 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphRPM: Risk Pattern Mining on Industrial Large Attributed Graphs
Nov 11, 2024Graph-based patterns are extensively employed and favored by practitioners within industrial companies due to their capacity to represent the behavioral attributes and topological relationships among users, thereby offering enhanced interpretability in comparison to black-box models commonly utilized for classification and recognition tasks. For instance, within the scenario of transaction risk management, a graph pattern that is characteristic of a particular risk category can be readily employed to discern transactions fraught with risk, delineate networks of criminal activity, or investigate the methodologies employed by fraudsters. Nonetheless, graph data in industrial settings is often characterized by its massive scale, encompassing data sets with millions or even billions of nodes, making the manual extraction of graph patterns not only labor-intensive but also necessitating specialized knowledge in particular domains of risk. Moreover, existing methodologies for mining graph patterns encounter significant obstacles when tasked with analyzing large-scale attributed graphs. In this work, we introduce GraphRPM, an industry-purpose parallel and distributed risk pattern mining framework on large attributed graphs. The framework incorporates a novel edge-involved graph isomorphism network alongside optimized operations for parallel graph computation, which collectively contribute to a considerable reduction in computational complexity and resource expenditure. Moreover, the intelligent filtration of efficacious risky graph patterns is facilitated by the proposed evaluation metrics. Comprehensive experimental evaluations conducted on real-world datasets of varying sizes substantiate the capability of GraphRPM to adeptly address the challenges inherent in mining patterns from large-scale industrial attributed graphs, thereby underscoring its substantial value for industrial deployment.
Subgraph Retrieval Enhanced by Graph-Text Alignment for Commonsense Question Answering
Nov 11, 2024Commonsense question answering is a crucial task that requires machines to employ reasoning according to commonsense. Previous studies predominantly employ an extracting-and-modeling paradigm to harness the information in KG, which first extracts relevant subgraphs based on pre-defined rules and then proceeds to design various strategies aiming to improve the representations and fusion of the extracted structural knowledge. Despite their effectiveness, there are still two challenges. On one hand, subgraphs extracted by rule-based methods may have the potential to overlook critical nodes and result in uncontrollable subgraph size. On the other hand, the misalignment between graph and text modalities undermines the effectiveness of knowledge fusion, ultimately impacting the task performance. To deal with the problems above, we propose a novel framework: \textbf{S}ubgraph R\textbf{E}trieval Enhanced by Gra\textbf{P}h-\textbf{T}ext \textbf{A}lignment, named \textbf{SEPTA}. Firstly, we transform the knowledge graph into a database of subgraph vectors and propose a BFS-style subgraph sampling strategy to avoid information loss, leveraging the analogy between BFS and the message-passing mechanism. In addition, we propose a bidirectional contrastive learning approach for graph-text alignment, which effectively enhances both subgraph retrieval and knowledge fusion. Finally, all the retrieved information is combined for reasoning in the prediction module. Extensive experiments on five datasets demonstrate the effectiveness and robustness of our framework.
Revisiting Modularity Maximization for Graph Clustering: A Contrastive Learning Perspective
Jun 20, 2024



Graph clustering, a fundamental and challenging task in graph mining, aims to classify nodes in a graph into several disjoint clusters. In recent years, graph contrastive learning (GCL) has emerged as a dominant line of research in graph clustering and advances the new state-of-the-art. However, GCL-based methods heavily rely on graph augmentations and contrastive schemes, which may potentially introduce challenges such as semantic drift and scalability issues. Another promising line of research involves the adoption of modularity maximization, a popular and effective measure for community detection, as the guiding principle for clustering tasks. Despite the recent progress, the underlying mechanism of modularity maximization is still not well understood. In this work, we dig into the hidden success of modularity maximization for graph clustering. Our analysis reveals the strong connections between modularity maximization and graph contrastive learning, where positive and negative examples are naturally defined by modularity. In light of our results, we propose a community-aware graph clustering framework, coined MAGI, which leverages modularity maximization as a contrastive pretext task to effectively uncover the underlying information of communities in graphs, while avoiding the problem of semantic drift. Extensive experiments on multiple graph datasets verify the effectiveness of MAGI in terms of scalability and clustering performance compared to state-of-the-art graph clustering methods. Notably, MAGI easily scales a sufficiently large graph with 100M nodes while outperforming strong baselines.
LasTGL: An Industrial Framework for Large-Scale Temporal Graph Learning
Nov 30, 2023



Over the past few years, graph neural networks (GNNs) have become powerful and practical tools for learning on (static) graph-structure data. However, many real-world applications, such as social networks and e-commerce, involve temporal graphs where nodes and edges are dynamically evolving. Temporal graph neural networks (TGNNs) have progressively emerged as an extension of GNNs to address time-evolving graphs and have gradually become a trending research topic in both academics and industry. Advancing research and application in such an emerging field necessitates the development of new tools to compose TGNN models and unify their different schemes for dealing with temporal graphs. In this work, we introduce LasTGL, an industrial framework that integrates unified and extensible implementations of common temporal graph learning algorithms for various advanced tasks. The purpose of LasTGL is to provide the essential building blocks for solving temporal graph learning tasks, focusing on the guiding principles of user-friendliness and quick prototyping on which PyTorch is based. In particular, LasTGL provides comprehensive temporal graph datasets, TGNN models and utilities along with well-documented tutorials, making it suitable for both absolute beginners and expert deep learning practitioners alike.
SAD: Semi-Supervised Anomaly Detection on Dynamic Graphs
May 23, 2023



Anomaly detection aims to distinguish abnormal instances that deviate significantly from the majority of benign ones. As instances that appear in the real world are naturally connected and can be represented with graphs, graph neural networks become increasingly popular in tackling the anomaly detection problem. Despite the promising results, research on anomaly detection has almost exclusively focused on static graphs while the mining of anomalous patterns from dynamic graphs is rarely studied but has significant application value. In addition, anomaly detection is typically tackled from semi-supervised perspectives due to the lack of sufficient labeled data. However, most proposed methods are limited to merely exploiting labeled data, leaving a large number of unlabeled samples unexplored. In this work, we present semi-supervised anomaly detection (SAD), an end-to-end framework for anomaly detection on dynamic graphs. By a combination of a time-equipped memory bank and a pseudo-label contrastive learning module, SAD is able to fully exploit the potential of large unlabeled samples and uncover underlying anomalies on evolving graph streams. Extensive experiments on four real-world datasets demonstrate that SAD efficiently discovers anomalies from dynamic graphs and outperforms existing advanced methods even when provided with only little labeled data.
Less Can Be More: Unsupervised Graph Pruning for Large-scale Dynamic Graphs
May 18, 2023



The prevalence of large-scale graphs poses great challenges in time and storage for training and deploying graph neural networks (GNNs). Several recent works have explored solutions for pruning the large original graph into a small and highly-informative one, such that training and inference on the pruned and large graphs have comparable performance. Although empirically effective, current researches focus on static or non-temporal graphs, which are not directly applicable to dynamic scenarios. In addition, they require labels as ground truth to learn the informative structure, limiting their applicability to new problem domains where labels are hard to obtain. To solve the dilemma, we propose and study the problem of unsupervised graph pruning on dynamic graphs. We approach the problem by our proposed STEP, a self-supervised temporal pruning framework that learns to remove potentially redundant edges from input dynamic graphs. From a technical and industrial viewpoint, our method overcomes the trade-offs between the performance and the time & memory overheads. Our results on three real-world datasets demonstrate the advantages on improving the efficacy, robustness, and efficiency of GNNs on dynamic node classification tasks. Most notably, STEP is able to prune more than 50% of edges on a million-scale industrial graph Alipay (7M nodes, 21M edges) while approximating up to 98% of the original performance. Code is available at https://github.com/EdisonLeeeee/STEP.
Scaling Up Dynamic Graph Representation Learning via Spiking Neural Networks
Aug 15, 2022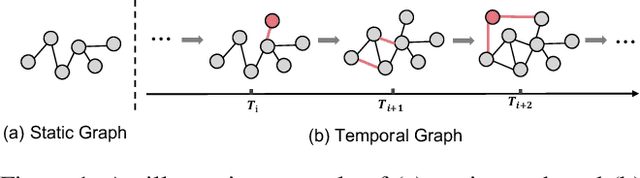
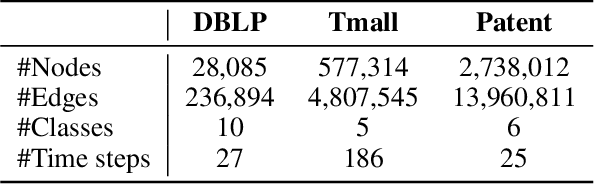
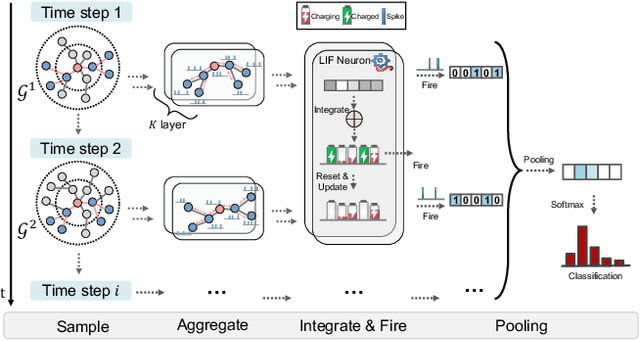
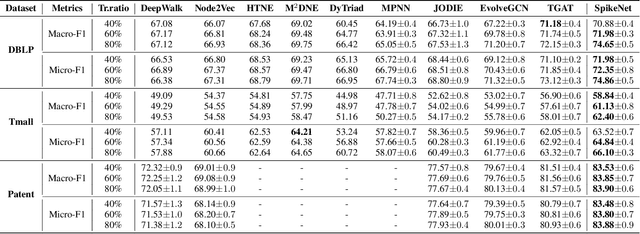
Recent years have seen a surge in research on dynamic graph representation learning, which aims to model temporal graphs that are dynamic and evolving constantly over time. However, current work typically models graph dynamics with recurrent neural networks (RNNs), making them suffer seriously from computation and memory overheads on large temporal graphs. So far, scalability of dynamic graph representation learning on large temporal graphs remains one of the major challenges. In this paper, we present a scalable framework, namely SpikeNet, to efficiently capture the temporal and structural patterns of temporal graphs. We explore a new direction in that we can capture the evolving dynamics of temporal graphs with spiking neural networks (SNNs) instead of RNNs. As a low-power alternative to RNNs, SNNs explicitly model graph dynamics as spike trains of neuron populations and enable spike-based propagation in an efficient way. Experiments on three large real-world temporal graph datasets demonstrate that SpikeNet outperforms strong baselines on the temporal node classification task with lower computational costs. Particularly, SpikeNet generalizes to a large temporal graph (2M nodes and 13M edges) with significantly fewer parameters and computation overheads. Our code is publicly available at https://github.com/EdisonLeeeee/SpikeNet
MaskGAE: Masked Graph Modeling Meets Graph Autoencoders
May 20, 2022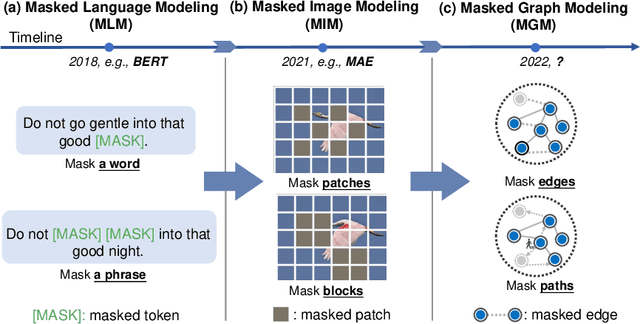
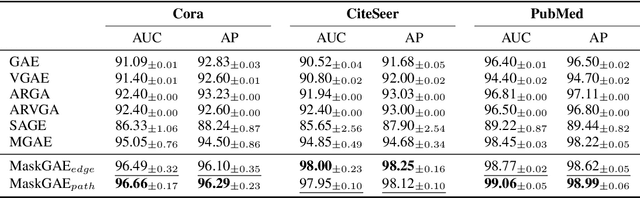
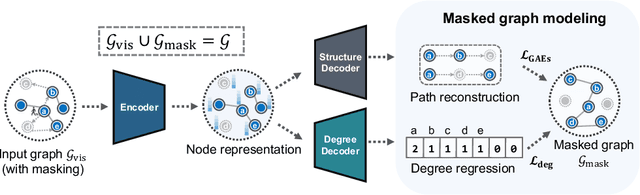
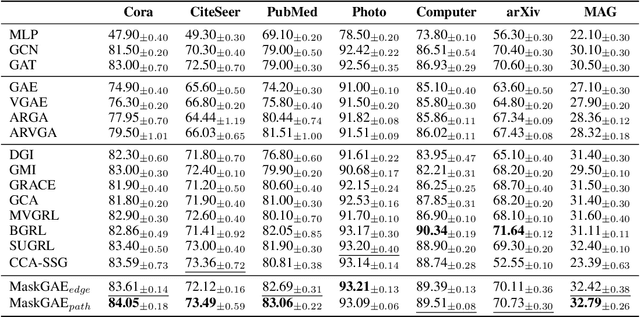
We present masked graph autoencoder (MaskGAE), a self-supervised learning framework for graph-structured data. Different from previous graph autoencoders (GAEs), MaskGAE adopts masked graph modeling (MGM) as a principled pretext task: masking a portion of edges and attempting to reconstruct the missing part with partially visible, unmasked graph structure. To understand whether MGM can help GAEs learn better representations, we provide both theoretical and empirical evidence to justify the benefits of this pretext task. Theoretically, we establish the connections between GAEs and contrastive learning, showing that MGM significantly improves the self-supervised learning scheme of GAEs. Empirically, we conduct extensive experiments on a number of benchmark datasets, demonstrating the superiority of MaskGAE over several state-of-the-arts on both link prediction and node classification tasks. Our code is publicly available at \url{https://github.com/EdisonLeeeee/MaskGAE}.