 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Loss Functions in Recommender Systems: A Comparative Study with a Rényi Divergence-Based Solution
Jun 18, 2025Loss functions play a pivotal role in optimizing recommendation models. Among various loss functions, Softmax Loss (SL) and Cosine Contrastive Loss (CCL) are particularly effective. Their theoretical connections and differences warrant in-depth exploration. This work conducts comprehensive analyses of these losses, yielding significant insights: 1) Common strengths -- both can be viewed as augmentations of traditional losses with Distributional Robust Optimization (DRO), enhancing robustness to distributional shifts; 2) Respective limitations -- stemming from their use of different distribution distance metrics in DRO optimization, SL exhibits high sensitivity to false negative instances, whereas CCL suffers from low data utilization. To address these limitations, this work proposes a new loss function, DrRL, which generalizes SL and CCL by leveraging R\'enyi-divergence in DRO optimization. DrRL incorporates the advantageous structures of both SL and CCL, and can be demonstrated to effectively mitigate their limitations. Extensive experiments have been conducted to validate the superiority of DrRL on both recommendation accuracy and robustness.
GUI-Robust: A Comprehensive Dataset for Testing GUI Agent Robustness in Real-World Anomalies
Jun 17, 2025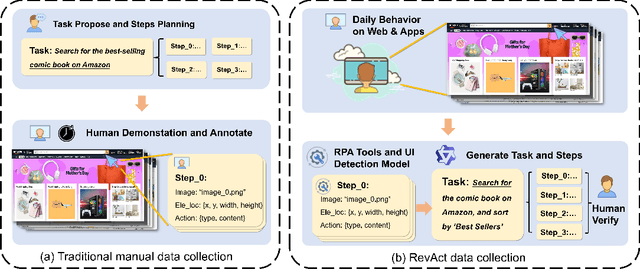
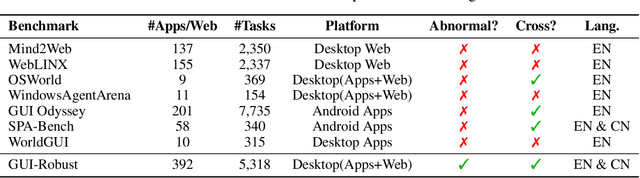

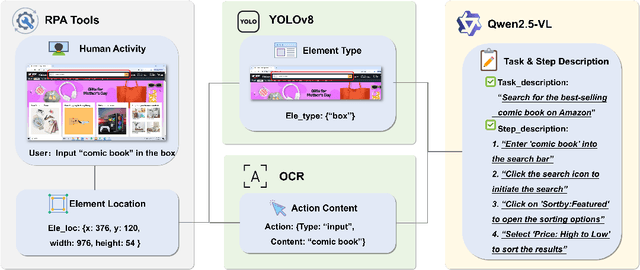
The development of high-quality datasets is crucial for benchmarking and advancing research in Graphical User Interface (GUI) agents. Despite their importance, existing datasets are often constructed under idealized conditions, overlooking the diverse anomalies frequently encountered in real-world deployments. To address this limitation, we introduce GUI-Robust, a novel dataset designed for comprehensive GUI agent evaluation, explicitly incorporating seven common types of anomalies observed in everyday GUI interactions. Furthermore, we propose a semi-automated dataset construction paradigm that collects user action sequences from natural interactions via RPA tools and then generate corresponding step and task descriptions for these actions with the assistance of MLLMs. This paradigm significantly reduces annotation time cost by a factor of over 19 times. Finally, we assess state-of-the-art GUI agents using the GUI-Robust dataset, revealing their substantial performance degradation in abnormal scenarios. We anticipate that our work will highlight the importance of robustness in GUI agents and inspires more future research in this direction. The dataset and code are available at https://github.com/chessbean1/GUI-Robust..
FedCGD: Collective Gradient Divergence Optimized Scheduling for Wireless Federated Learning
Jun 09, 2025Federated learning (FL) is a promising paradigm for multiple devices to cooperatively train a model. When applied in wireless networks, two issues consistently affect the performance of FL, i.e., data heterogeneity of devices and limited bandwidth. Many papers have investigated device scheduling strategies considering the two issues. However, most of them recognize data heterogeneity as a property of individual devices. In this paper, we prove that the convergence speed of FL is affected by the sum of device-level and sample-level collective gradient divergence (CGD). The device-level CGD refers to the gradient divergence of the scheduled device group, instead of the sum of the individual device divergence. The sample-level CGD is statistically upper bounded by sampling variance, which is inversely proportional to the total number of samples scheduled for local update. To derive a tractable form of the device-level CGD, we further consider a classification problem and transform it into the weighted earth moving distance (WEMD) between the group distribution and the global distribution. Then we propose FedCGD algorithm to minimize the sum of multi-level CGDs by balancing WEMD and sampling variance, within polynomial time. Simulation shows that the proposed strategy increases classification accuracy on the CIFAR-10 dataset by up to 4.2\% while scheduling 41.8\% fewer devices, and flexibly switches between reducing WEMD and reducing sampling variance.
Mobility-Aware Asynchronous Federated Learning with Dynamic Sparsification
Jun 08, 2025Asynchronous Federated Learning (AFL) enables distributed model training across multiple mobile devices, allowing each device to independently update its local model without waiting for others. However, device mobility introduces intermittent connectivity, which necessitates gradient sparsification and leads to model staleness, jointly affecting AFL convergence. This paper develops a theoretical model to characterize the interplay among sparsification, model staleness and mobility-induced contact patterns, and their joint impact on AFL convergence. Based on the analysis, we propose a mobility-aware dynamic sparsification (MADS) algorithm that optimizes the sparsification degree based on contact time and model staleness. Closed-form solutions are derived, showing that under low-speed conditions, MADS increases the sparsification degree to enhance convergence, while under high-speed conditions, it reduces the sparsification degree to guarantee reliable uploads within limited contact time. Experimental results validate the theoretical findings. Compared with the state-of-the-art benchmarks, the MADS algorithm increases the image classification accuracy on the CIFAR-10 dataset by 8.76% and reduces the average displacement error in the Argoverse trajectory prediction dataset by 9.46%.
OpenGT: A Comprehensive Benchmark For Graph Transformers
Jun 05, 2025Graph Transformers (GTs) have recently demonstrated remarkable performance across diverse domains. By leveraging attention mechanisms, GTs are capable of modeling long-range dependencies and complex structural relationships beyond local neighborhoods. However, their applicable scenarios are still underexplored, this highlights the need to identify when and why they excel. Furthermore, unlike GNNs, which predominantly rely on message-passing mechanisms, GTs exhibit a diverse design space in areas such as positional encoding, attention mechanisms, and graph-specific adaptations. Yet, it remains unclear which of these design choices are truly effective and under what conditions. As a result, the community currently lacks a comprehensive benchmark and library to promote a deeper understanding and further development of GTs. To address this gap, this paper introduces OpenGT, a comprehensive benchmark for Graph Transformers. OpenGT enables fair comparisons and multidimensional analysis by establishing standardized experimental settings and incorporating a broad selection of state-of-the-art GNNs and GTs. Our benchmark evaluates GTs from multiple perspectives, encompassing diverse tasks and datasets with varying properties. Through extensive experiments, our benchmark has uncovered several critical insights, including the difficulty of transferring models across task levels, the limitations of local attention, the efficiency trade-offs in several models, the application scenarios of specific positional encodings, and the preprocessing overhead of some positional encodings. We aspire for this work to establish a foundation for future graph transformer research emphasizing fairness, reproducibility, and generalizability. We have developed an easy-to-use library OpenGT for training and evaluating existing GTs. The benchmark code is available at https://github.com/eaglelab-zju/OpenGT.
Causal-LLaVA: Causal Disentanglement for Mitigating Hallucination in Multimodal Large Language Models
May 26, 2025



Multimodal Large Language Models (MLLMs) have demonstrated strong performance in visual understanding tasks, yet they often suffer from object hallucinations--generating descriptions of objects that are inconsistent with or entirely absent from the input. This issue is closely related to dataset biases, where frequent co-occurrences of objects lead to entangled semantic representations across modalities. As a result, models may erroneously activate object representations that are commonly associated with the input but not actually present. To address this, we propose a causality-driven disentanglement framework that mitigates hallucinations through causal intervention. Our approach includes a Causal-Driven Projector in the visual pathway and a Causal Intervention Module integrated into the final transformer layer of the language model. These components work together to reduce spurious correlations caused by biased training data. Experimental results show that our method significantly reduces hallucinations while maintaining strong performance on multiple multimodal benchmarks. Visualization analyses further confirm improved separability of object representations. The code is available at: https://github.com/IgniSavium/Causal-LLaVA
Doc-CoB: Enhancing Multi-Modal Document Understanding with Visual Chain-of-Boxes Reasoning
May 24, 2025



Multimodal large language models (MLLMs) have made significant progress in document understanding. However, the information-dense nature of document images still poses challenges, as most queries depend on only a few relevant regions, with the rest being redundant. Existing one-pass MLLMs process entire document images without considering query relevance, often failing to focus on critical regions and producing unfaithful responses. Inspired by the human coarse-to-fine reading pattern, we introduce Doc-CoB (Chain-of-Box), a simple-yet-effective mechanism that integrates human-style visual reasoning into MLLM without modifying its architecture. Our method allows the model to autonomously select the set of regions (boxes) most relevant to the query, and then focus attention on them for further understanding. We first design a fully automatic pipeline, integrating a commercial MLLM with a layout analyzer, to generate 249k training samples with intermediate visual reasoning supervision. Then we incorporate two enabling tasks that improve box identification and box-query reasoning, which together enhance document understanding. Extensive experiments on seven benchmarks with four popular models show that Doc-CoB significantly improves performance, demonstrating its effectiveness and wide applicability. All code, data, and models will be released publicly.
FocusedAD: Character-centric Movie Audio Description
Apr 16, 2025



Movie Audio Description (AD) aims to narrate visual content during dialogue-free segments, particularly benefiting blind and visually impaired (BVI) audiences. Compared with general video captioning, AD demands plot-relevant narration with explicit character name references, posing unique challenges in movie understanding.To identify active main characters and focus on storyline-relevant regions, we propose FocusedAD, a novel framework that delivers character-centric movie audio descriptions. It includes: (i) a Character Perception Module(CPM) for tracking character regions and linking them to names; (ii) a Dynamic Prior Module(DPM) that injects contextual cues from prior ADs and subtitles via learnable soft prompts; and (iii) a Focused Caption Module(FCM) that generates narrations enriched with plot-relevant details and named characters. To overcome limitations in character identification, we also introduce an automated pipeline for building character query banks. FocusedAD achieves state-of-the-art performance on multiple benchmarks, including strong zero-shot results on MAD-eval-Named and our newly proposed Cinepile-AD dataset. Code and data will be released at https://github.com/Thorin215/FocusedAD .
Optimization of Layer Skipping and Frequency Scaling for Convolutional Neural Networks under Latency Constraint
Mar 31, 2025



The energy consumption of Convolutional Neural Networks (CNNs) is a critical factor in deploying deep learning models on resource-limited equipment such as mobile devices and autonomous vehicles. We propose an approach involving Proportional Layer Skipping (PLS) and Frequency Scaling (FS). Layer skipping reduces computational complexity by selectively bypassing network layers, whereas frequency scaling adjusts the frequency of the processor to optimize energy use under latency constraints. Experiments of PLS and FS on ResNet-152 with the CIFAR-10 dataset demonstrated significant reductions in computational demands and energy consumption with minimal accuracy loss. This study offers practical solutions for improving real-time processing in resource-limited settings and provides insights into balancing computational efficiency and model performance.
Robust DNN Partitioning and Resource Allocation Under Uncertain Inference Time
Mar 27, 2025



In edge intelligence systems, deep neural network (DNN) partitioning and data offloading can provide real-time task inference for resource-constrained mobile devices. However, the inference time of DNNs is typically uncertain and cannot be precisely determined in advance, presenting significant challenges in ensuring timely task processing within deadlines. To address the uncertain inference time, we propose a robust optimization scheme to minimize the total energy consumption of mobile devices while meeting task probabilistic deadlines. The scheme only requires the mean and variance information of the inference time, without any prediction methods or distribution functions. The problem is formulated as a mixed-integer nonlinear programming (MINLP) that involves jointly optimizing the DNN model partitioning and the allocation of local CPU/GPU frequencies and uplink bandwidth. To tackle the problem, we first decompose the original problem into two subproblems: resource allocation and DNN model partitioning. Subsequently, the two subproblems with probability constraints are equivalently transformed into deterministic optimization problems using the chance-constrained programming (CCP) method. Finally, the convex optimization technique and the penalty convex-concave procedure (PCCP) technique are employed to obtain the optimal solution of the resource allocation subproblem and a stationary point of the DNN model partitioning subproblem, respectively. The proposed algorithm leverages real-world data from popular hardware platforms and is evaluated on widely used DNN models. Extensive simulations show that our proposed algorithm effectively addresses the inference time uncertainty with probabilistic deadline guarantees while minimizing the energy consumption of mobile devices.