 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptively Coordinating with Novel Partners via Learned Latent Strategies
Nov 16, 2025Adaptation is the cornerstone of effective collaboration among heterogeneous team members. In human-agent teams, artificial agents need to adapt to their human partners in real time, as individuals often have unique preferences and policies that may change dynamically throughout interactions. This becomes particularly challenging in tasks with time pressure and complex strategic spaces, where identifying partner behaviors and selecting suitable responses is difficult. In this work, we introduce a strategy-conditioned cooperator framework that learns to represent, categorize, and adapt to a broad range of potential partner strategies in real-time. Our approach encodes strategies with a variational autoencoder to learn a latent strategy space from agent trajectory data, identifies distinct strategy types through clustering, and trains a cooperator agent conditioned on these clusters by generating partners of each strategy type. For online adaptation to novel partners, we leverage a fixed-share regret minimization algorithm that dynamically infers and adjusts the partner's strategy estimation during interaction. We evaluate our method in a modified version of the Overcooked domain, a complex collaborative cooking environment that requires effective coordination among two players with a diverse potential strategy space. Through these experiments and an online user study, we demonstrate that our proposed agent achieves state of the art performance compared to existing baselines when paired with novel human, and agent teammates.
Personalized Decision Supports based on Theory of Mind Modeling and Explainable Reinforcement Learning
Dec 13, 2023



In this paper, we propose a novel personalized decision support system that combines Theory of Mind (ToM) modeling and explainable Reinforcement Learning (XRL) to provide effective and interpretable interventions. Our method leverages DRL to provide expert action recommendations while incorporating ToM modeling to understand users' mental states and predict their future actions, enabling appropriate timing for intervention. To explain interventions, we use counterfactual explanations based on RL's feature importance and users' ToM model structure. Our proposed system generates accurate and personalized interventions that are easily interpretable by end-users. We demonstrate the effectiveness of our approach through a series of crowd-sourcing experiments in a simulated team decision-making task, where our system outperforms control baselines in terms of task performance. Our proposed approach is agnostic to task environment and RL model structure, therefore has the potential to be generalized to a wide range of applications.
Long-Horizon Dialogue Understanding for Role Identification in the Game of Avalon with Large Language Models
Nov 09, 2023Deception and persuasion play a critical role in long-horizon dialogues between multiple parties, especially when the interests, goals, and motivations of the participants are not aligned. Such complex tasks pose challenges for current Large Language Models (LLM) as deception and persuasion can easily mislead them, especially in long-horizon multi-party dialogues. To this end, we explore the game of Avalon: The Resistance, a social deduction game in which players must determine each other's hidden identities to complete their team's objective. We introduce an online testbed and a dataset containing 20 carefully collected and labeled games among human players that exhibit long-horizon deception in a cooperative-competitive setting. We discuss the capabilities of LLMs to utilize deceptive long-horizon conversations between six human players to determine each player's goal and motivation. Particularly, we discuss the multimodal integration of the chat between the players and the game's state that grounds the conversation, providing further insights into the true player identities. We find that even current state-of-the-art LLMs do not reach human performance, making our dataset a compelling benchmark to investigate the decision-making and language-processing capabilities of LLMs. Our dataset and online testbed can be found at our project website: https://sstepput.github.io/Avalon-NLU/
Theory of Mind for Multi-Agent Collaboration via Large Language Models
Oct 22, 2023



While Large Language Models (LLMs) have demonstrated impressive accomplishments in both reasoning and planning, their abilities in multi-agent collaborations remains largely unexplored. This study evaluates LLM-based agents in a multi-agent cooperative text game with Theory of Mind (ToM) inference tasks, comparing their performance with Multi-Agent Reinforcement Learning (MARL) and planning-based baselines. We observed evidence of emergent collaborative behaviors and high-order Theory of Mind capabilities among LLM-based agents. Our results reveal limitations in LLM-based agents' planning optimization due to systematic failures in managing long-horizon contexts and hallucination about the task state. We explore the use of explicit belief state representations to mitigate these issues, finding that it enhances task performance and the accuracy of ToM inferences for LLM-based agents.
The Enforcers: Consistent Sparse-Discrete Methods for Constraining Informative Emergent Communication
Jan 19, 2022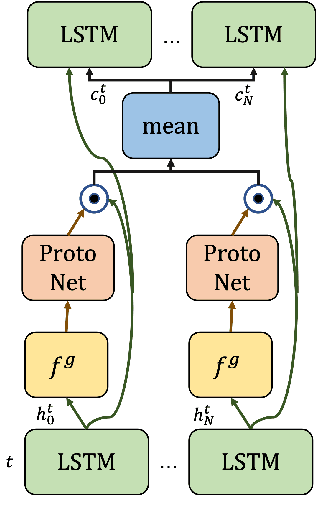
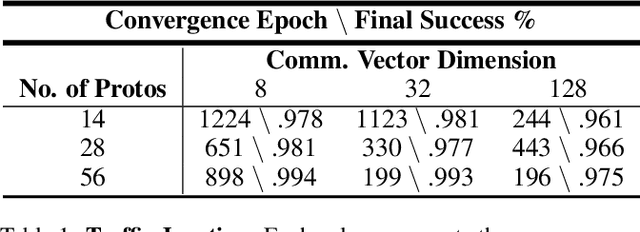
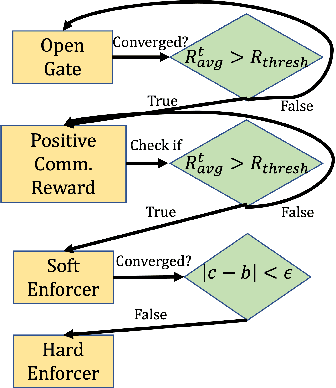
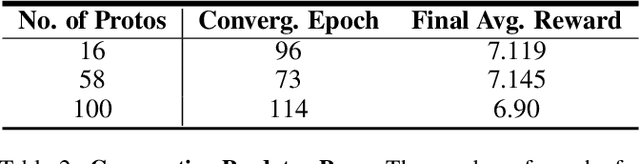
Communication enables agents to cooperate to achieve their goals. Learning when to communicate, i.e. sparse communication, is particularly important where bandwidth is limited, in situations where agents interact with humans, in partially observable scenarios where agents must convey information unavailable to others, and in non-cooperative scenarios where agents may hide information to gain a competitive advantage. Recent work in learning sparse communication, however, suffers from high variance training where, the price of decreasing communication is a decrease in reward, particularly in cooperative tasks. Sparse communications are necessary to match agent communication to limited human bandwidth. Humans additionally communicate via discrete linguistic tokens, previously shown to decrease task performance when compared to continuous communication vectors. This research addresses the above issues by limiting the loss in reward of decreasing communication and eliminating the penalty for discretization. In this work, we successfully constrain training using a learned gate to regulate when to communicate while using discrete prototypes that reflect what to communicate for cooperative tasks with partial observability. We provide two types of "Enforcers" for hard and soft budget constraints and present results of communication under different budgets. We show that our method satisfies constraints while yielding the same performance as comparable, unconstrained methods.
Emergent Discrete Communication in Semantic Spaces
Aug 05, 2021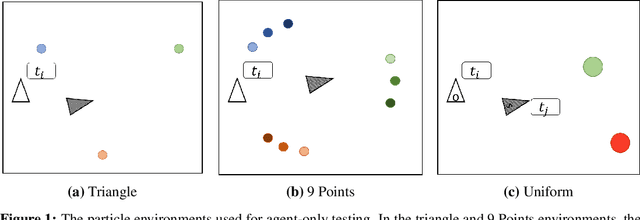
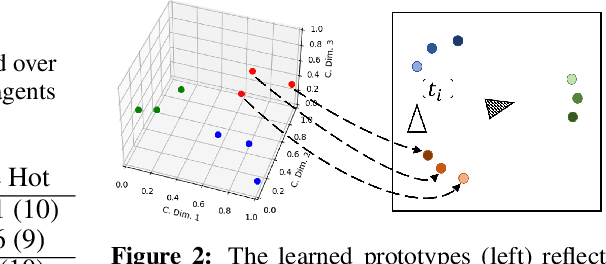

Neural agents trained in reinforcement learning settings can learn to communicate among themselves via discrete tokens, accomplishing as a team what agents would be unable to do alone. However, the current standard of using one-hot vectors as discrete communication tokens prevents agents from acquiring more desirable aspects of communication such as zero-shot understanding. Inspired by word embedding techniques from natural language processing, we propose neural agent architectures that enables them to communicate via discrete tokens derived from a learned, continuous space. We show in a decision theoretic framework that our technique optimizes communication over a wide range of scenarios, whereas one-hot tokens are only optimal under restrictive assumptions. In self-play experiments, we validate that our trained agents learn to cluster tokens in semantically-meaningful ways, allowing them communicate in noisy environments where other techniques fail. Lastly, we demonstrate both that agents using our method can effectively respond to novel human communication and that humans can understand unlabeled emergent agent communication, outperforming the use of one-hot communication.
Hiding Leader's Identity in Leader-Follower Navigation through Multi-Agent Reinforcement Learning
Mar 10, 2021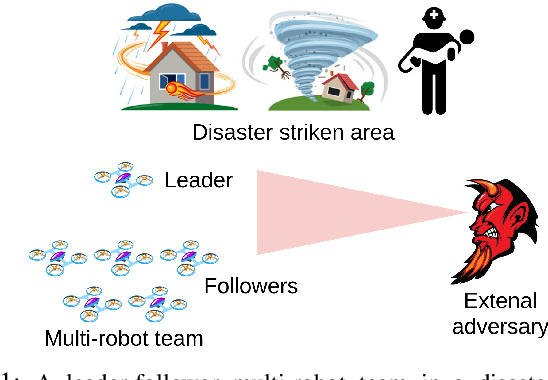
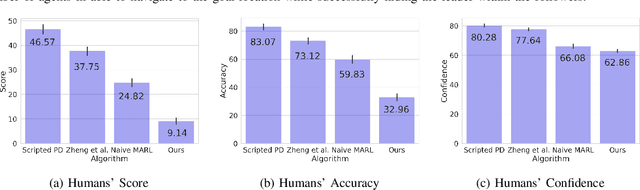
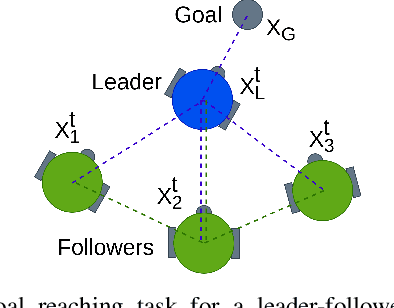
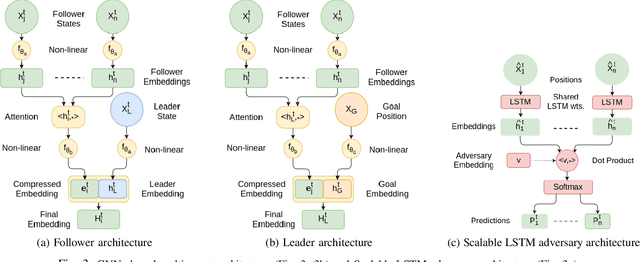
Leader-follower navigation is a popular class of multi-robot algorithms where a leader robot leads the follower robots in a team. The leader has specialized capabilities or mission critical information (e.g. goal location) that the followers lack which makes the leader crucial for the mission's success. However, this also makes the leader a vulnerability - an external adversary who wishes to sabotage the robot team's mission can simply harm the leader and the whole robot team's mission would be compromised. Since robot motion generated by traditional leader-follower navigation algorithms can reveal the identity of the leader, we propose a defense mechanism of hiding the leader's identity by ensuring the leader moves in a way that behaviorally camouflages it with the followers, making it difficult for an adversary to identify the leader. To achieve this, we combine Multi-Agent Reinforcement Learning, Graph Neural Networks and adversarial training. Our approach enables the multi-robot team to optimize the primary task performance with leader motion similar to follower motion, behaviorally camouflaging it with the followers. Our algorithm outperforms existing work that tries to hide the leader's identity in a multi-robot team by tuning traditional leader-follower control parameters with Classical Genetic Algorithms. We also evaluated human performance in inferring the leader's identity and found that humans had lower accuracy when the robot team used our proposed navigation algorithm.
Adaptive Agent Architecture for Real-time Human-Agent Teaming
Mar 07, 2021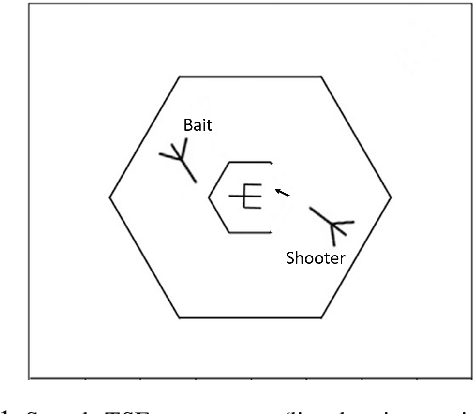
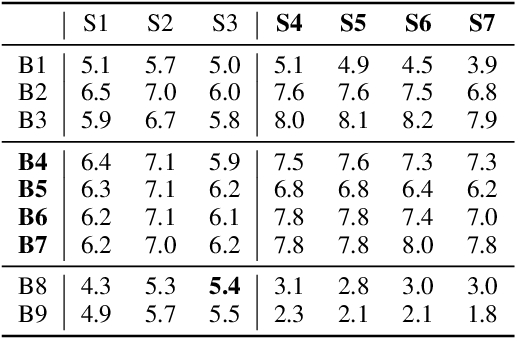
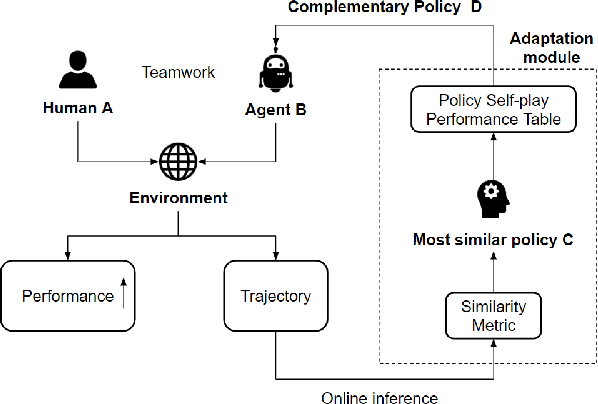
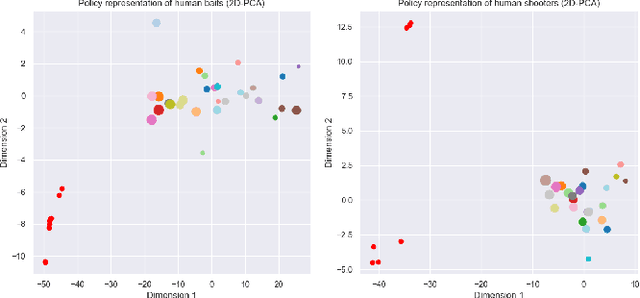
Teamwork is a set of interrelated reasoning, actions and behaviors of team members that facilitate common objectives. Teamwork theory and experiments have resulted in a set of states and processes for team effectiveness in both human-human and agent-agent teams. However, human-agent teaming is less well studied because it is so new and involves asymmetry in policy and intent not present in human teams. To optimize team performance in human-agent teaming, it is critical that agents infer human intent and adapt their polices for smooth coordination. Most literature in human-agent teaming builds agents referencing a learned human model. Though these agents are guaranteed to perform well with the learned model, they lay heavy assumptions on human policy such as optimality and consistency, which is unlikely in many real-world scenarios. In this paper, we propose a novel adaptive agent architecture in human-model-free setting on a two-player cooperative game, namely Team Space Fortress (TSF). Previous human-human team research have shown complementary policies in TSF game and diversity in human players' skill, which encourages us to relax the assumptions on human policy. Therefore, we discard learning human models from human data, and instead use an adaptation strategy on a pre-trained library of exemplar policies composed of RL algorithms or rule-based methods with minimal assumptions of human behavior. The adaptation strategy relies on a novel similarity metric to infer human policy and then selects the most complementary policy in our library to maximize the team performance. The adaptive agent architecture can be deployed in real-time and generalize to any off-the-shelf static agents. We conducted human-agent experiments to evaluate the proposed adaptive agent framework, and demonstrated the suboptimality, diversity, and adaptability of human policies in human-agent teams.
SpeakingFaces: A Large-Scale Multimodal Dataset of Voice Commands with Visual and Thermal Video Streams
Dec 18, 2020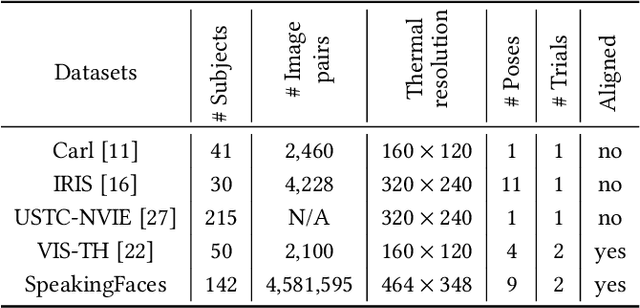


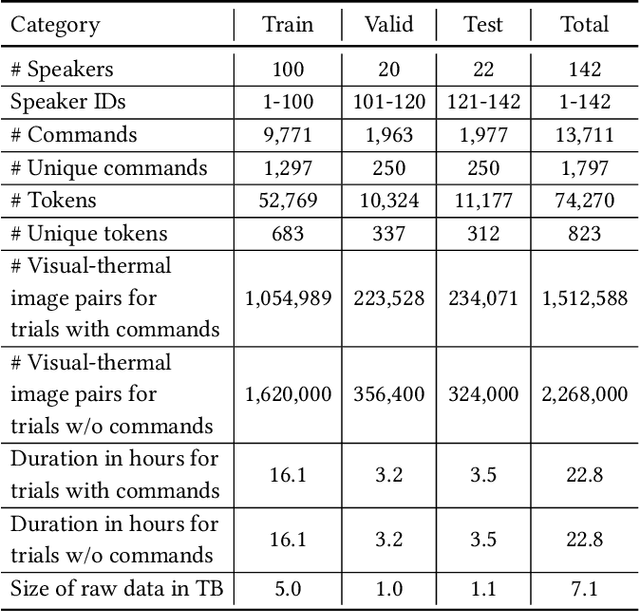
We present SpeakingFaces as a publicly-available large-scale dataset developed to support multimodal machine learning research in contexts that utilize a combination of thermal, visual, and audio data streams; examples include human-computer interaction (HCI), biometric authentication, recognition systems, domain transfer, and speech recognition. SpeakingFaces is comprised of well-aligned high-resolution thermal and visual spectra image streams of fully-framed faces synchronized with audio recordings of each subject speaking approximately 100 imperative phrases. Data were collected from 142 subjects, yielding over 13,000 instances of synchronized data (~3.8 TB). For technical validation, we demonstrate two baseline examples. The first baseline shows classification by gender, utilizing different combinations of the three data streams in both clean and noisy environments. The second example consists of thermal-to-visual facial image translation, as an instance of domain transfer.
Predicting Human Strategies in Simulated Search and Rescue Task
Nov 19, 2020
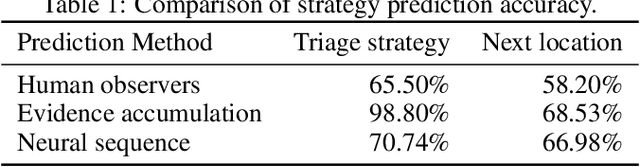

In a search and rescue scenario, rescuers may have different knowledge of the environment and strategies for exploration. Understanding what is inside a rescuer's mind will enable an observer agent to proactively assist them with critical information that can help them perform their task efficiently. To this end, we propose to build models of the rescuers based on their trajectory observations to predict their strategies. In our efforts to model the rescuer's mind, we begin with a simple simulated search and rescue task in Minecraft with human participants. We formulate neural sequence models to predict the triage strategy and the next location of the rescuer. As the neural networks are data-driven, we design a diverse set of artificial "faux human" agents for training, to test them with limited human rescuer trajectory data. To evaluate the agents, we compare it to an evidence accumulation method that explicitly incorporates all available background knowledge and provides an intended upper bound for the expected performance. Further, we perform experiments where the observer/predictor is human. We show results in terms of prediction accuracy of our computational approaches as compared with that of human observers.