 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobileInst: Video Instance Segmentation on the Mobile
Mar 30, 2023



Although recent approaches aiming for video instance segmentation have achieved promising results, it is still difficult to employ those approaches for real-world applications on mobile devices, which mainly suffer from (1) heavy computation and memory cost and (2) complicated heuristics for tracking objects. To address those issues, we present MobileInst, a lightweight and mobile-friendly framework for video instance segmentation on mobile devices. Firstly, MobileInst adopts a mobile vision transformer to extract multi-level semantic features and presents an efficient query-based dual-transformer instance decoder for mask kernels and a semantic-enhanced mask decoder to generate instance segmentation per frame. Secondly, MobileInst exploits simple yet effective kernel reuse and kernel association to track objects for video instance segmentation. Further, we propose temporal query passing to enhance the tracking ability for kernels. We conduct experiments on COCO and YouTube-VIS datasets to demonstrate the superiority of MobileInst and evaluate the inference latency on a mobile CPU core of Qualcomm Snapdragon-778G, without other methods of acceleration. On the COCO dataset, MobileInst achieves 30.5 mask AP and 176 ms on the mobile CPU, which reduces the latency by 50% compared to the previous SOTA. For video instance segmentation, MobileInst achieves 35.0 AP on YouTube-VIS 2019 and 30.1 AP on YouTube-VIS 2021. Code will be available to facilitate real-world applications and future research.
Masked Visual Reconstruction in Language Semantic Space
Jan 17, 2023



Both masked image modeling (MIM) and natural language supervision have facilitated the progress of transferable visual pre-training. In this work, we seek the synergy between two paradigms and study the emerging properties when MIM meets natural language supervision. To this end, we present a novel masked visual Reconstruction In Language semantic Space (RILS) pre-training framework, in which sentence representations, encoded by the text encoder, serve as prototypes to transform the vision-only signals into patch-sentence probabilities as semantically meaningful MIM reconstruction targets. The vision models can therefore capture useful components with structured information by predicting proper semantic of masked tokens. Better visual representations could, in turn, improve the text encoder via the image-text alignment objective, which is essential for the effective MIM target transformation. Extensive experimental results demonstrate that our method not only enjoys the best of previous MIM and CLIP but also achieves further improvements on various tasks due to their mutual benefits. RILS exhibits advanced transferability on downstream classification, detection, and segmentation, especially for low-shot regimes. Code will be made available at https://github.com/hustvl/RILS.
Masked Image Modeling with Denoising Contrast
May 19, 2022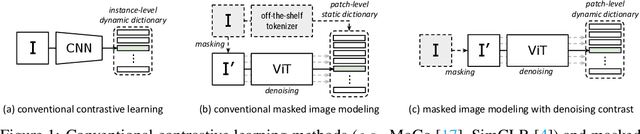
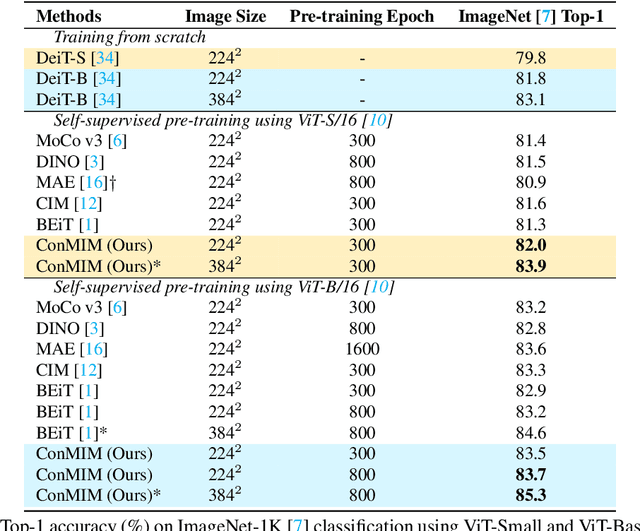
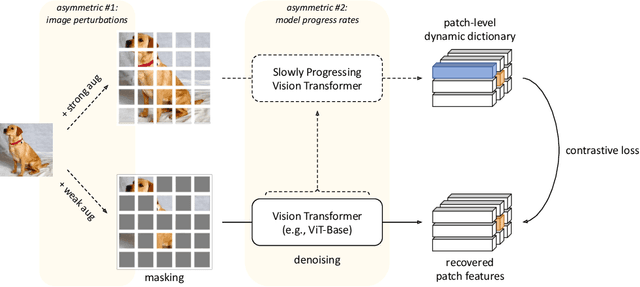

Since the development of self-supervised visual representation learning from contrastive learning to masked image modeling, there is no significant difference in essence, that is, how to design proper pretext tasks for vision dictionary look-up. Masked image modeling recently dominates this line of research with state-of-the-art performance on vision Transformers, where the core is to enhance the patch-level visual context capturing of the network via denoising auto-encoding mechanism. Rather than tailoring image tokenizers with extra training stages as in previous works, we unleash the great potential of contrastive learning on denoising auto-encoding and introduce a new pre-training method, ConMIM, to produce simple intra-image inter-patch contrastive constraints as the learning objectives for masked patch prediction. We further strengthen the denoising mechanism with asymmetric designs, including image perturbations and model progress rates, to improve the network pre-training. ConMIM-pretrained vision Transformers with various scales achieve promising results on downstream image classification, semantic segmentation, object detection, and instance segmentation tasks.
Temporally Efficient Vision Transformer for Video Instance Segmentation
Apr 18, 2022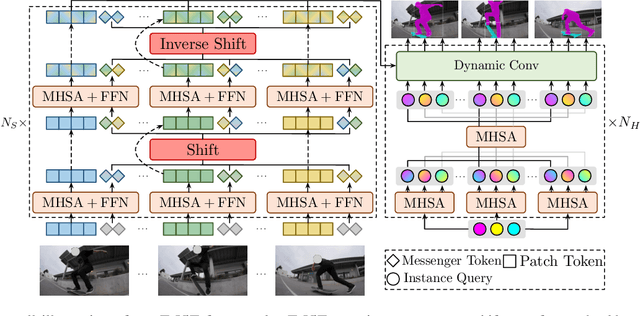
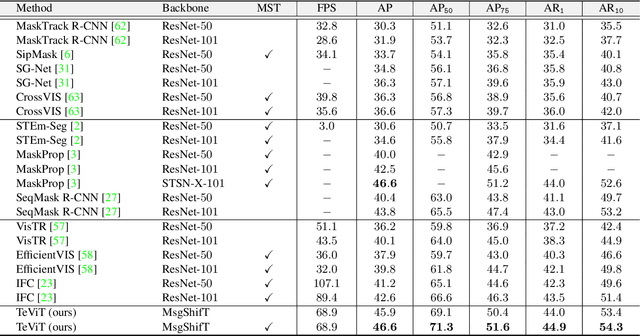
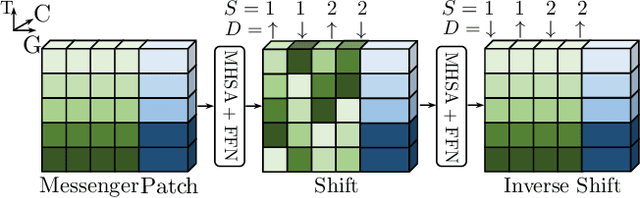
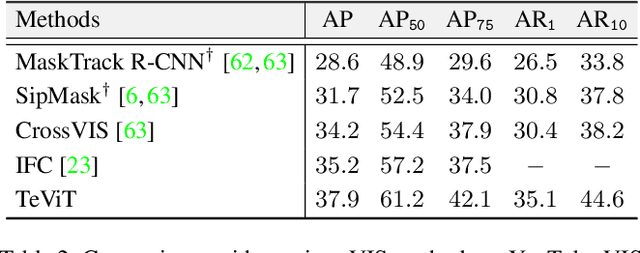
Recently vision transformer has achieved tremendous success on image-level visual recognition tasks. To effectively and efficiently model the crucial temporal information within a video clip, we propose a Temporally Efficient Vision Transformer (TeViT) for video instance segmentation (VIS). Different from previous transformer-based VIS methods, TeViT is nearly convolution-free, which contains a transformer backbone and a query-based video instance segmentation head. In the backbone stage, we propose a nearly parameter-free messenger shift mechanism for early temporal context fusion. In the head stages, we propose a parameter-shared spatiotemporal query interaction mechanism to build the one-to-one correspondence between video instances and queries. Thus, TeViT fully utilizes both framelevel and instance-level temporal context information and obtains strong temporal modeling capacity with negligible extra computational cost. On three widely adopted VIS benchmarks, i.e., YouTube-VIS-2019, YouTube-VIS-2021, and OVIS, TeViT obtains state-of-the-art results and maintains high inference speed, e.g., 46.6 AP with 68.9 FPS on YouTube-VIS-2019. Code is available at https://github.com/hustvl/TeViT.
Unleashing Vanilla Vision Transformer with Masked Image Modeling for Object Detection
Apr 06, 2022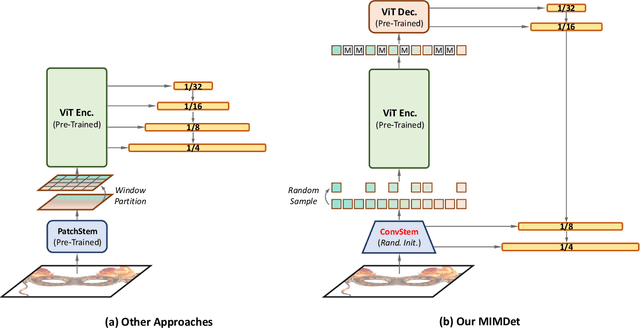
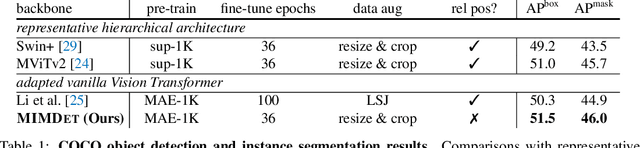
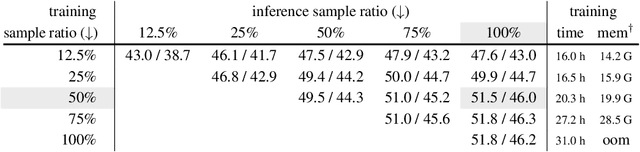

We present an approach to efficiently and effectively adapt a masked image modeling (MIM) pre-trained vanilla Vision Transformer (ViT) for object detection, which is based on our two novel observations: (i) A MIM pre-trained vanilla ViT can work surprisingly well in the challenging object-level recognition scenario even with random sampled partial observations, e.g., only 25% ~ 50% of the input sequence. (ii) In order to construct multi-scale representations for object detection, a random initialized compact convolutional stem supplants the pre-trained large kernel patchify stem, and its intermediate features can naturally serve as the higher resolution inputs of a feature pyramid without upsampling. While the pre-trained ViT is only regarded as the third-stage of our detector's backbone instead of the whole feature extractor, resulting in a ConvNet-ViT hybrid architecture. The proposed detector, named MIMDet, enables a MIM pre-trained vanilla ViT to outperform hierarchical Swin Transformer by 2.3 box AP and 2.5 mask AP on COCO, and achieve even better results compared with other adapted vanilla ViT using a more modest fine-tuning recipe while converging 2.8x faster. Code and pre-trained models are available at \url{https://github.com/hustvl/MIMDet}.
Relational Surrogate Loss Learning
Feb 26, 2022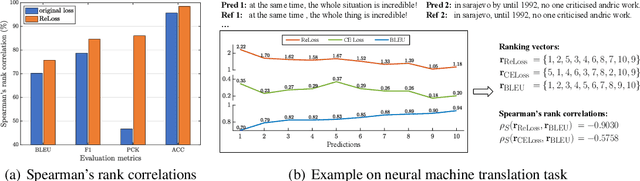
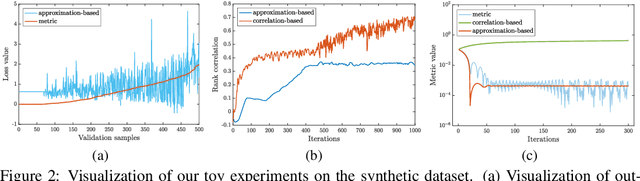
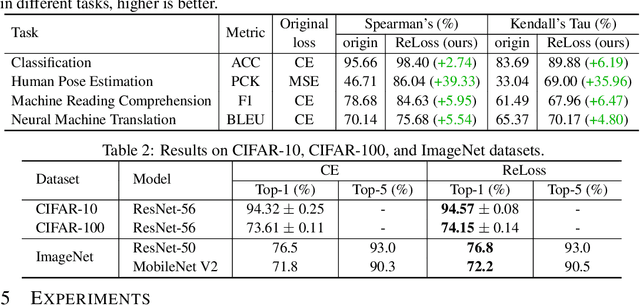
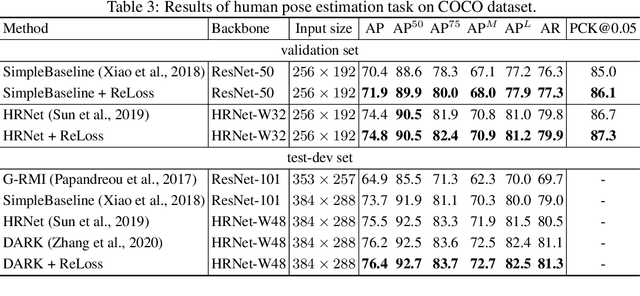
Evaluation metrics in machine learning are often hardly taken as loss functions, as they could be non-differentiable and non-decomposable, e.g., average precision and F1 score. This paper aims to address this problem by revisiting the surrogate loss learning, where a deep neural network is employed to approximate the evaluation metrics. Instead of pursuing an exact recovery of the evaluation metric through a deep neural network, we are reminded of the purpose of the existence of these evaluation metrics, which is to distinguish whether one model is better or worse than another. In this paper, we show that directly maintaining the relation of models between surrogate losses and metrics suffices, and propose a rank correlation-based optimization method to maximize this relation and learn surrogate losses. Compared to previous works, our method is much easier to optimize and enjoys significant efficiency and performance gains. Extensive experiments show that our method achieves improvements on various tasks including image classification and neural machine translation, and even outperforms state-of-the-art methods on human pose estimation and machine reading comprehension tasks. Code is available at: https://github.com/hunto/ReLoss.
Tracking Instances as Queries
Jun 23, 2021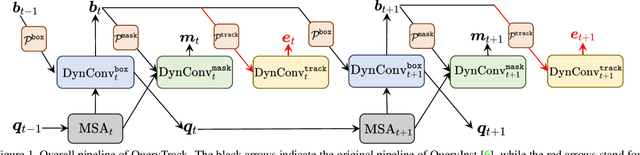

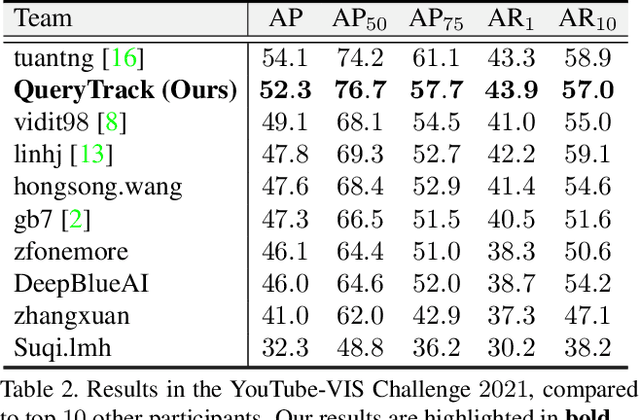
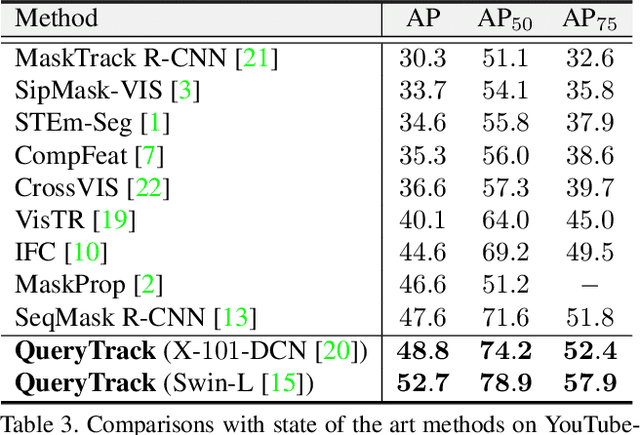
Recently, query based deep networks catch lots of attention owing to their end-to-end pipeline and competitive results on several fundamental computer vision tasks, such as object detection, semantic segmentation, and instance segmentation. However, how to establish a query based video instance segmentation (VIS) framework with elegant architecture and strong performance remains to be settled. In this paper, we present \textbf{QueryTrack} (i.e., tracking instances as queries), a unified query based VIS framework fully leveraging the intrinsic one-to-one correspondence between instances and queries in QueryInst. The proposed method obtains 52.7 / 52.3 AP on YouTube-VIS-2019 / 2021 datasets, which wins the 2-nd place in the YouTube-VIS Challenge at CVPR 2021 \textbf{with a single online end-to-end model, single scale testing \& modest amount of training data}. We also provide QueryTrack-ResNet-50 baseline results on YouTube-VIS-2021 val set as references for the VIS community.
* Preprint. Work in progress
Instances as Queries
May 23, 2021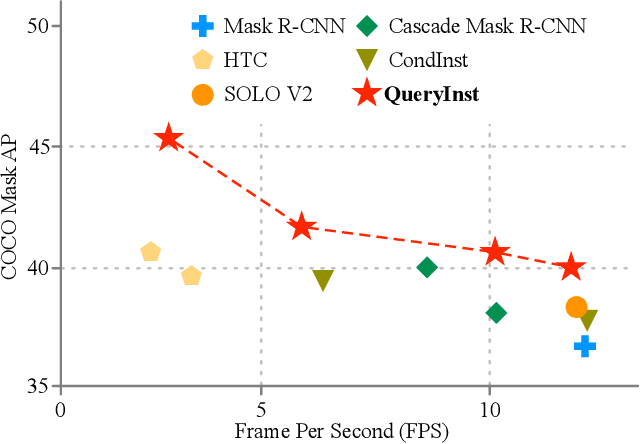
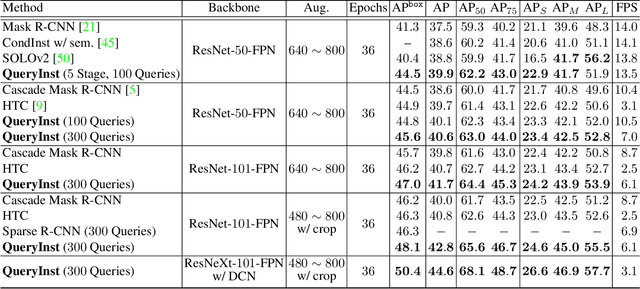
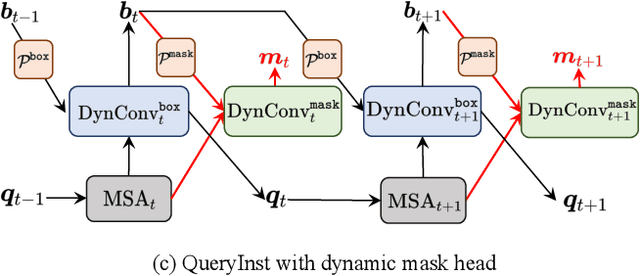

Recently, query based object detection frameworks achieve comparable performance with previous state-of-the-art object detectors. However, how to fully leverage such frameworks to perform instance segmentation remains an open problem. In this paper, we present QueryInst (Instances as Queries), a query based instance segmentation method driven by parallel supervision on dynamic mask heads. The key insight of QueryInst is to leverage the intrinsic one-to-one correspondence in object queries across different stages, as well as one-to-one correspondence between mask RoI features and object queries in the same stage. This approach eliminates the explicit multi-stage mask head connection and the proposal distribution inconsistency issues inherent in non-query based multi-stage instance segmentation methods. We conduct extensive experiments on three challenging benchmarks, i.e., COCO, CityScapes, and YouTube-VIS to evaluate the effectiveness of QueryInst in instance segmentation and video instance segmentation (VIS) task. Specifically, using ResNet-101-FPN backbone, QueryInst obtains 48.1 box AP and 42.8 mask AP on COCO test-dev, which is 2 points higher than HTC in terms of both box AP and mask AP, while runs 2.4 times faster. For video instance segmentation, QueryInst achieves the best performance among all online VIS approaches and strikes a decent speed-accuracy trade-off. Code is available at \url{https://github.com/hustvl/QueryInst}.
Crossover Learning for Fast Online Video Instance Segmentation
Apr 13, 2021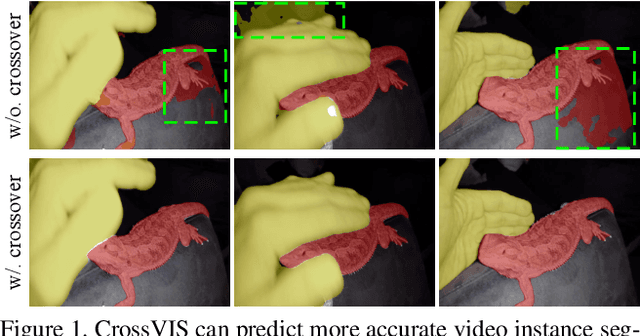
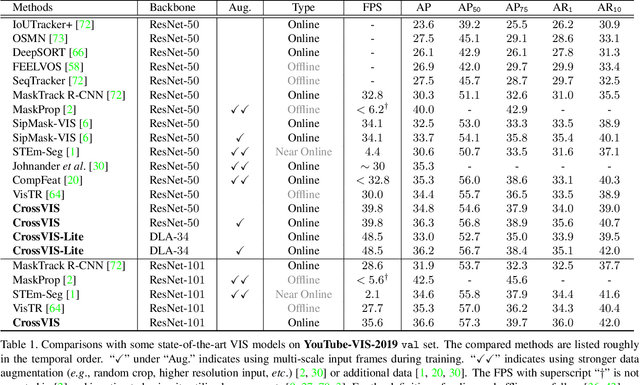
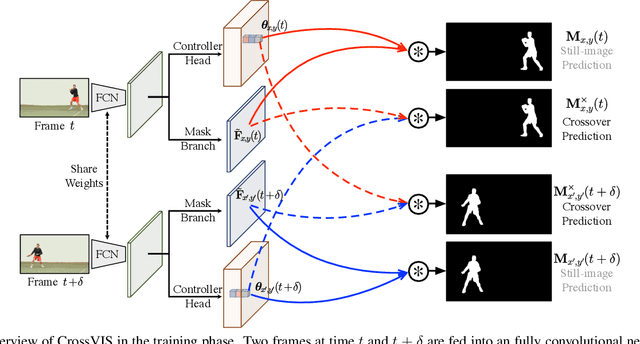
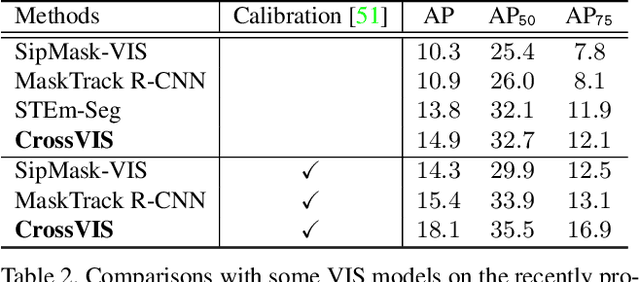
Modeling temporal visual context across frames is critical for video instance segmentation (VIS) and other video understanding tasks. In this paper, we propose a fast online VIS model named CrossVIS. For temporal information modeling in VIS, we present a novel crossover learning scheme that uses the instance feature in the current frame to pixel-wisely localize the same instance in other frames. Different from previous schemes, crossover learning does not require any additional network parameters for feature enhancement. By integrating with the instance segmentation loss, crossover learning enables efficient cross-frame instance-to-pixel relation learning and brings cost-free improvement during inference. Besides, a global balanced instance embedding branch is proposed for more accurate and more stable online instance association. We conduct extensive experiments on three challenging VIS benchmarks, \ie, YouTube-VIS-2019, OVIS, and YouTube-VIS-2021 to evaluate our methods. To our knowledge, CrossVIS achieves state-of-the-art performance among all online VIS methods and shows a decent trade-off between latency and accuracy. Code will be available to facilitate future research.