 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Domain Disentanglement for Generalized Multi-source Domain Adaptation
Jul 11, 2022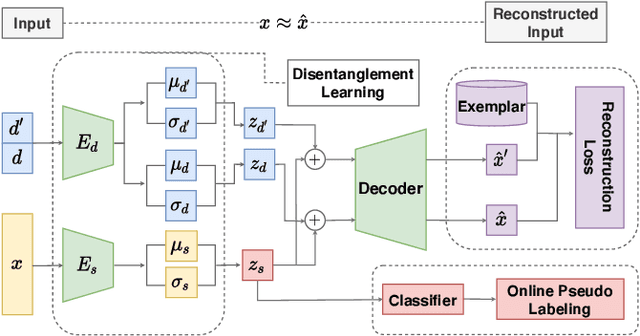


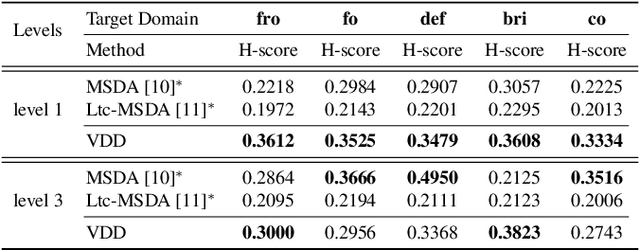
A typical multi-source domain adaptation (MSDA) approach aims to transfer knowledge learned from a set of labeled source domains, to an unlabeled target domain. Nevertheless, prior works strictly assume that each source domain shares the identical group of classes with the target domain, which could hardly be guaranteed as the target label space is not observable. In this paper, we consider a more versatile setting of MSDA, namely Generalized Multi-source Domain Adaptation, wherein the source domains are partially overlapped, and the target domain is allowed to contain novel categories that are not presented in any source domains. This new setting is more elusive than any existing domain adaptation protocols due to the coexistence of the domain and category shifts across the source and target domains. To address this issue, we propose a variational domain disentanglement (VDD) framework, which decomposes the domain representations and semantic features for each instance by encouraging dimension-wise independence. To identify the target samples of unknown classes, we leverage online pseudo labeling, which assigns the pseudo-labels to unlabeled target data based on the confidence scores. Quantitative and qualitative experiments conducted on two benchmark datasets demonstrate the validity of the proposed framework.
GSMFlow: Generation Shifts Mitigating Flow for Generalized Zero-Shot Learning
Jul 08, 2022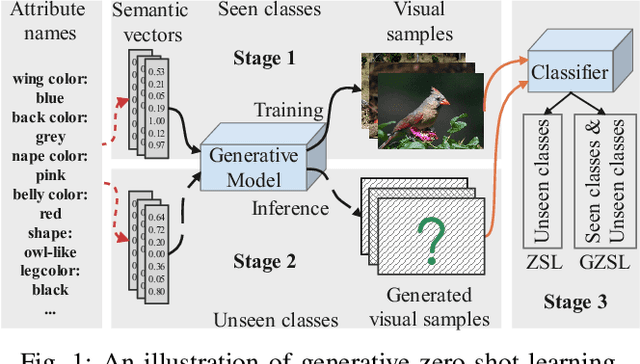
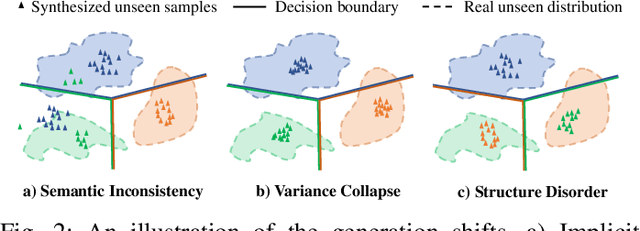
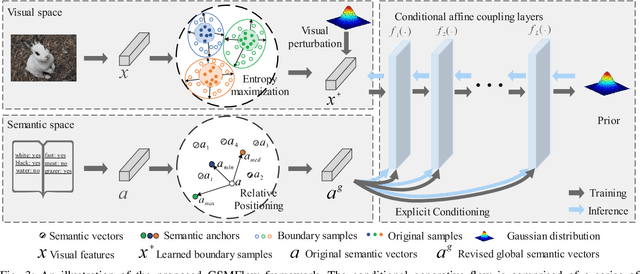
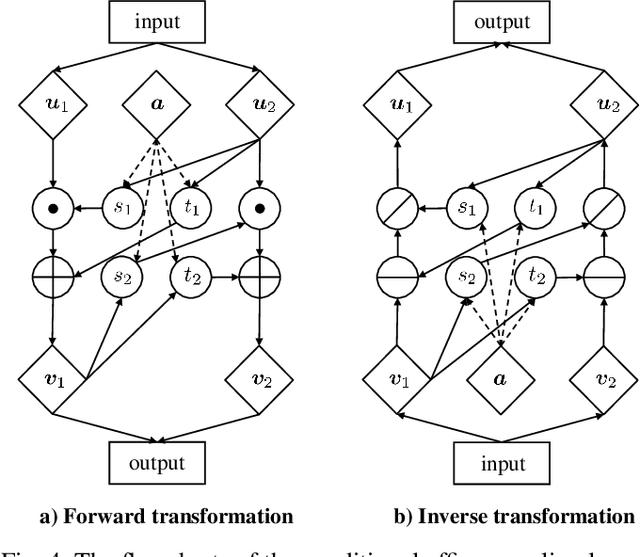
Generalized Zero-Shot Learning (GZSL) aims to recognize images from both the seen and unseen classes by transferring semantic knowledge from seen to unseen classes. It is a promising solution to take the advantage of generative models to hallucinate realistic unseen samples based on the knowledge learned from the seen classes. However, due to the generation shifts, the synthesized samples by most existing methods may drift from the real distribution of the unseen data. To address this issue, we propose a novel flow-based generative framework that consists of multiple conditional affine coupling layers for learning unseen data generation. Specifically, we discover and address three potential problems that trigger the generation shifts, i.e., semantic inconsistency, variance collapse, and structure disorder. First, to enhance the reflection of the semantic information in the generated samples, we explicitly embed the semantic information into the transformation in each conditional affine coupling layer. Second, to recover the intrinsic variance of the real unseen features, we introduce a boundary sample mining strategy with entropy maximization to discover more difficult visual variants of semantic prototypes and hereby adjust the decision boundary of the classifiers. Third, a relative positioning strategy is proposed to revise the attribute embeddings, guiding them to fully preserve the inter-class geometric structure and further avoid structure disorder in the semantic space. Extensive experimental results on four GZSL benchmark datasets demonstrate that GSMFlow achieves the state-of-the-art performance on GZSL.
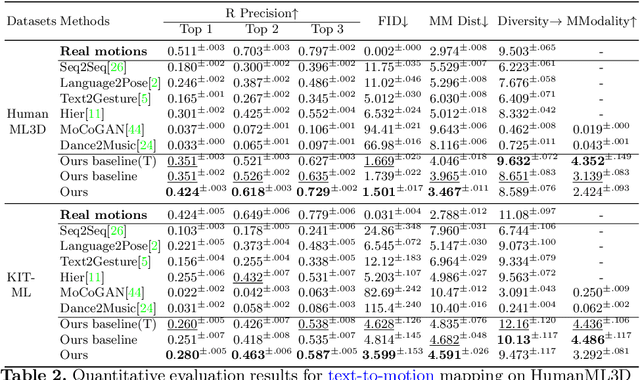
TM2T: Stochastic and Tokenized Modeling for the Reciprocal Generation of 3D Human Motions and Texts
Jul 04, 2022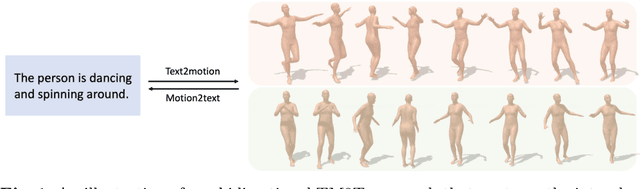
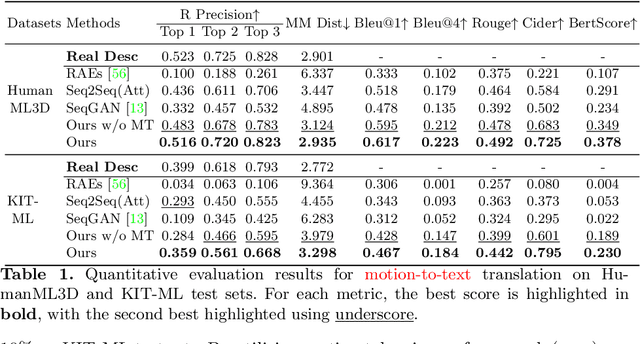
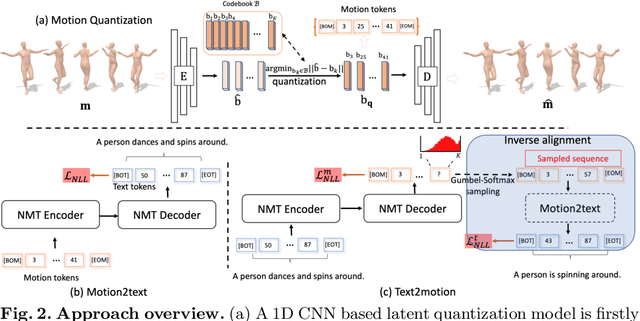
Inspired by the strong ties between vision and language, the two intimate human sensing and communication modalities, our paper aims to explore the generation of 3D human full-body motions from texts, as well as its reciprocal task, shorthanded for text2motion and motion2text, respectively. To tackle the existing challenges, especially to enable the generation of multiple distinct motions from the same text, and to avoid the undesirable production of trivial motionless pose sequences, we propose the use of motion token, a discrete and compact motion representation. This provides one level playing ground when considering both motions and text signals, as the motion and text tokens, respectively. Moreover, our motion2text module is integrated into the inverse alignment process of our text2motion training pipeline, where a significant deviation of synthesized text from the input text would be penalized by a large training loss; empirically this is shown to effectively improve performance. Finally, the mappings in-between the two modalities of motions and texts are facilitated by adapting the neural model for machine translation (NMT) to our context. This autoregressive modeling of the distribution over discrete motion tokens further enables non-deterministic production of pose sequences, of variable lengths, from an input text. Our approach is flexible, could be used for both text2motion and motion2text tasks. Empirical evaluations on two benchmark datasets demonstrate the superior performance of our approach on both tasks over a variety of state-of-the-art methods. Project page: https://ericguo5513.github.io/TM2T/
CURL: Continuous, Ultra-compact Representation for LiDAR
May 12, 2022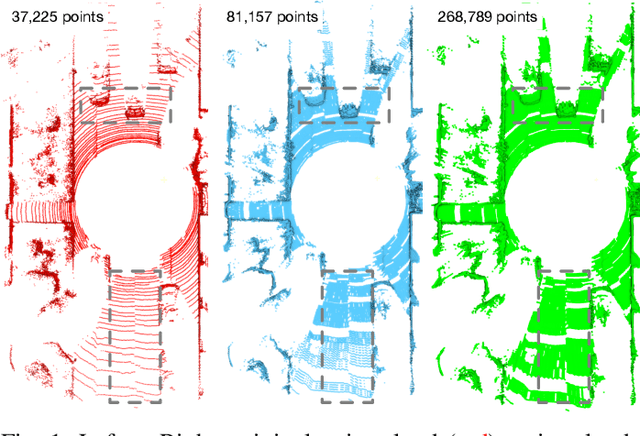
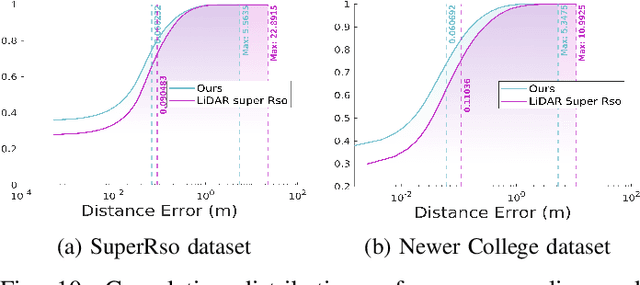

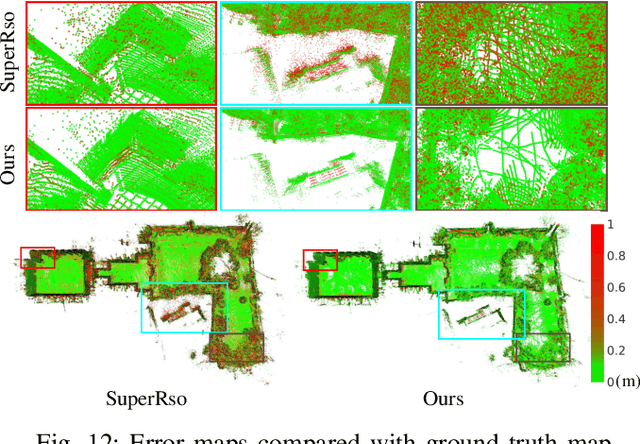
Increasing the density of the 3D LiDAR point cloud is appealing for many applications in robotics. However, high-density LiDAR sensors are usually costly and still limited to a level of coverage per scan (e.g., 128 channels). Meanwhile, denser point cloud scans and maps mean larger volumes to store and longer times to transmit. Existing works focus on either improving point cloud density or compressing its size. This paper aims to design a novel 3D point cloud representation that can continuously increase point cloud density while reducing its storage and transmitting size. The pipeline of the proposed Continuous, Ultra-compact Representation of LiDAR (CURL) includes four main steps: meshing, upsampling, encoding, and continuous reconstruction. It is capable of transforming a 3D LiDAR scan or map into a compact spherical harmonics representation which can be used or transmitted in low latency to continuously reconstruct a much denser 3D point cloud. Extensive experiments on four public datasets, covering college gardens, city streets, and indoor rooms, demonstrate that much denser 3D point clouds can be accurately reconstructed using the proposed CURL representation while achieving up to 80% storage space-saving. We open-source the CURL codes for the community.
Reliability Assessment and Safety Arguments for Machine Learning Components in Assuring Learning-Enabled Autonomous Systems
Nov 30, 2021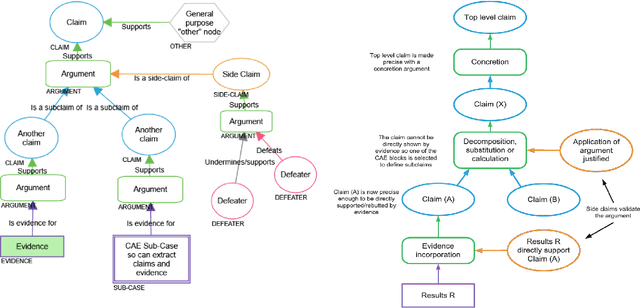

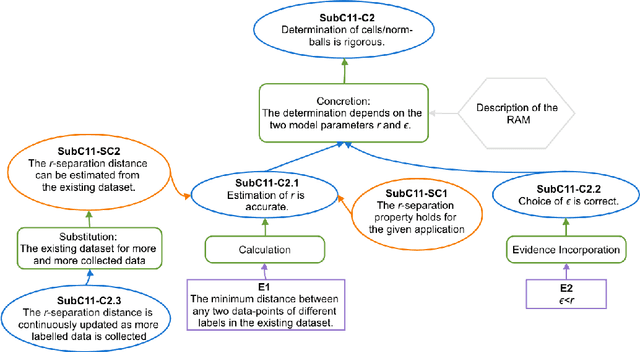
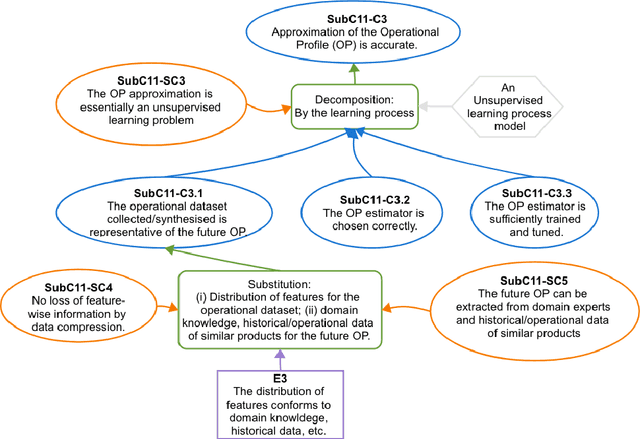
The increasing use of Machine Learning (ML) components embedded in autonomous systems -- so-called Learning-Enabled Systems (LES) -- has resulted in the pressing need to assure their functional safety. As for traditional functional safety, the emerging consensus within both, industry and academia, is to use assurance cases for this purpose. Typically assurance cases support claims of reliability in support of safety, and can be viewed as a structured way of organising arguments and evidence generated from safety analysis and reliability modelling activities. While such assurance activities are traditionally guided by consensus-based standards developed from vast engineering experience, LES pose new challenges in safety-critical application due to the characteristics and design of ML models. In this article, we first present an overall assurance framework for LES with an emphasis on quantitative aspects, e.g., breaking down system-level safety targets to component-level requirements and supporting claims stated in reliability metrics. We then introduce a novel model-agnostic Reliability Assessment Model (RAM) for ML classifiers that utilises the operational profile and robustness verification evidence. We discuss the model assumptions and the inherent challenges of assessing ML reliability uncovered by our RAM and propose practical solutions. Probabilistic safety arguments at the lower ML component-level are also developed based on the RAM. Finally, to evaluate and demonstrate our methods, we not only conduct experiments on synthetic/benchmark datasets but also demonstrate the scope of our methods with a comprehensive case study on Autonomous Underwater Vehicles in simulation.
3D Pose Estimation and Future Motion Prediction from 2D Images
Nov 26, 2021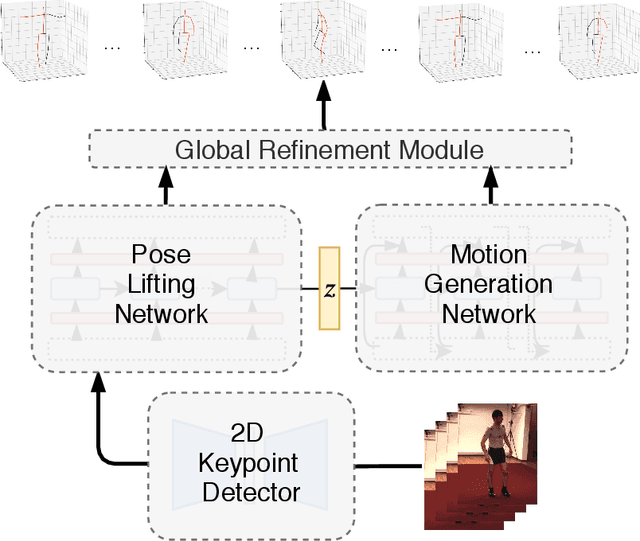
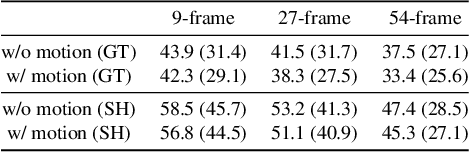

This paper considers to jointly tackle the highly correlated tasks of estimating 3D human body poses and predicting future 3D motions from RGB image sequences. Based on Lie algebra pose representation, a novel self-projection mechanism is proposed that naturally preserves human motion kinematics. This is further facilitated by a sequence-to-sequence multi-task architecture based on an encoder-decoder topology, which enables us to tap into the common ground shared by both tasks. Finally, a global refinement module is proposed to boost the performance of our framework. The effectiveness of our approach, called PoseMoNet, is demonstrated by ablation tests and empirical evaluations on Human3.6M and HumanEva-I benchmark, where competitive performance is obtained comparing to the state-of-the-arts.
Action2video: Generating Videos of Human 3D Actions
Nov 12, 2021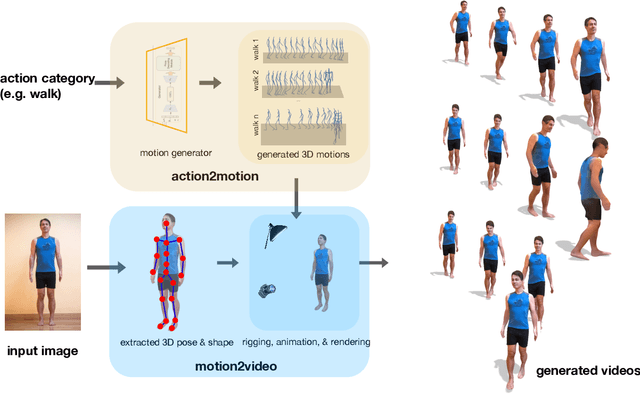
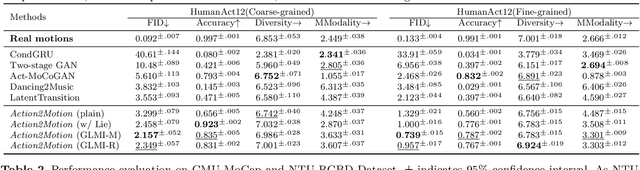
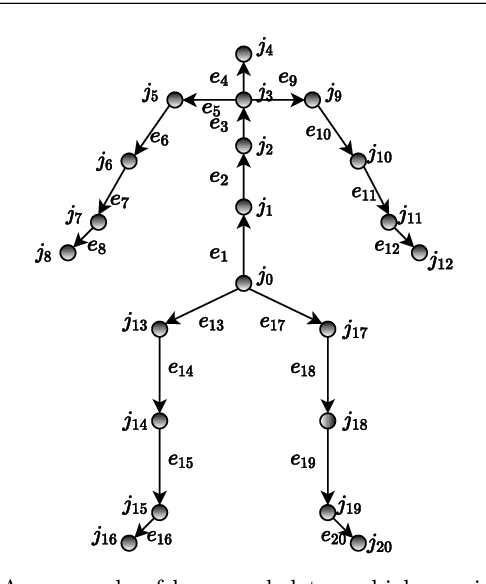
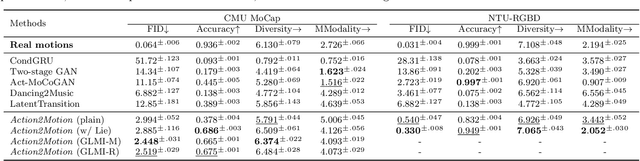
We aim to tackle the interesting yet challenging problem of generating videos of diverse and natural human motions from prescribed action categories. The key issue lies in the ability to synthesize multiple distinct motion sequences that are realistic in their visual appearances. It is achieved in this paper by a two-step process that maintains internal 3D pose and shape representations, action2motion and motion2video. Action2motion stochastically generates plausible 3D pose sequences of a prescribed action category, which are processed and rendered by motion2video to form 2D videos. Specifically, the Lie algebraic theory is engaged in representing natural human motions following the physical law of human kinematics; a temporal variational auto-encoder (VAE) is developed that encourages diversity of output motions. Moreover, given an additional input image of a clothed human character, an entire pipeline is proposed to extract his/her 3D detailed shape, and to render in videos the plausible motions from different views. This is realized by improving existing methods to extract 3D human shapes and textures from single 2D images, rigging, animating, and rendering to form 2D videos of human motions. It also necessitates the curation and reannotation of 3D human motion datasets for training purpose. Thorough empirical experiments including ablation study, qualitative and quantitative evaluations manifest the applicability of our approach, and demonstrate its competitiveness in addressing related tasks, where components of our approach are compared favorably to the state-of-the-arts.
Generalized Polarization Transform: A Novel Coded Transmission Paradigm
Oct 23, 2021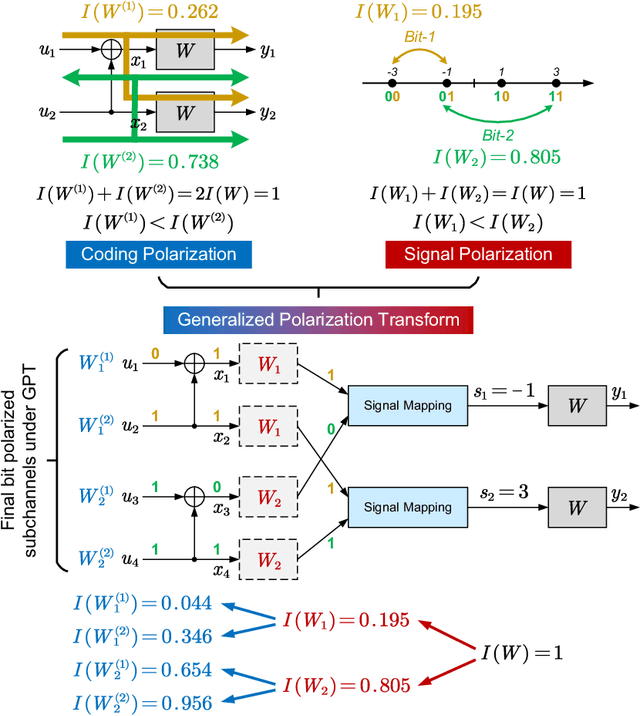
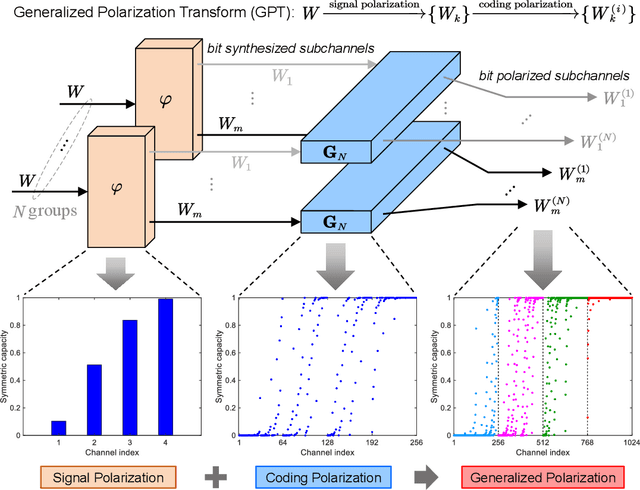
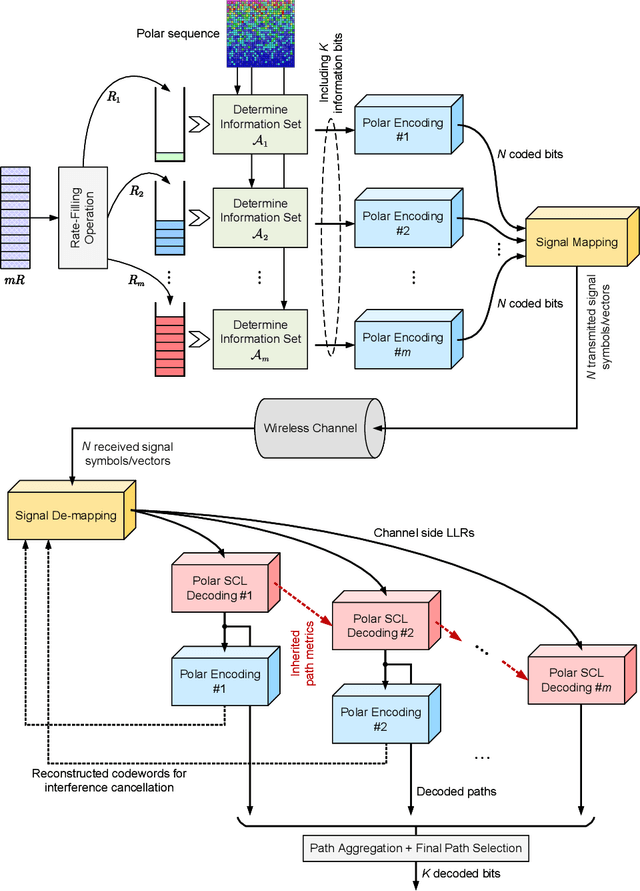
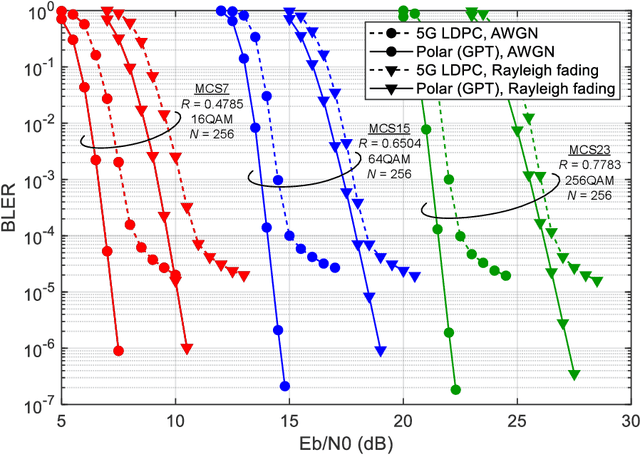
With the standardization and deployment of 5G, the focus has now shifted toward developing beyond-5G (B5G) solutions. A new wave of applications and services will demand ultra-high data rates and reliability. To this end, future wireless systems are expected to pave the way for entirely new fundamental air interface technologies to attain a breakthrough in spectrum efficiency (SE). This article discusses a new paradigm, named generalized polarization transform (GPT), to achieve an integrated design of coding, modulation, multi-antenna, multiple access, etc., in a real sense. The GPT enabled air interface develops far-reaching insights that the joint optimization of critical air interface ingredients can achieve remarkable gains on SE compared with the state-of-the-art module-stacking design. We present a comprehensive overview of the application of GPT in various coded transmission systems approaching Shannon limits under short to moderate blocklengths and highlight several promising trends for future research.
Sequential Diagnosis Prediction with Transformer and Ontological Representation
Sep 07, 2021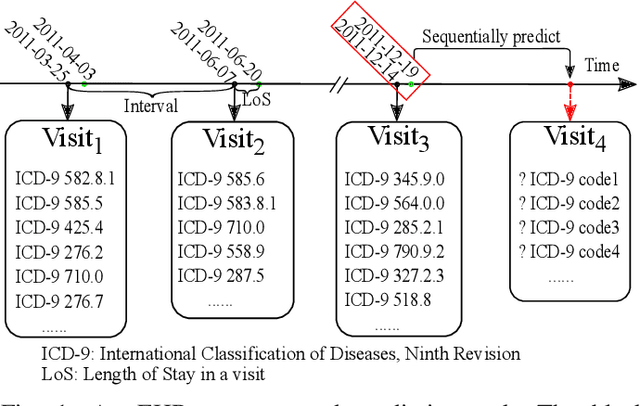
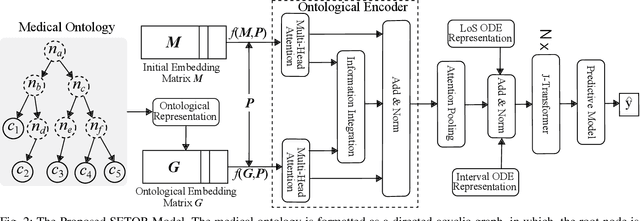
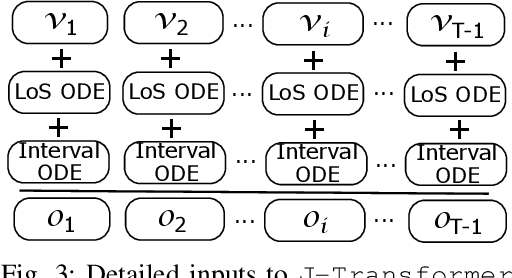
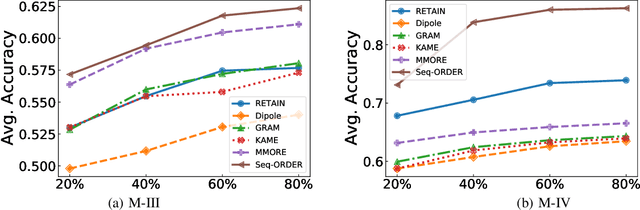
Sequential diagnosis prediction on the Electronic Health Record (EHR) has been proven crucial for predictive analytics in the medical domain. EHR data, sequential records of a patient's interactions with healthcare systems, has numerous inherent characteristics of temporality, irregularity and data insufficiency. Some recent works train healthcare predictive models by making use of sequential information in EHR data, but they are vulnerable to irregular, temporal EHR data with the states of admission/discharge from hospital, and insufficient data. To mitigate this, we propose an end-to-end robust transformer-based model called SETOR, which exploits neural ordinary differential equation to handle both irregular intervals between a patient's visits with admitted timestamps and length of stay in each visit, to alleviate the limitation of insufficient data by integrating medical ontology, and to capture the dependencies between the patient's visits by employing multi-layer transformer blocks. Experiments conducted on two real-world healthcare datasets show that, our sequential diagnoses prediction model SETOR not only achieves better predictive results than previous state-of-the-art approaches, irrespective of sufficient or insufficient training data, but also derives more interpretable embeddings of medical codes. The experimental codes are available at the GitHub repository (https://github.com/Xueping/SETOR).
Global Convolutional Neural Processes
Sep 02, 2021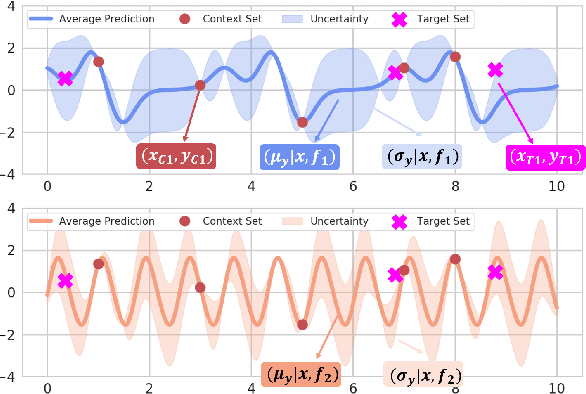
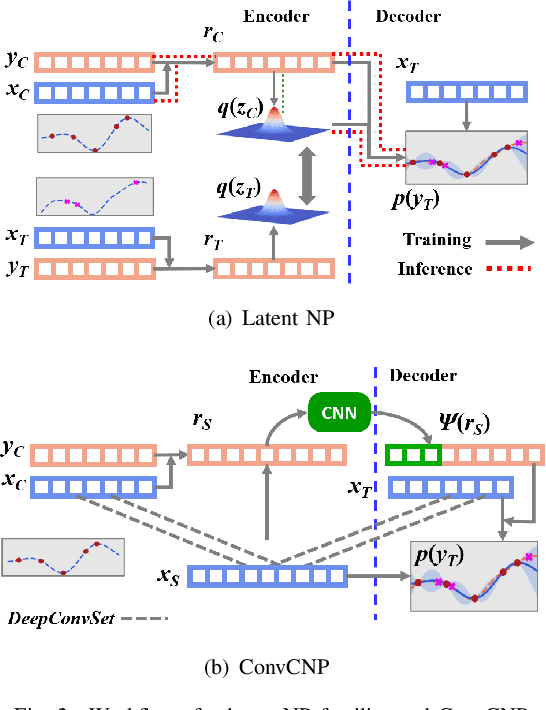
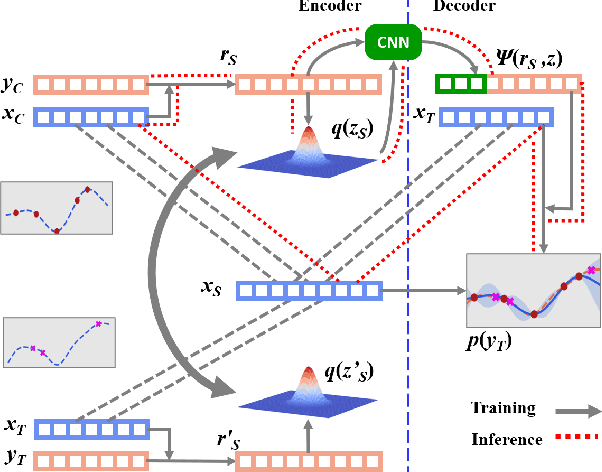
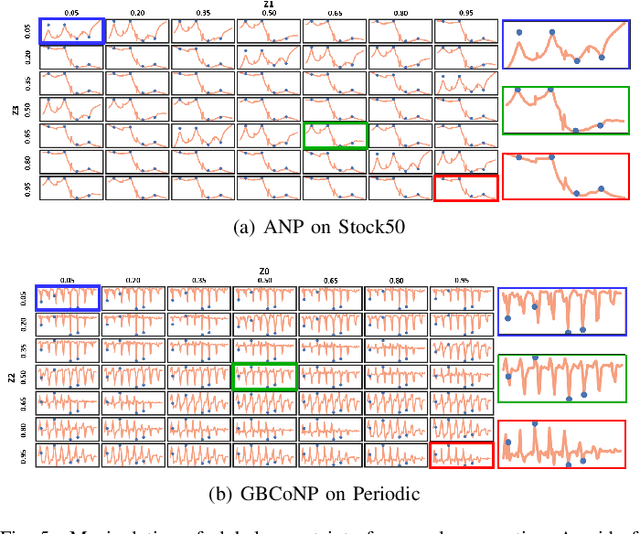
The ability to deal with uncertainty in machine learning models has become equally, if not more, crucial to their predictive ability itself. For instance, during the pandemic, governmental policies and personal decisions are constantly made around uncertainties. Targeting this, Neural Process Families (NPFs) have recently shone a light on prediction with uncertainties by bridging Gaussian processes and neural networks. Latent neural process, a member of NPF, is believed to be capable of modelling the uncertainty on certain points (local uncertainty) as well as the general function priors (global uncertainties). Nonetheless, some critical questions remain unresolved, such as a formal definition of global uncertainties, the causality behind global uncertainties, and the manipulation of global uncertainties for generative models. Regarding this, we build a member GloBal Convolutional Neural Process(GBCoNP) that achieves the SOTA log-likelihood in latent NPFs. It designs a global uncertainty representation p(z), which is an aggregation on a discretized input space. The causal effect between the degree of global uncertainty and the intra-task diversity is discussed. The learnt prior is analyzed on a variety of scenarios, including 1D, 2D, and a newly proposed spatial-temporal COVID dataset. Our manipulation of the global uncertainty not only achieves generating the desired samples to tackle few-shot learning, but also enables the probability evaluation on the functional priors.