 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Continuous Environment Fields via Implicit Functions
Nov 27, 2021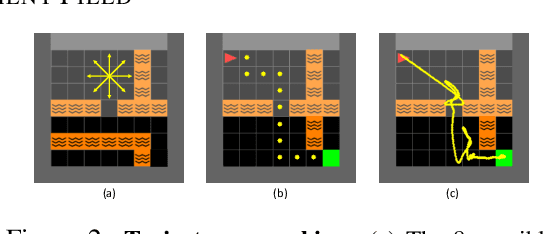
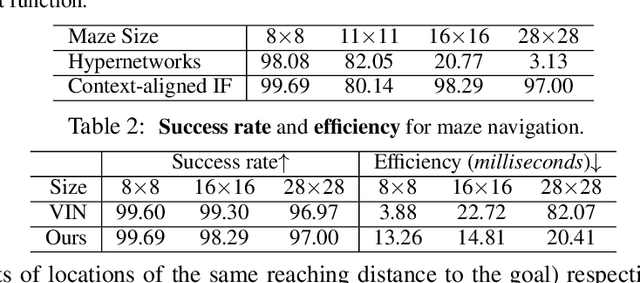
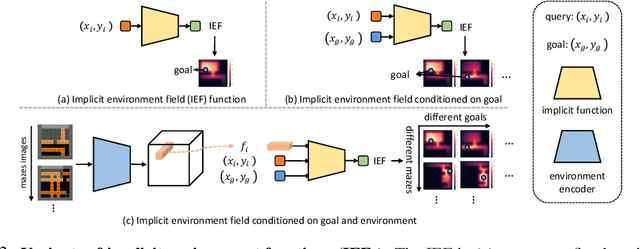
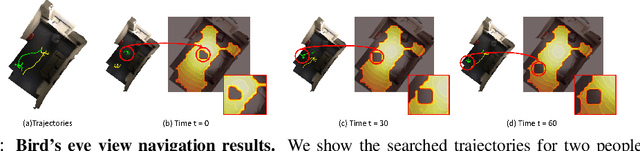
We propose a novel scene representation that encodes reaching distance -- the distance between any position in the scene to a goal along a feasible trajectory. We demonstrate that this environment field representation can directly guide the dynamic behaviors of agents in 2D mazes or 3D indoor scenes. Our environment field is a continuous representation and learned via a neural implicit function using discretely sampled training data. We showcase its application for agent navigation in 2D mazes, and human trajectory prediction in 3D indoor environments. To produce physically plausible and natural trajectories for humans, we additionally learn a generative model that predicts regions where humans commonly appear, and enforce the environment field to be defined within such regions. Extensive experiments demonstrate that the proposed method can generate both feasible and plausible trajectories efficiently and accurately.
Self-Supervised Object Detection via Generative Image Synthesis
Oct 19, 2021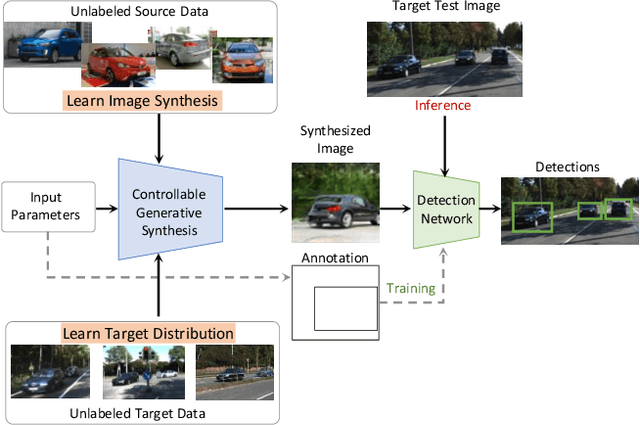
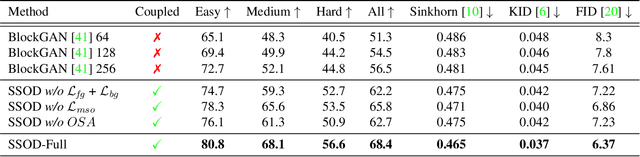
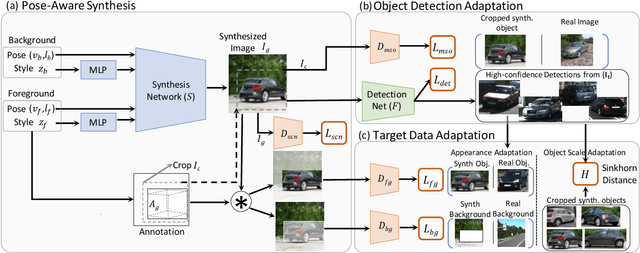
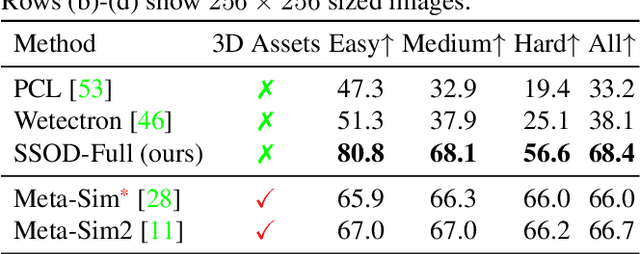
We present SSOD, the first end-to-end analysis-by synthesis framework with controllable GANs for the task of self-supervised object detection. We use collections of real world images without bounding box annotations to learn to synthesize and detect objects. We leverage controllable GANs to synthesize images with pre-defined object properties and use them to train object detectors. We propose a tight end-to-end coupling of the synthesis and detection networks to optimally train our system. Finally, we also propose a method to optimally adapt SSOD to an intended target data without requiring labels for it. For the task of car detection, on the challenging KITTI and Cityscapes datasets, we show that SSOD outperforms the prior state-of-the-art purely image-based self-supervised object detection method Wetectron. Even without requiring any 3D CAD assets, it also surpasses the state-of-the-art rendering based method Meta-Sim2. Our work advances the field of self-supervised object detection by introducing a successful new paradigm of using controllable GAN-based image synthesis for it and by significantly improving the baseline accuracy of the task. We open-source our code at https://github.com/NVlabs/SSOD.
Video Autoencoder: self-supervised disentanglement of static 3D structure and motion
Oct 06, 2021
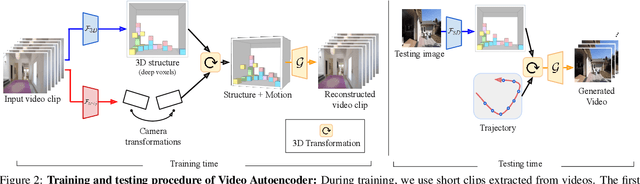
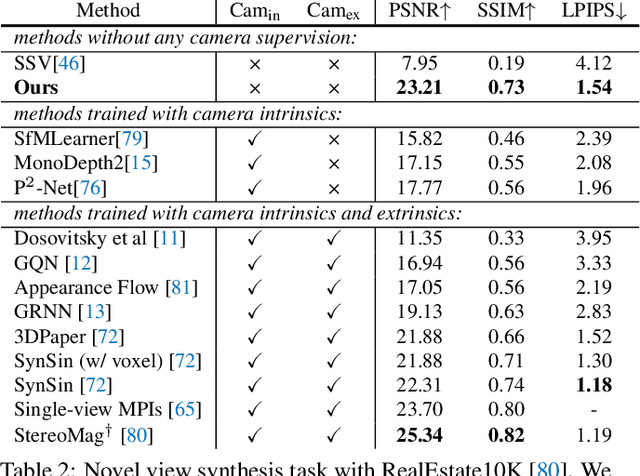
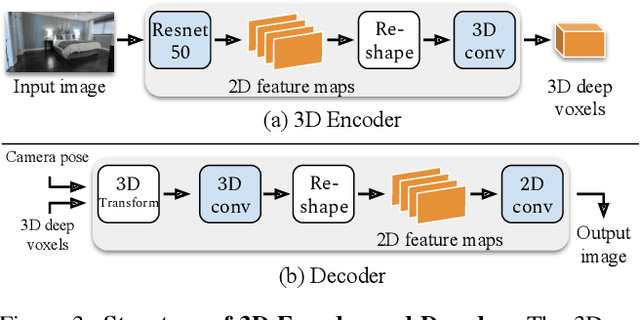
A video autoencoder is proposed for learning disentan- gled representations of 3D structure and camera pose from videos in a self-supervised manner. Relying on temporal continuity in videos, our work assumes that the 3D scene structure in nearby video frames remains static. Given a sequence of video frames as input, the video autoencoder extracts a disentangled representation of the scene includ- ing: (i) a temporally-consistent deep voxel feature to represent the 3D structure and (ii) a 3D trajectory of camera pose for each frame. These two representations will then be re-entangled for rendering the input video frames. This video autoencoder can be trained directly using a pixel reconstruction loss, without any ground truth 3D or camera pose annotations. The disentangled representation can be applied to a range of tasks, including novel view synthesis, camera pose estimation, and video generation by motion following. We evaluate our method on several large- scale natural video datasets, and show generalization results on out-of-domain images.
Learning Contrastive Representation for Semantic Correspondence
Sep 22, 2021
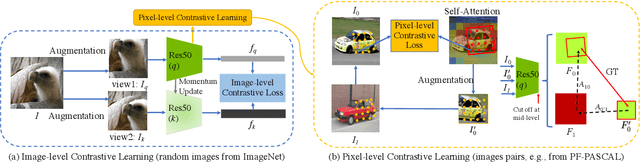

Dense correspondence across semantically related images has been extensively studied, but still faces two challenges: 1) large variations in appearance, scale and pose exist even for objects from the same category, and 2) labeling pixel-level dense correspondences is labor intensive and infeasible to scale. Most existing approaches focus on designing various matching approaches with fully-supervised ImageNet pretrained networks. On the other hand, while a variety of self-supervised approaches are proposed to explicitly measure image-level similarities, correspondence matching the pixel level remains under-explored. In this work, we propose a multi-level contrastive learning approach for semantic matching, which does not rely on any ImageNet pretrained model. We show that image-level contrastive learning is a key component to encourage the convolutional features to find correspondence between similar objects, while the performance can be further enhanced by regularizing cross-instance cycle-consistency at intermediate feature levels. Experimental results on the PF-PASCAL, PF-WILLOW, and SPair-71k benchmark datasets demonstrate that our method performs favorably against the state-of-the-art approaches. The source code and trained models will be made available to the public.
Learning 3D Dense Correspondence via Canonical Point Autoencoder
Jul 10, 2021

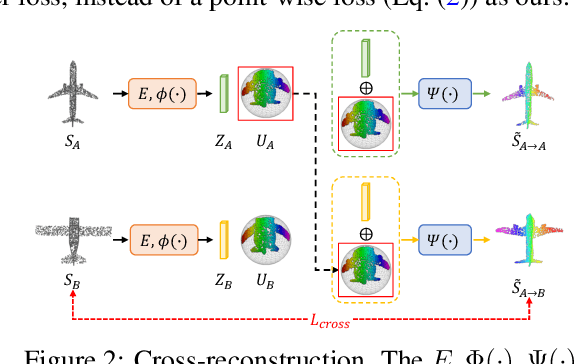
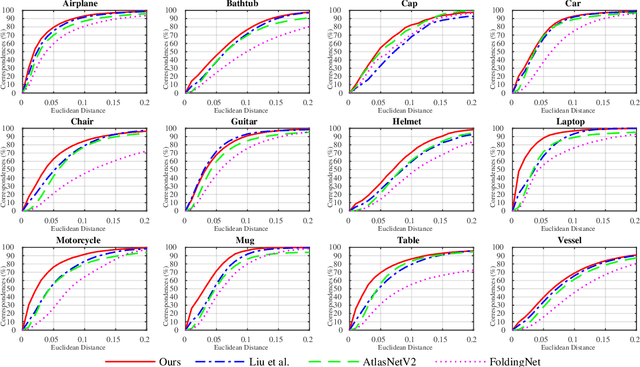
We propose a canonical point autoencoder (CPAE) that predicts dense correspondences between 3D shapes of the same category. The autoencoder performs two key functions: (a) encoding an arbitrarily ordered point cloud to a canonical primitive, e.g., a sphere, and (b) decoding the primitive back to the original input instance shape. As being placed in the bottleneck, this primitive plays a key role to map all the unordered point clouds on the canonical surface and to be reconstructed in an ordered fashion. Once trained, points from different shape instances that are mapped to the same locations on the primitive surface are determined to be a pair of correspondence. Our method does not require any form of annotation or self-supervised part segmentation network and can handle unaligned input point clouds. Experimental results on 3D semantic keypoint transfer and part segmentation transfer show that our model performs favorably against state-of-the-art correspondence learning methods.
Semi-Supervised 3D Hand-Object Poses Estimation with Interactions in Time
Jun 09, 2021

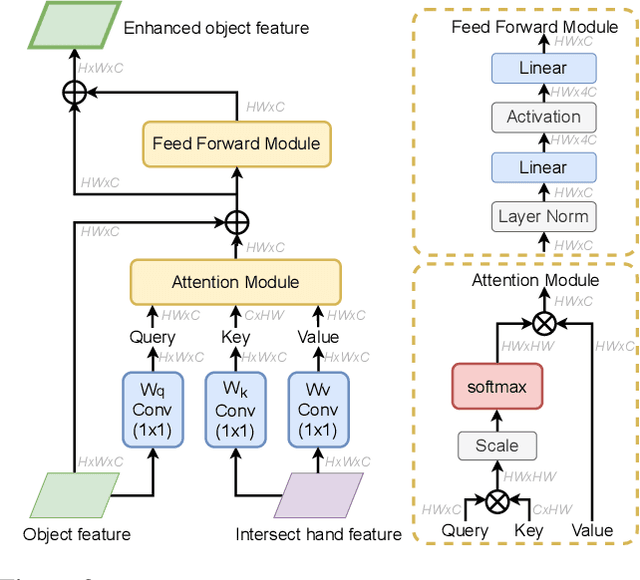
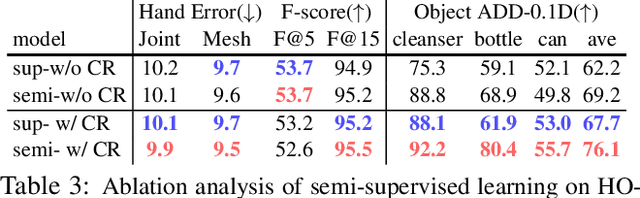
Estimating 3D hand and object pose from a single image is an extremely challenging problem: hands and objects are often self-occluded during interactions, and the 3D annotations are scarce as even humans cannot directly label the ground-truths from a single image perfectly. To tackle these challenges, we propose a unified framework for estimating the 3D hand and object poses with semi-supervised learning. We build a joint learning framework where we perform explicit contextual reasoning between hand and object representations by a Transformer. Going beyond limited 3D annotations in a single image, we leverage the spatial-temporal consistency in large-scale hand-object videos as a constraint for generating pseudo labels in semi-supervised learning. Our method not only improves hand pose estimation in challenging real-world dataset, but also substantially improve the object pose which has fewer ground-truths per instance. By training with large-scale diverse videos, our model also generalizes better across multiple out-of-domain datasets. Project page and code: https://stevenlsw.github.io/Semi-Hand-Object
Contrastive Syn-to-Real Generalization
Apr 06, 2021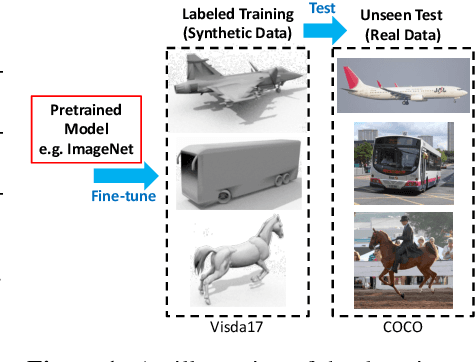
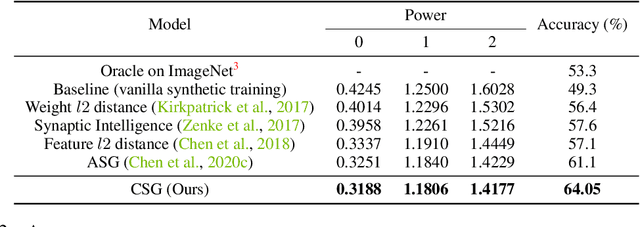
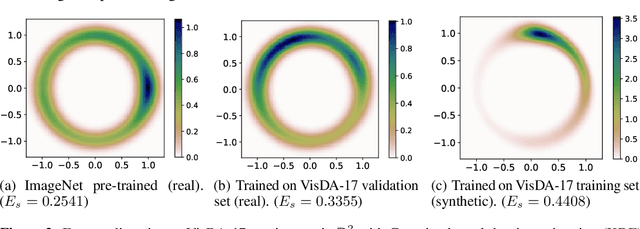
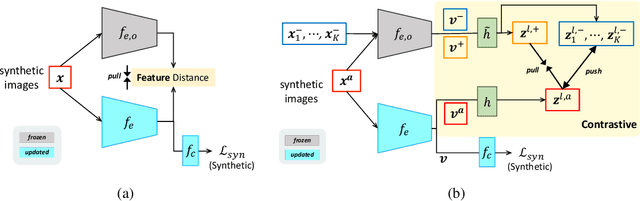
Training on synthetic data can be beneficial for label or data-scarce scenarios. However, synthetically trained models often suffer from poor generalization in real domains due to domain gaps. In this work, we make a key observation that the diversity of the learned feature embeddings plays an important role in the generalization performance. To this end, we propose contrastive synthetic-to-real generalization (CSG), a novel framework that leverages the pre-trained ImageNet knowledge to prevent overfitting to the synthetic domain, while promoting the diversity of feature embeddings as an inductive bias to improve generalization. In addition, we enhance the proposed CSG framework with attentional pooling (A-pool) to let the model focus on semantically important regions and further improve its generalization. We demonstrate the effectiveness of CSG on various synthetic training tasks, exhibiting state-of-the-art performance on zero-shot domain generalization.
Learning to Track Instances without Video Annotations
Apr 01, 2021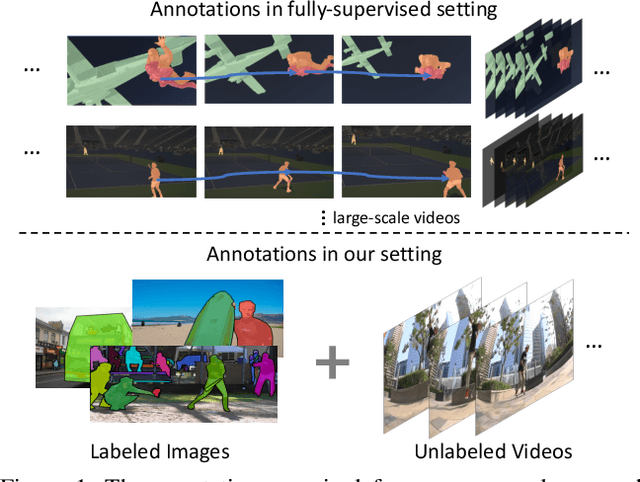

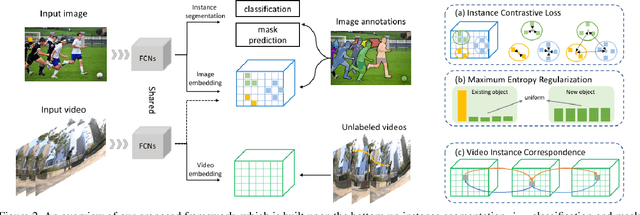

Tracking segmentation masks of multiple instances has been intensively studied, but still faces two fundamental challenges: 1) the requirement of large-scale, frame-wise annotation, and 2) the complexity of two-stage approaches. To resolve these challenges, we introduce a novel semi-supervised framework by learning instance tracking networks with only a labeled image dataset and unlabeled video sequences. With an instance contrastive objective, we learn an embedding to discriminate each instance from the others. We show that even when only trained with images, the learned feature representation is robust to instance appearance variations, and is thus able to track objects steadily across frames. We further enhance the tracking capability of the embedding by learning correspondence from unlabeled videos in a self-supervised manner. In addition, we integrate this module into single-stage instance segmentation and pose estimation frameworks, which significantly reduce the computational complexity of tracking compared to two-stage networks. We conduct experiments on the YouTube-VIS and PoseTrack datasets. Without any video annotation efforts, our proposed method can achieve comparable or even better performance than most fully-supervised methods.
Learning Continuous Image Representation with Local Implicit Image Function
Dec 16, 2020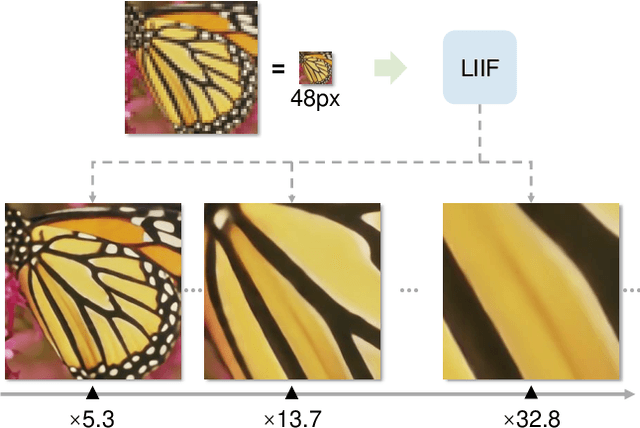
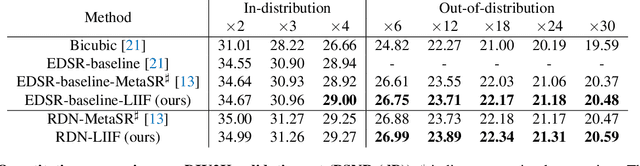
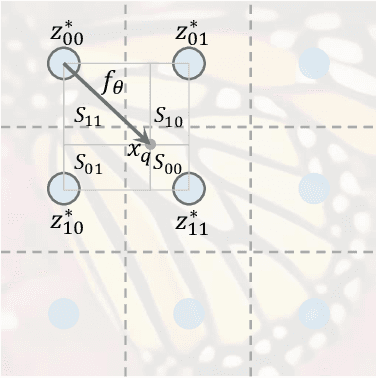
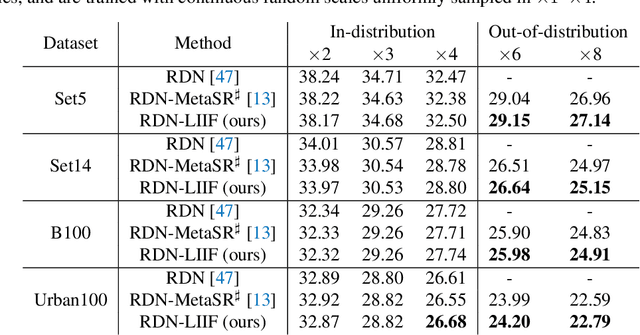
How to represent an image? While the visual world is presented in a continuous manner, machines store and see the images in a discrete way with 2D arrays of pixels. In this paper, we seek to learn a continuous representation for images. Inspired by the recent progress in 3D reconstruction with implicit function, we propose Local Implicit Image Function (LIIF), which takes an image coordinate and the 2D deep features around the coordinate as inputs, predicts the RGB value at a given coordinate as an output. Since the coordinates are continuous, LIIF can be presented in an arbitrary resolution. To generate the continuous representation for pixel-based images, we train an encoder and LIIF representation via a self-supervised task with super-resolution. The learned continuous representation can be presented in arbitrary resolution even extrapolate to $\times 30$ higher resolution, where the training tasks are not provided. We further show that LIIF representation builds a bridge between discrete and continuous representation in 2D, it naturally supports the learning tasks with size-varied image ground-truths and significantly outperforms the method with resizing the ground-truths. Our project page with code is at https://yinboc.github.io/liif/ .
Synthesizing Long-Term 3D Human Motion and Interaction in 3D Scenes
Dec 10, 2020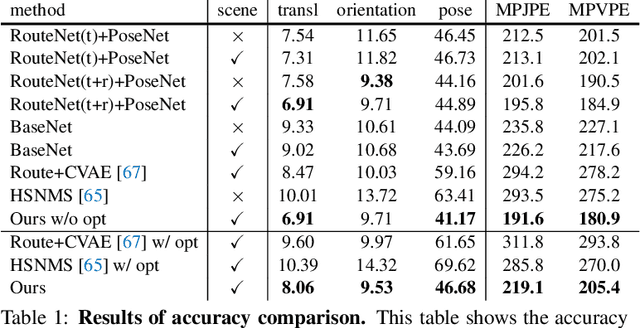

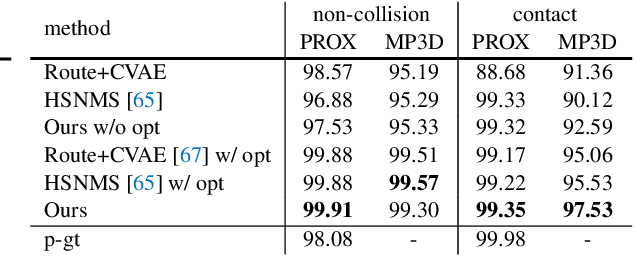
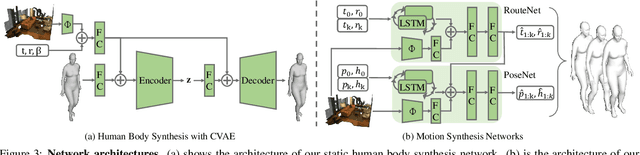
Synthesizing 3D human motion plays an important role in many graphics applications as well as understanding human activity. While many efforts have been made on generating realistic and natural human motion, most approaches neglect the importance of modeling human-scene interactions and affordance. On the other hand, affordance reasoning (e.g., standing on the floor or sitting on the chair) has mainly been studied with static human pose and gestures, and it has rarely been addressed with human motion. In this paper, we propose to bridge human motion synthesis and scene affordance reasoning. We present a hierarchical generative framework to synthesize long-term 3D human motion conditioning on the 3D scene structure. Building on this framework, we further enforce multiple geometry constraints between the human mesh and scene point clouds via optimization to improve realistic synthesis. Our experiments show significant improvements over previous approaches on generating natural and physically plausible human motion in a scene.