 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Filtering of Human Feedback Data for Aligning Text-to-Image Diffusion Models
Oct 14, 2024



Fine-tuning text-to-image diffusion models with human feedback is an effective method for aligning model behavior with human intentions. However, this alignment process often suffers from slow convergence due to the large size and noise present in human feedback datasets. In this work, we propose FiFA, a novel automated data filtering algorithm designed to enhance the fine-tuning of diffusion models using human feedback datasets with direct preference optimization (DPO). Specifically, our approach selects data by solving an optimization problem to maximize three components: preference margin, text quality, and text diversity. The concept of preference margin is used to identify samples that contain high informational value to address the noisy nature of feedback dataset, which is calculated using a proxy reward model. Additionally, we incorporate text quality, assessed by large language models to prevent harmful contents, and consider text diversity through a k-nearest neighbor entropy estimator to improve generalization. Finally, we integrate all these components into an optimization process, with approximating the solution by assigning importance score to each data pair and selecting the most important ones. As a result, our method efficiently filters data automatically, without the need for manual intervention, and can be applied to any large-scale dataset. Experimental results show that FiFA significantly enhances training stability and achieves better performance, being preferred by humans 17% more, while using less than 0.5% of the full data and thus 1% of the GPU hours compared to utilizing full human feedback datasets.
Towards Unbiased Evaluation of Detecting Unanswerable Questions in EHRSQL
Apr 29, 2024



Incorporating unanswerable questions into EHR QA systems is crucial for testing the trustworthiness of a system, as providing non-existent responses can mislead doctors in their diagnoses. The EHRSQL dataset stands out as a promising benchmark because it is the only dataset that incorporates unanswerable questions in the EHR QA system alongside practical questions. However, in this work, we identify a data bias in these unanswerable questions; they can often be discerned simply by filtering with specific N-gram patterns. Such biases jeopardize the authenticity and reliability of QA system evaluations. To tackle this problem, we propose a simple debiasing method of adjusting the split between the validation and test sets to neutralize the undue influence of N-gram filtering. By experimenting on the MIMIC-III dataset, we demonstrate both the existing data bias in EHRSQL and the effectiveness of our data split strategy in mitigating this bias.
Re-thinking Federated Active Learning based on Inter-class Diversity
Mar 22, 2023



Although federated learning has made awe-inspiring advances, most studies have assumed that the client's data are fully labeled. However, in a real-world scenario, every client may have a significant amount of unlabeled instances. Among the various approaches to utilizing unlabeled data, a federated active learning framework has emerged as a promising solution. In the decentralized setting, there are two types of available query selector models, namely 'global' and 'local-only' models, but little literature discusses their performance dominance and its causes. In this work, we first demonstrate that the superiority of two selector models depends on the global and local inter-class diversity. Furthermore, we observe that the global and local-only models are the keys to resolving the imbalance of each side. Based on our findings, we propose LoGo, a FAL sampling strategy robust to varying local heterogeneity levels and global imbalance ratio, that integrates both models by two steps of active selection scheme. LoGo consistently outperforms six active learning strategies in the total number of 38 experimental settings.
FedRN: Exploiting k-Reliable Neighbors Towards Robust Federated Learning
May 03, 2022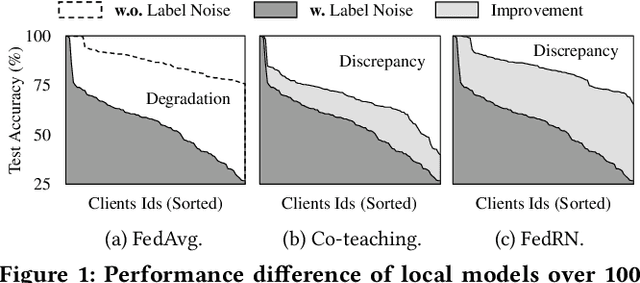
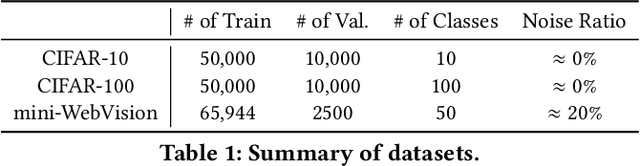
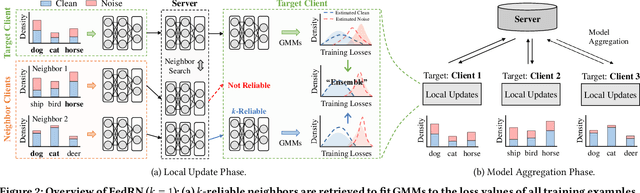
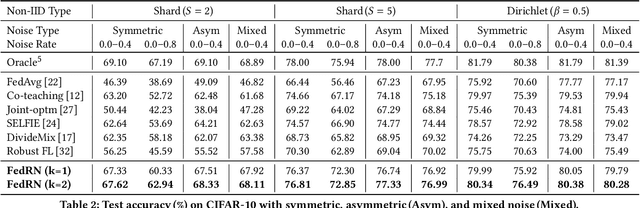
Robustness is becoming another important challenge of federated learning in that the data collection process in each client is naturally accompanied by noisy labels. However, it is far more complex and challenging owing to varying levels of data heterogeneity and noise over clients, which exacerbates the client-to-client performance discrepancy. In this work, we propose a robust federated learning method called FedRN, which exploits k-reliable neighbors with high data expertise or similarity. Our method helps mitigate the gap between low- and high-performance clients by training only with a selected set of clean examples, identified by their ensembled mixture models. We demonstrate the superiority of FedRN via extensive evaluations on three real-world or synthetic benchmark datasets. Compared with existing robust training methods, the results show that FedRN significantly improves the test accuracy in the presence of noisy labels.