 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrasping with Chopsticks: Combating Covariate Shift in Model-free Imitation Learning for Fine Manipulation
Nov 13, 2020
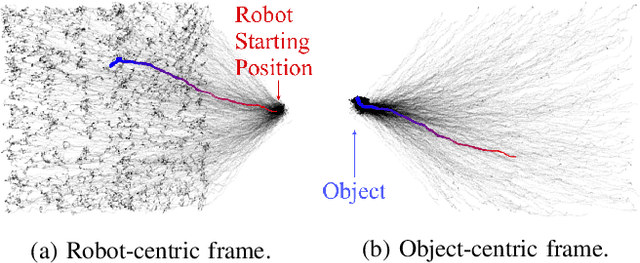
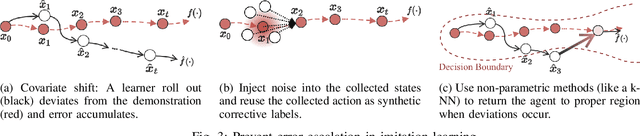

Billions of people use chopsticks, a simple yet versatile tool, for fine manipulation of everyday objects. The small, curved, and slippery tips of chopsticks pose a challenge for picking up small objects, making them a suitably complex test case. This paper leverages human demonstrations to develop an autonomous chopsticks-equipped robotic manipulator. Due to the lack of accurate models for fine manipulation, we explore model-free imitation learning, which traditionally suffers from the covariate shift phenomenon that causes poor generalization. We propose two approaches to reduce covariate shift, neither of which requires access to an interactive expert or a model, unlike previous approaches. First, we alleviate single-step prediction errors by applying an invariant operator to increase the data support at critical steps for grasping. Second, we generate synthetic corrective labels by adding bounded noise and combining parametric and non-parametric methods to prevent error accumulation. We demonstrate our methods on a real chopstick-equipped robot that we built, and observe the agent's success rate increase from 37.3% to 80%, which is comparable to the human expert performance of 82.6%.
Amodal 3D Reconstruction for Robotic Manipulation via Stability and Connectivity
Sep 28, 2020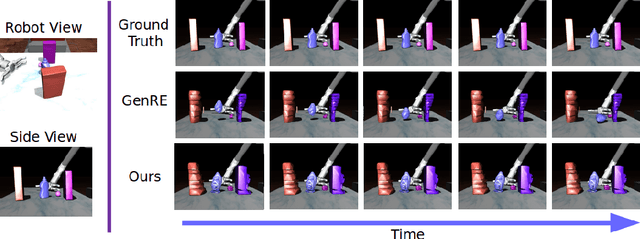
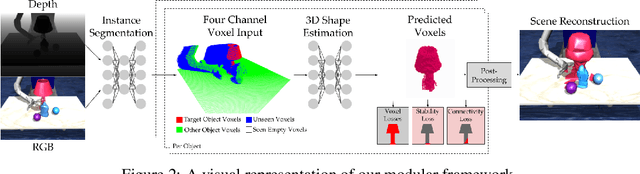
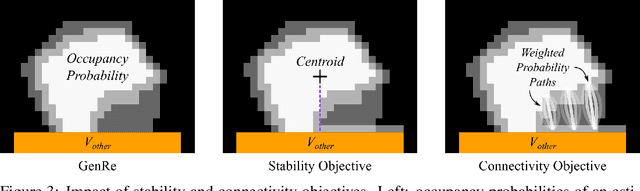
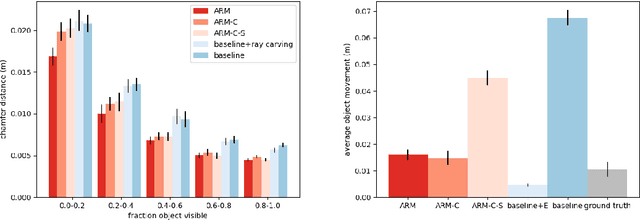
Learning-based 3D object reconstruction enables single- or few-shot estimation of 3D object models. For robotics, this holds the potential to allow model-based methods to rapidly adapt to novel objects and scenes. Existing 3D reconstruction techniques optimize for visual reconstruction fidelity, typically measured by chamfer distance or voxel IOU. We find that when applied to realistic, cluttered robotics environments, these systems produce reconstructions with low physical realism, resulting in poor task performance when used for model-based control. We propose ARM, an amodal 3D reconstruction system that introduces (1) a stability prior over object shapes, (2) a connectivity prior, and (3) a multi-channel input representation that allows for reasoning over relationships between groups of objects. By using these priors over the physical properties of objects, our system improves reconstruction quality not just by standard visual metrics, but also performance of model-based control on a variety of robotics manipulation tasks in challenging, cluttered environments. Code is available at github.com/wagnew3/ARM.
Lyceum: An efficient and scalable ecosystem for robot learning
Jan 21, 2020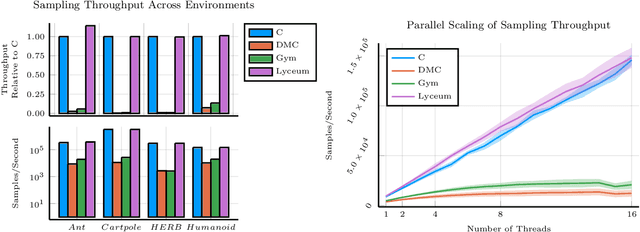

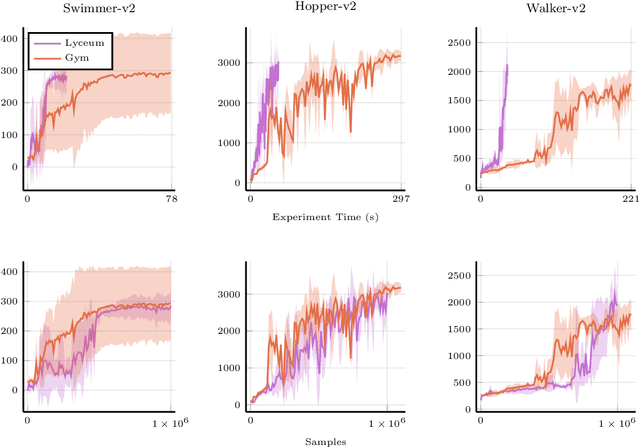
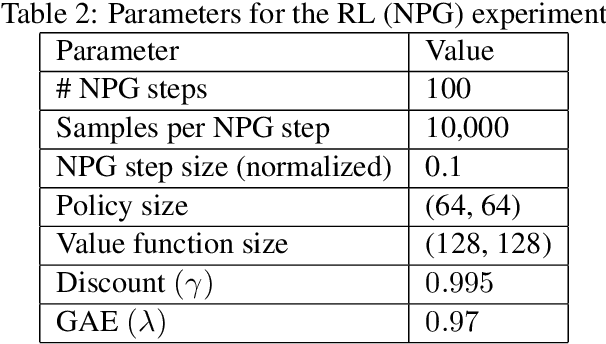
We introduce Lyceum, a high-performance computational ecosystem for robot learning. Lyceum is built on top of the Julia programming language and the MuJoCo physics simulator, combining the ease-of-use of a high-level programming language with the performance of native C. In addition, Lyceum has a straightforward API to support parallel computation across multiple cores and machines. Overall, depending on the complexity of the environment, Lyceum is 5-30x faster compared to other popular abstractions like OpenAI's Gym and DeepMind's dm-control. This substantially reduces training time for various reinforcement learning algorithms; and is also fast enough to support real-time model predictive control through MuJoCo. The code, tutorials, and demonstration videos can be found at: www.lyceum.ml.
Mo' States Mo' Problems: Emergency Stop Mechanisms from Observation
Dec 03, 2019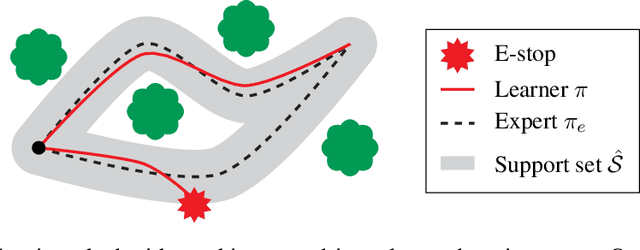
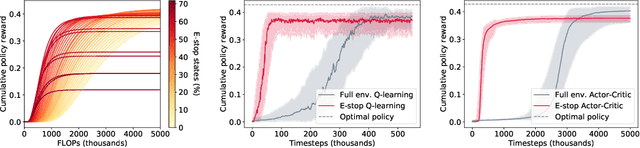
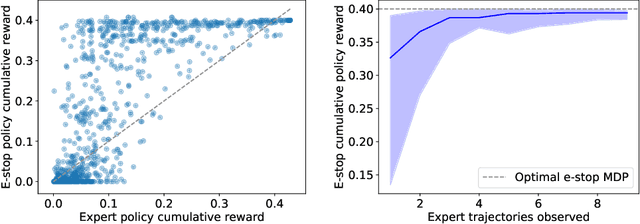
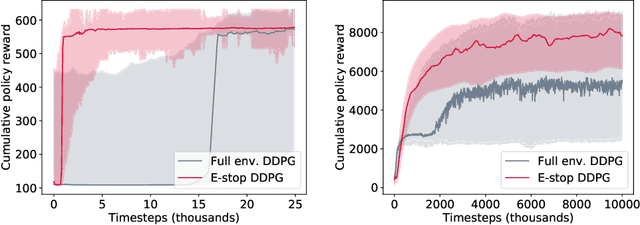
In many environments, only a relatively small subset of the complete state space is necessary in order to accomplish a given task. We develop a simple technique using emergency stops (e-stops) to exploit this phenomenon. Using e-stops significantly improves sample complexity by reducing the amount of required exploration, while retaining a performance bound that efficiently trades off the rate of convergence with a small asymptotic sub-optimality gap. We analyze the regret behavior of e-stops and present empirical results in discrete and continuous settings demonstrating that our reset mechanism can provide order-of-magnitude speedups on top of existing reinforcement learning methods.
Imitation Learning as $f$-Divergence Minimization
May 30, 2019

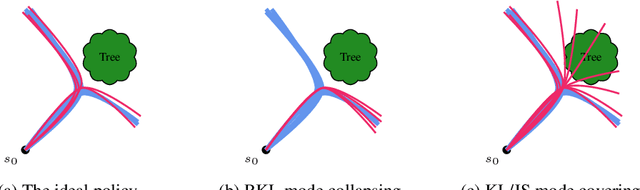
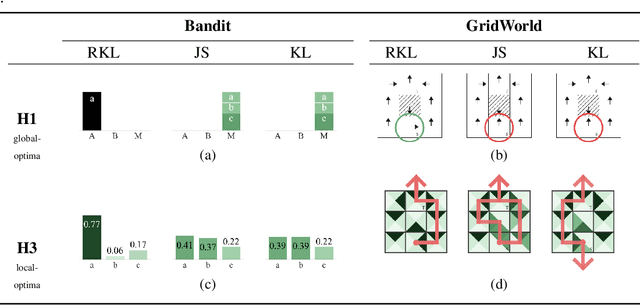
We address the problem of imitation learning with multi-modal demonstrations. Instead of attempting to learn all modes, we argue that in many tasks it is sufficient to imitate any one of them. We show that the state-of-the-art methods such as GAIL and behavior cloning, due to their choice of loss function, often incorrectly interpolate between such modes. Our key insight is to minimize the right divergence between the learner and the expert state-action distributions, namely the reverse KL divergence or I-projection. We propose a general imitation learning framework for estimating and minimizing any f-Divergence. By plugging in different divergences, we are able to recover existing algorithms such as Behavior Cloning (Kullback-Leibler), GAIL (Jensen Shannon) and Dagger (Total Variation). Empirical results show that our approximate I-projection technique is able to imitate multi-modal behaviors more reliably than GAIL and behavior cloning.
Generalized Lazy Search for Robot Motion Planning: Interleaving Search and Edge Evaluation via Event-based Toggles
Apr 08, 2019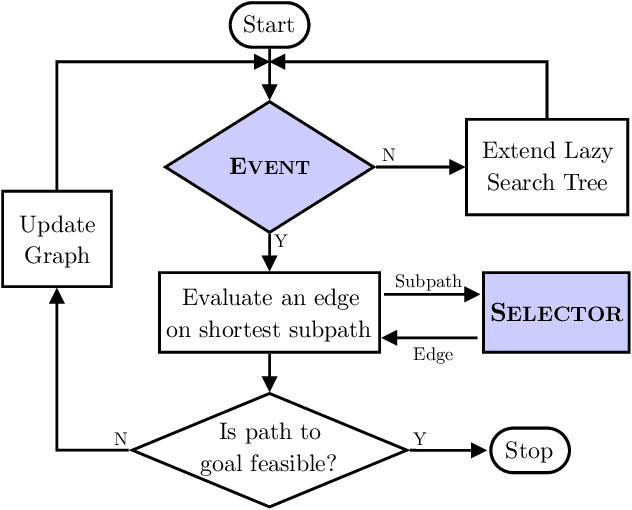

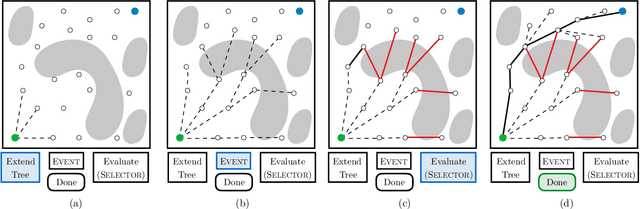
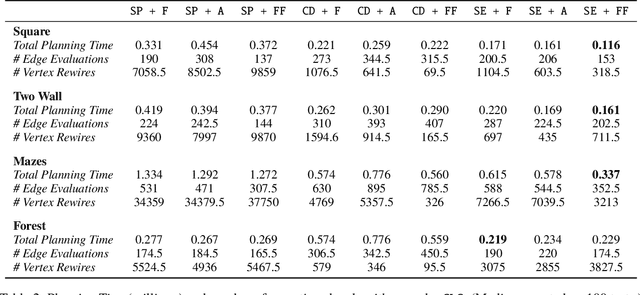
Lazy search algorithms can efficiently solve problems where edge evaluation is the bottleneck in computation, as is the case for robotic motion planning. The optimal algorithm in this class, LazySP, lazily restricts edge evaluation to only the shortest path. Doing so comes at the expense of search effort, i.e., LazySP must recompute the search tree every time an edge is found to be invalid. This becomes prohibitively expensive when dealing with large graphs or highly cluttered environments. Our key insight is the need to balance both edge evaluation and search effort to minimize the total planning time. Our contribution is two-fold. First, we propose a framework, Generalized Lazy Search (GLS), that seamlessly toggles between search and evaluation to prevent wasted efforts. We show that for a choice of toggle, GLS is provably more efficient than LazySP. Second, we leverage prior experience of edge probabilities to derive GLS policies that minimize expected planning time. We show that GLS equipped with such priors significantly outperforms competitive baselines for many simulated environments in R2, SE(2) and 7-DoF manipulation.
Improving Robot Success Detection using Static Object Data
Apr 02, 2019
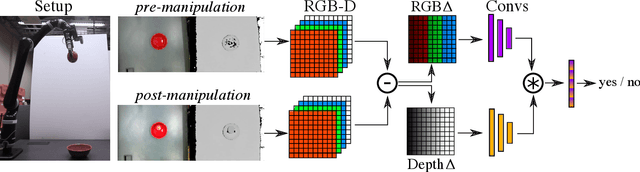
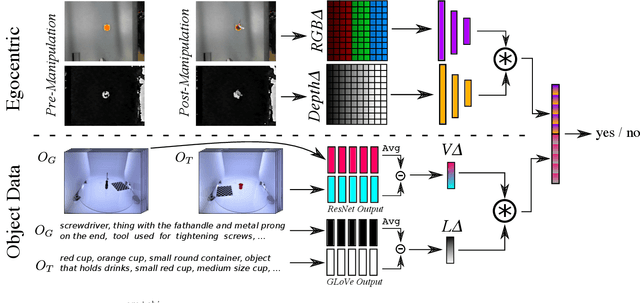
We use static object data to improve success detection for stacking objects on and nesting objects in one another. Such actions are necessary for certain robotics tasks, e.g., clearing a dining table or packing a warehouse bin. However, using an RGB-D camera to detect success can be insufficient: same-colored objects can be difficult to differentiate, and reflective silverware cause noisy depth camera perception. We show that adding static data about the objects themselves improves the performance of an end-to-end pipeline for classifying action outcomes. Images of the objects, and language expressions describing them, encode prior geometry, shape, and size information that refine classification accuracy. We collect over 13 hours of egocentric manipulation data for training a model to reason about whether a robot successfully placed unseen objects in or on one another. The model achieves up to a 57% absolute gain over the task baseline on pairs of previously unseen objects.
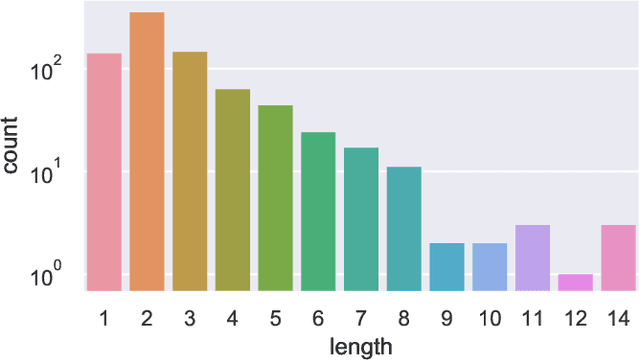
Tactical Rewind: Self-Correction via Backtracking in Vision-and-Language Navigation
Apr 02, 2019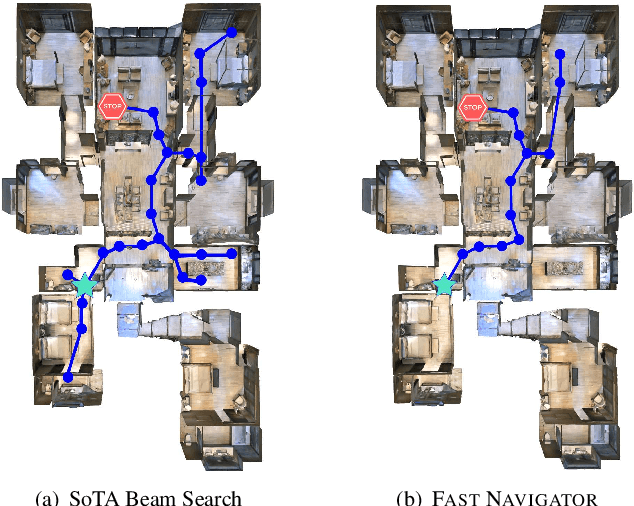
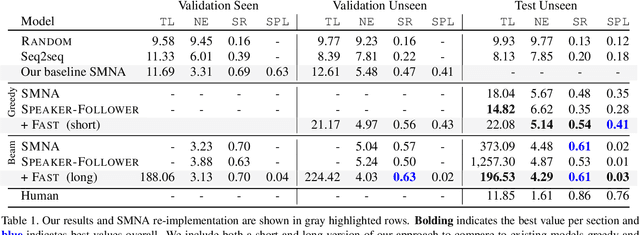
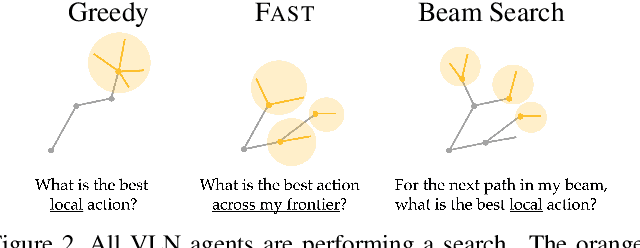
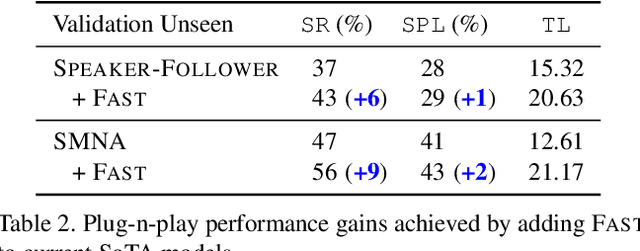
We present the Frontier Aware Search with backTracking (FAST) Navigator, a general framework for action decoding, that achieves state-of-the-art results on the Room-to-Room (R2R) Vision-and-Language navigation challenge of Anderson et. al. (2018). Given a natural language instruction and photo-realistic image views of a previously unseen environment, the agent was tasked with navigating from source to target location as quickly as possible. While all current approaches make local action decisions or score entire trajectories using beam search, ours balances local and global signals when exploring an unobserved environment. Importantly, this lets us act greedily but use global signals to backtrack when necessary. Applying FAST framework to existing state-of-the-art models achieved a 17% relative gain, an absolute 6% gain on Success rate weighted by Path Length (SPL).
Learning Configuration Space Belief Model from Collision Checks for Motion Planning
Feb 10, 2019
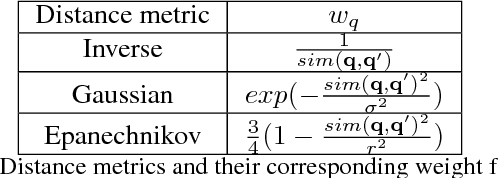
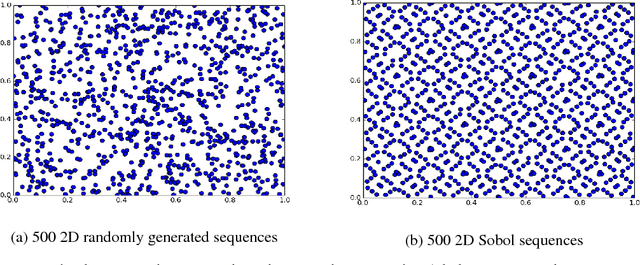
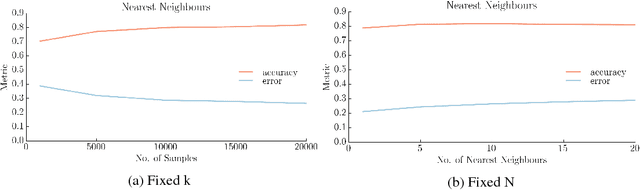
For motion planning in high dimensional configuration spaces, a significant computational bottleneck is collision detection. Our aim is to reduce the expected number of collision checks by creating a belief model of the configuration space using results from collision tests. We assume the robot's configuration space to be a continuous ambient space whereby neighbouring points tend to share the same collision state. This enables us to formulate a probabilistic model that assigns to unevaluated configurations a belief estimate of being collision-free. We have presented a detailed comparative analysis of various kNN methods and distance metrics used to evaluate C-space belief. We have also proposed a weighting matrix in C-space to improve the performance of kNN methods. Moreover, we have proposed a topological method that exploits the higher order structure of the C-space to generate a belief model. Our results indicate that our proposed topological method outperforms kNN methods by achieving higher model accuracy while being computationally efficient.
The Assistive Multi-Armed Bandit
Jan 24, 2019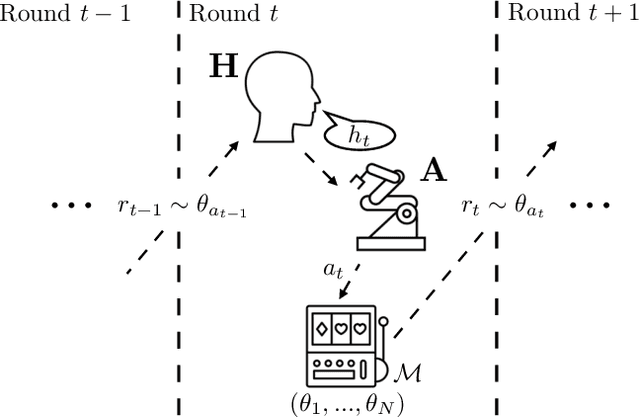
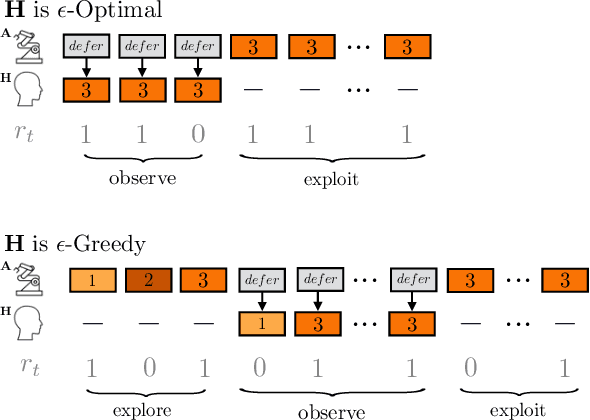
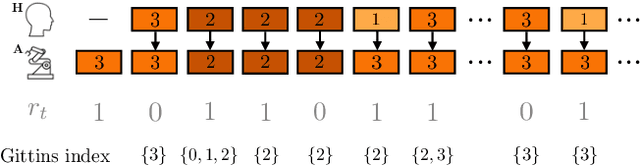
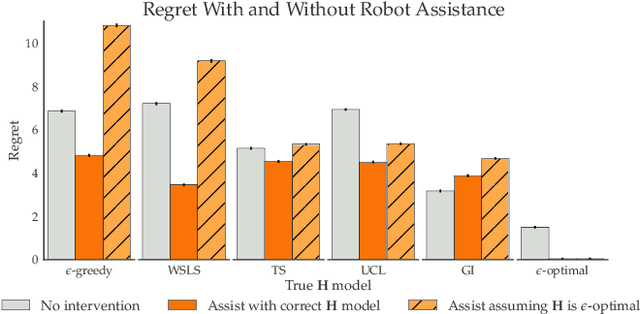
Learning preferences implicit in the choices humans make is a well studied problem in both economics and computer science. However, most work makes the assumption that humans are acting (noisily) optimally with respect to their preferences. Such approaches can fail when people are themselves learning about what they want. In this work, we introduce the assistive multi-armed bandit, where a robot assists a human playing a bandit task to maximize cumulative reward. In this problem, the human does not know the reward function but can learn it through the rewards received from arm pulls; the robot only observes which arms the human pulls but not the reward associated with each pull. We offer sufficient and necessary conditions for successfully assisting the human in this framework. Surprisingly, better human performance in isolation does not necessarily lead to better performance when assisted by the robot: a human policy can do better by effectively communicating its observed rewards to the robot. We conduct proof-of-concept experiments that support these results. We see this work as contributing towards a theory behind algorithms for human-robot interaction.