 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT2VAttack: Adversarial Attack on Text-to-Video Diffusion Models
Dec 30, 2025The rapid evolution of Text-to-Video (T2V) diffusion models has driven remarkable advancements in generating high-quality, temporally coherent videos from natural language descriptions. Despite these achievements, their vulnerability to adversarial attacks remains largely unexplored. In this paper, we introduce T2VAttack, a comprehensive study of adversarial attacks on T2V diffusion models from both semantic and temporal perspectives. Considering the inherently dynamic nature of video data, we propose two distinct attack objectives: a semantic objective to evaluate video-text alignment and a temporal objective to assess the temporal dynamics. To achieve an effective and efficient attack process, we propose two adversarial attack methods: (i) T2VAttack-S, which identifies semantically or temporally critical words in prompts and replaces them with synonyms via greedy search, and (ii) T2VAttack-I, which iteratively inserts optimized words with minimal perturbation to the prompt. By combining these objectives and strategies, we conduct a comprehensive evaluation on the adversarial robustness of several state-of-the-art T2V models, including ModelScope, CogVideoX, Open-Sora, and HunyuanVideo. Our experiments reveal that even minor prompt modifications, such as the substitution or insertion of a single word, can cause substantial degradation in semantic fidelity and temporal dynamics, highlighting critical vulnerabilities in current T2V diffusion models.
BIMM: Brain Inspired Masked Modeling for Video Representation Learning
May 21, 2024



The visual pathway of human brain includes two sub-pathways, ie, the ventral pathway and the dorsal pathway, which focus on object identification and dynamic information modeling, respectively. Both pathways comprise multi-layer structures, with each layer responsible for processing different aspects of visual information. Inspired by visual information processing mechanism of the human brain, we propose the Brain Inspired Masked Modeling (BIMM) framework, aiming to learn comprehensive representations from videos. Specifically, our approach consists of ventral and dorsal branches, which learn image and video representations, respectively. Both branches employ the Vision Transformer (ViT) as their backbone and are trained using masked modeling method. To achieve the goals of different visual cortices in the brain, we segment the encoder of each branch into three intermediate blocks and reconstruct progressive prediction targets with light weight decoders. Furthermore, drawing inspiration from the information-sharing mechanism in the visual pathways, we propose a partial parameter sharing strategy between the branches during training. Extensive experiments demonstrate that BIMM achieves superior performance compared to the state-of-the-art methods.
Patch Is Not All You Need
Aug 21, 2023Vision Transformers have achieved great success in computer visions, delivering exceptional performance across various tasks. However, their inherent reliance on sequential input enforces the manual partitioning of images into patch sequences, which disrupts the image's inherent structural and semantic continuity. To handle this, we propose a novel Pattern Transformer (Patternformer) to adaptively convert images to pattern sequences for Transformer input. Specifically, we employ the Convolutional Neural Network to extract various patterns from the input image, with each channel representing a unique pattern that is fed into the succeeding Transformer as a visual token. By enabling the network to optimize these patterns, each pattern concentrates on its local region of interest, thereby preserving its intrinsic structural and semantic information. Only employing the vanilla ResNet and Transformer, we have accomplished state-of-the-art performance on CIFAR-10 and CIFAR-100, and have achieved competitive results on ImageNet.
Hierarchical Compositional Representations for Few-shot Action Recognition
Aug 19, 2022
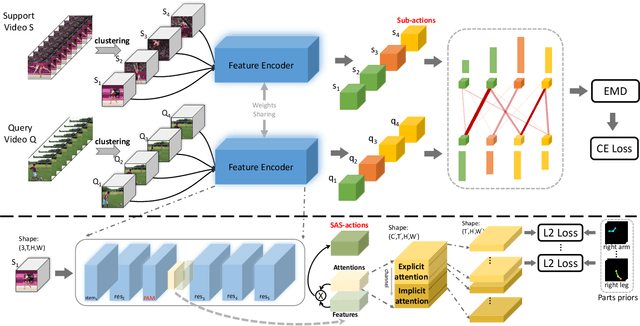
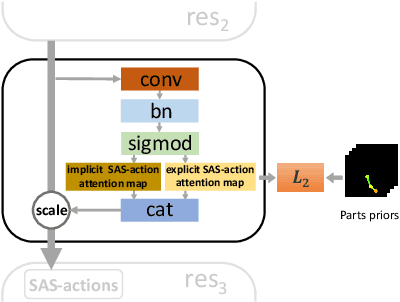
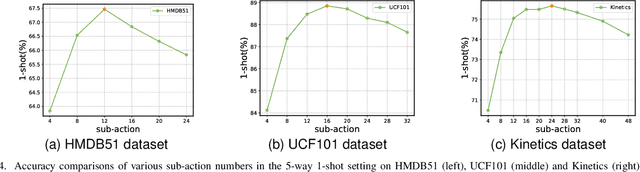
Recently action recognition has received more and more attention for its comprehensive and practical applications in intelligent surveillance and human-computer interaction. However, few-shot action recognition has not been well explored and remains challenging because of data scarcity. In this paper, we propose a novel hierarchical compositional representations (HCR) learning approach for few-shot action recognition. Specifically, we divide a complicated action into several sub-actions by carefully designed hierarchical clustering and further decompose the sub-actions into more fine-grained spatially attentional sub-actions (SAS-actions). Although there exist large differences between base classes and novel classes, they can share similar patterns in sub-actions or SAS-actions. Furthermore, we adopt the Earth Mover's Distance in the transportation problem to measure the similarity between video samples in terms of sub-action representations. It computes the optimal matching flows between sub-actions as distance metric, which is favorable for comparing fine-grained patterns. Extensive experiments show our method achieves the state-of-the-art results on HMDB51, UCF101 and Kinetics datasets.