 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinTSB: A Comprehensive and Practical Benchmark for Financial Time Series Forecasting
Feb 26, 2025



Financial time series (FinTS) record the behavior of human-brain-augmented decision-making, capturing valuable historical information that can be leveraged for profitable investment strategies. Not surprisingly, this area has attracted considerable attention from researchers, who have proposed a wide range of methods based on various backbones. However, the evaluation of the area often exhibits three systemic limitations: 1. Failure to account for the full spectrum of stock movement patterns observed in dynamic financial markets. (Diversity Gap), 2. The absence of unified assessment protocols undermines the validity of cross-study performance comparisons. (Standardization Deficit), and 3. Neglect of critical market structure factors, resulting in inflated performance metrics that lack practical applicability. (Real-World Mismatch). Addressing these limitations, we propose FinTSB, a comprehensive and practical benchmark for financial time series forecasting (FinTSF). To increase the variety, we categorize movement patterns into four specific parts, tokenize and pre-process the data, and assess the data quality based on some sequence characteristics. To eliminate biases due to different evaluation settings, we standardize the metrics across three dimensions and build a user-friendly, lightweight pipeline incorporating methods from various backbones. To accurately simulate real-world trading scenarios and facilitate practical implementation, we extensively model various regulatory constraints, including transaction fees, among others. Finally, we conduct extensive experiments on FinTSB, highlighting key insights to guide model selection under varying market conditions. Overall, FinTSB provides researchers with a novel and comprehensive platform for improving and evaluating FinTSF methods. The code is available at https://github.com/TongjiFinLab/FinTSBenchmark.
ReFIR: Grounding Large Restoration Models with Retrieval Augmentation
Oct 08, 2024



Recent advances in diffusion-based Large Restoration Models (LRMs) have significantly improved photo-realistic image restoration by leveraging the internal knowledge embedded within model weights. However, existing LRMs often suffer from the hallucination dilemma, i.e., producing incorrect contents or textures when dealing with severe degradations, due to their heavy reliance on limited internal knowledge. In this paper, we propose an orthogonal solution called the Retrieval-augmented Framework for Image Restoration (ReFIR), which incorporates retrieved images as external knowledge to extend the knowledge boundary of existing LRMs in generating details faithful to the original scene. Specifically, we first introduce the nearest neighbor lookup to retrieve content-relevant high-quality images as reference, after which we propose the cross-image injection to modify existing LRMs to utilize high-quality textures from retrieved images. Thanks to the additional external knowledge, our ReFIR can well handle the hallucination challenge and facilitate faithfully results. Extensive experiments demonstrate that ReFIR can achieve not only high-fidelity but also realistic restoration results. Importantly, our ReFIR requires no training and is adaptable to various LRMs.
TimeBridge: Non-Stationarity Matters for Long-term Time Series Forecasting
Oct 06, 2024



Non-stationarity poses significant challenges for multivariate time series forecasting due to the inherent short-term fluctuations and long-term trends that can lead to spurious regressions or obscure essential long-term relationships. Most existing methods either eliminate or retain non-stationarity without adequately addressing its distinct impacts on short-term and long-term modeling. Eliminating non-stationarity is essential for avoiding spurious regressions and capturing local dependencies in short-term modeling, while preserving it is crucial for revealing long-term cointegration across variates. In this paper, we propose TimeBridge, a novel framework designed to bridge the gap between non-stationarity and dependency modeling in long-term time series forecasting. By segmenting input series into smaller patches, TimeBridge applies Integrated Attention to mitigate short-term non-stationarity and capture stable dependencies within each variate, while Cointegrated Attention preserves non-stationarity to model long-term cointegration across variates. Extensive experiments show that TimeBridge consistently achieves state-of-the-art performance in both short-term and long-term forecasting. Additionally, TimeBridge demonstrates exceptional performance in financial forecasting on the CSI 500 and S&P 500 indices, further validating its robustness and effectiveness. Code is available at \url{https://github.com/Hank0626/TimeBridge}.
Not All Prompts Are Secure: A Switchable Backdoor Attack Against Pre-trained Vision Transformers
May 17, 2024



Given the power of vision transformers, a new learning paradigm, pre-training and then prompting, makes it more efficient and effective to address downstream visual recognition tasks. In this paper, we identify a novel security threat towards such a paradigm from the perspective of backdoor attacks. Specifically, an extra prompt token, called the switch token in this work, can turn the backdoor mode on, i.e., converting a benign model into a backdoored one. Once under the backdoor mode, a specific trigger can force the model to predict a target class. It poses a severe risk to the users of cloud API, since the malicious behavior can not be activated and detected under the benign mode, thus making the attack very stealthy. To attack a pre-trained model, our proposed attack, named SWARM, learns a trigger and prompt tokens including a switch token. They are optimized with the clean loss which encourages the model always behaves normally even the trigger presents, and the backdoor loss that ensures the backdoor can be activated by the trigger when the switch is on. Besides, we utilize the cross-mode feature distillation to reduce the effect of the switch token on clean samples. The experiments on diverse visual recognition tasks confirm the success of our switchable backdoor attack, i.e., achieving 95%+ attack success rate, and also being hard to be detected and removed. Our code is available at https://github.com/20000yshust/SWARM.
FMM-Attack: A Flow-based Multi-modal Adversarial Attack on Video-based LLMs
Mar 21, 2024Despite the remarkable performance of video-based large language models (LLMs), their adversarial threat remains unexplored. To fill this gap, we propose the first adversarial attack tailored for video-based LLMs by crafting flow-based multi-modal adversarial perturbations on a small fraction of frames within a video, dubbed FMM-Attack. Extensive experiments show that our attack can effectively induce video-based LLMs to generate incorrect answers when videos are added with imperceptible adversarial perturbations. Intriguingly, our FMM-Attack can also induce garbling in the model output, prompting video-based LLMs to hallucinate. Overall, our observations inspire a further understanding of multi-modal robustness and safety-related feature alignment across different modalities, which is of great importance for various large multi-modal models. Our code is available at https://github.com/THU-Kingmin/FMM-Attack.
Versatile Weight Attack via Flipping Limited Bits
Jul 25, 2022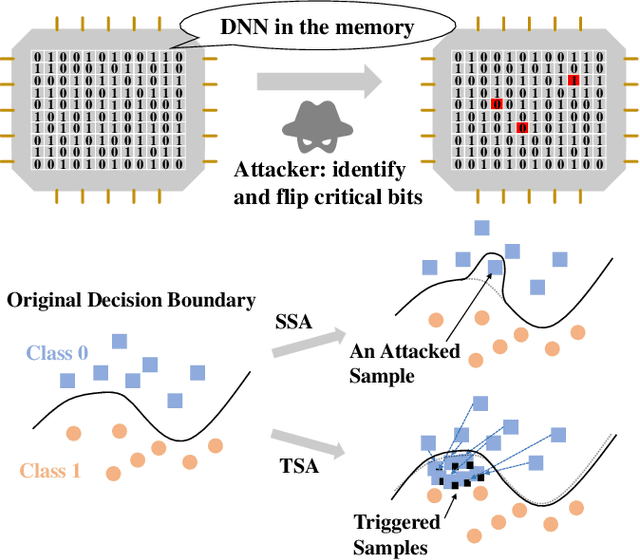
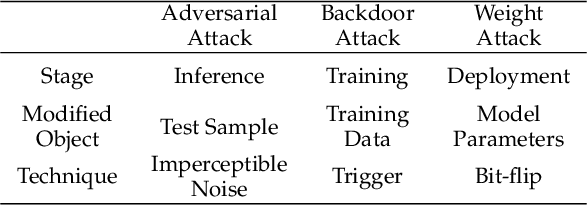
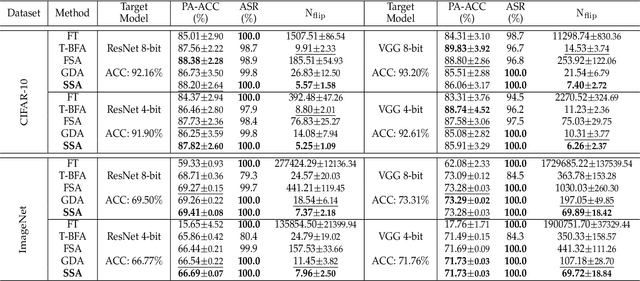
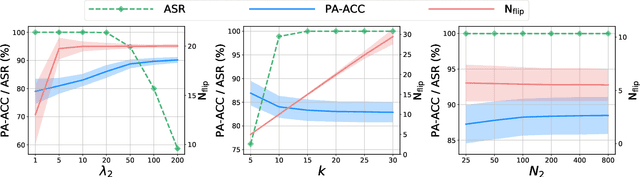
To explore the vulnerability of deep neural networks (DNNs), many attack paradigms have been well studied, such as the poisoning-based backdoor attack in the training stage and the adversarial attack in the inference stage. In this paper, we study a novel attack paradigm, which modifies model parameters in the deployment stage. Considering the effectiveness and stealthiness goals, we provide a general formulation to perform the bit-flip based weight attack, where the effectiveness term could be customized depending on the attacker's purpose. Furthermore, we present two cases of the general formulation with different malicious purposes, i.e., single sample attack (SSA) and triggered samples attack (TSA). To this end, we formulate this problem as a mixed integer programming (MIP) to jointly determine the state of the binary bits (0 or 1) in the memory and learn the sample modification. Utilizing the latest technique in integer programming, we equivalently reformulate this MIP problem as a continuous optimization problem, which can be effectively and efficiently solved using the alternating direction method of multipliers (ADMM) method. Consequently, the flipped critical bits can be easily determined through optimization, rather than using a heuristic strategy. Extensive experiments demonstrate the superiority of SSA and TSA in attacking DNNs.
Adaptive Frequency Learning in Two-branch Face Forgery Detection
Mar 27, 2022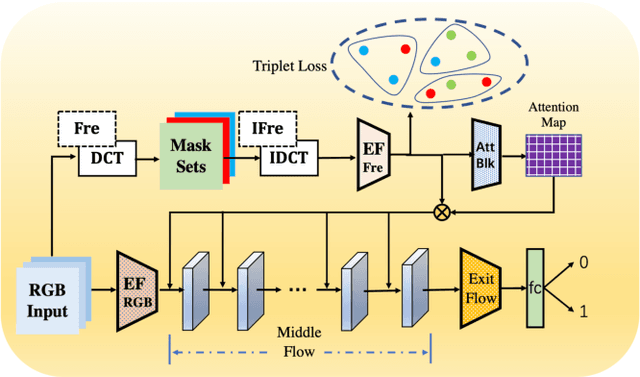
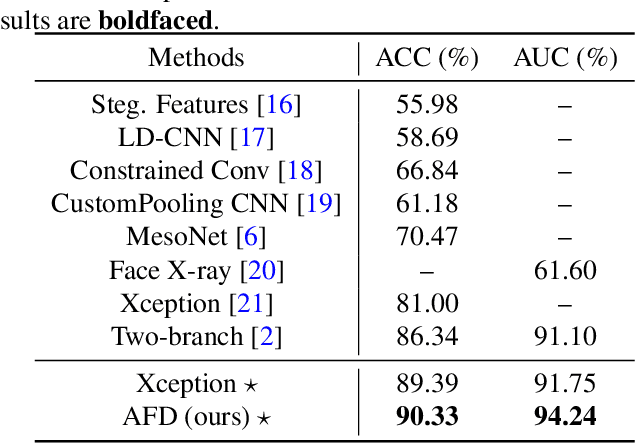
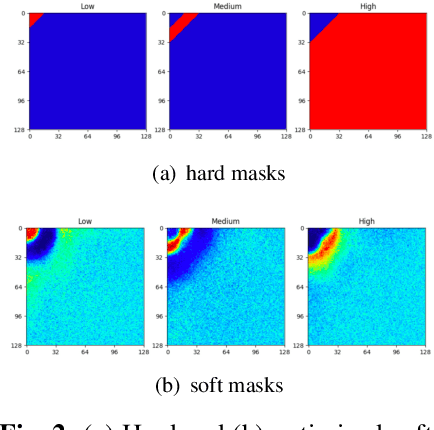
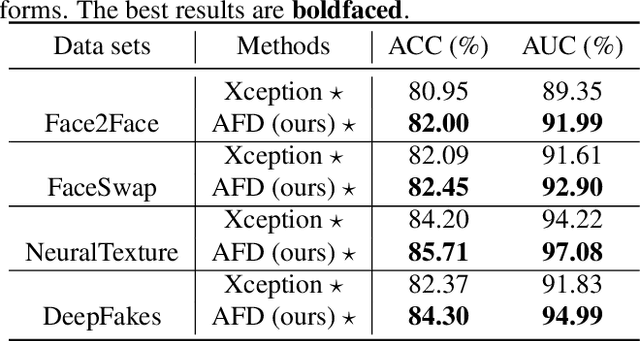
Face forgery has attracted increasing attention in recent applications of computer vision. Existing detection techniques using the two-branch framework benefit a lot from a frequency perspective, yet are restricted by their fixed frequency decomposition and transform. In this paper, we propose to Adaptively learn Frequency information in the two-branch Detection framework, dubbed AFD. To be specific, we automatically learn decomposition in the frequency domain by introducing heterogeneity constraints, and propose an attention-based module to adaptively incorporate frequency features into spatial clues. Then we liberate our network from the fixed frequency transforms, and achieve better performance with our data- and task-dependent transform layers. Extensive experiments show that AFD generally outperforms.
Temporal Calibrated Regularization for Robust Noisy Label Learning
Jul 01, 2020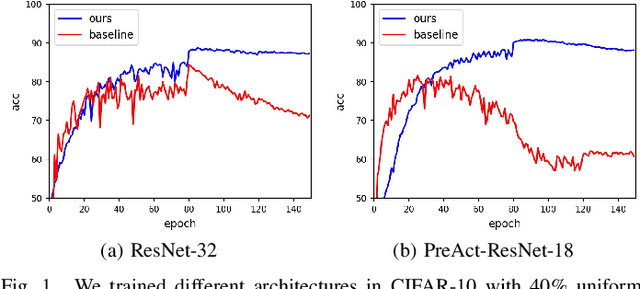
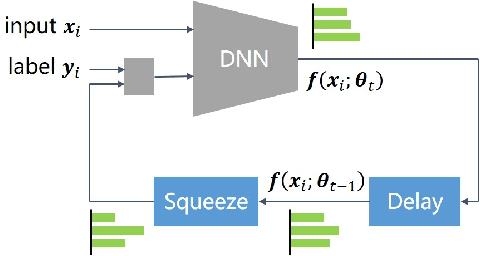
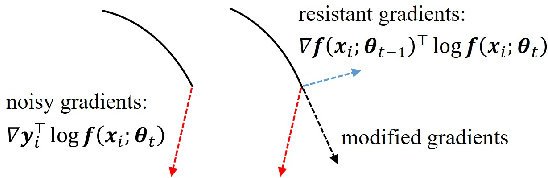
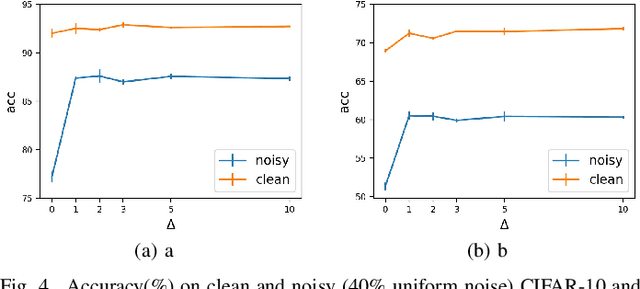
Deep neural networks (DNNs) exhibit great success on many tasks with the help of large-scale well annotated datasets. However, labeling large-scale data can be very costly and error-prone so that it is difficult to guarantee the annotation quality (i.e., having noisy labels). Training on these noisy labeled datasets may adversely deteriorate their generalization performance. Existing methods either rely on complex training stage division or bring too much computation for marginal performance improvement. In this paper, we propose a Temporal Calibrated Regularization (TCR), in which we utilize the original labels and the predictions in the previous epoch together to make DNN inherit the simple pattern it has learned with little overhead. We conduct extensive experiments on various neural network architectures and datasets, and find that it consistently enhances the robustness of DNNs to label noise.
Targeted Attack for Deep Hashing based Retrieval
May 08, 2020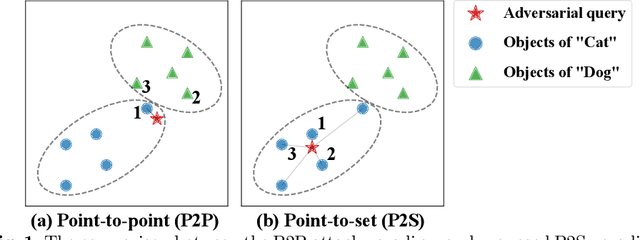
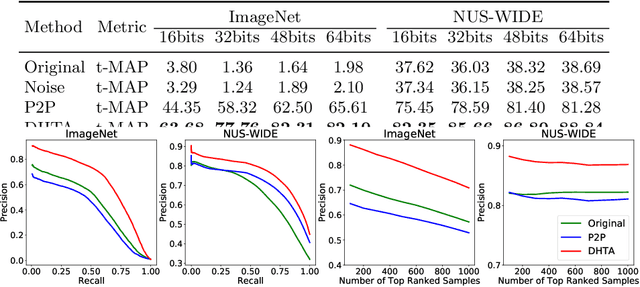
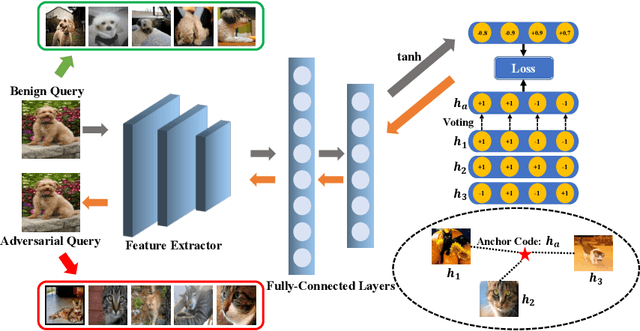
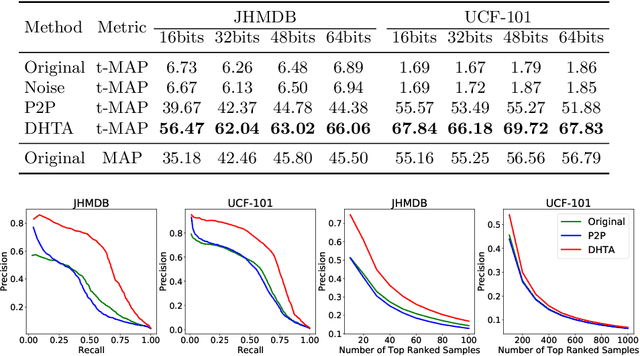
The deep hashing based retrieval method is widely adopted in large-scale image and video retrieval. However, there is little investigation on its security. In this paper, we propose a novel method, dubbed deep hashing targeted attack (DHTA), to study the targeted attack on such retrieval. Specifically, we first formulate the targeted attack as a point-to-set optimization, which minimizes the average distance between the hash code of an adversarial example and those of a set of objects with the target label. Then we design a novel component-voting scheme to obtain an anchor code as the representative of the set of hash codes of objects with the target label, whose optimality guarantee is also theoretically derived. To balance the performance and perceptibility, we propose to minimize the Hamming distance between the hash code of the adversarial example and the anchor code under the $\ell^\infty$ restriction on the perturbation. Extensive experiments verify that DHTA is effective in attacking both deep hashing based image retrieval and video retrieval.
Revisiting Loss Landscape for Adversarial Robustness
Apr 13, 2020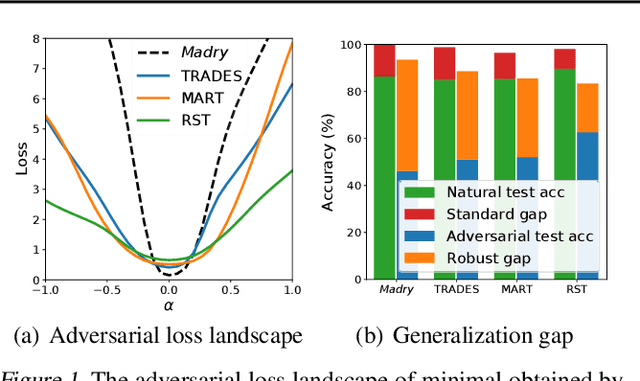

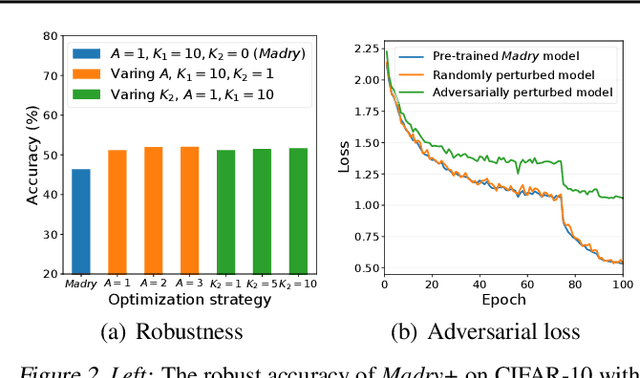
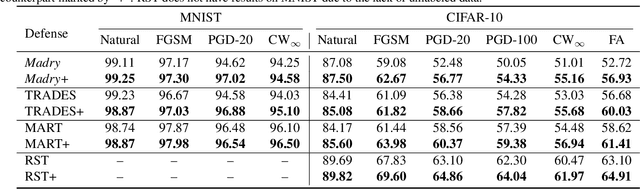
The study on improving the robustness of deep neural networks against adversarial examples grows rapidly in recent years. Among them, adversarial training is the most promising one, based on which, a lot of improvements have been developed, such as adding regularizations or leveraging unlabeled data. However, these improvements seem to come from isolated perspectives, so that we are curious about if there is something in common behind them. In this paper, we investigate the surface geometry of several well-recognized adversarial training variants, and reveal that their adversarial loss landscape is closely related to the adversarially robust generalization, i.e., the flatter the adversarial loss landscape, the smaller the adversarially robust generalization gap. Based on this finding, we then propose a simple yet effective module, Adversarial Weight Perturbation (AWP), to directly regularize the flatness of the adversarial loss landscape in the adversarial training framework. Extensive experiments demonstrate that AWP indeed owns flatter landscape and can be easily incorporated into various adversarial training variants to enhance their adversarial robustness further.