 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal Face Foundation Representation Learning for Generalized Deepfake Detection
Mar 15, 2023



The emergence of deepfake technologies has become a matter of social concern as they pose threats to individual privacy and public security. It is now of great significance to develop reliable deepfake detectors. However, with numerous face manipulation algorithms present, it is almost impossible to collect sufficient representative fake faces, and it is hard for existing detectors to generalize to all types of manipulation. Therefore, we turn to learn the distribution of real faces, and indirectly identify fake images that deviate from the real face distribution. In this study, we propose Real Face Foundation Representation Learning (RFFR), which aims to learn a general representation from large-scale real face datasets and detect potential artifacts outside the distribution of RFFR. Specifically, we train a model on real face datasets by masked image modeling (MIM), which results in a discrepancy between input faces and the reconstructed ones when applying the model on fake samples. This discrepancy reveals the low-level artifacts not contained in RFFR, making it easier to build a deepfake detector sensitive to all kinds of potential artifacts outside the distribution of RFFR. Extensive experiments demonstrate that our method brings about better generalization performance, as it significantly outperforms the state-of-the-art methods in cross-manipulation evaluations, and has the potential to further improve by introducing extra real faces for training RFFR.
Diversity-Measurable Anomaly Detection
Mar 09, 2023



Reconstruction-based anomaly detection models achieve their purpose by suppressing the generalization ability for anomaly. However, diverse normal patterns are consequently not well reconstructed as well. Although some efforts have been made to alleviate this problem by modeling sample diversity, they suffer from shortcut learning due to undesired transmission of abnormal information. In this paper, to better handle the tradeoff problem, we propose Diversity-Measurable Anomaly Detection (DMAD) framework to enhance reconstruction diversity while avoid the undesired generalization on anomalies. To this end, we design Pyramid Deformation Module (PDM), which models diverse normals and measures the severity of anomaly by estimating multi-scale deformation fields from reconstructed reference to original input. Integrated with an information compression module, PDM essentially decouples deformation from prototypical embedding and makes the final anomaly score more reliable. Experimental results on both surveillance videos and industrial images demonstrate the effectiveness of our method. In addition, DMAD works equally well in front of contaminated data and anomaly-like normal samples.
Hierarchical Compositional Representations for Few-shot Action Recognition
Aug 19, 2022
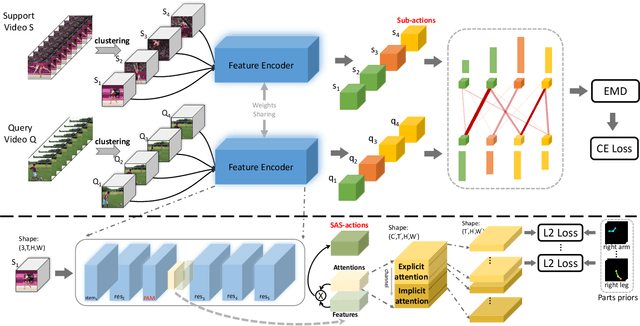
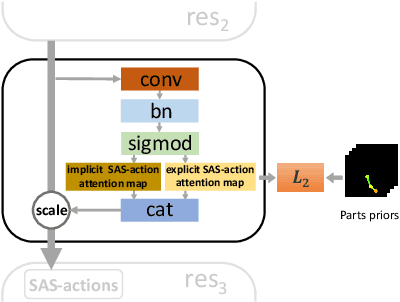
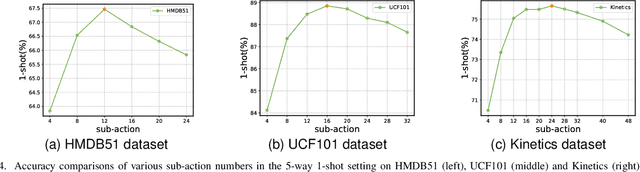
Recently action recognition has received more and more attention for its comprehensive and practical applications in intelligent surveillance and human-computer interaction. However, few-shot action recognition has not been well explored and remains challenging because of data scarcity. In this paper, we propose a novel hierarchical compositional representations (HCR) learning approach for few-shot action recognition. Specifically, we divide a complicated action into several sub-actions by carefully designed hierarchical clustering and further decompose the sub-actions into more fine-grained spatially attentional sub-actions (SAS-actions). Although there exist large differences between base classes and novel classes, they can share similar patterns in sub-actions or SAS-actions. Furthermore, we adopt the Earth Mover's Distance in the transportation problem to measure the similarity between video samples in terms of sub-action representations. It computes the optimal matching flows between sub-actions as distance metric, which is favorable for comparing fine-grained patterns. Extensive experiments show our method achieves the state-of-the-art results on HMDB51, UCF101 and Kinetics datasets.
MAFW: A Large-scale, Multi-modal, Compound Affective Database for Dynamic Facial Expression Recognition in the Wild
Aug 01, 2022
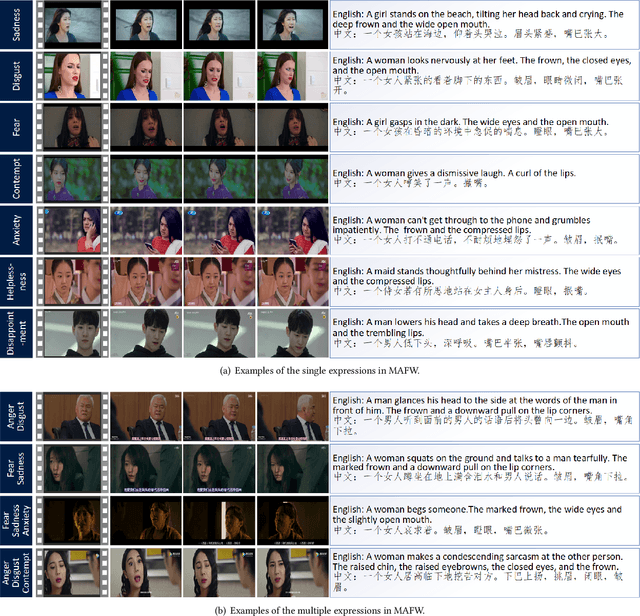
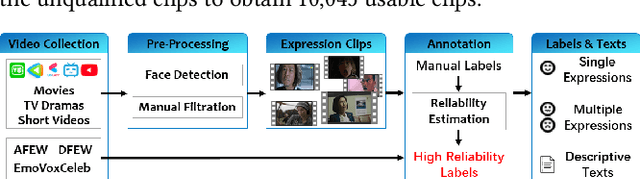
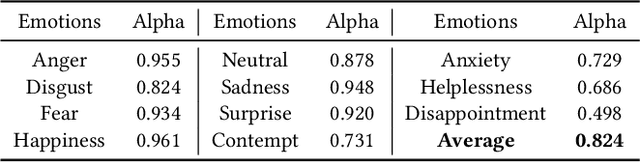
Dynamic facial expression recognition (FER) databases provide important data support for affective computing and applications. However, most FER databases are annotated with several basic mutually exclusive emotional categories and contain only one modality, e.g., videos. The monotonous labels and modality cannot accurately imitate human emotions and fulfill applications in the real world. In this paper, we propose MAFW, a large-scale multi-modal compound affective database with 10,045 video-audio clips in the wild. Each clip is annotated with a compound emotional category and a couple of sentences that describe the subjects' affective behaviors in the clip. For the compound emotion annotation, each clip is categorized into one or more of the 11 widely-used emotions, i.e., anger, disgust, fear, happiness, neutral, sadness, surprise, contempt, anxiety, helplessness, and disappointment. To ensure high quality of the labels, we filter out the unreliable annotations by an Expectation Maximization (EM) algorithm, and then obtain 11 single-label emotion categories and 32 multi-label emotion categories. To the best of our knowledge, MAFW is the first in-the-wild multi-modal database annotated with compound emotion annotations and emotion-related captions. Additionally, we also propose a novel Transformer-based expression snippet feature learning method to recognize the compound emotions leveraging the expression-change relations among different emotions and modalities. Extensive experiments on MAFW database show the advantages of the proposed method over other state-of-the-art methods for both uni- and multi-modal FER. Our MAFW database is publicly available from https://mafw-database.github.io/MAFW.
UniCon+: ICTCAS-UCAS Submission to the AVA-ActiveSpeaker Task at ActivityNet Challenge 2022
Jun 22, 2022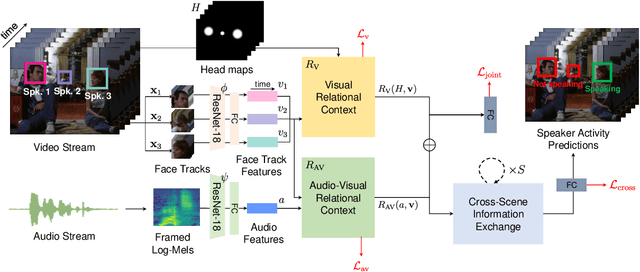
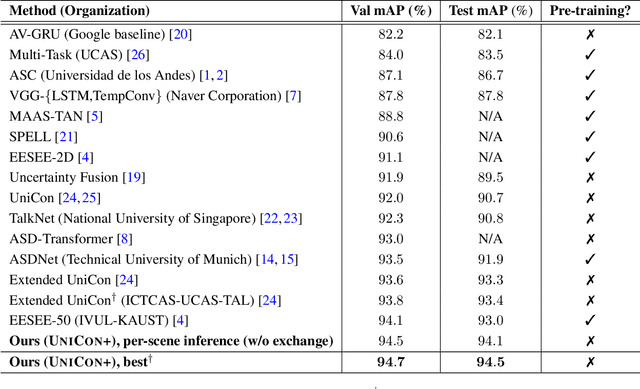
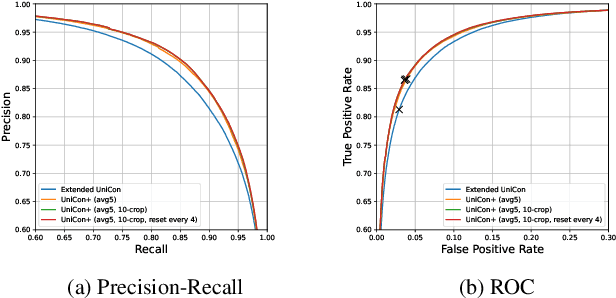
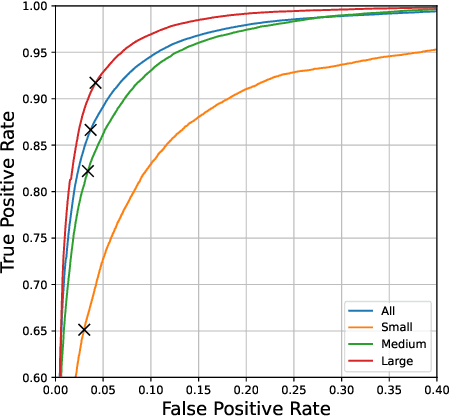
This report presents a brief description of our winning solution to the AVA Active Speaker Detection (ASD) task at ActivityNet Challenge 2022. Our underlying model UniCon+ continues to build on our previous work, the Unified Context Network (UniCon) and Extended UniCon which are designed for robust scene-level ASD. We augment the architecture with a simple GRU-based module that allows information of recurring identities to flow across scenes through read and update operations. We report a best result of 94.47% mAP on the AVA-ActiveSpeaker test set, which continues to rank first on this year's challenge leaderboard and significantly pushes the state-of-the-art.
Clothes-Changing Person Re-identification with RGB Modality Only
Apr 14, 2022
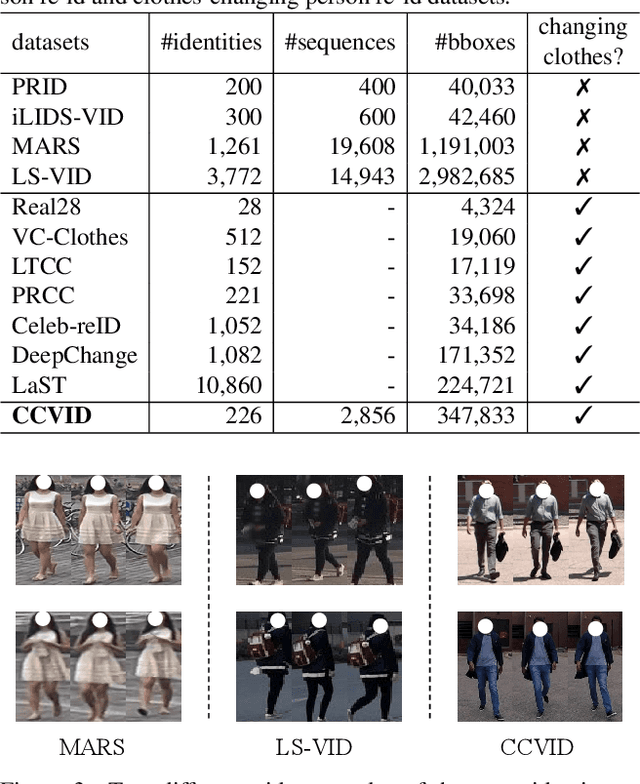
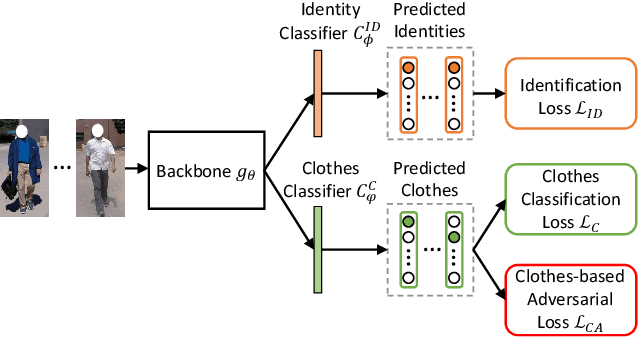
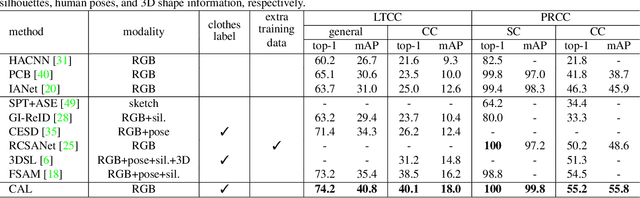
The key to address clothes-changing person re-identification (re-id) is to extract clothes-irrelevant features, e.g., face, hairstyle, body shape, and gait. Most current works mainly focus on modeling body shape from multi-modality information (e.g., silhouettes and sketches), but do not make full use of the clothes-irrelevant information in the original RGB images. In this paper, we propose a Clothes-based Adversarial Loss (CAL) to mine clothes-irrelevant features from the original RGB images by penalizing the predictive power of re-id model w.r.t. clothes. Extensive experiments demonstrate that using RGB images only, CAL outperforms all state-of-the-art methods on widely-used clothes-changing person re-id benchmarks. Besides, compared with images, videos contain richer appearance and additional temporal information, which can be used to model proper spatiotemporal patterns to assist clothes-changing re-id. Since there is no publicly available clothes-changing video re-id dataset, we contribute a new dataset named CCVID and show that there exists much room for improvement in modeling spatiotemporal information. The code and new dataset are available at: https://github.com/guxinqian/Simple-CCReID.
Joint Feature Learning and Relation Modeling for Tracking: A One-Stream Framework
Mar 24, 2022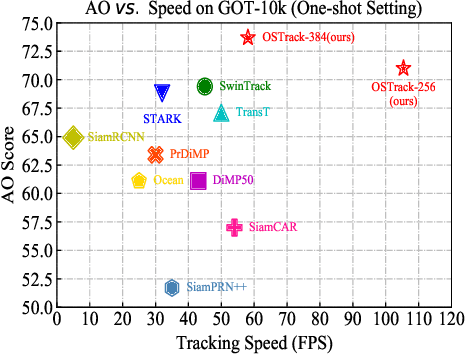
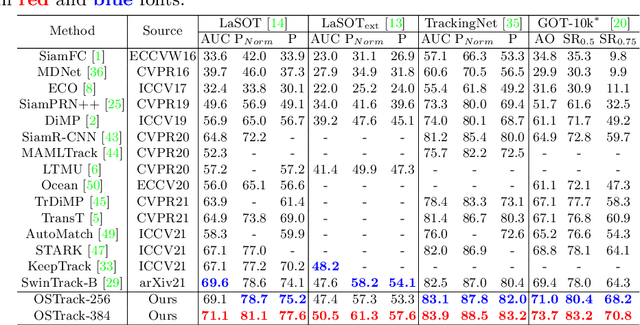
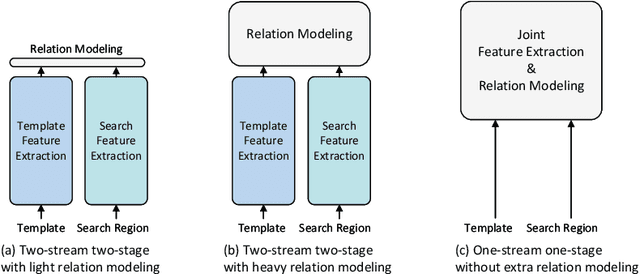

The current popular two-stream, two-stage tracking framework extracts the template and the search region features separately and then performs relation modeling, thus the extracted features lack the awareness of the target and have limited target-background discriminability. To tackle the above issue, we propose a novel one-stream tracking (OSTrack) framework that unifies feature learning and relation modeling by bridging the template-search image pairs with bidirectional information flows. In this way, discriminative target-oriented features can be dynamically extracted by mutual guidance. Since no extra heavy relation modeling module is needed and the implementation is highly parallelized, the proposed tracker runs at a fast speed. To further improve the inference efficiency, an in-network candidate early elimination module is proposed based on the strong similarity prior calculated in the one-stream framework. As a unified framework, OSTrack achieves state-of-the-art performance on multiple benchmarks, in particular, it shows impressive results on the one-shot tracking benchmark GOT-10k, i.e., achieving 73.7% AO, improving the existing best result (SwinTrack) by 4.3%. Besides, our method maintains a good performance-speed trade-off and shows faster convergence. The code and models will be available at https://github.com/botaoye/OSTrack.
Adaptive Image Transformations for Transfer-based Adversarial Attack
Nov 27, 2021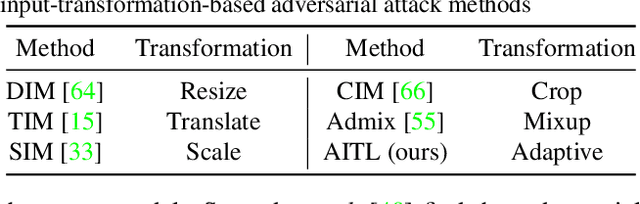
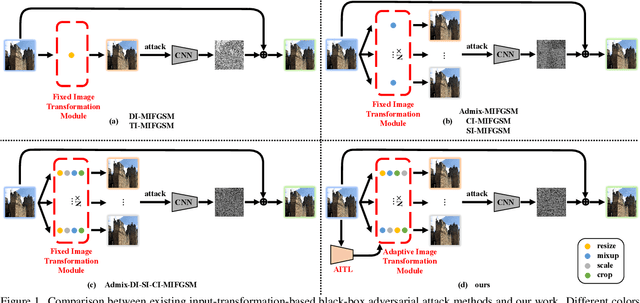
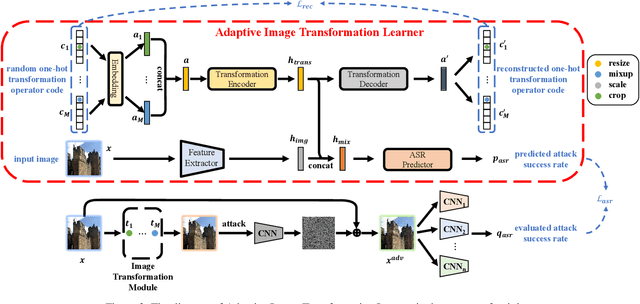
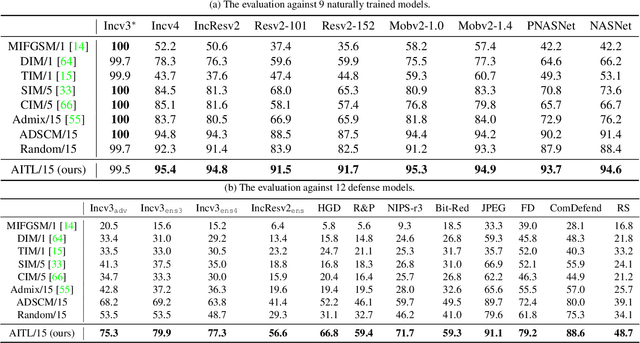
Adversarial attacks provide a good way to study the robustness of deep learning models. One category of methods in transfer-based black-box attack utilizes several image transformation operations to improve the transferability of adversarial examples, which is effective, but fails to take the specific characteristic of the input image into consideration. In this work, we propose a novel architecture, called Adaptive Image Transformation Learner (AITL), which incorporates different image transformation operations into a unified framework to further improve the transferability of adversarial examples. Unlike the fixed combinational transformations used in existing works, our elaborately designed transformation learner adaptively selects the most effective combination of image transformations specific to the input image. Extensive experiments on ImageNet demonstrate that our method significantly improves the attack success rates on both normally trained models and defense models under various settings.
Adaptive Perturbation for Adversarial Attack
Nov 27, 2021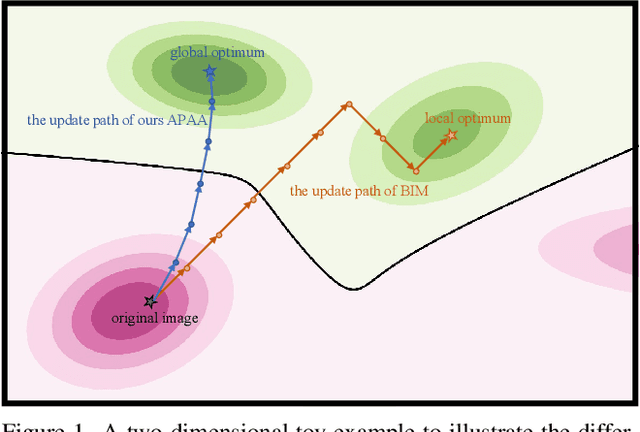
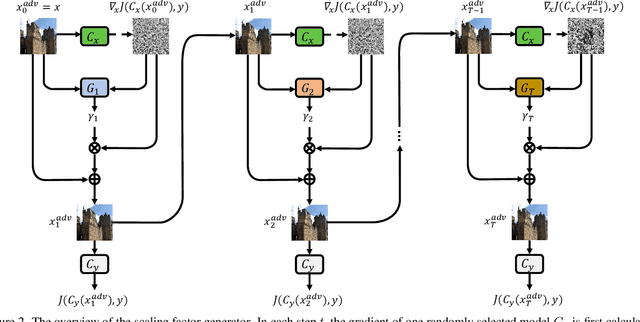
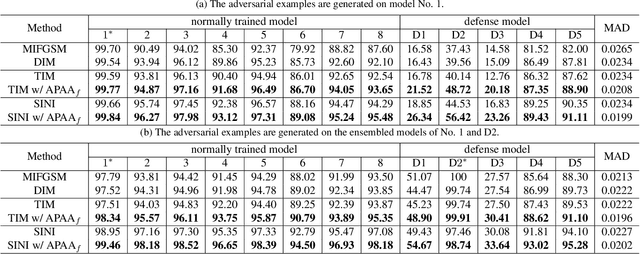
In recent years, the security of deep learning models achieves more and more attentions with the rapid development of neural networks, which are vulnerable to adversarial examples. Almost all existing gradient-based attack methods use the sign function in the generation to meet the requirement of perturbation budget on $L_\infty$ norm. However, we find that the sign function may be improper for generating adversarial examples since it modifies the exact gradient direction. We propose to remove the sign function and directly utilize the exact gradient direction with a scaling factor for generating adversarial perturbations, which improves the attack success rates of adversarial examples even with fewer perturbations. Moreover, considering that the best scaling factor varies across different images, we propose an adaptive scaling factor generator to seek an appropriate scaling factor for each image, which avoids the computational cost for manually searching the scaling factor. Our method can be integrated with almost all existing gradient-based attack methods to further improve the attack success rates. Extensive experiments on the CIFAR10 and ImageNet datasets show that our method exhibits higher transferability and outperforms the state-of-the-art methods.
Learning Fair Face Representation With Progressive Cross Transformer
Aug 11, 2021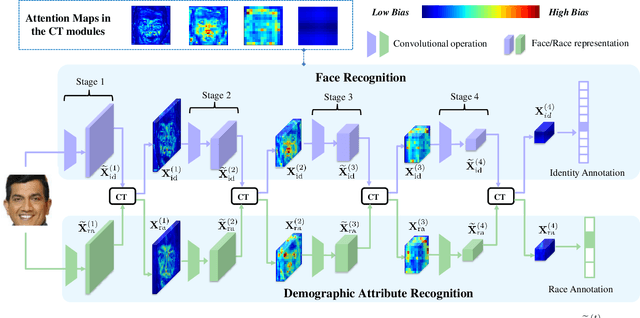
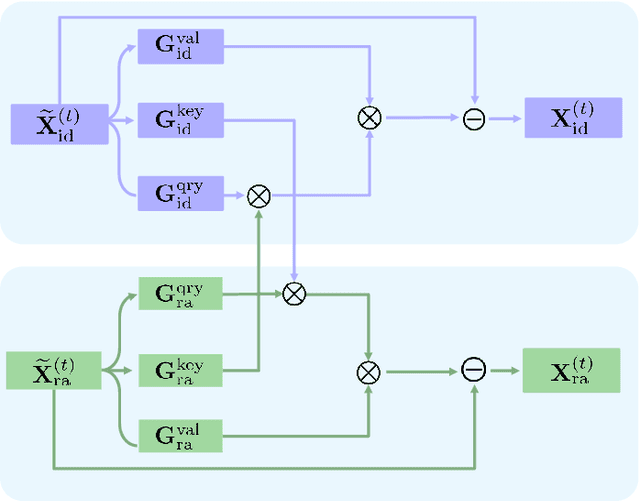
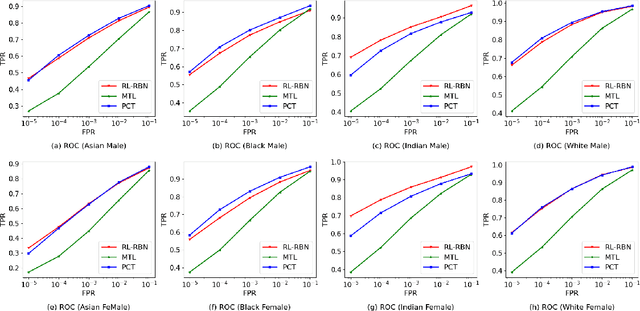
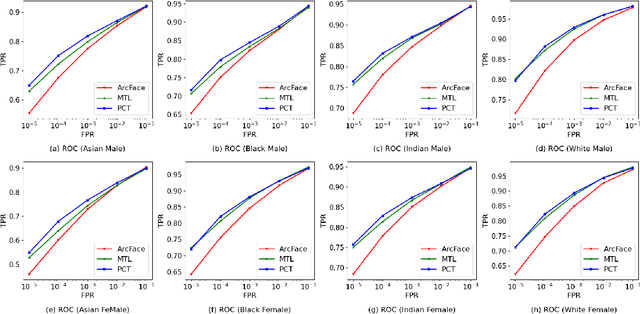
Face recognition (FR) has made extraordinary progress owing to the advancement of deep convolutional neural networks. However, demographic bias among different racial cohorts still challenges the practical face recognition system. The race factor has been proven to be a dilemma for fair FR (FFR) as the subject-related specific attributes induce the classification bias whilst carrying some useful cues for FR. To mitigate racial bias and meantime preserve robust FR, we abstract face identity-related representation as a signal denoising problem and propose a progressive cross transformer (PCT) method for fair face recognition. Originating from the signal decomposition theory, we attempt to decouple face representation into i) identity-related components and ii) noisy/identity-unrelated components induced by race. As an extension of signal subspace decomposition, we formulate face decoupling as a generalized functional expression model to cross-predict face identity and race information. The face expression model is further concretized by designing dual cross-transformers to distill identity-related components and suppress racial noises. In order to refine face representation, we take a progressive face decoupling way to learn identity/race-specific transformations, so that identity-unrelated components induced by race could be better disentangled. We evaluate the proposed PCT on the public fair face recognition benchmarks (BFW, RFW) and verify that PCT is capable of mitigating bias in face recognition while achieving state-of-the-art FR performance. Besides, visualization results also show that the attention maps in PCT can well reveal the race-related/biased facial regions.