 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing
Oct 29, 2021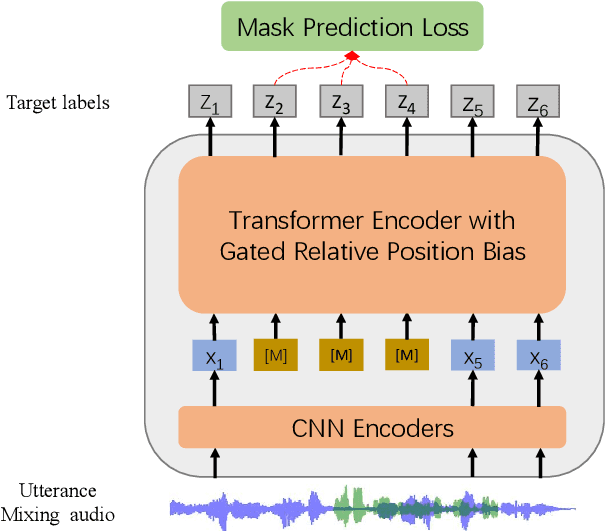
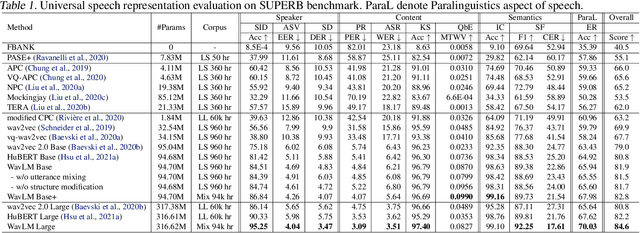
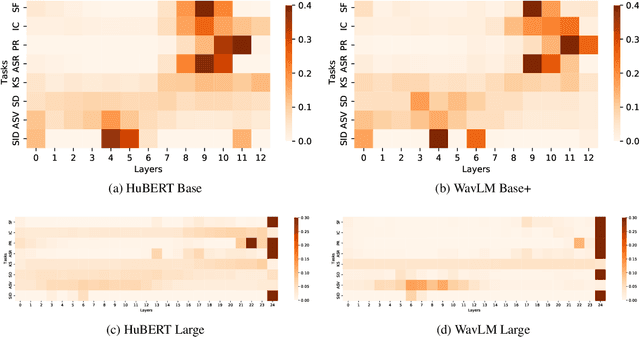
Self-supervised learning (SSL) achieves great success in speech recognition, while limited exploration has been attempted for other speech processing tasks. As speech signal contains multi-faceted information including speaker identity, paralinguistics, spoken content, etc., learning universal representations for all speech tasks is challenging. In this paper, we propose a new pre-trained model, WavLM, to solve full-stack downstream speech tasks. WavLM is built based on the HuBERT framework, with an emphasis on both spoken content modeling and speaker identity preservation. We first equip the Transformer structure with gated relative position bias to improve its capability on recognition tasks. For better speaker discrimination, we propose an utterance mixing training strategy, where additional overlapped utterances are created unsupervisely and incorporated during model training. Lastly, we scale up the training dataset from 60k hours to 94k hours. WavLM Large achieves state-of-the-art performance on the SUPERB benchmark, and brings significant improvements for various speech processing tasks on their representative benchmarks. The code and pretrained models are available at https://aka.ms/wavlm.
Improving Noise Robustness of Contrastive Speech Representation Learning with Speech Reconstruction
Oct 28, 2021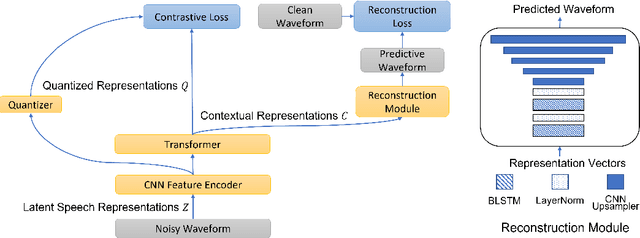
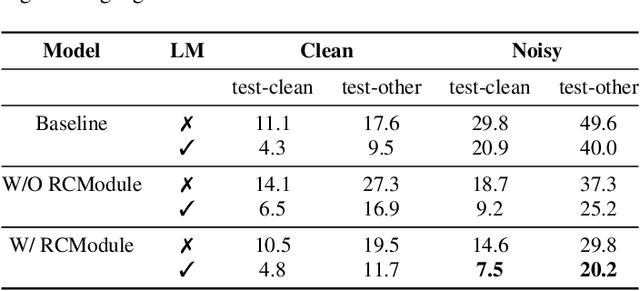
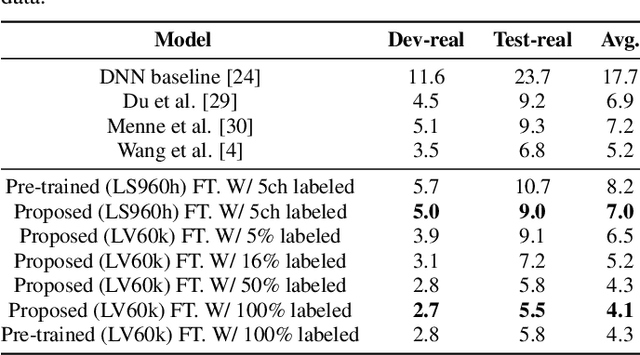
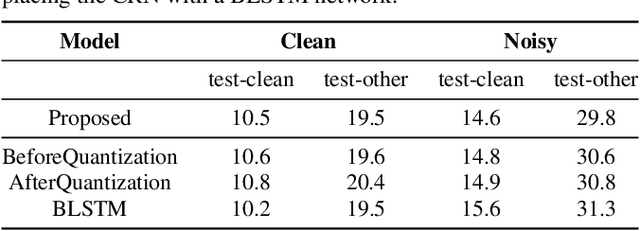
Noise robustness is essential for deploying automatic speech recognition (ASR) systems in real-world environments. One way to reduce the effect of noise interference is to employ a preprocessing module that conducts speech enhancement, and then feed the enhanced speech to an ASR backend. In this work, instead of suppressing background noise with a conventional cascaded pipeline, we employ a noise-robust representation learned by a refined self-supervised framework for noisy speech recognition. We propose to combine a reconstruction module with contrastive learning and perform multi-task continual pre-training on noisy data. The reconstruction module is used for auxiliary learning to improve the noise robustness of the learned representation and thus is not required during inference. Experiments demonstrate the effectiveness of our proposed method. Our model substantially reduces the word error rate (WER) for the synthesized noisy LibriSpeech test sets, and yields around 4.1/7.5% WER reduction on noisy clean/other test sets compared to data augmentation. For the real-world noisy speech from the CHiME-4 challenge (1-channel track), we have obtained the state of the art ASR performance without any denoising front-end. Moreover, we achieve comparable performance to the best supervised approach reported with only 16% of labeled data.
Optimizing Alignment of Speech and Language Latent Spaces for End-to-End Speech Recognition and Understanding
Oct 23, 2021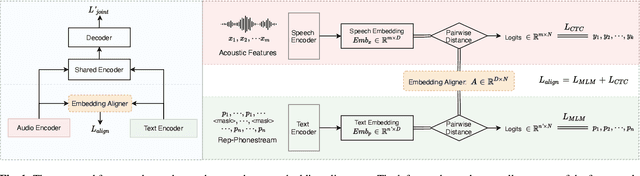
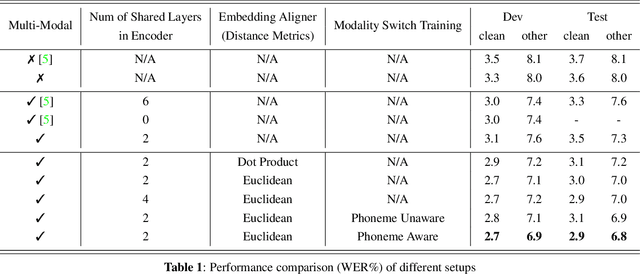
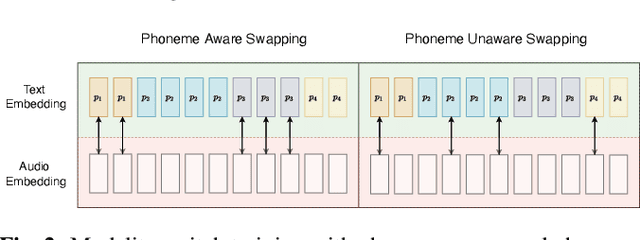
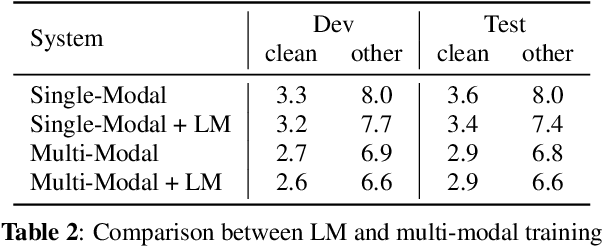
The advances in attention-based encoder-decoder (AED) networks have brought great progress to end-to-end (E2E) automatic speech recognition (ASR). One way to further improve the performance of AED-based E2E ASR is to introduce an extra text encoder for leveraging extensive text data and thus capture more context-aware linguistic information. However, this approach brings a mismatch problem between the speech encoder and the text encoder due to the different units used for modeling. In this paper, we propose an embedding aligner and modality switch training to better align the speech and text latent spaces. The embedding aligner is a shared linear projection between text encoder and speech encoder trained by masked language modeling (MLM) loss and connectionist temporal classification (CTC), respectively. The modality switch training randomly swaps speech and text embeddings based on the forced alignment result to learn a joint representation space. Experimental results show that our proposed approach achieves a relative 14% to 19% word error rate (WER) reduction on Librispeech ASR task. We further verify its effectiveness on spoken language understanding (SLU), i.e., an absolute 2.5% to 2.8% F1 score improvement on SNIPS slot filling task.
SpeechT5: Unified-Modal Encoder-Decoder Pre-training for Spoken Language Processing
Oct 14, 2021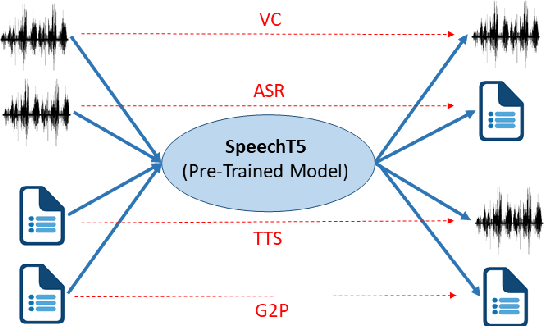
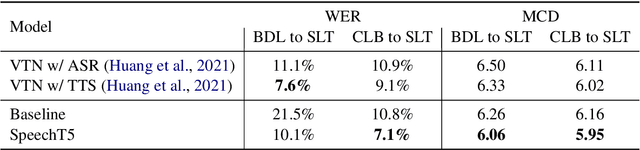
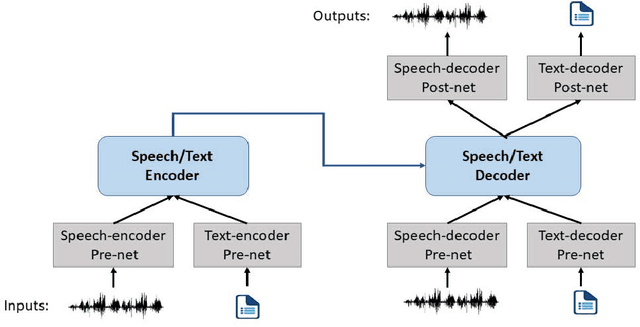
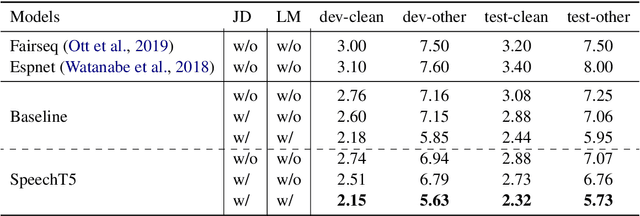
Motivated by the success of T5 (Text-To-Text Transfer Transformer) in pre-training natural language processing models, we propose a unified-modal SpeechT5 framework that explores the encoder-decoder pre-training for self-supervised speech/text representation learning. The SpeechT5 framework consists of a shared encoder-decoder network and six modal-specific (speech/text) pre/post-nets. After preprocessing the speech/text input through the pre-nets, the shared encoder-decoder network models the sequence to sequence transformation, and then the post-nets generate the output in the speech/text modality based on the decoder output. Particularly, SpeechT5 can pre-train on a large scale of unlabeled speech and text data to improve the capability of the speech and textual modeling. To align the textual and speech information into a unified semantic space, we propose a cross-modal vector quantization method with random mixing-up to bridge speech and text. Extensive evaluations on a wide variety of spoken language processing tasks, including voice conversion, automatic speech recognition, text to speech, and speaker identification, show the superiority of the proposed SpeechT5 framework.
Large-scale Self-Supervised Speech Representation Learning for Automatic Speaker Verification
Oct 12, 2021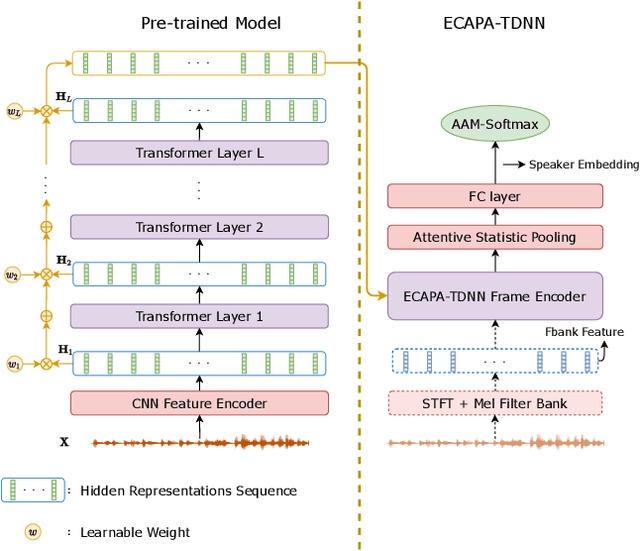


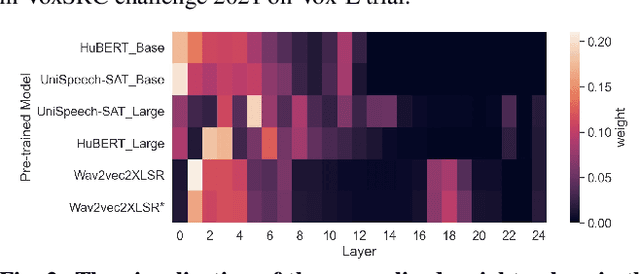
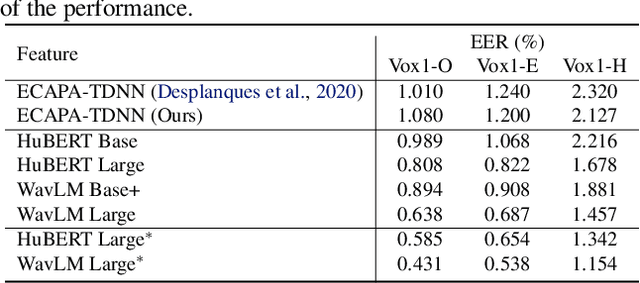
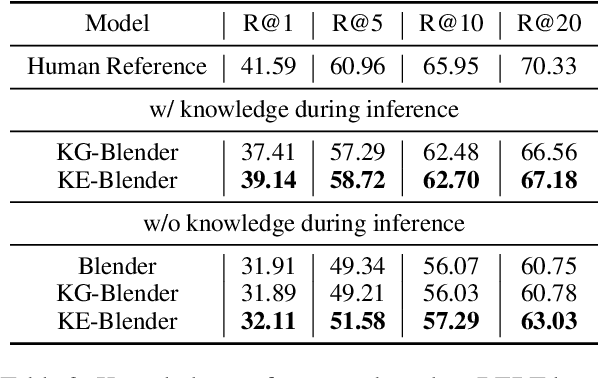
The speech representations learned from large-scale unlabeled data have shown better generalizability than those from supervised learning and thus attract a lot of interest to be applied for various downstream tasks. In this paper, we explore the limits of speech representations learned by different self-supervised objectives and datasets for automatic speaker verification (ASV), especially with a well-recognized SOTA ASV model, ECAPA-TDNN [1], as a downstream model. The representations from all hidden layers of the pre-trained model are firstly averaged with learnable weights and then fed into the ECAPA-TDNN as input features. The experimental results on Voxceleb dataset show that the weighted average representation is significantly superior to FBank, a conventional handcrafted feature for ASV. Our best single system achieves 0.564%, 0.561%, and 1.230% equal error rate (EER) on the three official trials of VoxCeleb1, separately. Accordingly, the ensemble system with three pre-trained models can further improve the EER to 0.431%, 0.507% and 1.081%. Among the three evaluation trials, our best system outperforms the winner system [2] of the VoxCeleb Speaker Recognition Challenge 2021 (VoxSRC2021) on the VoxCeleb1-E trial.
UniSpeech-SAT: Universal Speech Representation Learning with Speaker Aware Pre-Training
Oct 12, 2021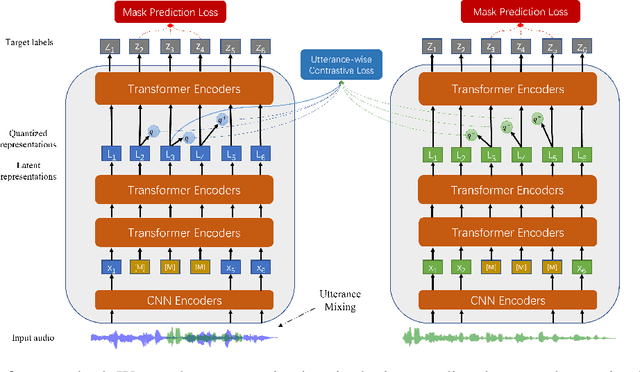
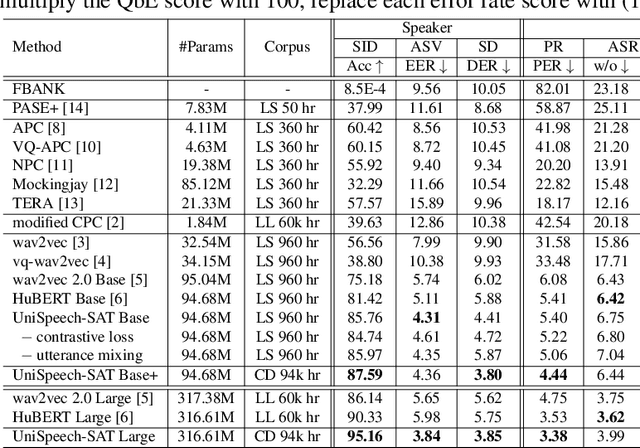
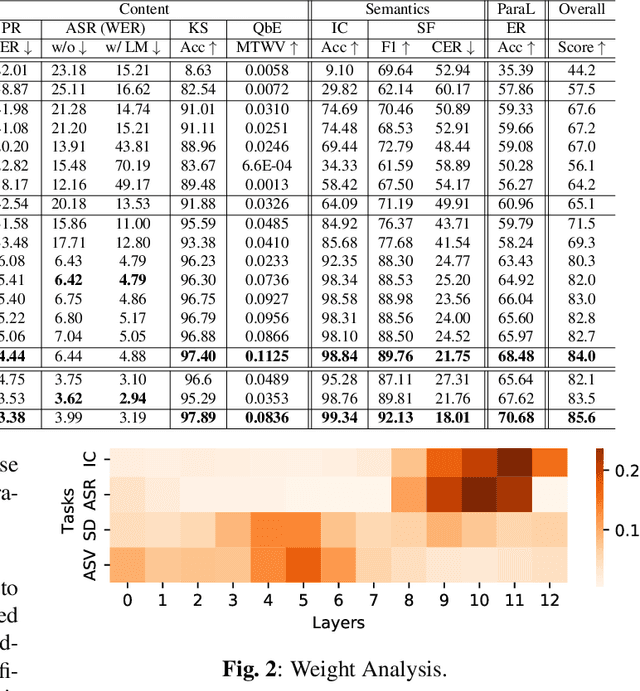
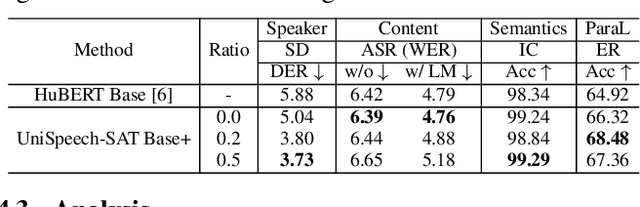
Self-supervised learning (SSL) is a long-standing goal for speech processing, since it utilizes large-scale unlabeled data and avoids extensive human labeling. Recent years witness great successes in applying self-supervised learning in speech recognition, while limited exploration was attempted in applying SSL for modeling speaker characteristics. In this paper, we aim to improve the existing SSL framework for speaker representation learning. Two methods are introduced for enhancing the unsupervised speaker information extraction. First, we apply the multi-task learning to the current SSL framework, where we integrate the utterance-wise contrastive loss with the SSL objective function. Second, for better speaker discrimination, we propose an utterance mixing strategy for data augmentation, where additional overlapped utterances are created unsupervisely and incorporate during training. We integrate the proposed methods into the HuBERT framework. Experiment results on SUPERB benchmark show that the proposed system achieves state-of-the-art performance in universal representation learning, especially for speaker identification oriented tasks. An ablation study is performed verifying the efficacy of each proposed method. Finally, we scale up training dataset to 94 thousand hours public audio data and achieve further performance improvement in all SUPERB tasks.
Multi-View Self-Attention Based Transformer for Speaker Recognition
Oct 11, 2021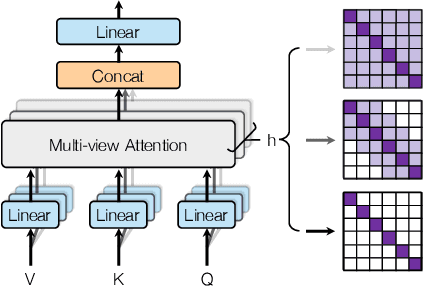
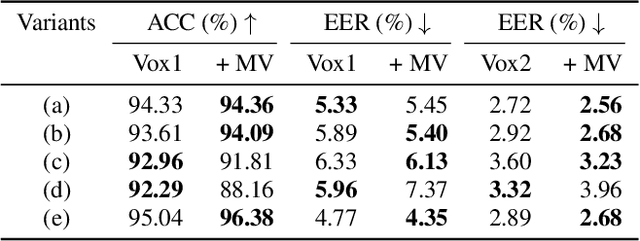
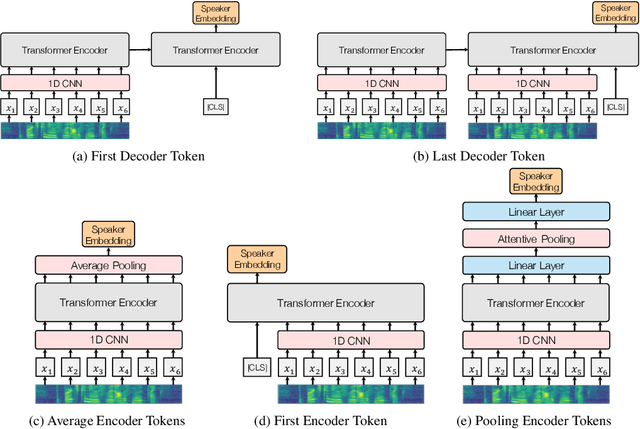
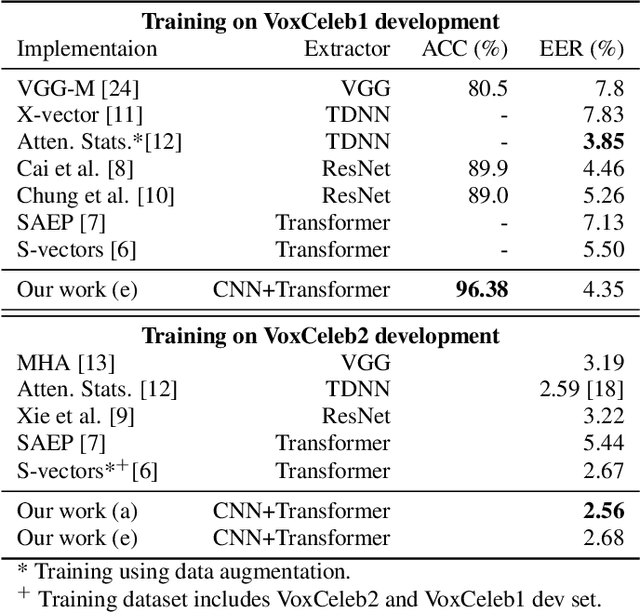
Initially developed for natural language processing (NLP), Transformer model is now widely used for speech processing tasks such as speaker recognition, due to its powerful sequence modeling capabilities. However, conventional self-attention mechanisms are originally designed for modeling textual sequence without considering the characteristics of speech and speaker modeling. Besides, different Transformer variants for speaker recognition have not been well studied. In this work, we propose a novel multi-view self-attention mechanism and present an empirical study of different Transformer variants with or without the proposed attention mechanism for speaker recognition. Specifically, to balance the capabilities of capturing global dependencies and modeling the locality, we propose a multi-view self-attention mechanism for speaker Transformer, in which different attention heads can attend to different ranges of the receptive field. Furthermore, we introduce and compare five Transformer variants with different network architectures, embedding locations, and pooling methods to learn speaker embeddings. Experimental results on the VoxCeleb1 and VoxCeleb2 datasets show that the proposed multi-view self-attention mechanism achieves improvement in the performance of speaker recognition, and the proposed speaker Transformer network attains excellent results compared with state-of-the-art models.
Jointly Learning to Repair Code and Generate Commit Message
Sep 25, 2021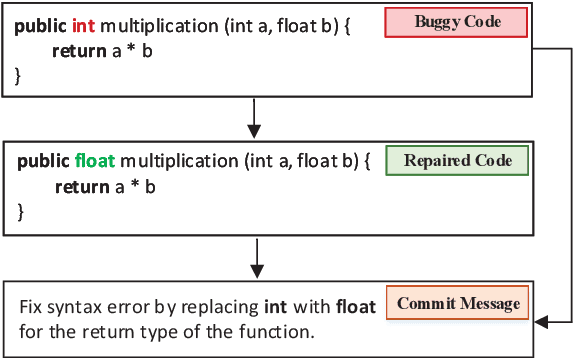
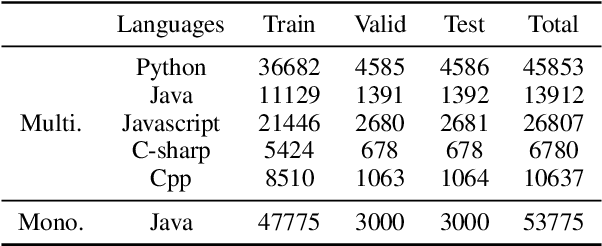
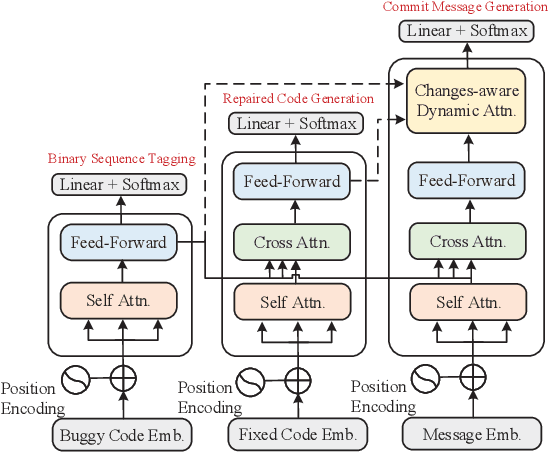
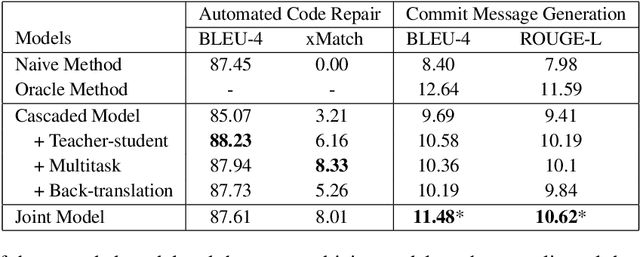
We propose a novel task of jointly repairing program codes and generating commit messages. Code repair and commit message generation are two essential and related tasks for software development. However, existing work usually performs the two tasks independently. We construct a multilingual triple dataset including buggy code, fixed code, and commit messages for this novel task. We provide the cascaded models as baseline, which are enhanced with different training approaches, including the teacher-student method, the multi-task method, and the back-translation method. To deal with the error propagation problem of the cascaded method, the joint model is proposed that can both repair the code and generate the commit message in a unified framework. Experimental results show that the enhanced cascaded model with teacher-student method and multitask-learning method achieves the best score on different metrics of automated code repair, and the joint model behaves better than the cascaded model on commit message generation.
Knowledge Enhanced Fine-Tuning for Better Handling Unseen Entities in Dialogue Generation
Sep 12, 2021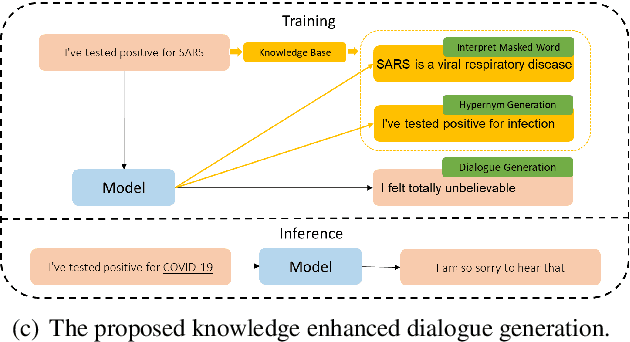
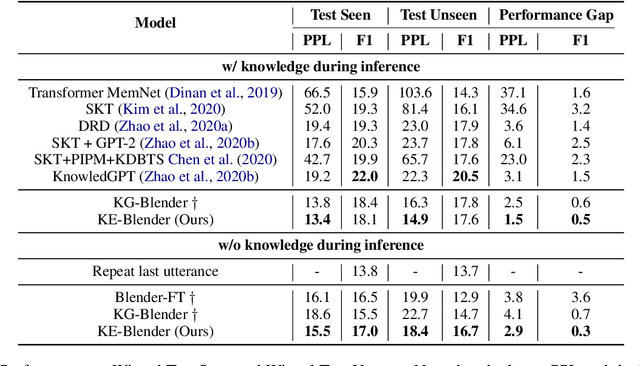
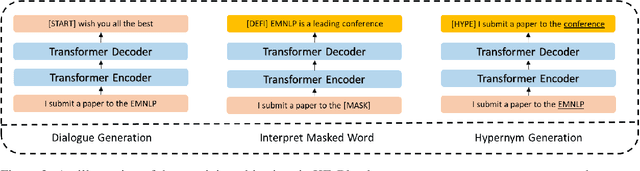
Although pre-training models have achieved great success in dialogue generation, their performance drops dramatically when the input contains an entity that does not appear in pre-training and fine-tuning datasets (unseen entity). To address this issue, existing methods leverage an external knowledge base to generate appropriate responses. In real-world scenario, the entity may not be included by the knowledge base or suffer from the precision of knowledge retrieval. To deal with this problem, instead of introducing knowledge base as the input, we force the model to learn a better semantic representation by predicting the information in the knowledge base, only based on the input context. Specifically, with the help of a knowledge base, we introduce two auxiliary training objectives: 1) Interpret Masked Word, which conjectures the meaning of the masked entity given the context; 2) Hypernym Generation, which predicts the hypernym of the entity based on the context. Experiment results on two dialogue corpus verify the effectiveness of our methods under both knowledge available and unavailable settings.
A Configurable Multilingual Model is All You Need to Recognize All Languages
Jul 13, 2021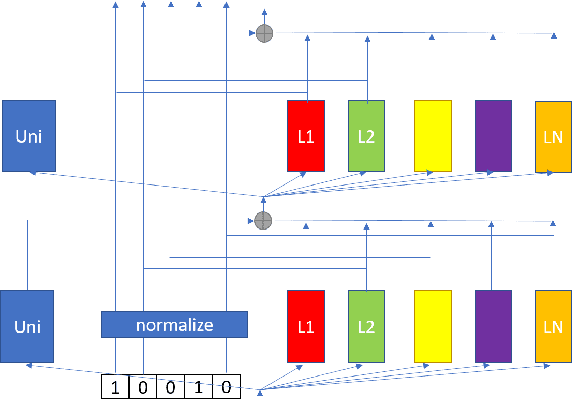
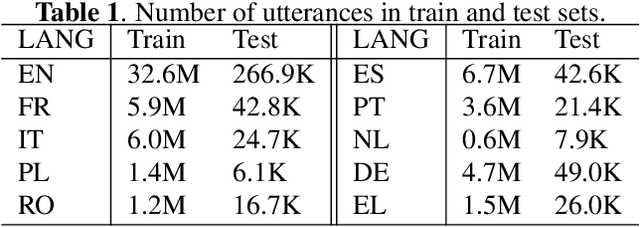
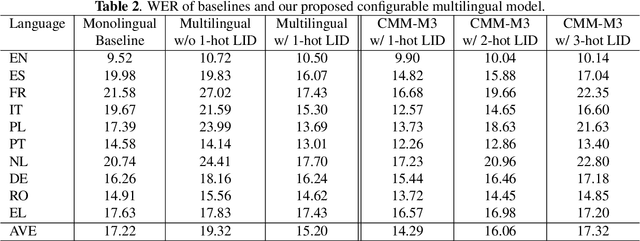
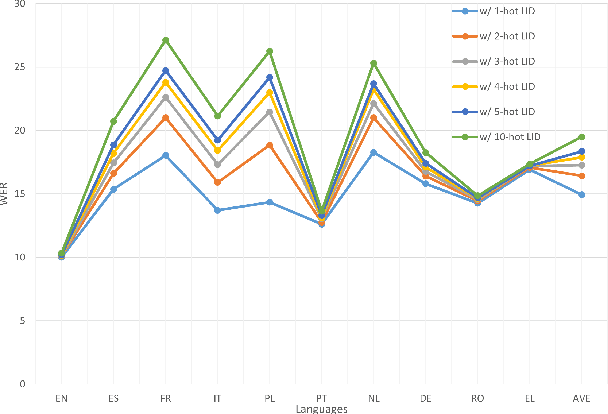
Multilingual automatic speech recognition (ASR) models have shown great promise in recent years because of the simplified model training and deployment process. Conventional methods either train a universal multilingual model without taking any language information or with a 1-hot language ID (LID) vector to guide the recognition of the target language. In practice, the user can be prompted to pre-select several languages he/she can speak. The multilingual model without LID cannot well utilize the language information set by the user while the multilingual model with LID can only handle one pre-selected language. In this paper, we propose a novel configurable multilingual model (CMM) which is trained only once but can be configured as different models based on users' choices by extracting language-specific modules together with a universal model from the trained CMM. Particularly, a single CMM can be deployed to any user scenario where the users can pre-select any combination of languages. Trained with 75K hours of transcribed anonymized Microsoft multilingual data and evaluated with 10-language test sets, the proposed CMM improves from the universal multilingual model by 26.0%, 16.9%, and 10.4% relative word error reduction when the user selects 1, 2, or 3 languages, respectively. CMM also performs significantly better on code-switching test sets.