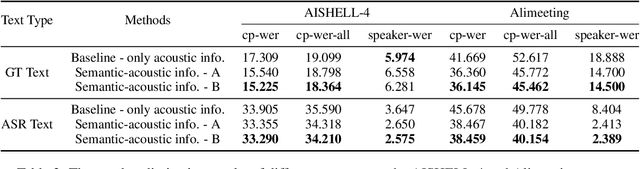
Speaker diarization(SD) is a classic task in speech processing and is crucial in multi-party scenarios such as meetings and conversations. Current mainstream speaker diarization approaches consider acoustic information only, which result in performance degradation when encountering adverse acoustic conditions. In this paper, we propose methods to extract speaker-related information from semantic content in multi-party meetings, which, as we will show, can further benefit speaker diarization. We introduce two sub-tasks, Dialogue Detection and Speaker-Turn Detection, in which we effectively extract speaker information from conversational semantics. We also propose a simple yet effective algorithm to jointly model acoustic and semantic information and obtain speaker-identified texts. Experiments on both AISHELL-4 and AliMeeting datasets show that our method achieves consistent improvements over acoustic-only speaker diarization systems.
An Enhanced Res2Net with Local and Global Feature Fusion for Speaker Verification
May 22, 2023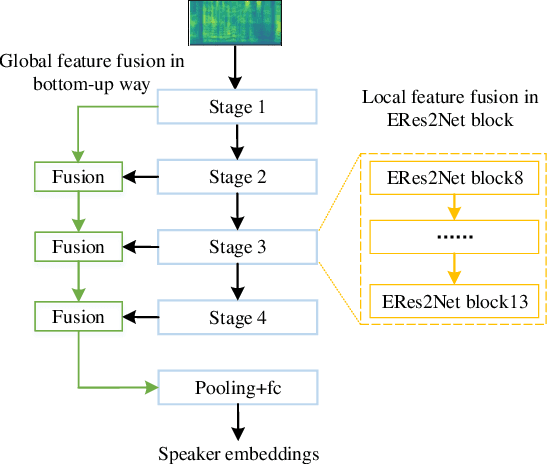
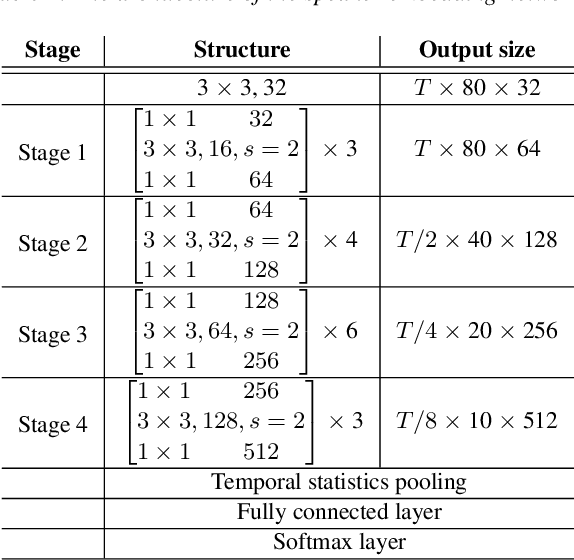
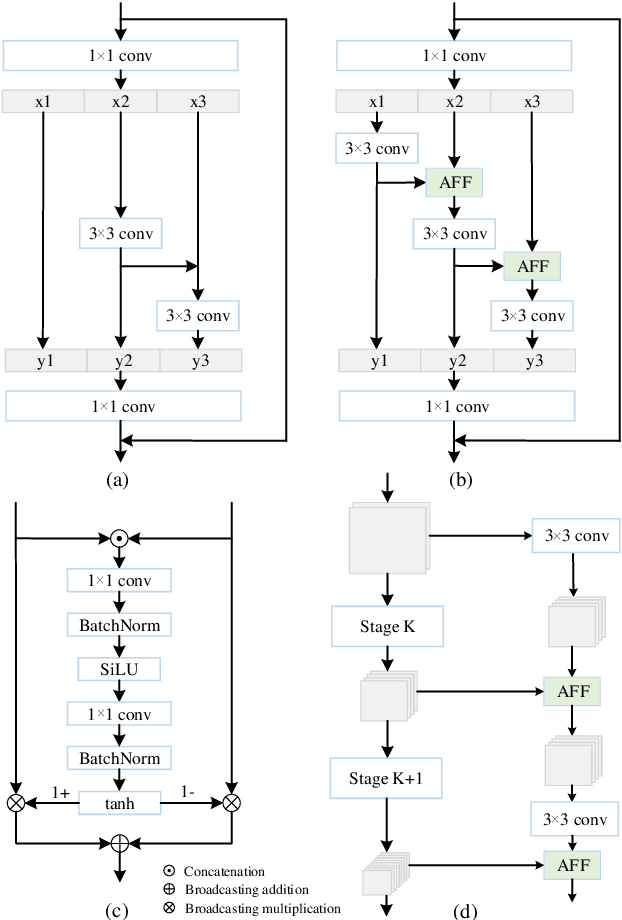

Effective fusion of multi-scale features is crucial for improving speaker verification performance. While most existing methods aggregate multi-scale features in a layer-wise manner via simple operations, such as summation or concatenation. This paper proposes a novel architecture called Enhanced Res2Net (ERes2Net), which incorporates both local and global feature fusion techniques to improve the performance. The local feature fusion (LFF) fuses the features within one single residual block to extract the local signal. The global feature fusion (GFF) takes acoustic features of different scales as input to aggregate global signal. To facilitate effective feature fusion in both LFF and GFF, an attentional feature fusion module is employed in the ERes2Net architecture, replacing summation or concatenation operations. A range of experiments conducted on the VoxCeleb datasets demonstrate the superiority of the ERes2Net in speaker verification.
Ditto: A Simple and Efficient Approach to Improve Sentence Embeddings
May 18, 2023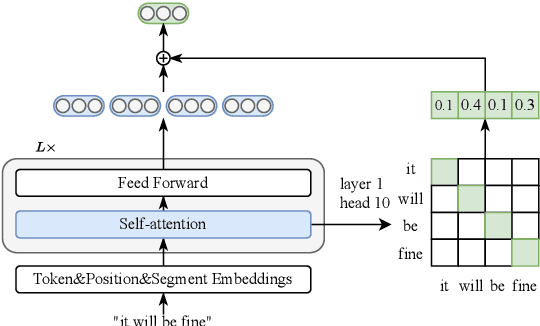
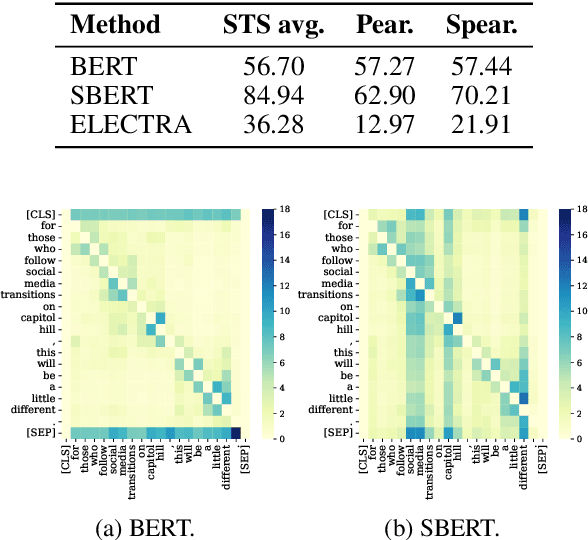
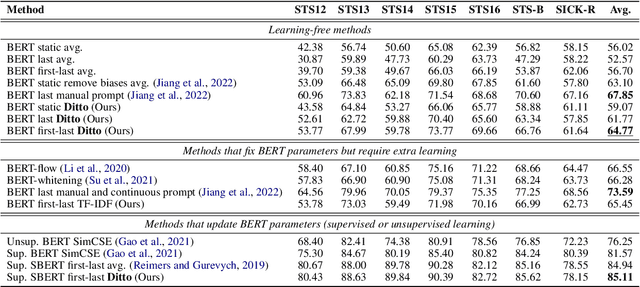

Prior studies diagnose the anisotropy problem in sentence representations from pre-trained language models, e.g., BERT, without fine-tuning. Our analysis reveals that the sentence embeddings from BERT suffer from a bias towards uninformative words, limiting the performance in semantic textual similarity (STS) tasks. To address this bias, we propose a simple and efficient unsupervised approach, Diagonal Attention Pooling (Ditto), which weights words with model-based importance estimations and computes the weighted average of word representations from pre-trained models as sentence embeddings. Ditto can be easily applied to any pre-trained language model as a postprocessing operation. Compared to prior sentence embedding approaches, Ditto does not add parameters nor requires any learning. Empirical evaluations demonstrate that our proposed Ditto can alleviate the anisotropy problem and improve various pre-trained models on STS tasks.
CAM++: A Fast and Efficient Network for Speaker Verification Using Context-Aware Masking
Mar 02, 2023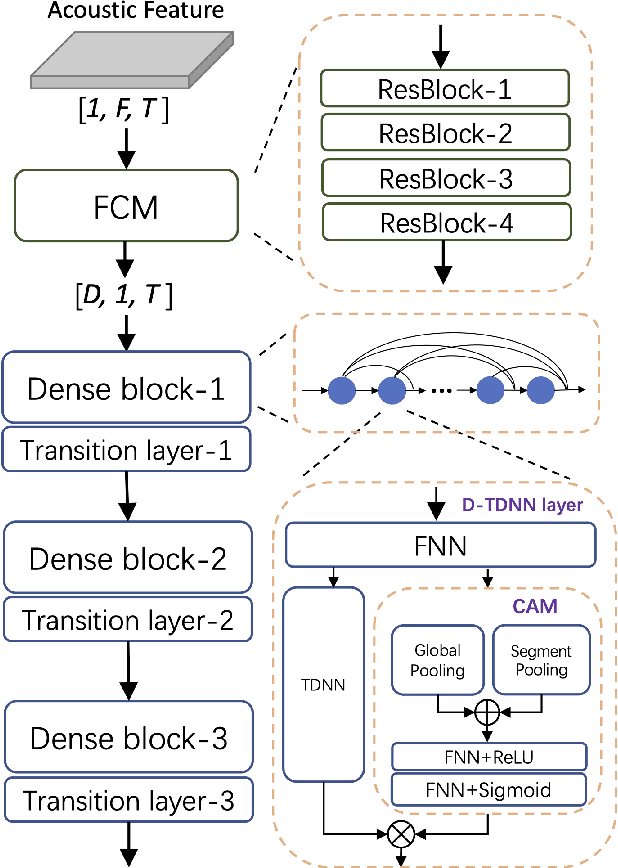
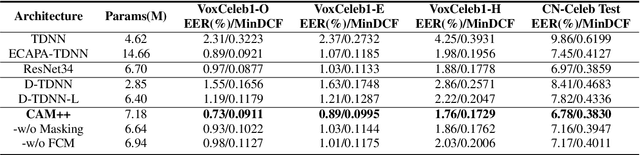
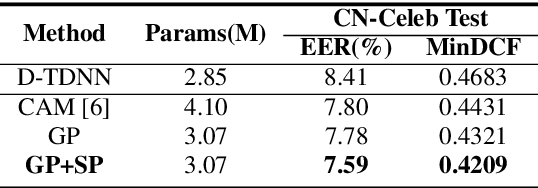

Time delay neural network (TDNN) has been proven to be efficient for speaker verification. One of its successful variants, ECAPA-TDNN, achieved state-of-the-art performance at the cost of much higher computational complexity and slower inference speed. This makes it inadequate for scenarios with demanding inference rate and limited computational resources. We are thus interested in finding an architecture that can achieve the performance of ECAPA-TDNN and the efficiency of vanilla TDNN. In this paper, we propose an efficient network based on context-aware masking, namely CAM++, which uses densely connected time delay neural network (D-TDNN) as backbone and adopts a novel multi-granularity pooling to capture contextual information at different levels. Extensive experiments on two public benchmarks, VoxCeleb and CN-Celeb, demonstrate that the proposed architecture outperforms other mainstream speaker verification systems with lower computational cost and faster inference speed.
CAM++: A Fast and Efficient Network For Speaker Verification Using Context-Aware Masking
Mar 01, 2023Time delay neural network (TDNN) has been proven to be efficient in learning discriminative speaker embeddings. One of its successful variant, ECAPA-TDNN, achieved state-of-the-art performance on speaker verification tasks at the cost of much higher computational complexity and slower inference speed. This makes it inadequate for scenarios with demanding inference rate and limited computational resources. We are thus interested in finding an architecture that can achieve the performance of ECAPA-TDNN and the efficiency of vanilla TDNN. In this paper, we propose an efficient network based on context-aware masking, namely CAM++, which uses densely connected time delay neural network (D-TDNN) as backbone and adopts a novel multi-granularity pooling to capture contextual information at different levels. Extensive experiments on two public benchmarks, VoxCeleb and CN-Celeb, demonstrate that the proposed architecture outperforms other mainstream speaker verification systems with lower computational cost and faster inference speed.
DopplerBAS: Binaural Audio Synthesis Addressing Doppler Effect
Dec 16, 2022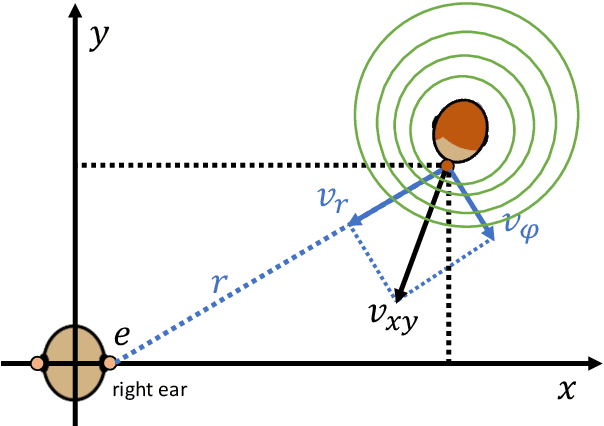
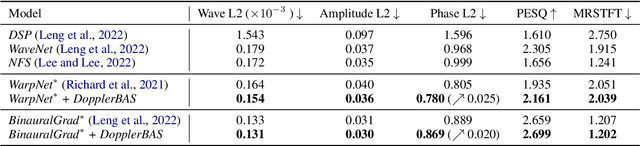
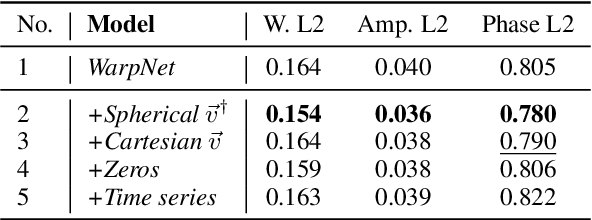
Recently, binaural audio synthesis (BAS) has emerged as a promising research field for its applications in augmented and virtual realities. Binaural audio helps us to orient ourselves and establish immersion by providing the brain with interaural time differences reflecting spatial information. However, existing methods are limited in terms of phase estimation, which is crucial for spatial hearing. In this paper, we propose the DopplerBAS method to explicitly address the Doppler effect of the moving sound source. Specifically, we calculate the radial relative velocity of the moving speaker in spherical coordinates, which further guides the synthesis of binaural audio. This simple method neither introduces any additional hyper-parameters nor modifies the loss functions, and is plug-and-play: it scales well to different types of backbones. DopplerBAS distinctly improves WarpNet and BinauralGrad in the phase error metric and reaches a new state-of-the-art: 0.780 (vs. the current state-of-the-art 0.807). Experiments and ablation studies demonstrate the effectiveness of our method.
Contextual Expressive Text-to-Speech
Nov 26, 2022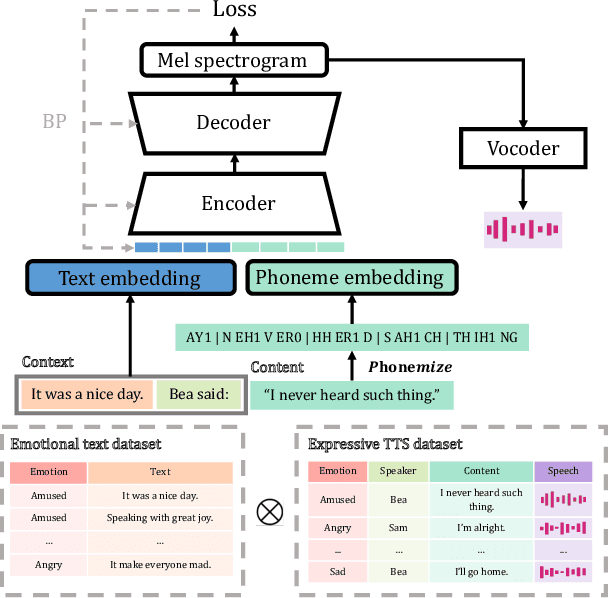

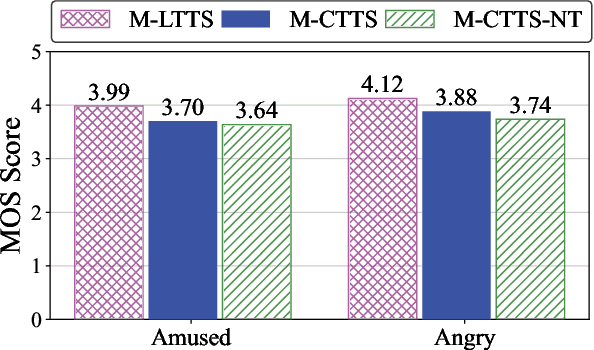
The goal of expressive Text-to-speech (TTS) is to synthesize natural speech with desired content, prosody, emotion, or timbre, in high expressiveness. Most of previous studies attempt to generate speech from given labels of styles and emotions, which over-simplifies the problem by classifying styles and emotions into a fixed number of pre-defined categories. In this paper, we introduce a new task setting, Contextual TTS (CTTS). The main idea of CTTS is that how a person speaks depends on the particular context she is in, where the context can typically be represented as text. Thus, in the CTTS task, we propose to utilize such context to guide the speech synthesis process instead of relying on explicit labels of styles and emotions. To achieve this task, we construct a synthetic dataset and develop an effective framework. Experiments show that our framework can generate high-quality expressive speech based on the given context both in synthetic datasets and real-world scenarios.
Speaker Overlap-aware Neural Diarization for Multi-party Meeting Analysis
Nov 18, 2022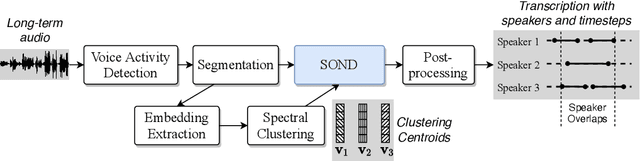
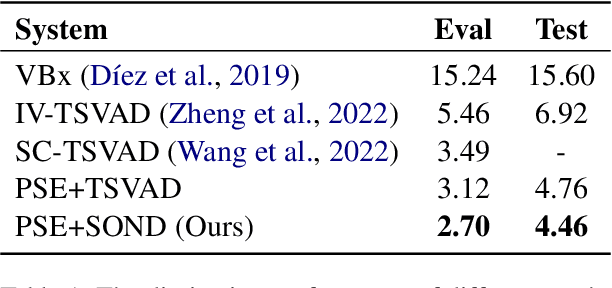
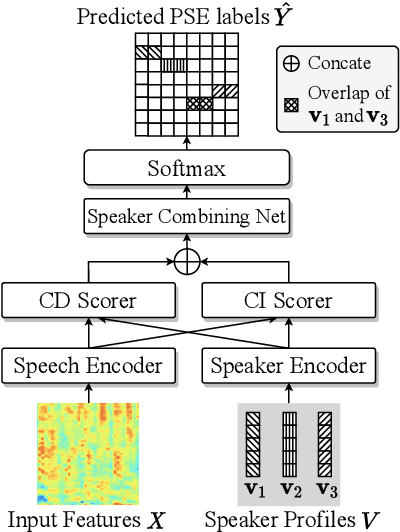
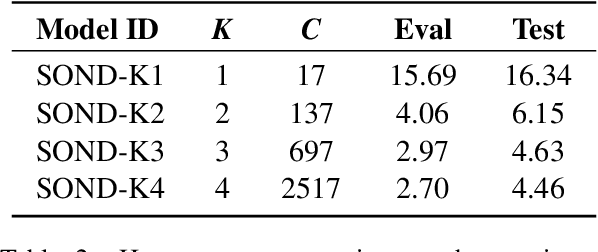
Recently, hybrid systems of clustering and neural diarization models have been successfully applied in multi-party meeting analysis. However, current models always treat overlapped speaker diarization as a multi-label classification problem, where speaker dependency and overlaps are not well considered. To overcome the disadvantages, we reformulate overlapped speaker diarization task as a single-label prediction problem via the proposed power set encoding (PSE). Through this formulation, speaker dependency and overlaps can be explicitly modeled. To fully leverage this formulation, we further propose the speaker overlap-aware neural diarization (SOND) model, which consists of a context-independent (CI) scorer to model global speaker discriminability, a context-dependent scorer (CD) to model local discriminability, and a speaker combining network (SCN) to combine and reassign speaker activities. Experimental results show that using the proposed formulation can outperform the state-of-the-art methods based on target speaker voice activity detection, and the performance can be further improved with SOND, resulting in a 6.30% relative diarization error reduction.
Pushing the limits of self-supervised speaker verification using regularized distillation framework
Nov 08, 2022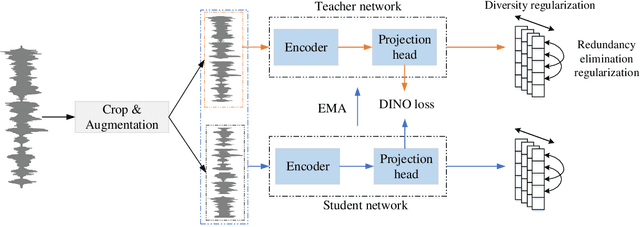
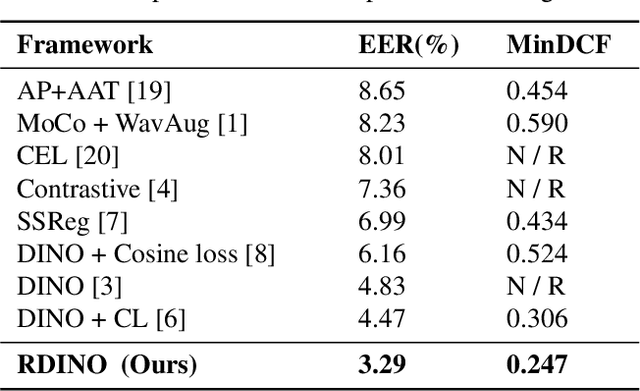
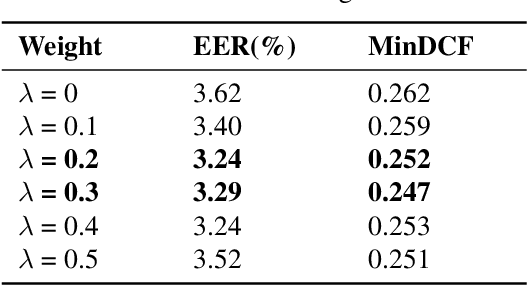
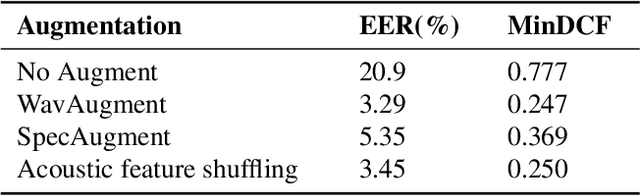
Training robust speaker verification systems without speaker labels has long been a challenging task. Previous studies observed a large performance gap between self-supervised and fully supervised methods. In this paper, we apply a non-contrastive self-supervised learning framework called DIstillation with NO labels (DINO) and propose two regularization terms applied to embeddings in DINO. One regularization term guarantees the diversity of the embeddings, while the other regularization term decorrelates the variables of each embedding. The effectiveness of various data augmentation techniques are explored, on both time and frequency domain. A range of experiments conducted on the VoxCeleb datasets demonstrate the superiority of the regularized DINO framework in speaker verification. Our method achieves the state-of-the-art speaker verification performance under a single-stage self-supervised setting on VoxCeleb. The codes will be made publicly-available.