 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTempGlitch: Evaluating Vision-Language Models for Temporal Glitch Detection in Gameplay Videos
May 20, 2026Vision-language models (VLMs) are increasingly being explored for video game quality assurance, especially gameplay glitch detection. Most existing evaluations, however, treat glitches as static visual anomalies, asking models to detect failures from a single frame. We argue that this framing misses a key distinction: some glitches are spatial and visible in an isolated frame, whereas others are temporal and become evident only through changes across ordered frames. A preliminary study confirms this gap, showing that temporal glitches are substantially harder for VLMs to detect than spatial ones. To enable systematic evaluation of this underexplored setting, we introduce TempGlitch, a controlled gameplay video benchmark for temporal glitch detection. TempGlitch covers five temporal glitch types with balanced per-category samples, together with paired glitch-free videos that enable reliable binary evaluation. We evaluate 12 proprietary and open-weight VLMs across multiple frame-sampling settings. Our results show that current VLMs remain near chance on TempGlitch, often collapsing into either overly conservative behavior that misses most glitches or overly sensitive behavior that flags clean videos as glitchy. Moreover, denser frame sampling and larger model size do not reliably resolve these failures. TempGlitch provides a focused testbed for temporal reasoning, robust gameplay understanding, and automated glitch detection with VLMs. Code and data are available at the project website.
RESP: Reference-guided Sequential Prompting for Visual Glitch Detection in Video Games
Apr 13, 2026Visual glitches in video games degrade player experience and perceived quality, yet manual quality assurance cannot scale to the growing test surface of modern game development. Prior automation efforts, particularly those using vision-language models (VLMs), largely operate on single frames or rely on limited video-level baselines that struggle under realistic scene variation, making robust video-level glitch detection challenging. We present RESP, a practical multi-frame framework for gameplay glitch detection with VLMs. Our key idea is reference-guided prompting: for each test frame, we select a reference frame from earlier in the same video, establishing a visual baseline and reframing detection as within-video comparison rather than isolated classification. RESP sequentially prompts the VLM with reference/test pairs and aggregates noisy frame predictions into a stable video-level decision without fine-tuning the VLM. To enable controlled analysis of reference effects, we introduce RefGlitch, a synthetic dataset of manually labeled reference/test frame pairs with balanced coverage across five glitch types. Experiments across five VLMs and three datasets (one synthetic, two real-world) show that reference guidance consistently strengthens frame-level detection and that the improved frame-level evidence reliably transfers to stronger video-level triage under realistic QA conditions. Code and data are available at: \href{https://github.com/PipiZong/RESP_code.git}{this https URL}.
Toward Conditional Distribution Calibration in Survival Prediction
Oct 27, 2024Survival prediction often involves estimating the time-to-event distribution from censored datasets. Previous approaches have focused on enhancing discrimination and marginal calibration. In this paper, we highlight the significance of conditional calibration for real-world applications -- especially its role in individual decision-making. We propose a method based on conformal prediction that uses the model's predicted individual survival probability at that instance's observed time. This method effectively improves the model's marginal and conditional calibration, without compromising discrimination. We provide asymptotic theoretical guarantees for both marginal and conditional calibration and test it extensively across 15 diverse real-world datasets, demonstrating the method's practical effectiveness and versatility in various settings.
Conformalized Survival Distributions: A Generic Post-Process to Increase Calibration
May 12, 2024



Discrimination and calibration represent two important properties of survival analysis, with the former assessing the model's ability to accurately rank subjects and the latter evaluating the alignment of predicted outcomes with actual events. With their distinct nature, it is hard for survival models to simultaneously optimize both of them especially as many previous results found improving calibration tends to diminish discrimination performance. This paper introduces a novel approach utilizing conformal regression that can improve a model's calibration without degrading discrimination. We provide theoretical guarantees for the above claim, and rigorously validate the efficiency of our approach across 11 real-world datasets, showcasing its practical applicability and robustness in diverse scenarios.
iHAS: Instance-wise Hierarchical Architecture Search for Deep Learning Recommendation Models
Sep 14, 2023



Current recommender systems employ large-sized embedding tables with uniform dimensions for all features, leading to overfitting, high computational cost, and suboptimal generalizing performance. Many techniques aim to solve this issue by feature selection or embedding dimension search. However, these techniques typically select a fixed subset of features or embedding dimensions for all instances and feed all instances into one recommender model without considering heterogeneity between items or users. This paper proposes a novel instance-wise Hierarchical Architecture Search framework, iHAS, which automates neural architecture search at the instance level. Specifically, iHAS incorporates three stages: searching, clustering, and retraining. The searching stage identifies optimal instance-wise embedding dimensions across different field features via carefully designed Bernoulli gates with stochastic selection and regularizers. After obtaining these dimensions, the clustering stage divides samples into distinct groups via a deterministic selection approach of Bernoulli gates. The retraining stage then constructs different recommender models, each one designed with optimal dimensions for the corresponding group. We conduct extensive experiments to evaluate the proposed iHAS on two public benchmark datasets from a real-world recommender system. The experimental results demonstrate the effectiveness of iHAS and its outstanding transferability to widely-used deep recommendation models.
ConKI: Contrastive Knowledge Injection for Multimodal Sentiment Analysis
Jun 27, 2023



Multimodal Sentiment Analysis leverages multimodal signals to detect the sentiment of a speaker. Previous approaches concentrate on performing multimodal fusion and representation learning based on general knowledge obtained from pretrained models, which neglects the effect of domain-specific knowledge. In this paper, we propose Contrastive Knowledge Injection (ConKI) for multimodal sentiment analysis, where specific-knowledge representations for each modality can be learned together with general knowledge representations via knowledge injection based on an adapter architecture. In addition, ConKI uses a hierarchical contrastive learning procedure performed between knowledge types within every single modality, across modalities within each sample, and across samples to facilitate the effective learning of the proposed representations, hence improving multimodal sentiment predictions. The experiments on three popular multimodal sentiment analysis benchmarks show that ConKI outperforms all prior methods on a variety of performance metrics.
TCR: Short Video Title Generation and Cover Selection with Attention Refinement
Apr 25, 2023With the widespread popularity of user-generated short videos, it becomes increasingly challenging for content creators to promote their content to potential viewers. Automatically generating appealing titles and covers for short videos can help grab viewers' attention. Existing studies on video captioning mostly focus on generating factual descriptions of actions, which do not conform to video titles intended for catching viewer attention. Furthermore, research for cover selection based on multimodal information is sparse. These problems motivate the need for tailored methods to specifically support the joint task of short video title generation and cover selection (TG-CS) as well as the demand for creating corresponding datasets to support the studies. In this paper, we first collect and present a real-world dataset named Short Video Title Generation (SVTG) that contains videos with appealing titles and covers. We then propose a Title generation and Cover selection with attention Refinement (TCR) method for TG-CS. The refinement procedure progressively selects high-quality samples and highly relevant frames and text tokens within each sample to refine model training. Extensive experiments show that our TCR method is superior to various existing video captioning methods in generating titles and is able to select better covers for noisy real-world short videos.
Search-Map-Search: A Frame Selection Paradigm for Action Recognition
Apr 20, 2023



Despite the success of deep learning in video understanding tasks, processing every frame in a video is computationally expensive and often unnecessary in real-time applications. Frame selection aims to extract the most informative and representative frames to help a model better understand video content. Existing frame selection methods either individually sample frames based on per-frame importance prediction, without considering interaction among frames, or adopt reinforcement learning agents to find representative frames in succession, which are costly to train and may lead to potential stability issues. To overcome the limitations of existing methods, we propose a Search-Map-Search learning paradigm which combines the advantages of heuristic search and supervised learning to select the best combination of frames from a video as one entity. By combining search with learning, the proposed method can better capture frame interactions while incurring a low inference overhead. Specifically, we first propose a hierarchical search method conducted on each training video to search for the optimal combination of frames with the lowest error on the downstream task. A feature mapping function is then learned to map the frames of a video to the representation of its target optimal frame combination. During inference, another search is performed on an unseen video to select a combination of frames whose feature representation is close to the projected feature representation. Extensive experiments based on several action recognition benchmarks demonstrate that our frame selection method effectively improves performance of action recognition models, and significantly outperforms a number of competitive baselines.
TAG: Toward Accurate Social Media Content Tagging with a Concept Graph
Oct 24, 2021
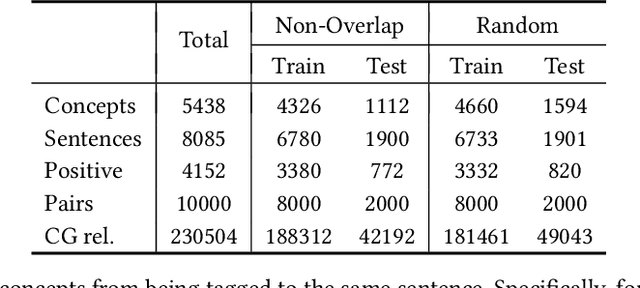

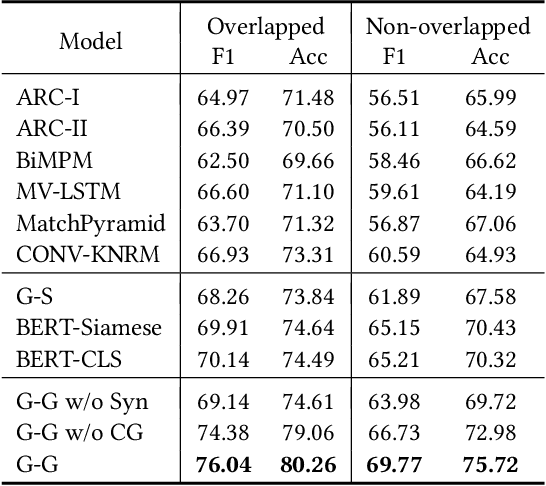
Although conceptualization has been widely studied in semantics and knowledge representation, it is still challenging to find the most accurate concept phrases to characterize the main idea of a text snippet on the fast-growing social media. This is partly attributed to the fact that most knowledge bases contain general terms of the world, such as trees and cars, which do not have the defining power or are not interesting enough to social media app users. Another reason is that the intricacy of natural language allows the use of tense, negation and grammar to change the logic or emphasis of language, thus conveying completely different meanings. In this paper, we present TAG, a high-quality concept matching dataset consisting of 10,000 labeled pairs of fine-grained concepts and web-styled natural language sentences, mined from the open-domain social media. The concepts we consider represent the trending interests of online users. Associated with TAG is a concept graph of these fine-grained concepts and entities to provide the structural context information. We evaluate a wide range of popular neural text matching models as well as pre-trained language models on TAG, and point out their insufficiency to tag social media content with the most appropriate concept. We further propose a novel graph-graph matching method that demonstrates superior abstraction and generalization performance by better utilizing both the structural context in the concept graph and logic interactions between semantic units in the sentence via syntactic dependency parsing. We open-source both the TAG dataset and the proposed methods to facilitate further research.
Generating Lode Runner Levels by Learning Player Paths with LSTMs
Jul 27, 2021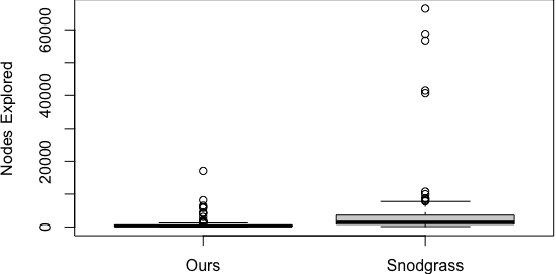


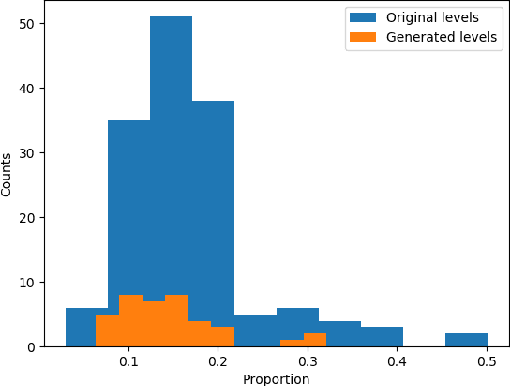
Machine learning has been a popular tool in many different fields, including procedural content generation. However, procedural content generation via machine learning (PCGML) approaches can struggle with controllability and coherence. In this paper, we attempt to address these problems by learning to generate human-like paths, and then generating levels based on these paths. We extract player path data from gameplay video, train an LSTM to generate new paths based on this data, and then generate game levels based on this path data. We demonstrate that our approach leads to more coherent levels for the game Lode Runner in comparison to an existing PCGML approach.
* 7 pages, 6 figures, Workshop on Procedural Content Generation