 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-Isolated Evaluation: Gating the Deterministic Scaffold of a Production LLM Agent with a No-LLM, Regression-Locked Test Harness
Jun 10, 2026End-to-end task-success is the dominant way to evaluate LLM agents, but one aggregate number tells you that an agent regressed, not where. We present layer-isolated evaluation: a deployed ordering agent is decomposed into a fixed taxonomy of layers (ontology, intent, routing, decomposition, escalation, safety, memory, and cross-cutting envelope/defense), each exercised by its own assertion slice in a deterministic, no-LLM "pure" mode. The pure suite (238 cases across 23 slices; 225 run in 2.39 s, ~10 ms/case) runs in CI on every change against a locked per-slice baseline. We validate by controlled regression injection, degrading one layer at a time across seven non-safety layers. The effect we did not design in is masking: the aggregate pass-rate barely moves (-1.7 to -5.9 pp for six local regressions), while the matching slice craters (-25 to -91 pp). A layer's slice reacting to its own fault is partly by construction; the measured results are (i) the aggregate masking and (ii) that damage stays off the other slices: the injected layer's slice is the single worst-hit in 5 of 7 cases and top-3 in 7 of 7 (mean rank 1.29 of 19). Localization replicates on a second, structurally different tenant (Starbucks SG): all seven matching slices crater, so it is not a single-catalog artifact. We position it as a concrete, deterministic instantiation of the component-level evaluation EDDOps prescribes but leaves unimplemented, with CheckList as ancestor and as the deterministic mirror image of whole-workflow stochastic mutation testing. Our contributions: (a) a fully decomposed, sub-second, no-LLM per-layer harness for a production agent, (b) a coverage-honesty test-adequacy criterion that refuses to score an unexercised layer, and (c) the regression-injection demonstration that per-slice baseline-locked gates localize regressions an aggregate metric masks.
Catching One in Five: LLM-as-Judge Blind Spots in Production Multi-Turn Transaction Agents
Jun 09, 2026LLM-as-judge is the default instrument for evaluating conversational agents, yet its reliability is almost always reported as agreement with human ratings, not recall of real defects. We study a deployed multi-turn food-and-beverage ordering agent and measure how many genuine quality problems its built-in LLM judge catches, using exhaustive human transcript review as ground truth. Across three batches the judge surfaces well under a quarter of human-confirmed systematic problems -- 2 of 9 patterns (22%) in one batch, and its operational gate flagged zero of 100 rounds in a batch where humans confirmed 23 distinct defects and 7 new cross-cutting patterns. Our blind-spot taxonomy shows the failure is structured, not random: the judge catches turn-local issues (a fabricated statistic, a wrong language) but misses cross-turn state issues (confirm-gate lockout, cart hallucination, escalation lockout, stale referents). The mechanism: the scoring rubric exposes only three coarse axes (intent, brand-voice, personalization) and has no category for the behavioural dimensions -- state-tracking, guardrails, recovery -- where most defects cluster. The failure is routing, not perception: 113 of 114 rounds whose raw judge note describes a confirm-gate or cart-state defect are scored "brand voice", and none reach an operational failure -- the gate is wired to hangs and hard assertions, not the rubric -- so the 0% is a routing-and-wiring failure, not blindness. The consequence for prevalence estimation is sharp: when the apparent defect rate is zero the Rogan-Gladen correction degenerates -- no signal can recover the true rate -- while where the gate reports a nonzero rate the same estimator implies a 3-6x undercount under our measured sensitivity. For production multi-turn agents, automated judging is a regression floor, not a substitute for human review.
Online learning of smooth functions on $\mathbb{R}$
Apr 04, 2026We study adversarial online learning of real-valued functions on $\mathbb{R}$. In each round the learner is queried at $x_t\in\mathbb{R}$, predicts $\hat y_t$, and then observes the true value $f(x_t)$; performance is measured by cumulative $p$-loss $\sum_{t\ge 1}|\hat y_t-f(x_t)|^p$. For the class \[ \mathcal{G}_q=\Bigl\{f:\mathbb{R}\to\mathbb{R}\ \text{absolutely continuous}:\ \int_{\mathbb{R}}|f'(x)|^q\,dx\le 1\Bigr\}, \] we show that the standard model becomes ill-posed on $\mathbb{R}$: for every $p\ge 1$ and $q>1$, an adversary can force infinite loss. Motivated by this obstruction, we analyze three modified learning scenarios that limit the influence of queries that are far from previously observed inputs. In Scenario 1 the adversary must choose each new query within distance $1$ of some past query. In Scenario 2 the adversary may query anywhere, but the learner is penalized only on rounds whose query lies within distance $1$ of a past query. In Scenario 3 the loss in round $t$ is multiplied by a weight $g(\min_{j<t}|x_t-x_j|)$. We obtain sharp characterizations for Scenarios 1-2 in several regimes. For Scenario 3 we identify a clean threshold phenomenon: if $g$ decays too slowly, then the adversary can force infinite weighted loss. In contrast, for rapidly decaying weights such as $g(z)=e^{-cz}$ we obtain finite and sharp guarantees in the quadratic case $p=q=2$. Finally, we study a natural multivariable slice generalization $\mathcal{G}_{q,d}$ of $\mathcal{G}_q$ on $\mathbb{R}^d$ and show a sharp dichotomy: while the one-dimensional case admits finite opt-values in certain regimes, for every $d\ge 2$ the slice class $\mathcal{G}_{q,d}$ is too permissive, and even under Scenarios 1-3 an adversary can force infinite loss.
GameDevBench: Evaluating Agentic Capabilities Through Game Development
Feb 11, 2026Despite rapid progress on coding agents, progress on their multimodal counterparts has lagged behind. A key challenge is the scarcity of evaluation testbeds that combine the complexity of software development with the need for deep multimodal understanding. Game development provides such a testbed as agents must navigate large, dense codebases while manipulating intrinsically multimodal assets such as shaders, sprites, and animations within a visual game scene. We present GameDevBench, the first benchmark for evaluating agents on game development tasks. GameDevBench consists of 132 tasks derived from web and video tutorials. Tasks require significant multimodal understanding and are complex -- the average solution requires over three times the amount of lines of code and file changes compared to prior software development benchmarks. Agents still struggle with game development, with the best agent solving only 54.5% of tasks. We find a strong correlation between perceived task difficulty and multimodal complexity, with success rates dropping from 46.9% on gameplay-oriented tasks to 31.6% on 2D graphics tasks. To improve multimodal capability, we introduce two simple image and video-based feedback mechanisms for agents. Despite their simplicity, these methods consistently improve performance, with the largest change being an increase in Claude Sonnet 4.5's performance from 33.3% to 47.7%. We release GameDevBench publicly to support further research into agentic game development.
Auptimize: Optimal Placement of Spatial Audio Cues for Extended Reality
Aug 18, 2024



Spatial audio in Extended Reality (XR) provides users with better awareness of where virtual elements are placed, and efficiently guides them to events such as notifications, system alerts from different windows, or approaching avatars. Humans, however, are inaccurate in localizing sound cues, especially with multiple sources due to limitations in human auditory perception such as angular discrimination error and front-back confusion. This decreases the efficiency of XR interfaces because users misidentify from which XR element a sound is coming. To address this, we propose Auptimize, a novel computational approach for placing XR sound sources, which mitigates such localization errors by utilizing the ventriloquist effect. Auptimize disentangles the sound source locations from the visual elements and relocates the sound sources to optimal positions for unambiguous identification of sound cues, avoiding errors due to inter-source proximity and front-back confusion. Our evaluation shows that Auptimize decreases spatial audio-based source identification errors compared to playing sound cues at the paired visual-sound locations. We demonstrate the applicability of Auptimize for diverse spatial audio-based interactive XR scenarios.
STAT: Shrinking Transformers After Training
May 29, 2024



We present STAT: a simple algorithm to prune transformer models without any fine-tuning. STAT eliminates both attention heads and neurons from the network, while preserving accuracy by calculating a correction to the weights of the next layer. Each layer block in the network is compressed using a series of principled matrix factorizations that preserve the network structure. Our entire algorithm takes minutes to compress BERT, and less than three hours to compress models with 7B parameters using a single GPU. Using only several hundred data examples, STAT preserves the output of the network and improves upon existing gradient-free pruning methods. It is even competitive with methods that include significant fine-tuning. We demonstrate our method on both encoder and decoder architectures, including BERT, DistilBERT, and Llama-2 using benchmarks such as GLUE, Squad, WikiText2.
SketchEmbedNet: Learning Novel Concepts by Imitating Drawings
Aug 27, 2020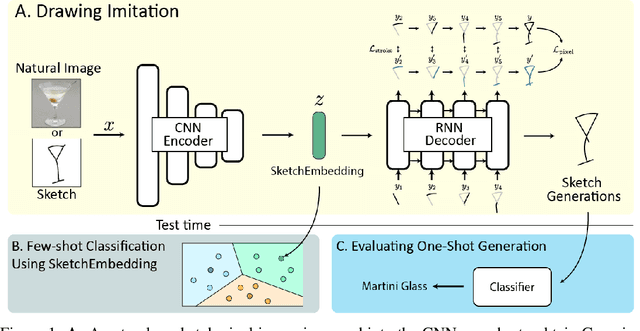
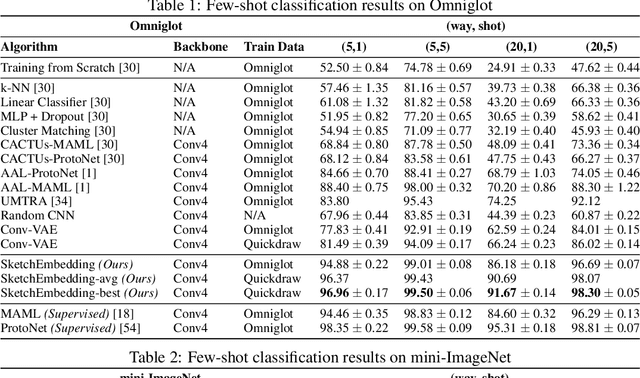

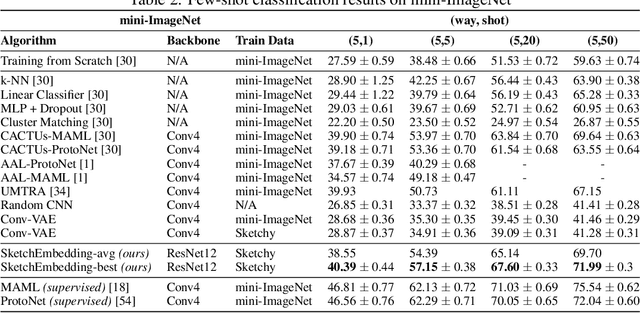
Sketch drawings are an intuitive visual domain that generally preserves semantics. Previous work has shown that recurrent neural networks are capable of producing sketch drawings of a single or few classes at a time. In this work we focus on the representations developed by training a generative model to produce sketches from pixel images across many classes in a sketch domain. We find that the embeddings learned by this sketching model are extremely informative for visual tasks and infer compositional information. We then use them to exceed state-of-the-art performance in unsupervised few-shot classification on the Omniglot and mini-ImageNet benchmarks. We also leverage the generative capacity of our model to produce high quality sketches of novel classes based on just a single example.
Covering up bias in CelebA-like datasets with Markov blankets: A post-hoc cure for attribute prior avoidance
Jul 22, 2019

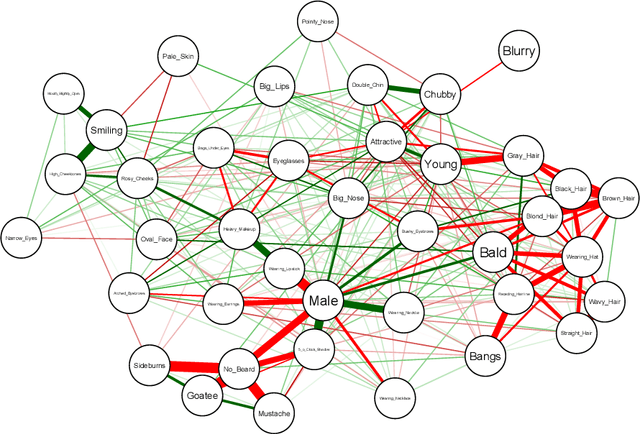
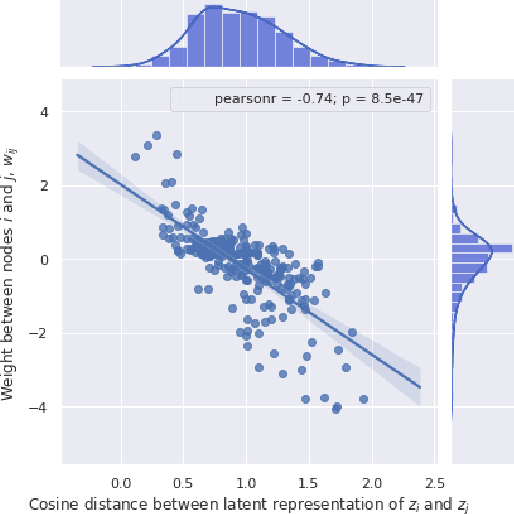
Attribute prior avoidance entails subconscious or willful non-modeling of (meta)attributes that datasets are oft born with, such as the 40 semantic facial attributes associated with the CelebA and CelebA-HQ datasets. The consequences of this infirmity, we discover, are especially stark in state-of-the-art deep generative models learned on these datasets that just model the pixel-space measurements, resulting in an inter-attribute bias-laden latent space. This viscerally manifests itself when we perform face manipulation experiments based on latent vector interpolations. In this paper, we address this and propose a post-hoc solution that utilizes an Ising attribute prior learned in the attribute space and showcase its efficacy via qualitative experiments.