 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Robustness: From Self-Supervised Pre-Training to Fine-Tuning
Mar 28, 2020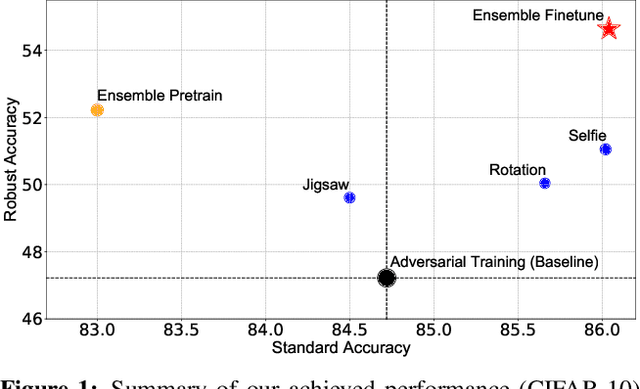


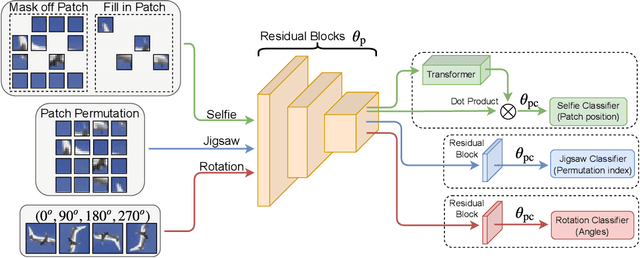
Pretrained models from self-supervision are prevalently used in fine-tuning downstream tasks faster or for better accuracy. However, gaining robustness from pretraining is left unexplored. We introduce adversarial training into self-supervision, to provide general-purpose robust pre-trained models for the first time. We find these robust pre-trained models can benefit the subsequent fine-tuning in two ways: i) boosting final model robustness; ii) saving the computation cost, if proceeding towards adversarial fine-tuning. We conduct extensive experiments to demonstrate that the proposed framework achieves large performance margins (eg, 3.83% on robust accuracy and 1.3% on standard accuracy, on the CIFAR-10 dataset), compared with the conventional end-to-end adversarial training baseline. Moreover, we find that different self-supervised pre-trained models have a diverse adversarial vulnerability. It inspires us to ensemble several pretraining tasks, which boosts robustness more. Our ensemble strategy contributes to a further improvement of 3.59% on robust accuracy, while maintaining a slightly higher standard accuracy on CIFAR-10. Our codes are available at https://github.com/TAMU-VITA/Adv-SS-Pretraining.
Invariant Rationalization
Mar 22, 2020

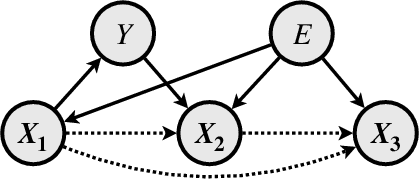
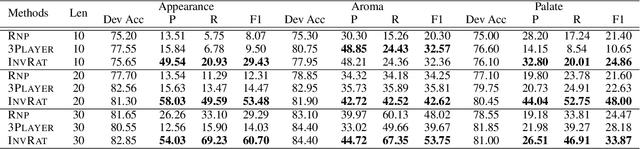
Selective rationalization improves neural network interpretability by identifying a small subset of input features -- the rationale -- that best explains or supports the prediction. A typical rationalization criterion, i.e. maximum mutual information (MMI), finds the rationale that maximizes the prediction performance based only on the rationale. However, MMI can be problematic because it picks up spurious correlations between the input features and the output. Instead, we introduce a game-theoretic invariant rationalization criterion where the rationales are constrained to enable the same predictor to be optimal across different environments. We show both theoretically and empirically that the proposed rationales can rule out spurious correlations, generalize better to different test scenarios, and align better with human judgments. Our data and code are available.
Rethinking Cooperative Rationalization: Introspective Extraction and Complement Control
Oct 29, 2019
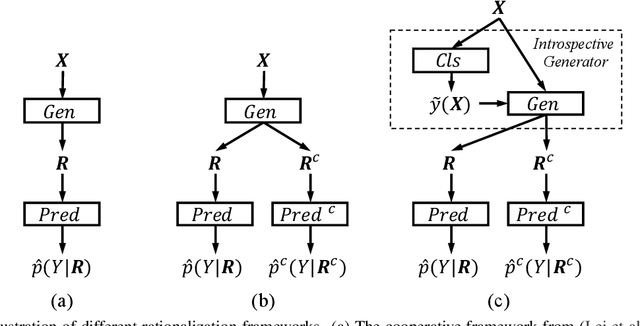
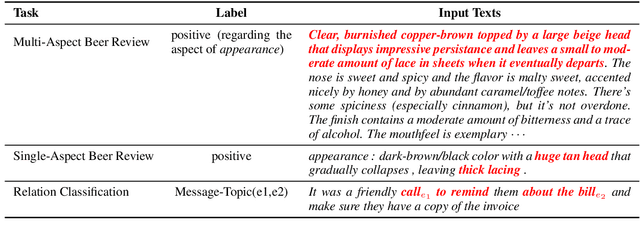
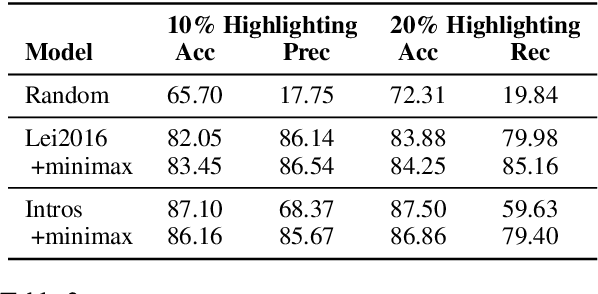
Selective rationalization has become a common mechanism to ensure that predictive models reveal how they use any available features. The selection may be soft or hard, and identifies a subset of input features relevant for prediction. The setup can be viewed as a co-operate game between the selector (aka rationale generator) and the predictor making use of only the selected features. The co-operative setting may, however, be compromised for two reasons. First, the generator typically has no direct access to the outcome it aims to justify, resulting in poor performance. Second, there's typically no control exerted on the information left outside the selection. We revise the overall co-operative framework to address these challenges. We introduce an introspective model which explicitly predicts and incorporates the outcome into the selection process. Moreover, we explicitly control the rationale complement via an adversary so as not to leave any useful information out of the selection. We show that the two complementary mechanisms maintain both high predictive accuracy and lead to comprehensive rationales.
A Game Theoretic Approach to Class-wise Selective Rationalization
Oct 28, 2019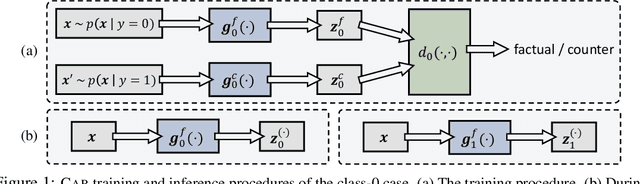

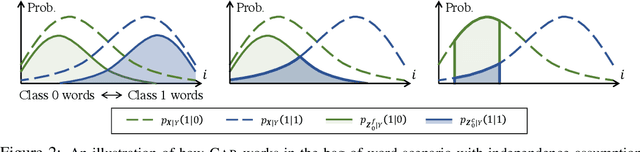
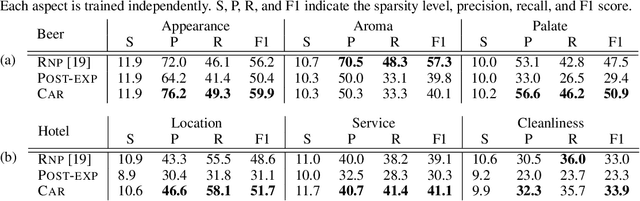
Selection of input features such as relevant pieces of text has become a common technique of highlighting how complex neural predictors operate. The selection can be optimized post-hoc for trained models or incorporated directly into the method itself (self-explaining). However, an overall selection does not properly capture the multi-faceted nature of useful rationales such as pros and cons for decisions. To this end, we propose a new game theoretic approach to class-dependent rationalization, where the method is specifically trained to highlight evidence supporting alternative conclusions. Each class involves three players set up competitively to find evidence for factual and counterfactual scenarios. We show theoretically in a simplified scenario how the game drives the solution towards meaningful class-dependent rationales. We evaluate the method in single- and multi-aspect sentiment classification tasks and demonstrate that the proposed method is able to identify both factual (justifying the ground truth label) and counterfactual (countering the ground truth label) rationales consistent with human rationalization. The code for our method is publicly available.
An Efficient and Margin-Approaching Zero-Confidence Adversarial Attack
Oct 01, 2019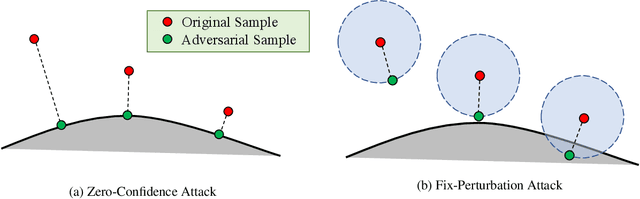
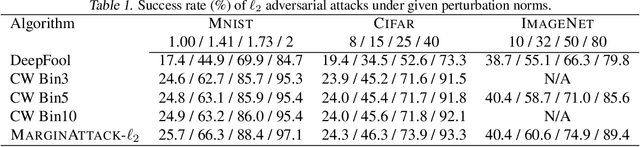
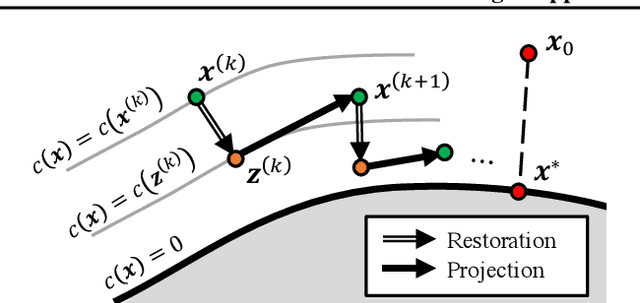

There are two major paradigms of white-box adversarial attacks that attempt to impose input perturbations. The first paradigm, called the fix-perturbation attack, crafts adversarial samples within a given perturbation level. The second paradigm, called the zero-confidence attack, finds the smallest perturbation needed to cause mis-classification, also known as the margin of an input feature. While the former paradigm is well-resolved, the latter is not. Existing zero-confidence attacks either introduce significant ap-proximation errors, or are too time-consuming. We therefore propose MARGINATTACK, a zero-confidence attack framework that is able to compute the margin with improved accuracy and efficiency. Our experiments show that MARGINATTACK is able to compute a smaller margin than the state-of-the-art zero-confidence attacks, and matches the state-of-the-art fix-perturbation at-tacks. In addition, it runs significantly faster than the Carlini-Wagner attack, currently the most ac-curate zero-confidence attack algorithm.
Simple yet Effective Bridge Reasoning for Open-Domain Multi-Hop Question Answering
Sep 17, 2019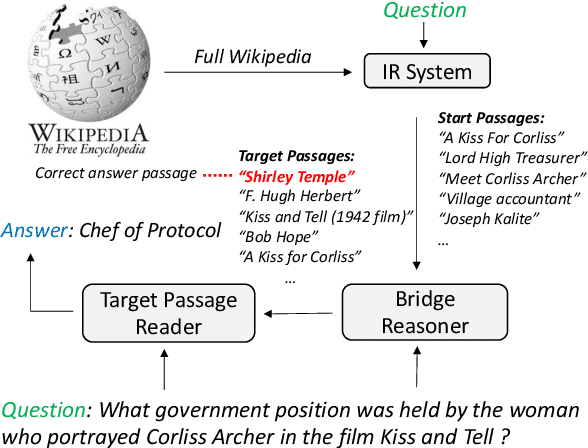

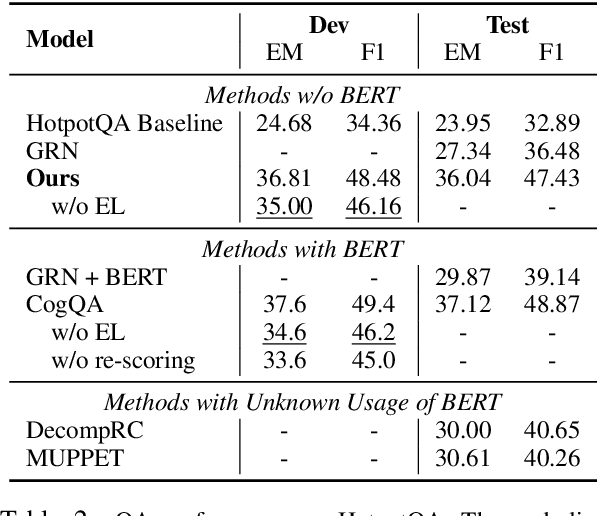
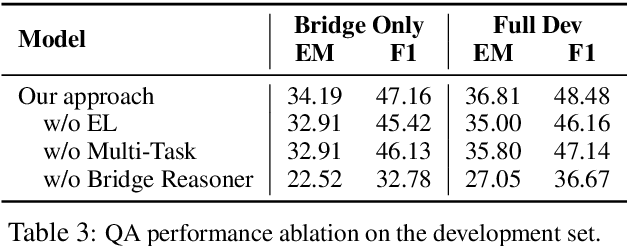
A key challenge of multi-hop question answering (QA) in the open-domain setting is to accurately retrieve the supporting passages from a large corpus. Existing work on open-domain QA typically relies on off-the-shelf information retrieval (IR) techniques to retrieve \textbf{answer passages}, i.e., the passages containing the groundtruth answers. However, IR-based approaches are insufficient for multi-hop questions, as the topic of the second or further hops is not explicitly covered by the question. To resolve this issue, we introduce a new sub-problem of open-domain multi-hop QA, which aims to recognize the bridge (\emph{i.e.}, the anchor that links to the answer passage) from the context of a set of start passages with a reading comprehension model. This model, the \textbf{bridge reasoner}, is trained with a weakly supervised signal and produces the candidate answer passages for the \textbf{passage reader} to extract the answer. On the full-wiki HotpotQA benchmark, we significantly improve the baseline method by 14 point F1. Without using any memory-inefficient contextual embeddings, our result is also competitive with the state-of-the-art that applies BERT in multiple modules.
Out-of-Domain Detection for Low-Resource Text Classification Tasks
Aug 31, 2019
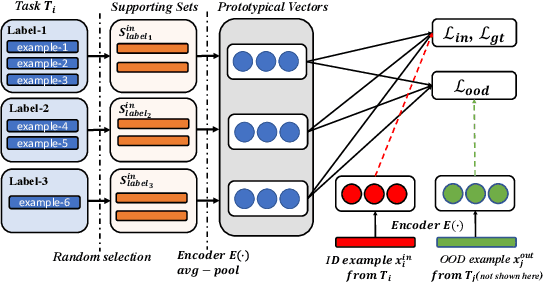
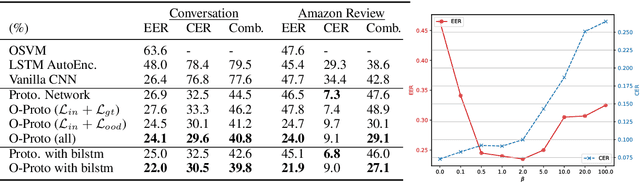
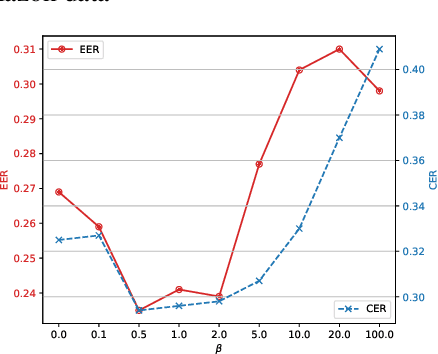
Out-of-domain (OOD) detection for low-resource text classification is a realistic but understudied task. The goal is to detect the OOD cases with limited in-domain (ID) training data, since we observe that training data is often insufficient in machine learning applications. In this work, we propose an OOD-resistant Prototypical Network to tackle this zero-shot OOD detection and few-shot ID classification task. Evaluation on real-world datasets show that the proposed solution outperforms state-of-the-art methods in zero-shot OOD detection task, while maintaining a competitive performance on ID classification task.
Few-shot Text Classification with Distributional Signatures
Aug 16, 2019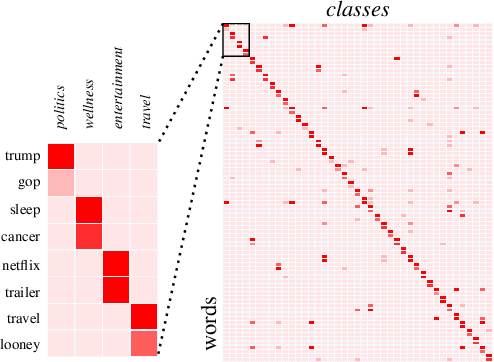
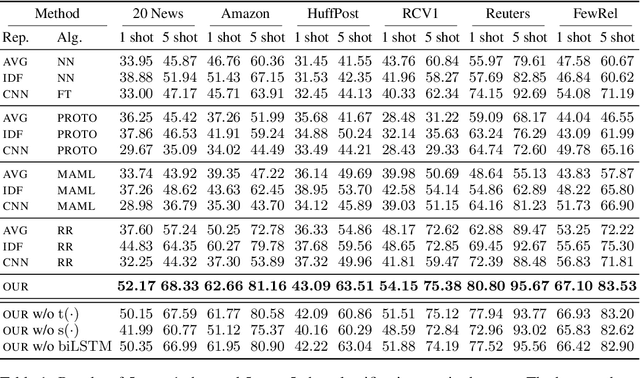

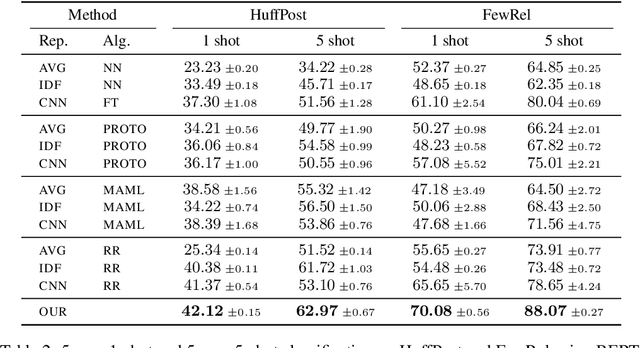
In this paper, we explore meta-learning for few-shot text classification. Meta-learning has shown strong performance in computer vision, where low-level patterns are transferable across learning tasks. However, directly applying this approach to text is challenging--words highly informative for one task may have little significance for another. Thus, rather than learning solely from words, our model also leverages their distributional signatures, which encode pertinent word occurrence patterns. Our model is trained within a meta-learning framework to map these signatures into attention scores, which are then used to weight the lexical representations of words. We demonstrate that our model consistently outperforms prototypical networks in both few-shot text classification and relation classification by a significant margin across six benchmark datasets (19.96% on average in 1-shot classification). Our code is available at https://github.com/YujiaBao/Distributional-Signatures.
Meta Reasoning over Knowledge Graphs
Aug 13, 2019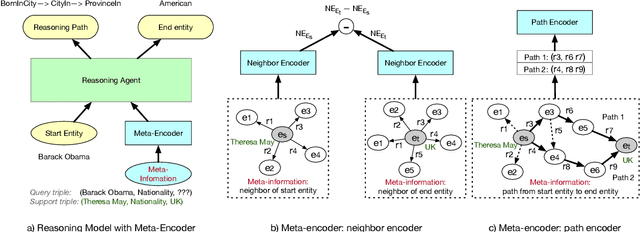
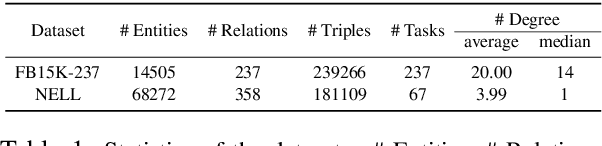
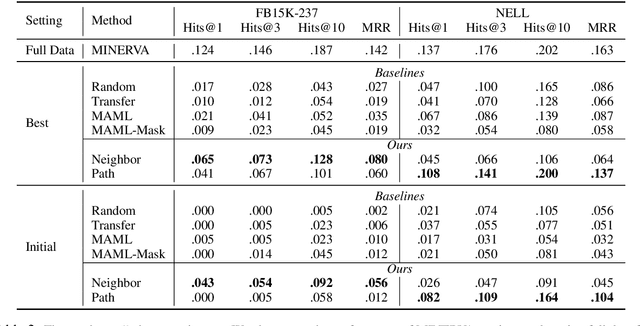
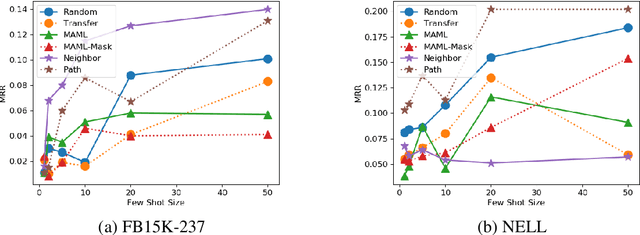
The ability to reason over learned knowledge is an innate ability for humans and humans can easily master new reasoning rules with only a few demonstrations. While most existing studies on knowledge graph (KG) reasoning assume enough training examples, we study the challenging and practical problem of few-shot knowledge graph reasoning under the paradigm of meta-learning. We propose a new meta learning framework that effectively utilizes the task-specific meta information such as local graph neighbors and reasoning paths in KGs. Specifically, we design a meta-encoder that encodes the meta information into task-specific initialization parameters for different tasks. This allows our reasoning module to have diverse starting points when learning to reason over different relations, which is expected to better fit the target task. On two few-shot knowledge base completion benchmarks, we show that the augmented task-specific meta-encoder yields much better initial point than MAML and outperforms several few-shot learning baselines.
AutoGAN: Neural Architecture Search for Generative Adversarial Networks
Aug 11, 2019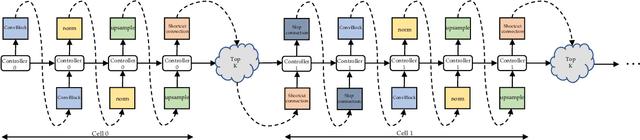
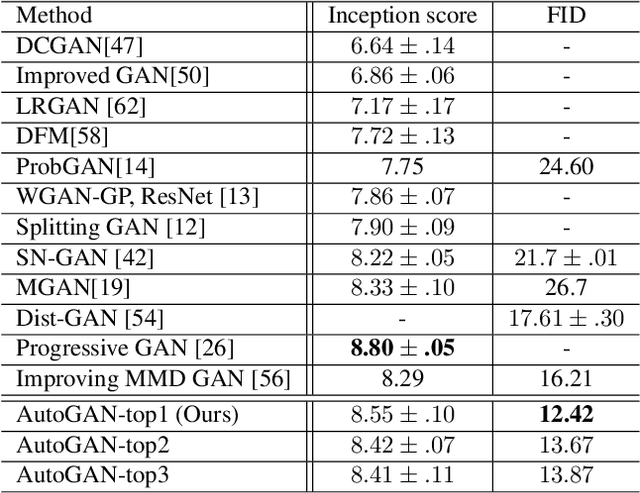
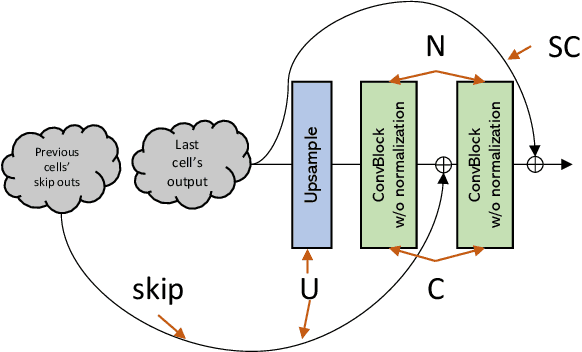
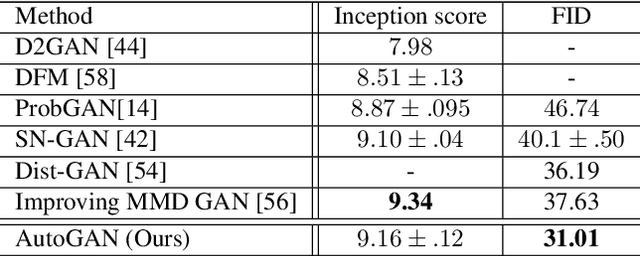
Neural architecture search (NAS) has witnessed prevailing success in image classification and (very recently) segmentation tasks. In this paper, we present the first preliminary study on introducing the NAS algorithm to generative adversarial networks (GANs), dubbed AutoGAN. The marriage of NAS and GANs faces its unique challenges. We define the search space for the generator architectural variations and use an RNN controller to guide the search, with parameter sharing and dynamic-resetting to accelerate the process. Inception score is adopted as the reward, and a multi-level search strategy is introduced to perform NAS in a progressive way. Experiments validate the effectiveness of AutoGAN on the task of unconditional image generation. Specifically, our discovered architectures achieve highly competitive performance compared to current state-of-the-art hand-crafted GANs, e.g., setting new state-of-the-art FID scores of 12.42 on CIFAR-10, and 31.01 on STL-10, respectively. We also conclude with a discussion of the current limitations and future potential of AutoGAN. The code is available at https://github.com/TAMU-VITA/AutoGAN