 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniRBT: A Two-stage Distilled Small Chinese Pre-trained Model
Apr 03, 2023



In natural language processing, pre-trained language models have become essential infrastructures. However, these models often suffer from issues such as large size, long inference time, and challenging deployment. Moreover, most mainstream pre-trained models focus on English, and there are insufficient studies on small Chinese pre-trained models. In this paper, we introduce MiniRBT, a small Chinese pre-trained model that aims to advance research in Chinese natural language processing. MiniRBT employs a narrow and deep student model and incorporates whole word masking and two-stage distillation during pre-training to make it well-suited for most downstream tasks. Our experiments on machine reading comprehension and text classification tasks reveal that MiniRBT achieves 94% performance relative to RoBERTa, while providing a 6.8x speedup, demonstrating its effectiveness and efficiency.
Towards a Holistic Understanding of Mathematical Questions with Contrastive Pre-training
Jan 18, 2023



Understanding mathematical questions effectively is a crucial task, which can benefit many applications, such as difficulty estimation. Researchers have drawn much attention to designing pre-training models for question representations due to the scarcity of human annotations (e.g., labeling difficulty). However, unlike general free-format texts (e.g., user comments), mathematical questions are generally designed with explicit purposes and mathematical logic, and usually consist of more complex content, such as formulas, and related mathematical knowledge (e.g., Function). Therefore, the problem of holistically representing mathematical questions remains underexplored. To this end, in this paper, we propose a novel contrastive pre-training approach for mathematical question representations, namely QuesCo, which attempts to bring questions with more similar purposes closer. Specifically, we first design two-level question augmentations, including content-level and structure-level, which generate literally diverse question pairs with similar purposes. Then, to fully exploit hierarchical information of knowledge concepts, we propose a knowledge hierarchy-aware rank strategy (KHAR), which ranks the similarities between questions in a fine-grained manner. Next, we adopt a ranking contrastive learning task to optimize our model based on the augmented and ranked questions. We conduct extensive experiments on two real-world mathematical datasets. The experimental results demonstrate the effectiveness of our model.
Gradient-based Intra-attention Pruning on Pre-trained Language Models
Dec 15, 2022



Pre-trained language models achieve superior performance, but they are computationally expensive due to their large size. Techniques such as pruning and knowledge distillation (KD) have been developed to reduce their size and latency. In most structural pruning methods, the pruning units, such as attention heads and feed-forward hidden dimensions, only span a small model structure space and limit the structures that the pruning algorithm can explore. In this work, we propose Gradient-based Intra-attention pruning (GRAIN), which inspects fine intra-attention structures, and allows different heads to have different sizes. Intra-attention pruning greatly expands the searching space of model structures and yields highly heterogeneous structures. We further propose structure regularization to encourage generating more regular structures, which achieves higher speedups than heterogeneous ones. We also integrate KD into the pruning process with a gradient separation strategy to reduce the interference of KD with the pruning process. GRAIN is evaluated on a variety of tasks. Results show that it notably outperforms other methods at the same or similar model size. Even under extreme compression where only $3\%$ weights in transformers remain, the pruned model is still competitive.
LERT: A Linguistically-motivated Pre-trained Language Model
Nov 10, 2022



Pre-trained Language Model (PLM) has become a representative foundation model in the natural language processing field. Most PLMs are trained with linguistic-agnostic pre-training tasks on the surface form of the text, such as the masked language model (MLM). To further empower the PLMs with richer linguistic features, in this paper, we aim to propose a simple but effective way to learn linguistic features for pre-trained language models. We propose LERT, a pre-trained language model that is trained on three types of linguistic features along with the original MLM pre-training task, using a linguistically-informed pre-training (LIP) strategy. We carried out extensive experiments on ten Chinese NLU tasks, and the experimental results show that LERT could bring significant improvements over various comparable baselines. Furthermore, we also conduct analytical experiments in various linguistic aspects, and the results prove that the design of LERT is valid and effective. Resources are available at https://github.com/ymcui/LERT
Overview of CTC 2021: Chinese Text Correction for Native Speakers
Aug 11, 2022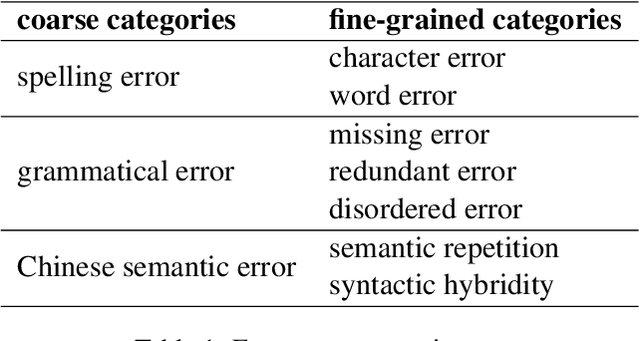
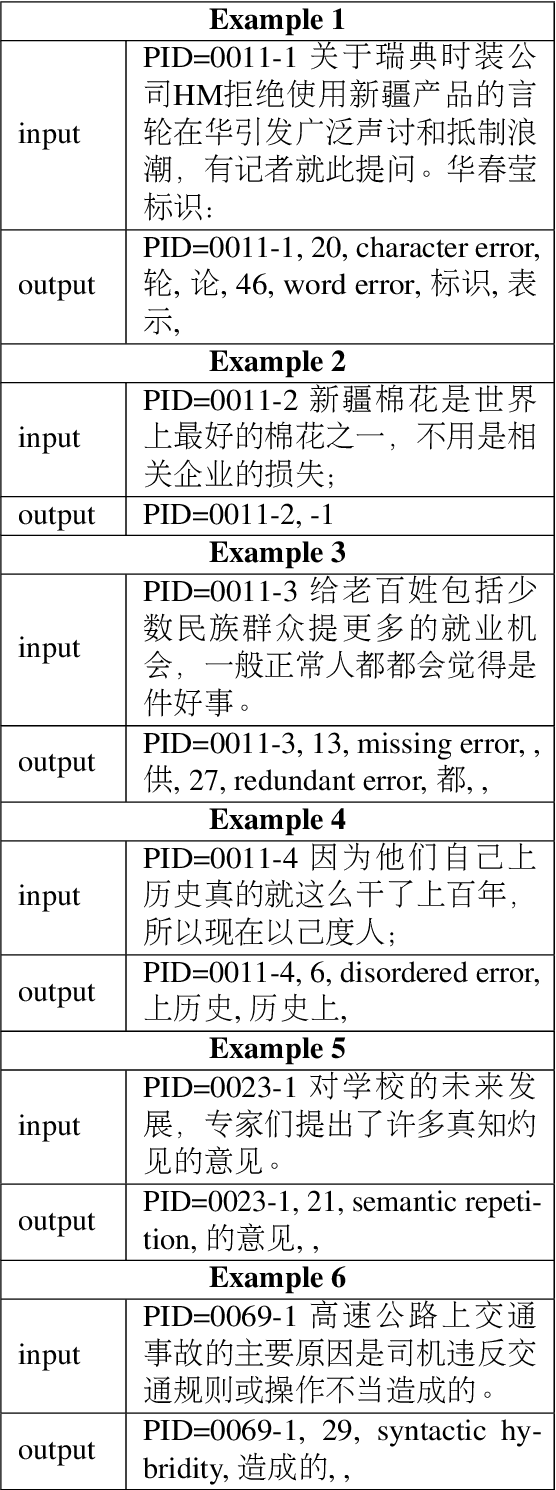
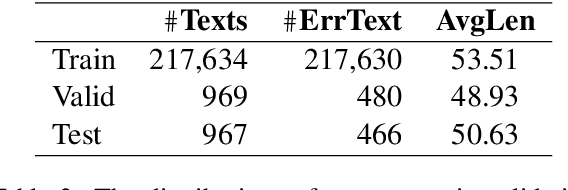

In this paper, we present an overview of the CTC 2021, a Chinese text correction task for native speakers. We give detailed descriptions of the task definition and the data for training as well as evaluation. We also summarize the approaches investigated by the participants of this task. We hope the data sets collected and annotated for this task can facilitate and expedite future development in this research area. Therefore, the pseudo training data, gold standards validation data, and entire leaderboard is publicly available online at https://destwang.github.io/CTC2021-explorer/.
JiuZhang: A Chinese Pre-trained Language Model for Mathematical Problem Understanding
Jun 13, 2022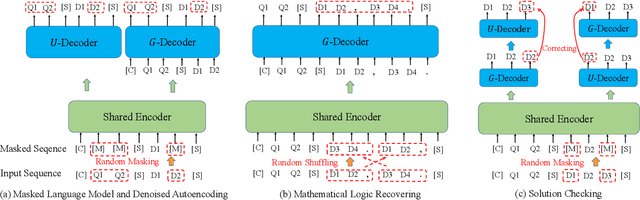
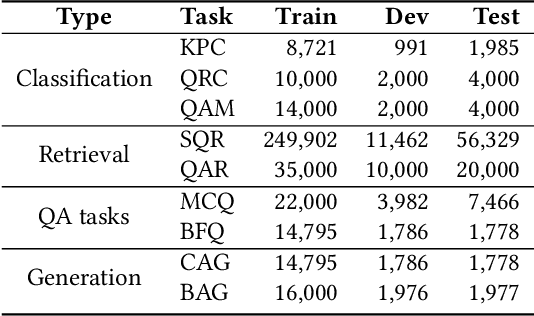
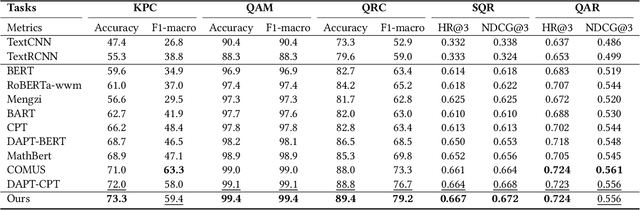

This paper aims to advance the mathematical intelligence of machines by presenting the first Chinese mathematical pre-trained language model~(PLM) for effectively understanding and representing mathematical problems. Unlike other standard NLP tasks, mathematical texts are difficult to understand, since they involve mathematical terminology, symbols and formulas in the problem statement. Typically, it requires complex mathematical logic and background knowledge for solving mathematical problems. Considering the complex nature of mathematical texts, we design a novel curriculum pre-training approach for improving the learning of mathematical PLMs, consisting of both basic and advanced courses. Specially, we first perform token-level pre-training based on a position-biased masking strategy, and then design logic-based pre-training tasks that aim to recover the shuffled sentences and formulas, respectively. Finally, we introduce a more difficult pre-training task that enforces the PLM to detect and correct the errors in its generated solutions. We conduct extensive experiments on offline evaluation (including nine math-related tasks) and online $A/B$ test. Experimental results demonstrate the effectiveness of our approach compared with a number of competitive baselines. Our code is available at: \textcolor{blue}{\url{https://github.com/RUCAIBox/JiuZhang}}.
Cross-Lingual Text Classification with Multilingual Distillation and Zero-Shot-Aware Training
Feb 28, 2022Multilingual pre-trained language models (MPLMs) not only can handle tasks in different languages but also exhibit surprising zero-shot cross-lingual transferability. However, MPLMs usually are not able to achieve comparable supervised performance on rich-resource languages compared to the state-of-the-art monolingual pre-trained models. In this paper, we aim to improve the multilingual model's supervised and zero-shot performance simultaneously only with the resources from supervised languages. Our approach is based on transferring knowledge from high-performance monolingual models with a teacher-student framework. We let the multilingual model learn from multiple monolingual models simultaneously. To exploit the model's cross-lingual transferability, we propose MBLM (multi-branch multilingual language model), a model built on the MPLMs with multiple language branches. Each branch is a stack of transformers. MBLM is trained with the zero-shot-aware training strategy that encourages the model to learn from the mixture of zero-shot representations from all the branches. The results on two cross-lingual classification tasks show that, with only the task's supervised data used, our method improves both the supervised and zero-shot performance of MPLMs.
InterHT: Knowledge Graph Embeddings by Interaction between Head and Tail Entities
Feb 10, 2022
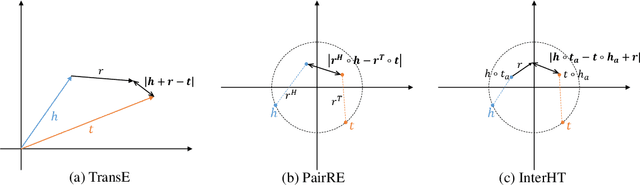
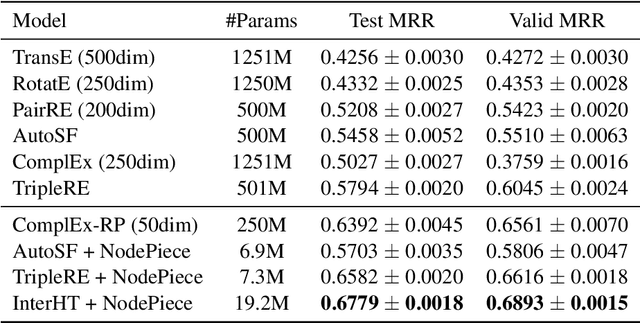
Knowledge graph embedding (KGE) models learn the representation of entities and relations in knowledge graphs. Distance-based methods show promising performance on link prediction task, which predicts the result by the distance between two entity representations. However, most of these methods represent the head entity and tail entity separately, which limits the model capacity. We propose a novel distance-based method named InterHT that allows the head and tail entities to interact better and get better entity representation. Experimental results show that our proposed method achieves the best results on ogbl-wikikg2 dataset.
Adversarial Training for Machine Reading Comprehension with Virtual Embeddings
Jun 08, 2021Adversarial training (AT) as a regularization method has proved its effectiveness on various tasks. Though there are successful applications of AT on some NLP tasks, the distinguishing characteristics of NLP tasks have not been exploited. In this paper, we aim to apply AT on machine reading comprehension (MRC) tasks. Furthermore, we adapt AT for MRC tasks by proposing a novel adversarial training method called PQAT that perturbs the embedding matrix instead of word vectors. To differentiate the roles of passages and questions, PQAT uses additional virtual P/Q-embedding matrices to gather the global perturbations of words from passages and questions separately. We test the method on a wide range of MRC tasks, including span-based extractive RC and multiple-choice RC. The results show that adversarial training is effective universally, and PQAT further improves the performance.
Bilingual Alignment Pre-training for Zero-shot Cross-lingual Transfer
Jun 03, 2021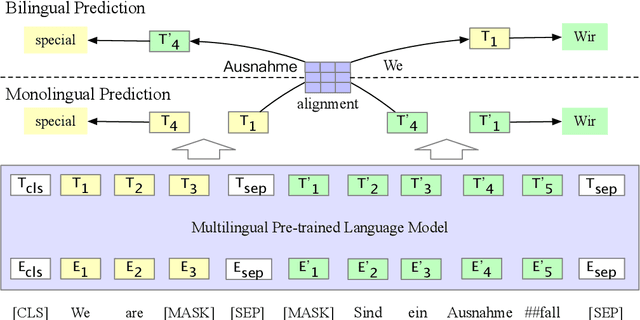
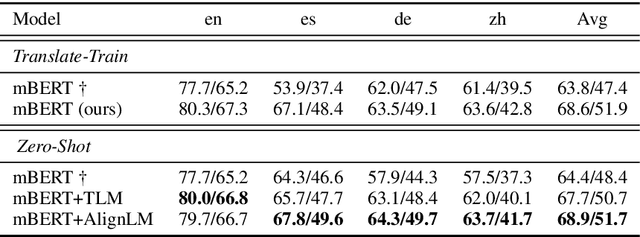
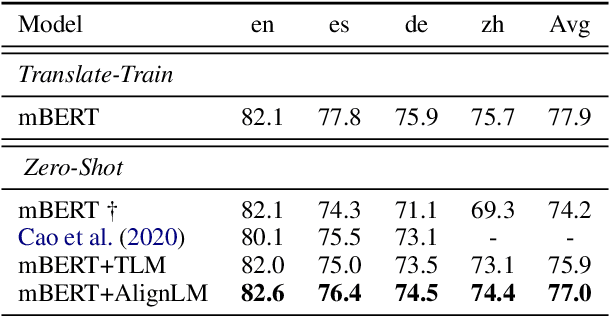
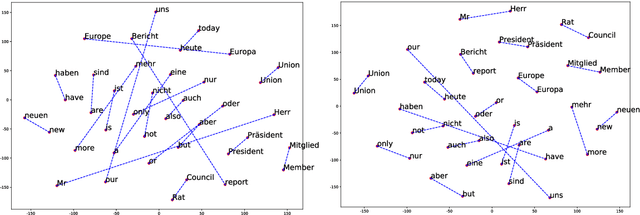
Multilingual pre-trained models have achieved remarkable transfer performance by pre-trained on rich kinds of languages. Most of the models such as mBERT are pre-trained on unlabeled corpora. The static and contextual embeddings from the models could not be aligned very well. In this paper, we aim to improve the zero-shot cross-lingual transfer performance by aligning the embeddings better. We propose a pre-training task named Alignment Language Model (AlignLM), which uses the statistical alignment information as the prior knowledge to guide bilingual word prediction. We evaluate our method on multilingual machine reading comprehension and natural language interface tasks. The results show AlignLM can improve the zero-shot performance significantly on MLQA and XNLI datasets.