 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting the Intrinsic Neighborhood Structure for Source-free Domain Adaptation
Oct 08, 2021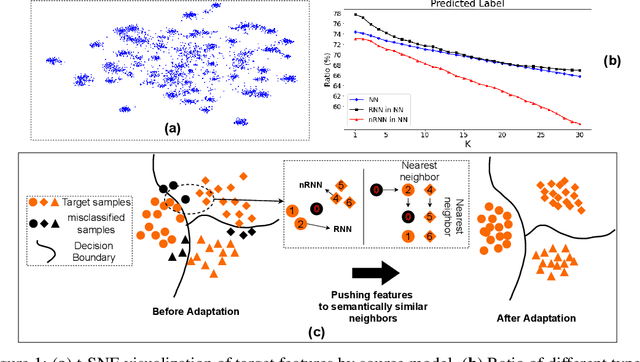
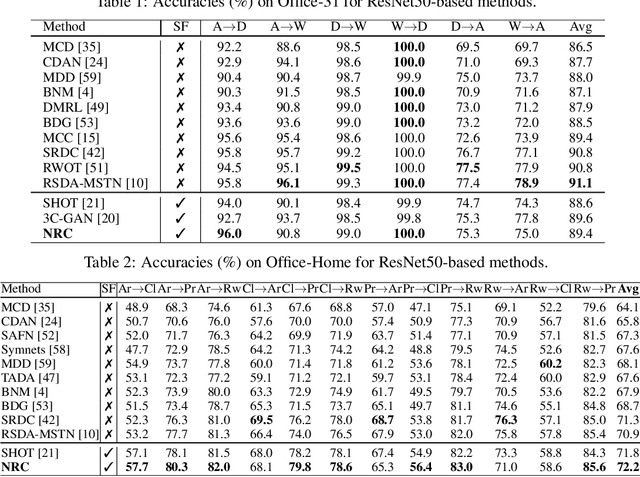
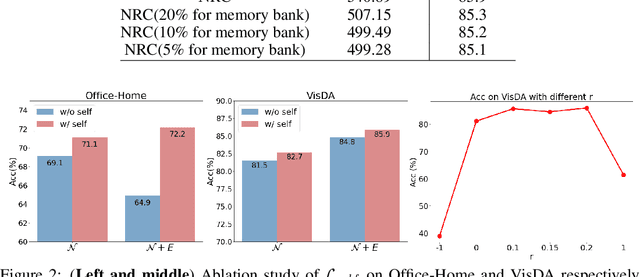
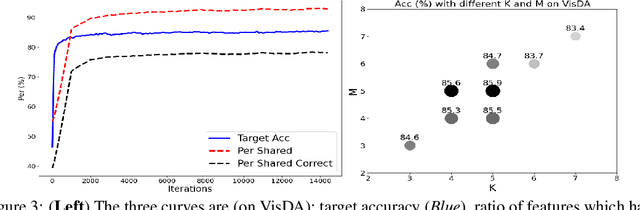
Domain adaptation (DA) aims to alleviate the domain shift between source domain and target domain. Most DA methods require access to the source data, but often that is not possible (e.g. due to data privacy or intellectual property). In this paper, we address the challenging source-free domain adaptation (SFDA) problem, where the source pretrained model is adapted to the target domain in the absence of source data. Our method is based on the observation that target data, which might no longer align with the source domain classifier, still forms clear clusters. We capture this intrinsic structure by defining local affinity of the target data, and encourage label consistency among data with high local affinity. We observe that higher affinity should be assigned to reciprocal neighbors, and propose a self regularization loss to decrease the negative impact of noisy neighbors. Furthermore, to aggregate information with more context, we consider expanded neighborhoods with small affinity values. In the experimental results we verify that the inherent structure of the target features is an important source of information for domain adaptation. We demonstrate that this local structure can be efficiently captured by considering the local neighbors, the reciprocal neighbors, and the expanded neighborhood. Finally, we achieve state-of-the-art performance on several 2D image and 3D point cloud recognition datasets. Code is available in https://github.com/Albert0147/SFDA_neighbors.
Profiling Neural Blocks and Design Spaces for Mobile Neural Architecture Search
Sep 25, 2021
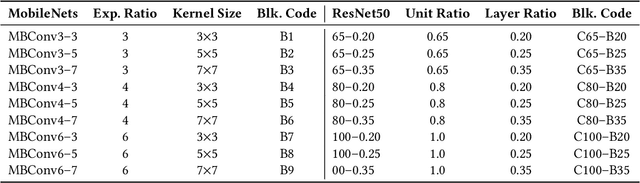
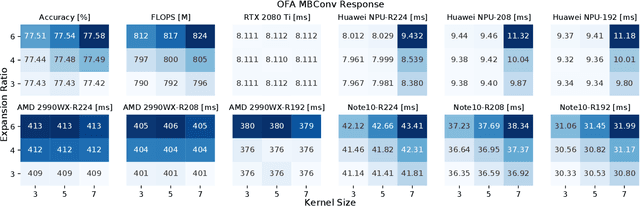
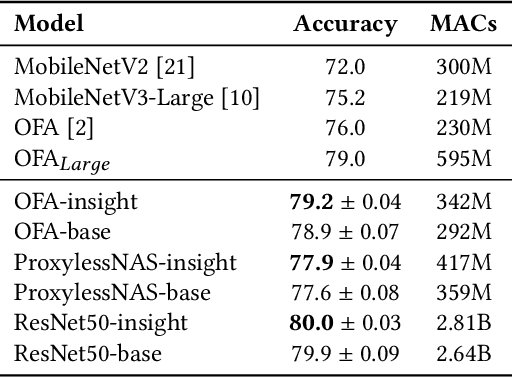
Neural architecture search automates neural network design and has achieved state-of-the-art results in many deep learning applications. While recent literature has focused on designing networks to maximize accuracy, little work has been conducted to understand the compatibility of architecture design spaces to varying hardware. In this paper, we analyze the neural blocks used to build Once-for-All (MobileNetV3), ProxylessNAS and ResNet families, in order to understand their predictive power and inference latency on various devices, including Huawei Kirin 9000 NPU, RTX 2080 Ti, AMD Threadripper 2990WX, and Samsung Note10. We introduce a methodology to quantify the friendliness of neural blocks to hardware and the impact of their placement in a macro network on overall network performance via only end-to-end measurements. Based on extensive profiling results, we derive design insights and apply them to hardware-specific search space reduction. We show that searching in the reduced search space generates better accuracy-latency Pareto frontiers than searching in the original search spaces, customizing architecture search according to the hardware. Moreover, insights derived from measurements lead to notably higher ImageNet top-1 scores on all search spaces investigated.
L$^{2}$NAS: Learning to Optimize Neural Architectures via Continuous-Action Reinforcement Learning
Sep 25, 2021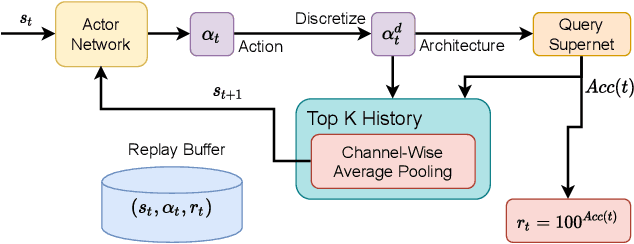
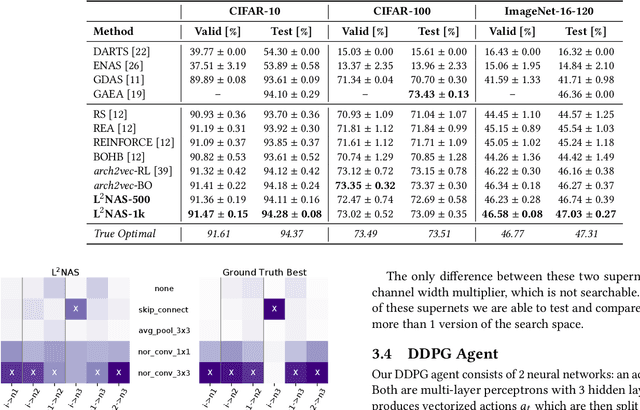
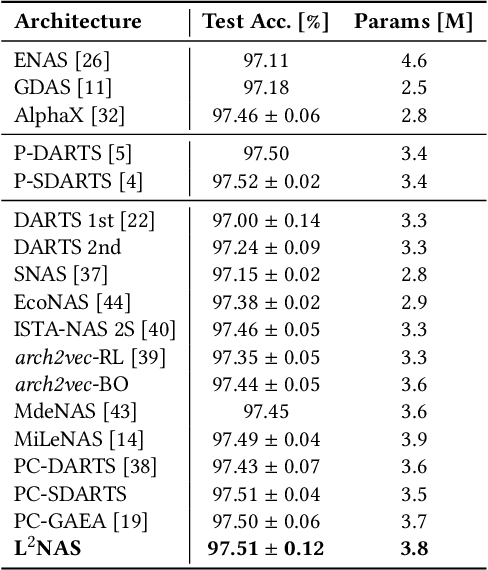
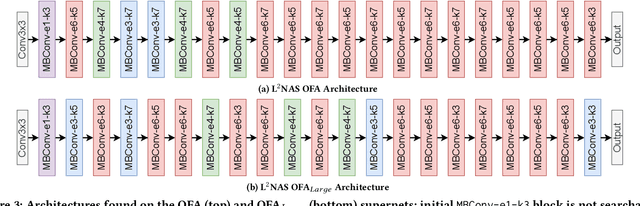
Neural architecture search (NAS) has achieved remarkable results in deep neural network design. Differentiable architecture search converts the search over discrete architectures into a hyperparameter optimization problem which can be solved by gradient descent. However, questions have been raised regarding the effectiveness and generalizability of gradient methods for solving non-convex architecture hyperparameter optimization problems. In this paper, we propose L$^{2}$NAS, which learns to intelligently optimize and update architecture hyperparameters via an actor neural network based on the distribution of high-performing architectures in the search history. We introduce a quantile-driven training procedure which efficiently trains L$^{2}$NAS in an actor-critic framework via continuous-action reinforcement learning. Experiments show that L$^{2}$NAS achieves state-of-the-art results on NAS-Bench-201 benchmark as well as DARTS search space and Once-for-All MobileNetV3 search space. We also show that search policies generated by L$^{2}$NAS are generalizable and transferable across different training datasets with minimal fine-tuning.
Exploring the Robustness of Distributional Reinforcement Learning against Noisy State Observations
Sep 17, 2021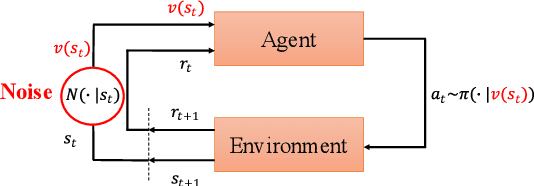
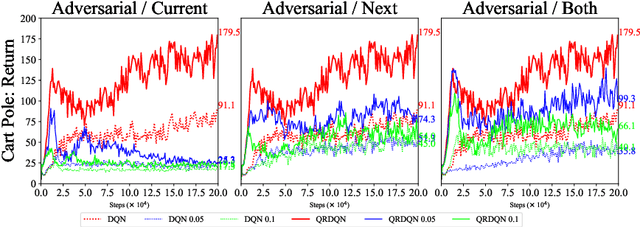
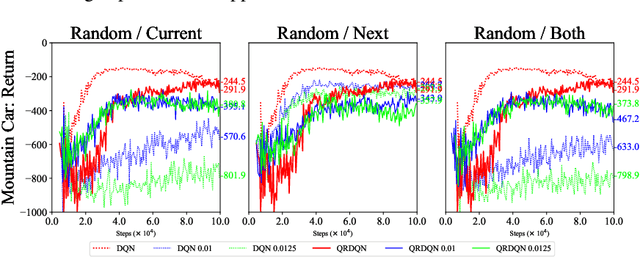
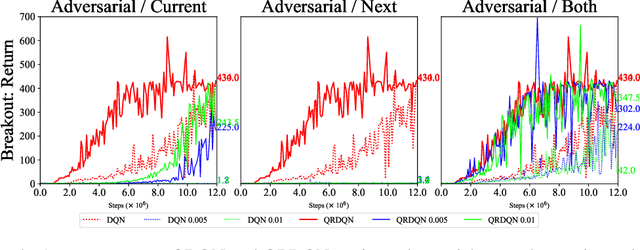
In real scenarios, state observations that an agent observes may contain measurement errors or adversarial noises, misleading the agent to take suboptimal actions or even collapse while training. In this paper, we study the training robustness of distributional Reinforcement Learning~(RL), a class of state-of-the-art methods that estimate the whole distribution, as opposed to only the expectation, of the total return. Firstly, we propose State-Noisy Markov Decision Process~(SN-MDP) in the tabular case to incorporate both random and adversarial state observation noises, in which the contraction of both expectation-based and distributional Bellman operators is derived. Beyond SN-MDP with the function approximation, we theoretically characterize the bounded gradient norm of histogram-based distributional loss, accounting for the better training robustness of distribution RL. We also provide stricter convergence conditions of the Temporal-Difference~(TD) learning under more flexible state noises, as well as the sensitivity analysis by the leverage of influence function. Finally, extensive experiments on the suite of games show that distributional RL enjoys better training robustness compared with its expectation-based counterpart across various state observation noises.
Generalized Source-free Domain Adaptation
Aug 03, 2021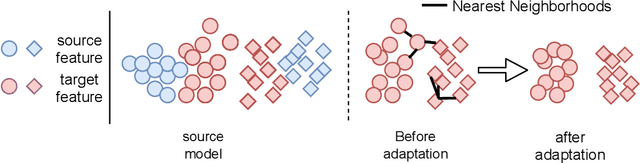
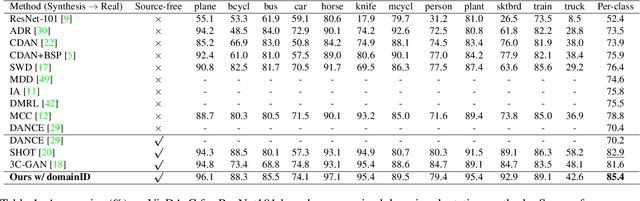
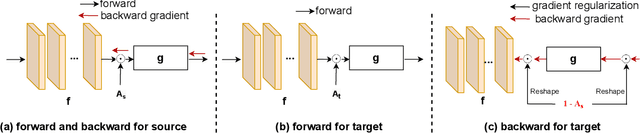
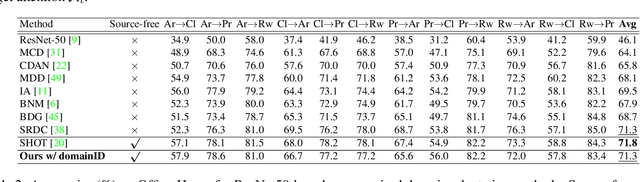
Domain adaptation (DA) aims to transfer the knowledge learned from a source domain to an unlabeled target domain. Some recent works tackle source-free domain adaptation (SFDA) where only a source pre-trained model is available for adaptation to the target domain. However, those methods do not consider keeping source performance which is of high practical value in real world applications. In this paper, we propose a new domain adaptation paradigm called Generalized Source-free Domain Adaptation (G-SFDA), where the learned model needs to perform well on both the target and source domains, with only access to current unlabeled target data during adaptation. First, we propose local structure clustering (LSC), aiming to cluster the target features with its semantically similar neighbors, which successfully adapts the model to the target domain in the absence of source data. Second, we propose sparse domain attention (SDA), it produces a binary domain specific attention to activate different feature channels for different domains, meanwhile the domain attention will be utilized to regularize the gradient during adaptation to keep source information. In the experiments, for target performance our method is on par with or better than existing DA and SFDA methods, specifically it achieves state-of-the-art performance (85.4%) on VisDA, and our method works well for all domains after adapting to single or multiple target domains. Code is available in https://github.com/Albert0147/G-SFDA.
Generative Adversarial Neural Architecture Search
May 19, 2021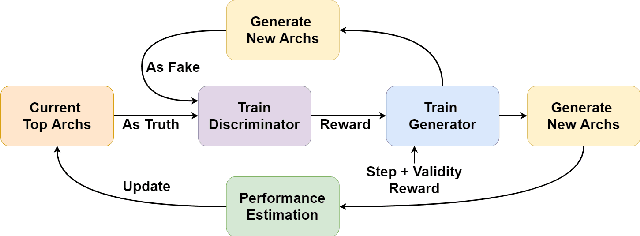
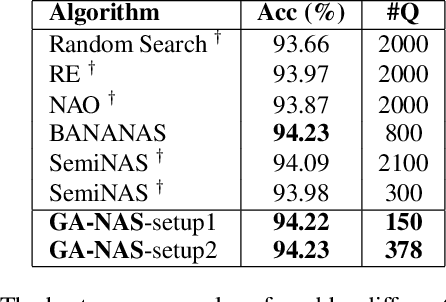
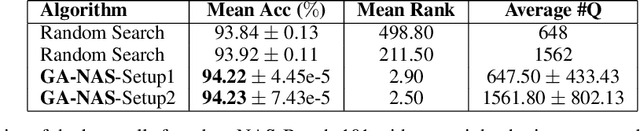
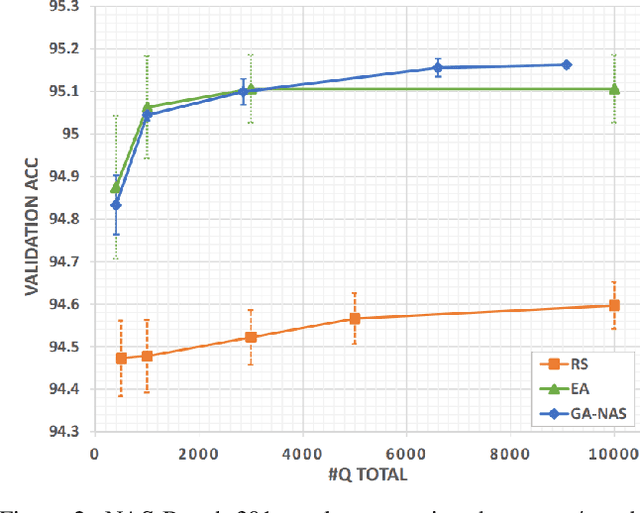
Despite the empirical success of neural architecture search (NAS) in deep learning applications, the optimality, reproducibility and cost of NAS schemes remain hard to assess. In this paper, we propose Generative Adversarial NAS (GA-NAS) with theoretically provable convergence guarantees, promoting stability and reproducibility in neural architecture search. Inspired by importance sampling, GA-NAS iteratively fits a generator to previously discovered top architectures, thus increasingly focusing on important parts of a large search space. Furthermore, we propose an efficient adversarial learning approach, where the generator is trained by reinforcement learning based on rewards provided by a discriminator, thus being able to explore the search space without evaluating a large number of architectures. Extensive experiments show that GA-NAS beats the best published results under several cases on three public NAS benchmarks. In the meantime, GA-NAS can handle ad-hoc search constraints and search spaces. We show that GA-NAS can be used to improve already optimized baselines found by other NAS methods, including EfficientNet and ProxylessNAS, in terms of ImageNet accuracy or the number of parameters, in their original search space.
MineGAN++: Mining Generative Models for Efficient Knowledge Transfer to Limited Data Domains
Apr 28, 2021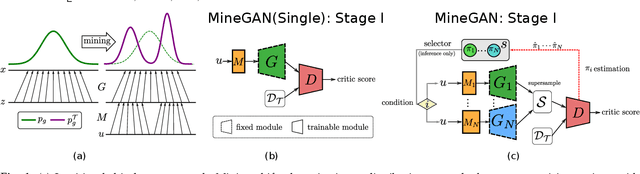
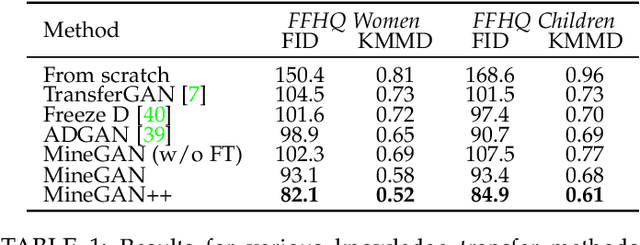
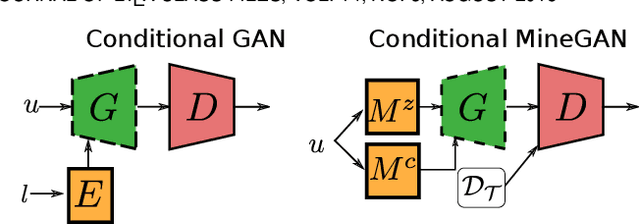
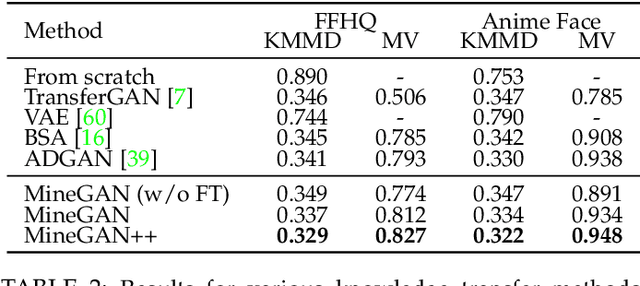
GANs largely increases the potential impact of generative models. Therefore, we propose a novel knowledge transfer method for generative models based on mining the knowledge that is most beneficial to a specific target domain, either from a single or multiple pretrained GANs. This is done using a miner network that identifies which part of the generative distribution of each pretrained GAN outputs samples closest to the target domain. Mining effectively steers GAN sampling towards suitable regions of the latent space, which facilitates the posterior finetuning and avoids pathologies of other methods, such as mode collapse and lack of flexibility. Furthermore, to prevent overfitting on small target domains, we introduce sparse subnetwork selection, that restricts the set of trainable neurons to those that are relevant for the target dataset. We perform comprehensive experiments on several challenging datasets using various GAN architectures (BigGAN, Progressive GAN, and StyleGAN) and show that the proposed method, called MineGAN, effectively transfers knowledge to domains with few target images, outperforming existing methods. In addition, MineGAN can successfully transfer knowledge from multiple pretrained GANs.
Unsupervised Domain Adaptation without Source Data by Casting a BAIT
Oct 28, 2020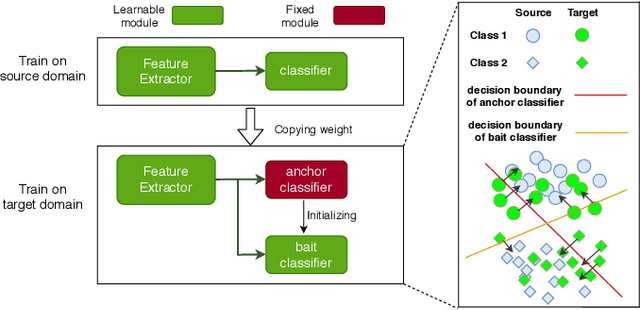
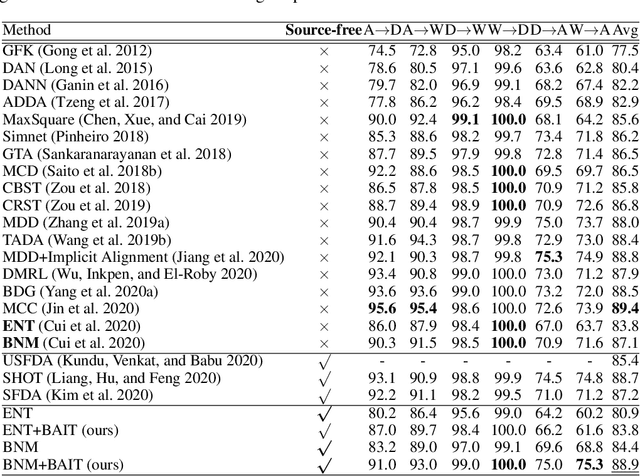
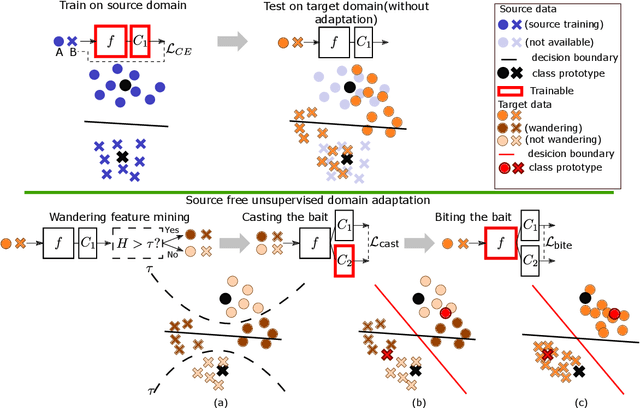
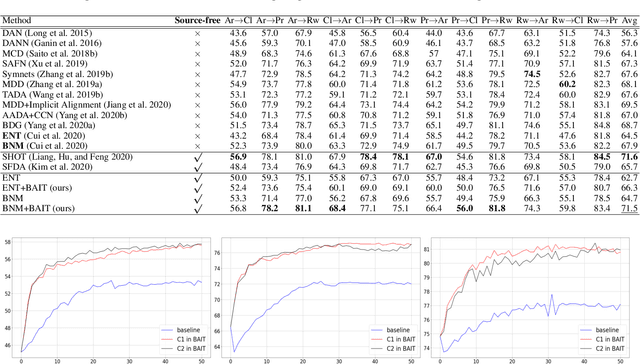
Unsupervised domain adaptation (UDA) aims to transfer the knowledge learned from labeled source domain to unlabeled target domain. Existing UDA methods require access to the data from the source domain, during adaptation to the target domain, which may not be feasible in some real-world situations. In this paper, we address Source-free Unsupervised Domain Adaptation (SFUDA), where the model has no access to any source data during the adaptation period. We propose a novel framework named BAIT to tackle SFUDA. Specifically, we first train the model on source domain. With the source-specific classifier head (referred to as anchor classifier) fixed, we further introduce a new learnable classifier head (referred to as bait classifier), which is initialized by the anchor classifier. When adapting the source model to the target domain, the source data are no more accessible and the bait classifier aims to push the target features towards the right side of the decision boundary of the anchor classifier, thus achieving the feature alignment. Experiment results show that proposed BAIT achieves state-of-the-art performance compared with existing normal UDA methods and several SFUDA methods.
Neural Architecture Search For Keyword Spotting
Sep 02, 2020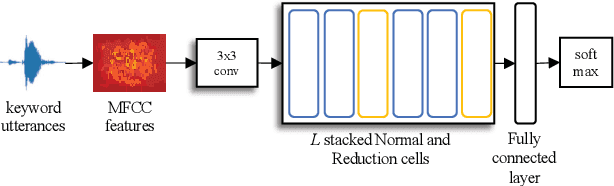

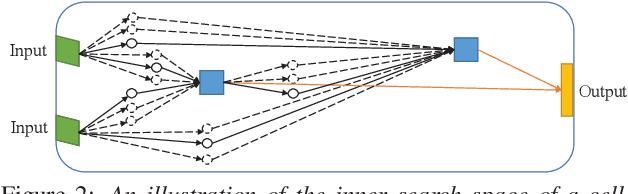
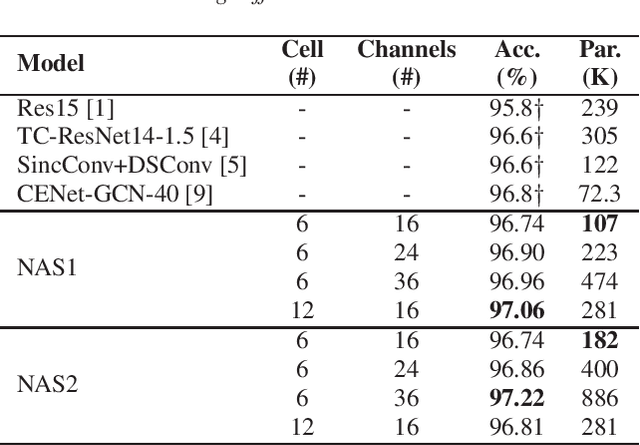
Deep neural networks have recently become a popular solution to keyword spotting systems, which enable the control of smart devices via voice. In this paper, we apply neural architecture search to search for convolutional neural network models that can help boost the performance of keyword spotting based on features extracted from acoustic signals while maintaining an acceptable memory footprint. Specifically, we use differentiable architecture search techniques to search for operators and their connections in a predefined cell search space. The found cells are then scaled up in both depth and width to achieve competitive performance. We evaluated the proposed method on Google's Speech Commands Dataset and achieved a state-of-the-art accuracy of over 97% on the setting of 12-class utterance classification commonly reported in the literature.
Generative Feature Replay For Class-Incremental Learning
Apr 20, 2020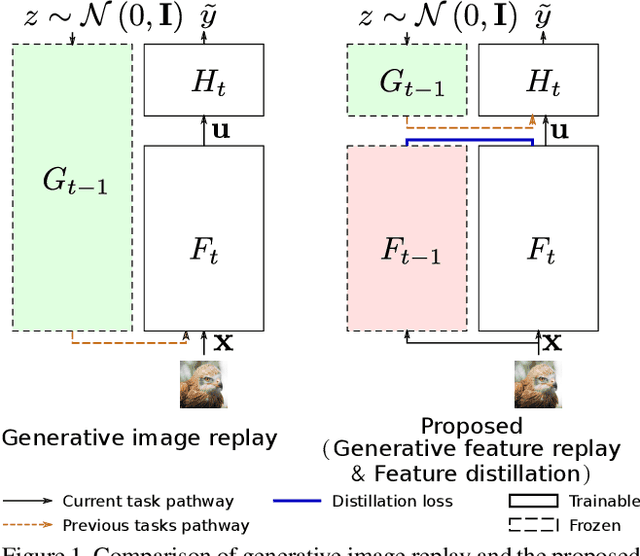

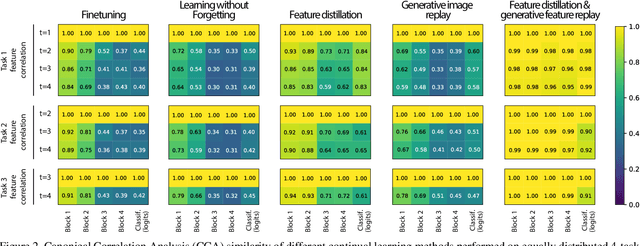
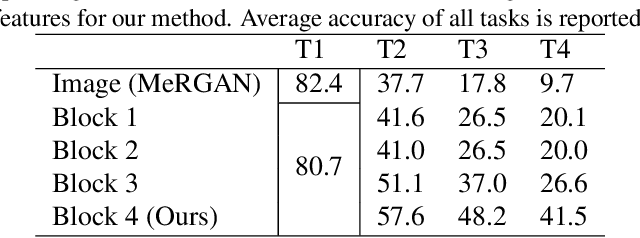
Humans are capable of learning new tasks without forgetting previous ones, while neural networks fail due to catastrophic forgetting between new and previously-learned tasks. We consider a class-incremental setting which means that the task-ID is unknown at inference time. The imbalance between old and new classes typically results in a bias of the network towards the newest ones. This imbalance problem can either be addressed by storing exemplars from previous tasks, or by using image replay methods. However, the latter can only be applied to toy datasets since image generation for complex datasets is a hard problem. We propose a solution to the imbalance problem based on generative feature replay which does not require any exemplars. To do this, we split the network into two parts: a feature extractor and a classifier. To prevent forgetting, we combine generative feature replay in the classifier with feature distillation in the feature extractor. Through feature generation, our method reduces the complexity of generative replay and prevents the imbalance problem. Our approach is computationally efficient and scalable to large datasets. Experiments confirm that our approach achieves state-of-the-art results on CIFAR-100 and ImageNet, while requiring only a fraction of the storage needed for exemplar-based continual learning. Code available at \url{https://github.com/xialeiliu/GFR-IL}.