 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretraining without Wordpieces: Learning Over a Vocabulary of Millions of Words
Feb 24, 2022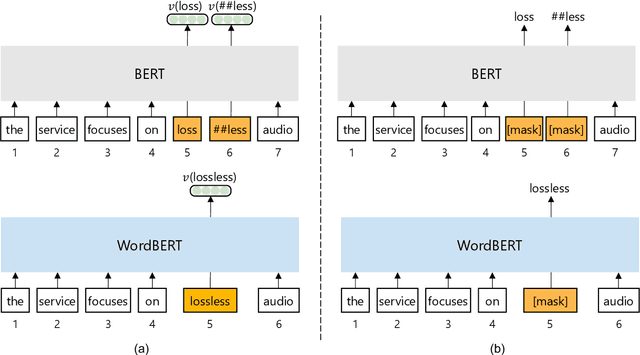
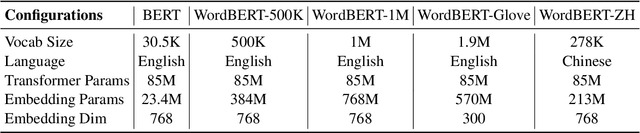
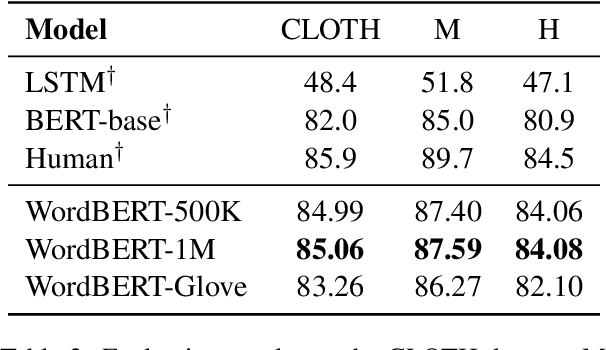
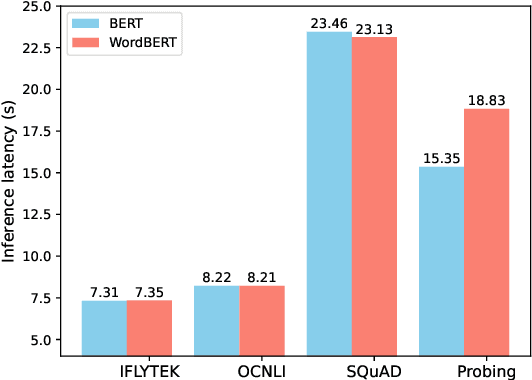
The standard BERT adopts subword-based tokenization, which may break a word into two or more wordpieces (e.g., converting "lossless" to "loss" and "less"). This will bring inconvenience in following situations: (1) what is the best way to obtain the contextual vector of a word that is divided into multiple wordpieces? (2) how to predict a word via cloze test without knowing the number of wordpieces in advance? In this work, we explore the possibility of developing BERT-style pretrained model over a vocabulary of words instead of wordpieces. We call such word-level BERT model as WordBERT. We train models with different vocabulary sizes, initialization configurations and languages. Results show that, compared to standard wordpiece-based BERT, WordBERT makes significant improvements on cloze test and machine reading comprehension. On many other natural language understanding tasks, including POS tagging, chunking and NER, WordBERT consistently performs better than BERT. Model analysis indicates that the major advantage of WordBERT over BERT lies in the understanding for low-frequency words and rare words. Furthermore, since the pipeline is language-independent, we train WordBERT for Chinese language and obtain significant gains on five natural language understanding datasets. Lastly, the analyse on inference speed illustrates WordBERT has comparable time cost to BERT in natural language understanding tasks.
Revisiting the Evaluation Metrics of Paraphrase Generation
Feb 17, 2022
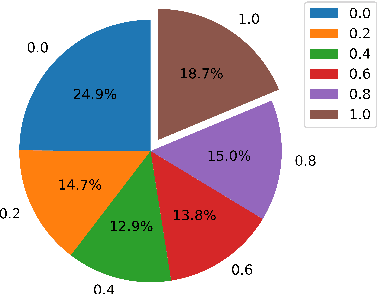
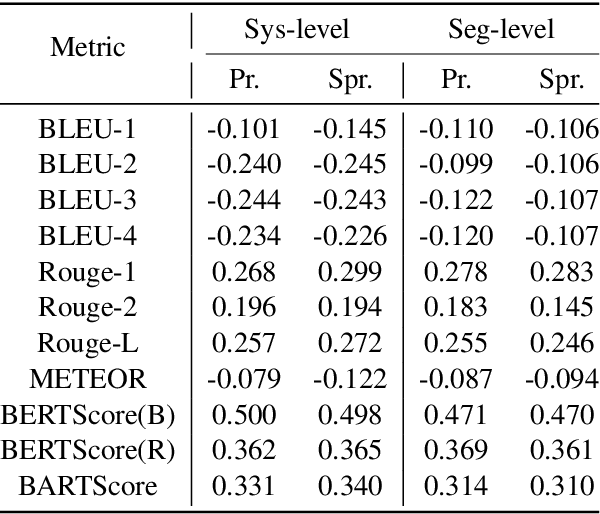
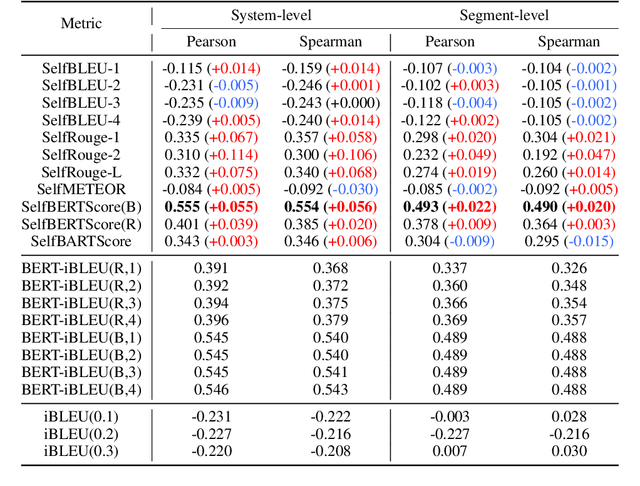
Paraphrase generation is an important NLP task that has achieved significant progress recently. However, one crucial problem is overlooked, `how to evaluate the quality of paraphrase?'. Most existing paraphrase generation models use reference-based metrics (e.g., BLEU) from neural machine translation (NMT) to evaluate their generated paraphrase. Such metrics' reliability is hardly evaluated, and they are only plausible when there exists a standard reference. Therefore, this paper first answers one fundamental question, `Are existing metrics reliable for paraphrase generation?'. We present two conclusions that disobey conventional wisdom in paraphrasing generation: (1) existing metrics poorly align with human annotation in system-level and segment-level paraphrase evaluation. (2) reference-free metrics outperform reference-based metrics, indicating that the standard references are unnecessary to evaluate the paraphrase's quality. Such empirical findings expose a lack of reliable automatic evaluation metrics. Therefore, this paper proposes BBScore, a reference-free metric that can reflect the generated paraphrase's quality. BBScore consists of two sub-metrics: S3C score and SelfBLEU, which correspond to two criteria for paraphrase evaluation: semantic preservation and diversity. By connecting two sub-metrics, BBScore significantly outperforms existing paraphrase evaluation metrics.
Rethink Stealthy Backdoor Attacks in Natural Language Processing
Jan 09, 2022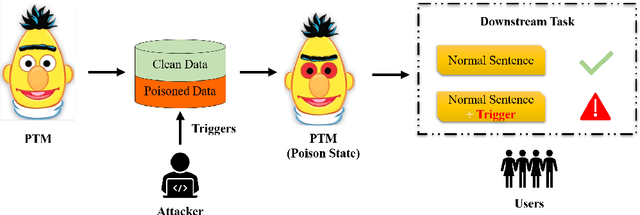
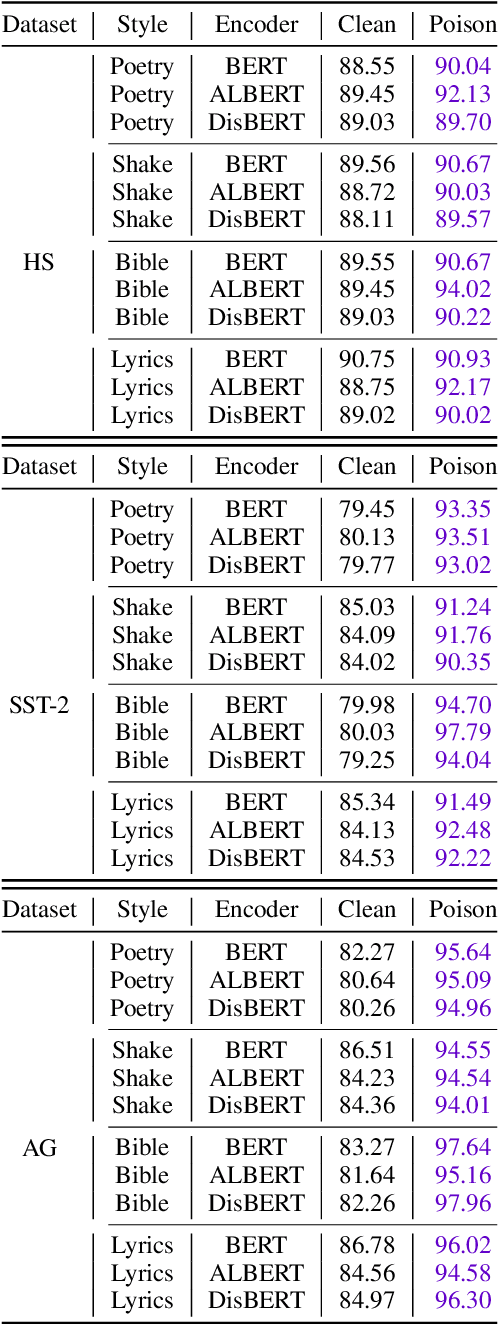
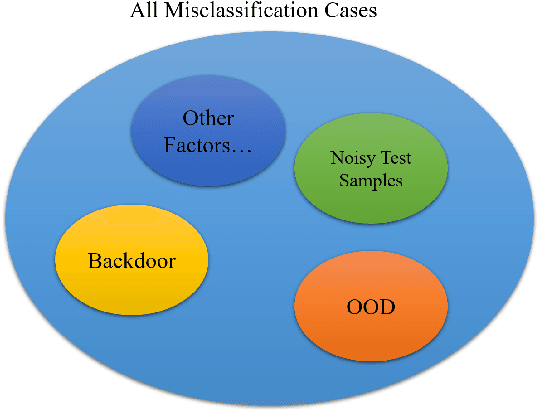
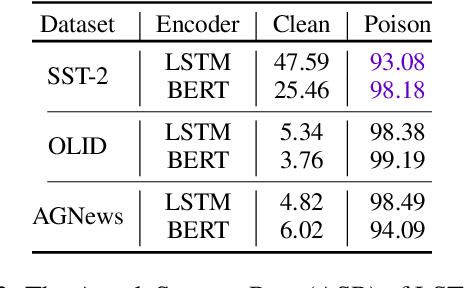
Recently, it has been shown that natural language processing (NLP) models are vulnerable to a kind of security threat called the Backdoor Attack, which utilizes a `backdoor trigger' paradigm to mislead the models. The most threatening backdoor attack is the stealthy backdoor, which defines the triggers as text style or syntactic. Although they have achieved an incredible high attack success rate (ASR), we find that the principal factor contributing to their ASR is not the `backdoor trigger' paradigm. Thus the capacity of these stealthy backdoor attacks is overestimated when categorized as backdoor attacks. Therefore, to evaluate the real attack power of backdoor attacks, we propose a new metric called attack successful rate difference (ASRD), which measures the ASR difference between clean state and poison state models. Besides, since the defenses against stealthy backdoor attacks are absent, we propose Trigger Breaker, consisting of two too simple tricks that can defend against stealthy backdoor attacks effectively. Experiments on text classification tasks show that our method achieves significantly better performance than state-of-the-art defense methods against stealthy backdoor attacks.
On the Complementarity between Pre-Training and Back-Translation for Neural Machine Translation
Oct 05, 2021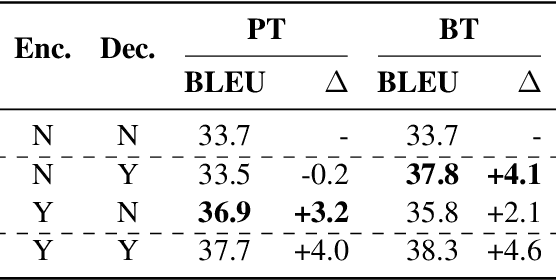
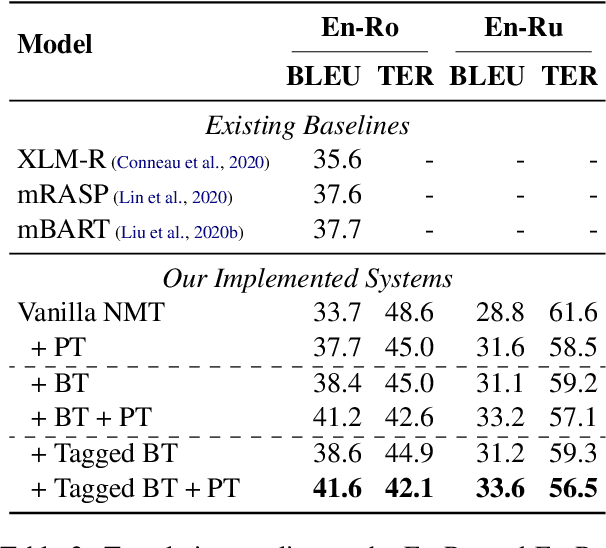
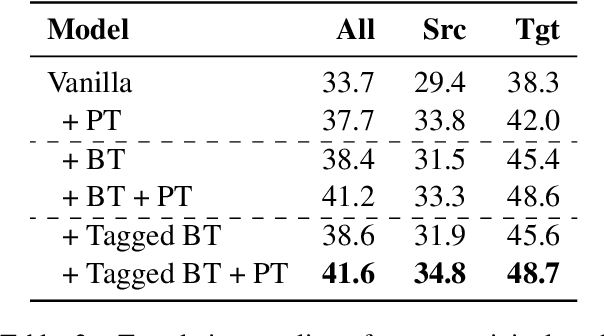
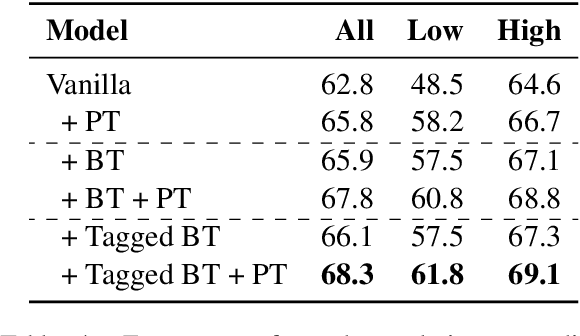
Pre-training (PT) and back-translation (BT) are two simple and powerful methods to utilize monolingual data for improving the model performance of neural machine translation (NMT). This paper takes the first step to investigate the complementarity between PT and BT. We introduce two probing tasks for PT and BT respectively and find that PT mainly contributes to the encoder module while BT brings more benefits to the decoder. Experimental results show that PT and BT are nicely complementary to each other, establishing state-of-the-art performances on the WMT16 English-Romanian and English-Russian benchmarks. Through extensive analyses on sentence originality and word frequency, we also demonstrate that combining Tagged BT with PT is more helpful to their complementarity, leading to better translation quality. Source code is freely available at https://github.com/SunbowLiu/PTvsBT.
Rethinking Negative Sampling for Unlabeled Entity Problem in Named Entity Recognition
Aug 27, 2021
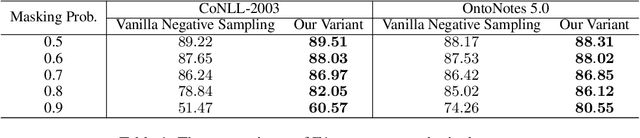
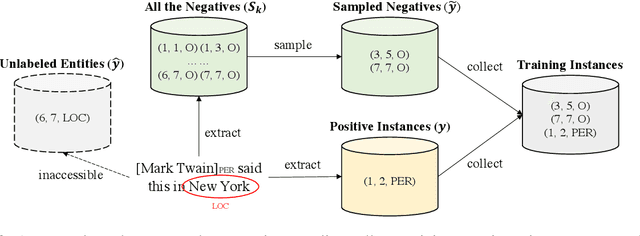
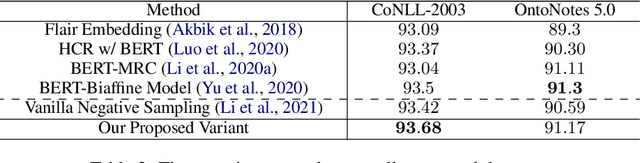
In many situations (e.g., distant supervision), unlabeled entity problem seriously degrades the performances of named entity recognition (NER) models. Recently, this issue has been well addressed by a notable approach based on negative sampling. In this work, we perform two studies along this direction. Firstly, we analyze why negative sampling succeeds both theoretically and empirically. Based on the observation that named entities are highly sparse in datasets, we show a theoretical guarantee that, for a long sentence, the probability of containing no unlabeled entities in sampled negatives is high. Missampling tests on synthetic datasets have verified our guarantee in practice. Secondly, to mine hard negatives and further reduce missampling rates, we propose a weighted and adaptive sampling distribution for negative sampling. Experiments on synthetic datasets and well-annotated datasets show that our method significantly improves negative sampling in robustness and effectiveness. We also have achieved new state-of-the-art results on real-world datasets.
On the Copying Behaviors of Pre-Training for Neural Machine Translation
Jul 17, 2021
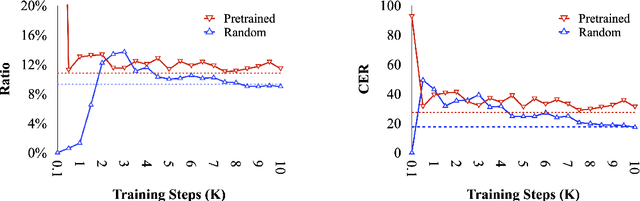
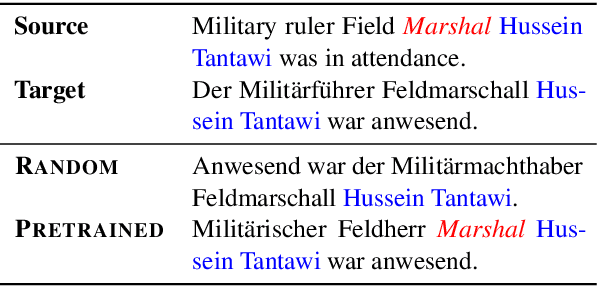
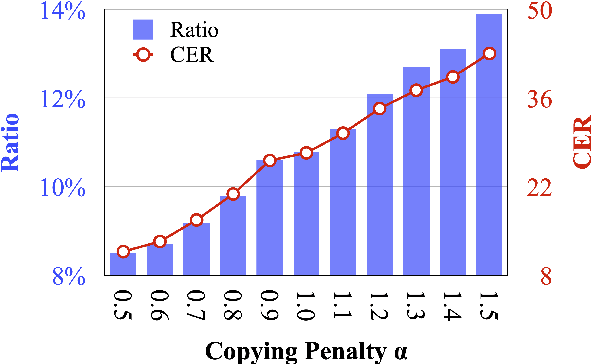
Previous studies have shown that initializing neural machine translation (NMT) models with the pre-trained language models (LM) can speed up the model training and boost the model performance. In this work, we identify a critical side-effect of pre-training for NMT, which is due to the discrepancy between the training objectives of LM-based pre-training and NMT. Since the LM objective learns to reconstruct a few source tokens and copy most of them, the pre-training initialization would affect the copying behaviors of NMT models. We provide a quantitative analysis of copying behaviors by introducing a metric called copying ratio, which empirically shows that pre-training based NMT models have a larger copying ratio than the standard one. In response to this problem, we propose a simple and effective method named copying penalty to control the copying behaviors in decoding. Extensive experiments on both in-domain and out-of-domain benchmarks show that the copying penalty method consistently improves translation performance by controlling copying behaviors for pre-training based NMT models. Source code is freely available at https://github.com/SunbowLiu/CopyingPenalty.
Tail-to-Tail Non-Autoregressive Sequence Prediction for Chinese Grammatical Error Correction
Jun 20, 2021
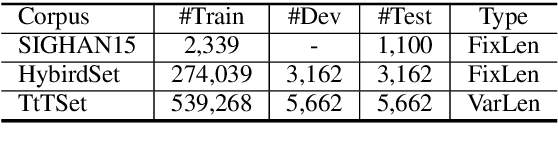

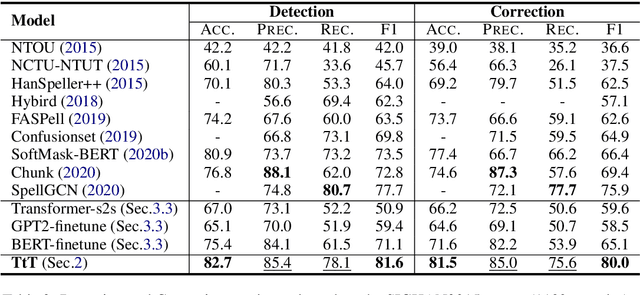
We investigate the problem of Chinese Grammatical Error Correction (CGEC) and present a new framework named Tail-to-Tail (\textbf{TtT}) non-autoregressive sequence prediction to address the deep issues hidden in CGEC. Considering that most tokens are correct and can be conveyed directly from source to target, and the error positions can be estimated and corrected based on the bidirectional context information, thus we employ a BERT-initialized Transformer Encoder as the backbone model to conduct information modeling and conveying. Considering that only relying on the same position substitution cannot handle the variable-length correction cases, various operations such substitution, deletion, insertion, and local paraphrasing are required jointly. Therefore, a Conditional Random Fields (CRF) layer is stacked on the up tail to conduct non-autoregressive sequence prediction by modeling the token dependencies. Since most tokens are correct and easily to be predicted/conveyed to the target, then the models may suffer from a severe class imbalance issue. To alleviate this problem, focal loss penalty strategies are integrated into the loss functions. Moreover, besides the typical fix-length error correction datasets, we also construct a variable-length corpus to conduct experiments. Experimental results on standard datasets, especially on the variable-length datasets, demonstrate the effectiveness of TtT in terms of sentence-level Accuracy, Precision, Recall, and F1-Measure on tasks of error Detection and Correction.
On the Language Coverage Bias for Neural Machine Translation
Jun 07, 2021
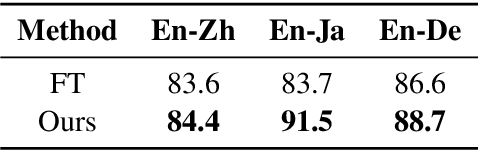
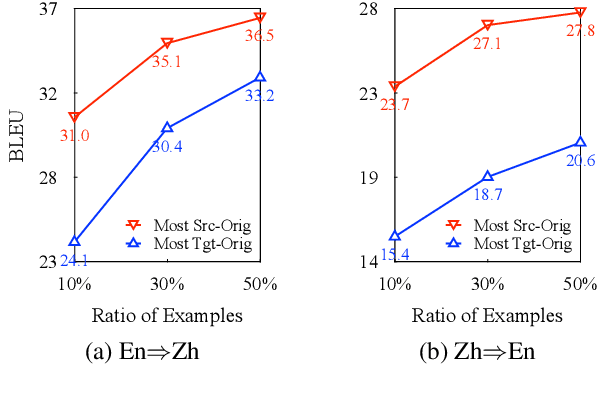

Language coverage bias, which indicates the content-dependent differences between sentence pairs originating from the source and target languages, is important for neural machine translation (NMT) because the target-original training data is not well exploited in current practice. By carefully designing experiments, we provide comprehensive analyses of the language coverage bias in the training data, and find that using only the source-original data achieves comparable performance with using full training data. Based on these observations, we further propose two simple and effective approaches to alleviate the language coverage bias problem through explicitly distinguishing between the source- and target-original training data, which consistently improve the performance over strong baselines on six WMT20 translation tasks. Complementary to the translationese effect, language coverage bias provides another explanation for the performance drop caused by back-translation. We also apply our approach to both back- and forward-translation and find that mitigating the language coverage bias can improve the performance of both the two representative data augmentation methods and their tagged variants.
Self-Training Sampling with Monolingual Data Uncertainty for Neural Machine Translation
Jun 02, 2021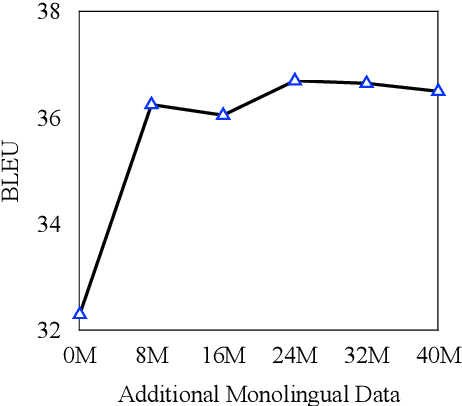

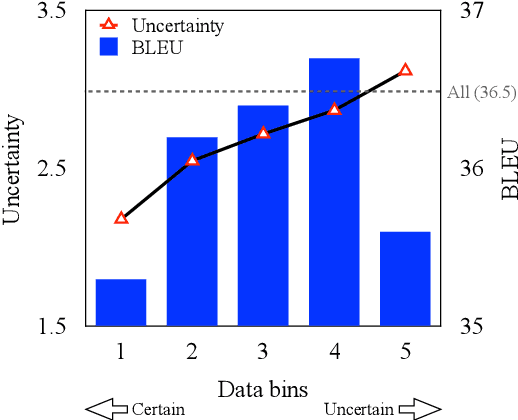
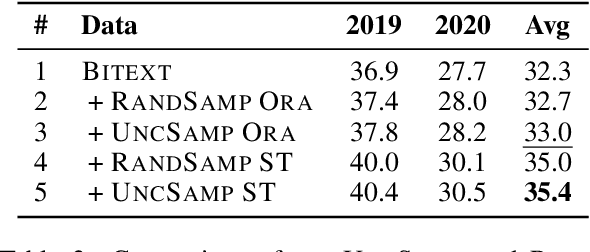
Self-training has proven effective for improving NMT performance by augmenting model training with synthetic parallel data. The common practice is to construct synthetic data based on a randomly sampled subset of large-scale monolingual data, which we empirically show is sub-optimal. In this work, we propose to improve the sampling procedure by selecting the most informative monolingual sentences to complement the parallel data. To this end, we compute the uncertainty of monolingual sentences using the bilingual dictionary extracted from the parallel data. Intuitively, monolingual sentences with lower uncertainty generally correspond to easy-to-translate patterns which may not provide additional gains. Accordingly, we design an uncertainty-based sampling strategy to efficiently exploit the monolingual data for self-training, in which monolingual sentences with higher uncertainty would be sampled with higher probability. Experimental results on large-scale WMT English$\Rightarrow$German and English$\Rightarrow$Chinese datasets demonstrate the effectiveness of the proposed approach. Extensive analyses suggest that emphasizing the learning on uncertain monolingual sentences by our approach does improve the translation quality of high-uncertainty sentences and also benefits the prediction of low-frequency words at the target side.
GWLAN: General Word-Level AutocompletioN for Computer-Aided Translation
May 31, 2021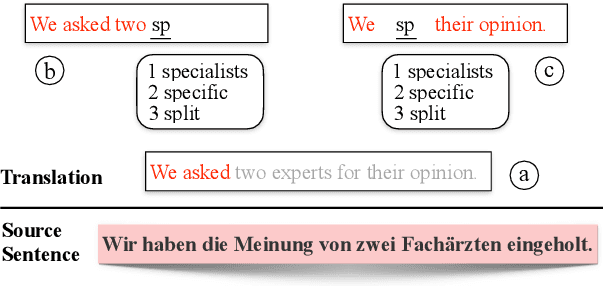
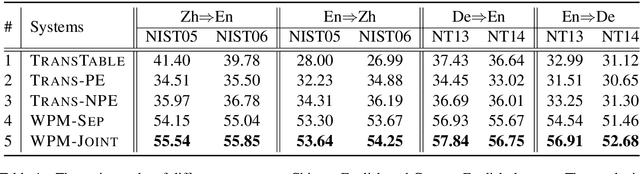
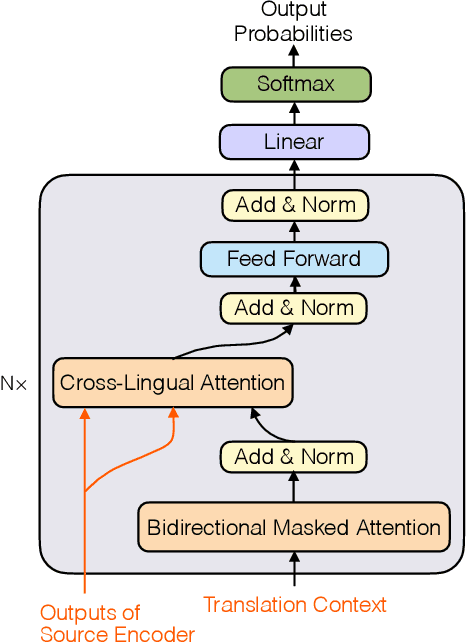
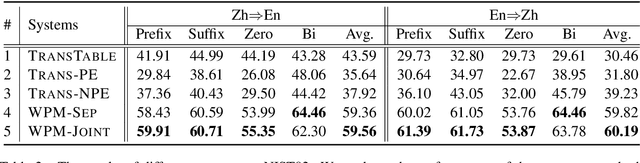
Computer-aided translation (CAT), the use of software to assist a human translator in the translation process, has been proven to be useful in enhancing the productivity of human translators. Autocompletion, which suggests translation results according to the text pieces provided by human translators, is a core function of CAT. There are two limitations in previous research in this line. First, most research works on this topic focus on sentence-level autocompletion (i.e., generating the whole translation as a sentence based on human input), but word-level autocompletion is under-explored so far. Second, almost no public benchmarks are available for the autocompletion task of CAT. This might be among the reasons why research progress in CAT is much slower compared to automatic MT. In this paper, we propose the task of general word-level autocompletion (GWLAN) from a real-world CAT scenario, and construct the first public benchmark to facilitate research in this topic. In addition, we propose an effective method for GWLAN and compare it with several strong baselines. Experiments demonstrate that our proposed method can give significantly more accurate predictions than the baseline methods on our benchmark datasets.