 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMONAI Label: A framework for AI-assisted Interactive Labeling of 3D Medical Images
Mar 23, 2022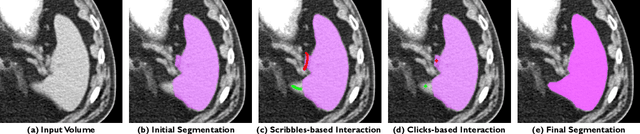
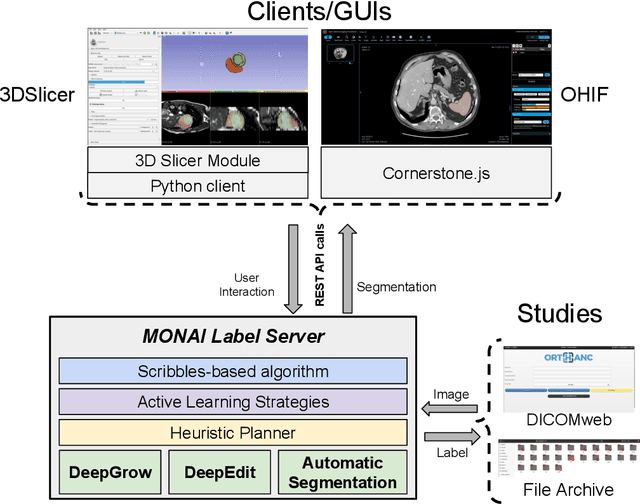
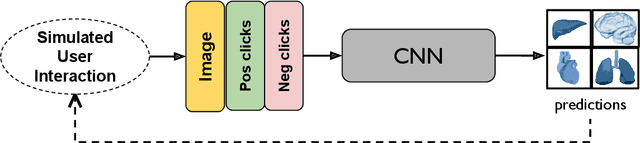
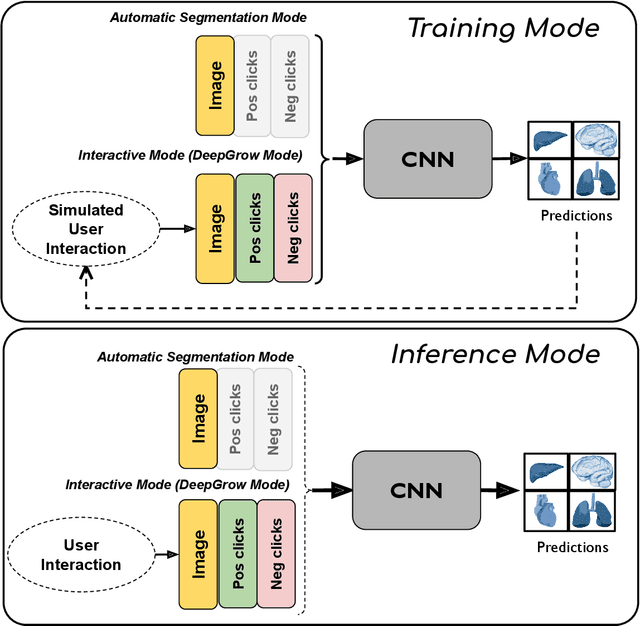
The lack of annotated datasets is a major challenge in training new task-specific supervised AI algorithms as manual annotation is expensive and time-consuming. To address this problem, we present MONAI Label, a free and open-source platform that facilitates the development of AI-based applications that aim at reducing the time required to annotate 3D medical image datasets. Through MONAI Label researchers can develop annotation applications focusing on their domain of expertise. It allows researchers to readily deploy their apps as services, which can be made available to clinicians via their preferred user-interface. Currently, MONAI Label readily supports locally installed (3DSlicer) and web-based (OHIF) frontends, and offers two Active learning strategies to facilitate and speed up the training of segmentation algorithms. MONAI Label allows researchers to make incremental improvements to their labeling apps by making them available to other researchers and clinicians alike. Lastly, MONAI Label provides sample labeling apps, namely DeepEdit and DeepGrow, demonstrating dramatically reduced annotation times.
Augmentation based unsupervised domain adaptation
Feb 23, 2022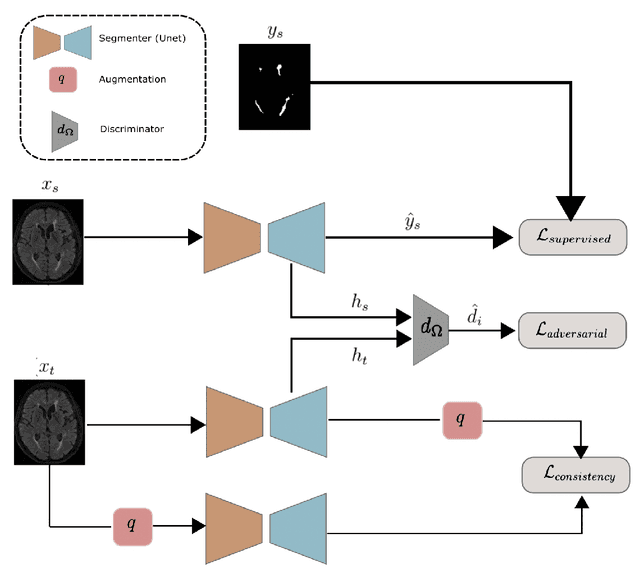

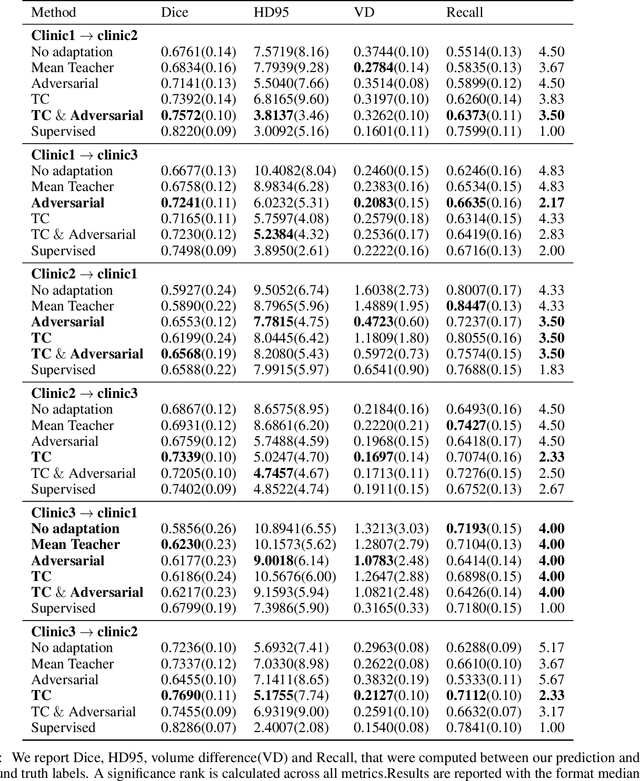
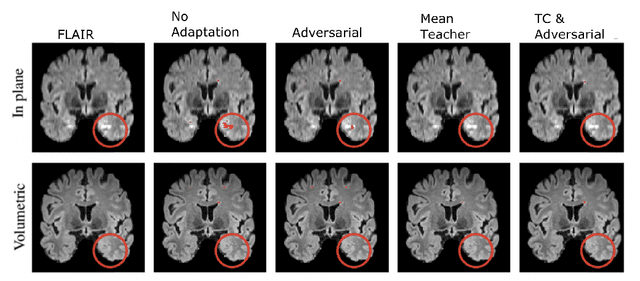
The insertion of deep learning in medical image analysis had lead to the development of state-of-the art strategies in several applications such a disease classification, as well as abnormality detection and segmentation. However, even the most advanced methods require a huge and diverse amount of data to generalize. Because in realistic clinical scenarios, data acquisition and annotation is expensive, deep learning models trained on small and unrepresentative data tend to outperform when deployed in data that differs from the one used for training (e.g data from different scanners). In this work, we proposed a domain adaptation methodology to alleviate this problem in segmentation models. Our approach takes advantage of the properties of adversarial domain adaptation and consistency training to achieve more robust adaptation. Using two datasets with white matter hyperintensities (WMH) annotations, we demonstrated that the proposed method improves model generalization even in corner cases where individual strategies tend to fail.
Motion Correction and Volumetric Reconstruction for Fetal Functional Magnetic Resonance Imaging Data
Feb 11, 2022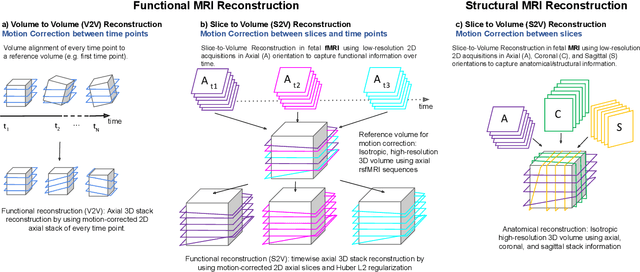
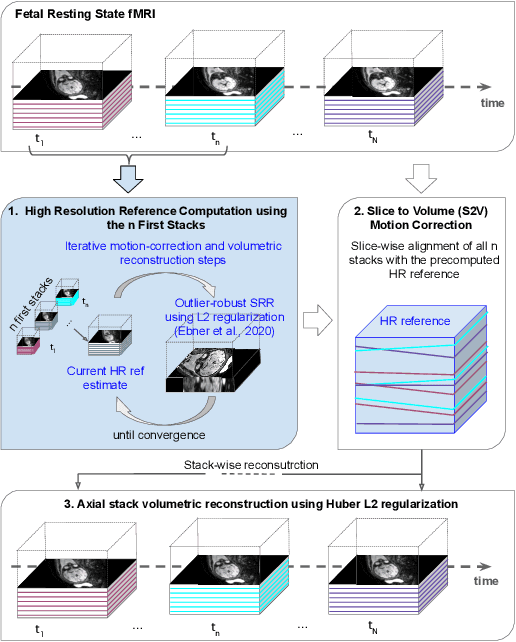
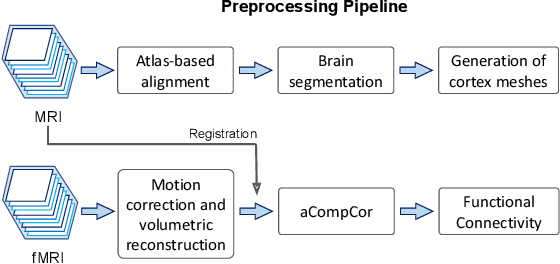
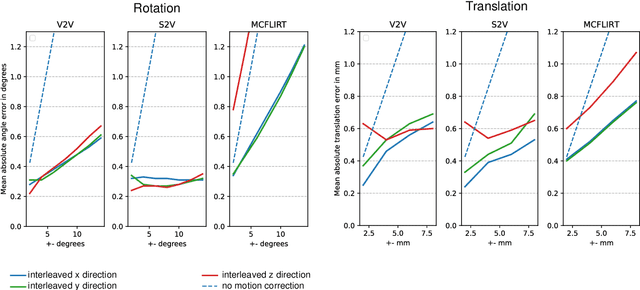
Motion correction is an essential preprocessing step in functional Magnetic Resonance Imaging (fMRI) of the fetal brain with the aim to remove artifacts caused by fetal movement and maternal breathing and consequently to suppress erroneous signal correlations. Current motion correction approaches for fetal fMRI choose a single 3D volume from a specific acquisition timepoint with least motion artefacts as reference volume, and perform interpolation for the reconstruction of the motion corrected time series. The results can suffer, if no low-motion frame is available, and if reconstruction does not exploit any assumptions about the continuity of the fMRI signal. Here, we propose a novel framework, which estimates a high-resolution reference volume by using outlier-robust motion correction, and by utilizing Huber L2 regularization for intra-stack volumetric reconstruction of the motion-corrected fetal brain fMRI. We performed an extensive parameter study to investigate the effectiveness of motion estimation and present in this work benchmark metrics to quantify the effect of motion correction and regularised volumetric reconstruction approaches on functional connectivity computations. We demonstrate the proposed framework's ability to improve functional connectivity estimates, reproducibility and signal interpretability, which is clinically highly desirable for the establishment of prognostic noninvasive imaging biomarkers. The motion correction and volumetric reconstruction framework is made available as an open-source package of NiftyMIC.
CrossMoDA 2021 challenge: Benchmark of Cross-Modality Domain Adaptation techniques for Vestibular Schwnannoma and Cochlea Segmentation
Jan 08, 2022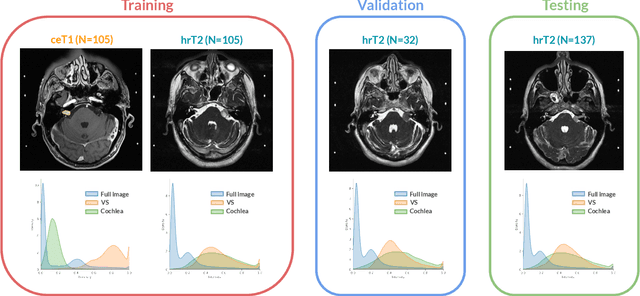
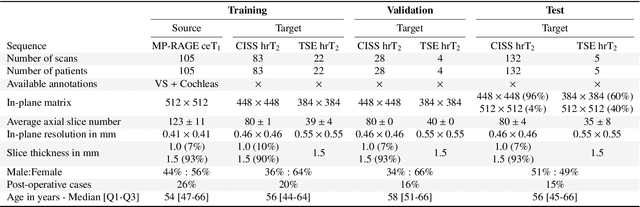
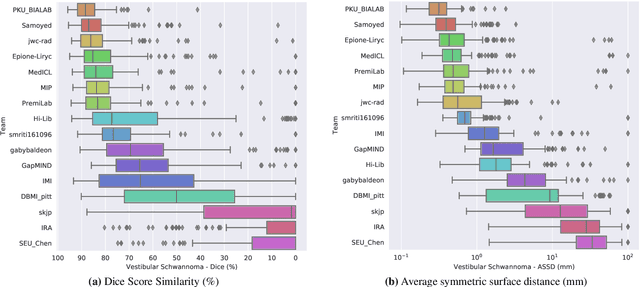
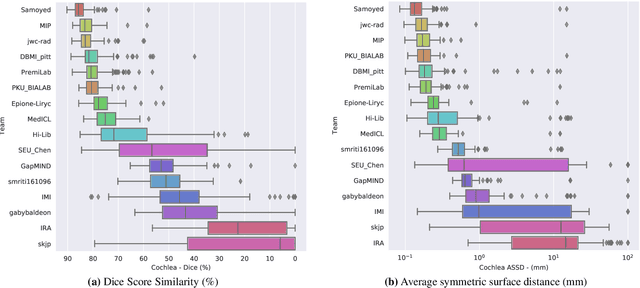
Domain Adaptation (DA) has recently raised strong interests in the medical imaging community. While a large variety of DA techniques has been proposed for image segmentation, most of these techniques have been validated either on private datasets or on small publicly available datasets. Moreover, these datasets mostly addressed single-class problems. To tackle these limitations, the Cross-Modality Domain Adaptation (crossMoDA) challenge was organised in conjunction with the 24th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2021). CrossMoDA is the first large and multi-class benchmark for unsupervised cross-modality DA. The challenge's goal is to segment two key brain structures involved in the follow-up and treatment planning of vestibular schwannoma (VS): the VS and the cochleas. Currently, the diagnosis and surveillance in patients with VS are performed using contrast-enhanced T1 (ceT1) MRI. However, there is growing interest in using non-contrast sequences such as high-resolution T2 (hrT2) MRI. Therefore, we created an unsupervised cross-modality segmentation benchmark. The training set provides annotated ceT1 (N=105) and unpaired non-annotated hrT2 (N=105). The aim was to automatically perform unilateral VS and bilateral cochlea segmentation on hrT2 as provided in the testing set (N=137). A total of 16 teams submitted their algorithm for the evaluation phase. The level of performance reached by the top-performing teams is strikingly high (best median Dice - VS:88.4%; Cochleas:85.7%) and close to full supervision (median Dice - VS:92.5%; Cochleas:87.7%). All top-performing methods made use of an image-to-image translation approach to transform the source-domain images into pseudo-target-domain images. A segmentation network was then trained using these generated images and the manual annotations provided for the source image.
Equitable modelling of brain imaging by counterfactual augmentation with morphologically constrained 3D deep generative models
Nov 29, 2021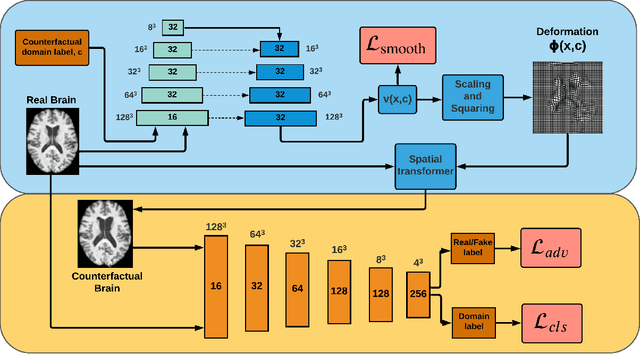

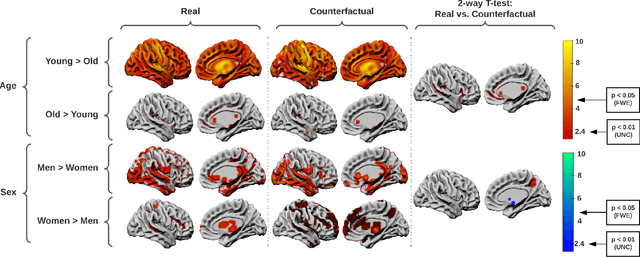
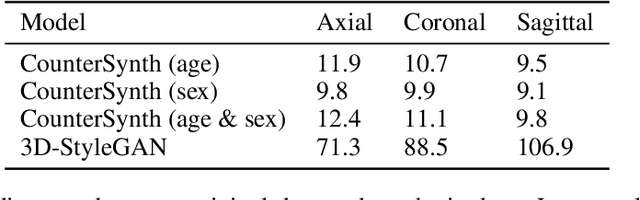
We describe Countersynth, a conditional generative model of diffeomorphic deformations that induce label-driven, biologically plausible changes in volumetric brain images. The model is intended to synthesise counterfactual training data augmentations for downstream discriminative modelling tasks where fidelity is limited by data imbalance, distributional instability, confounding, or underspecification, and exhibits inequitable performance across distinct subpopulations. Focusing on demographic attributes, we evaluate the quality of synthesized counterfactuals with voxel-based morphometry, classification and regression of the conditioning attributes, and the Fr\'{e}chet inception distance. Examining downstream discriminative performance in the context of engineered demographic imbalance and confounding, we use UK Biobank magnetic resonance imaging data to benchmark CounterSynth augmentation against current solutions to these problems. We achieve state-of-the-art improvements, both in overall fidelity and equity. The source code for CounterSynth is available online.
Acquisition-invariant brain MRI segmentation with informative uncertainties
Nov 07, 2021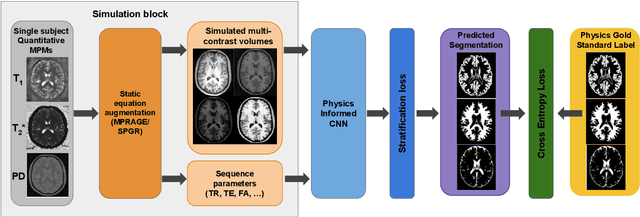
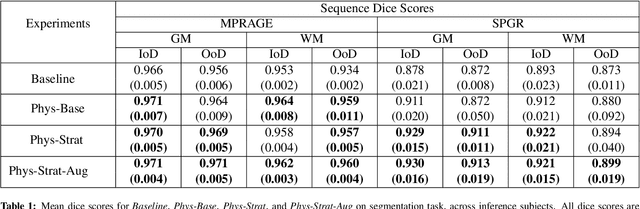
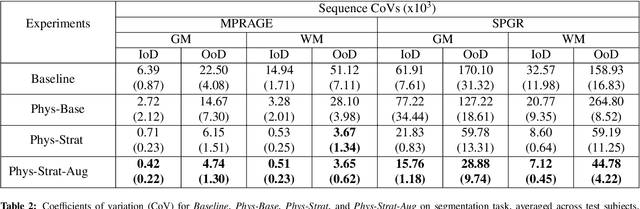
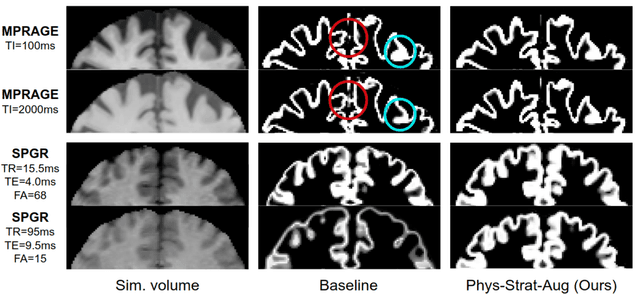
Combining multi-site data can strengthen and uncover trends, but is a task that is marred by the influence of site-specific covariates that can bias the data and therefore any downstream analyses. Post-hoc multi-site correction methods exist but have strong assumptions that often do not hold in real-world scenarios. Algorithms should be designed in a way that can account for site-specific effects, such as those that arise from sequence parameter choices, and in instances where generalisation fails, should be able to identify such a failure by means of explicit uncertainty modelling. This body of work showcases such an algorithm, that can become robust to the physics of acquisition in the context of segmentation tasks, while simultaneously modelling uncertainty. We demonstrate that our method not only generalises to complete holdout datasets, preserving segmentation quality, but does so while also accounting for site-specific sequence choices, which also allows it to perform as a harmonisation tool.
The role of MRI physics in brain segmentation CNNs: achieving acquisition invariance and instructive uncertainties
Nov 04, 2021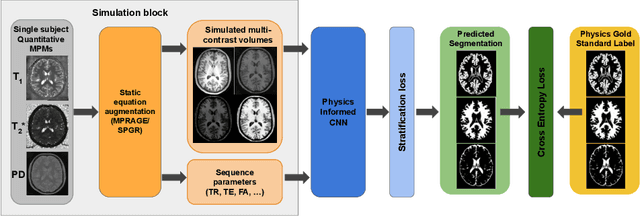
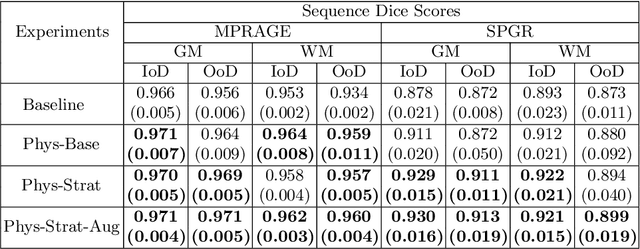
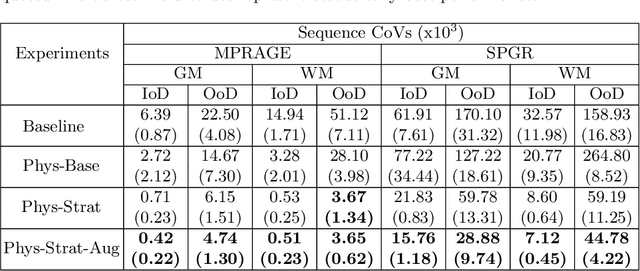
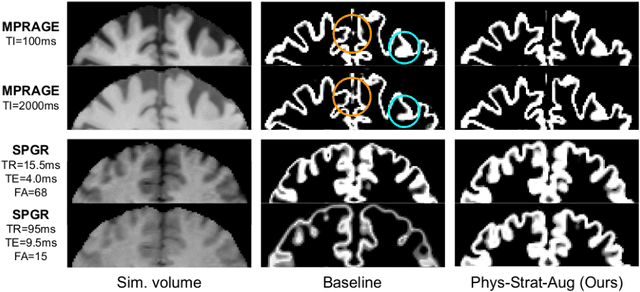
Being able to adequately process and combine data arising from different sites is crucial in neuroimaging, but is difficult, owing to site, sequence and acquisition-parameter dependent biases. It is important therefore to design algorithms that are not only robust to images of differing contrasts, but also be able to generalise well to unseen ones, with a quantifiable measure of uncertainty. In this paper we demonstrate the efficacy of a physics-informed, uncertainty-aware, segmentation network that employs augmentation-time MR simulations and homogeneous batch feature stratification to achieve acquisition invariance. We show that the proposed approach also accurately extrapolates to out-of-distribution sequence samples, providing well calibrated volumetric bounds on these. We demonstrate a significant improvement in terms of coefficients of variation, backed by uncertainty based volumetric validation.
Deep forecasting of translational impact in medical research
Oct 17, 2021
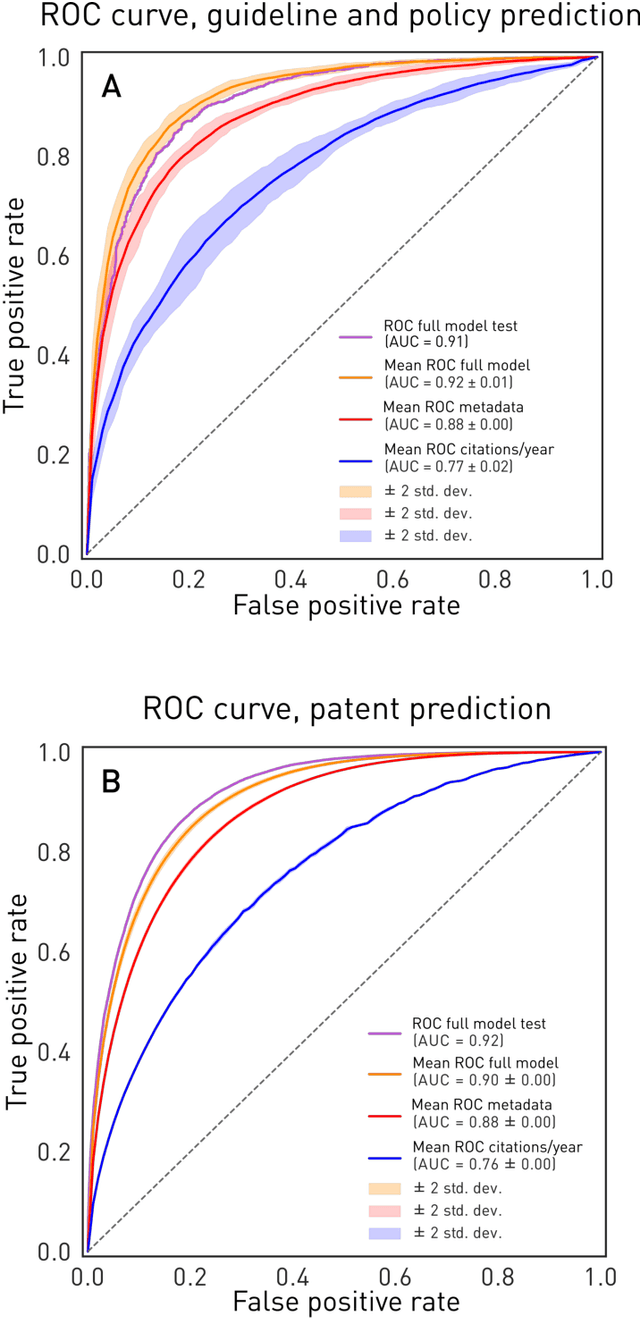
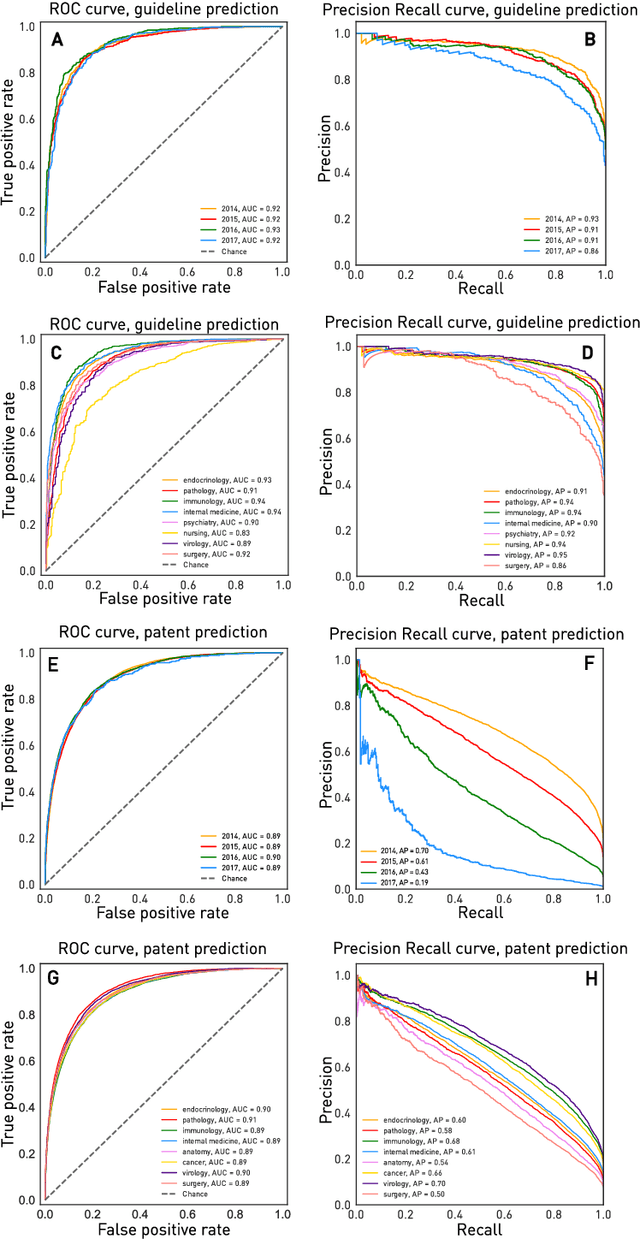
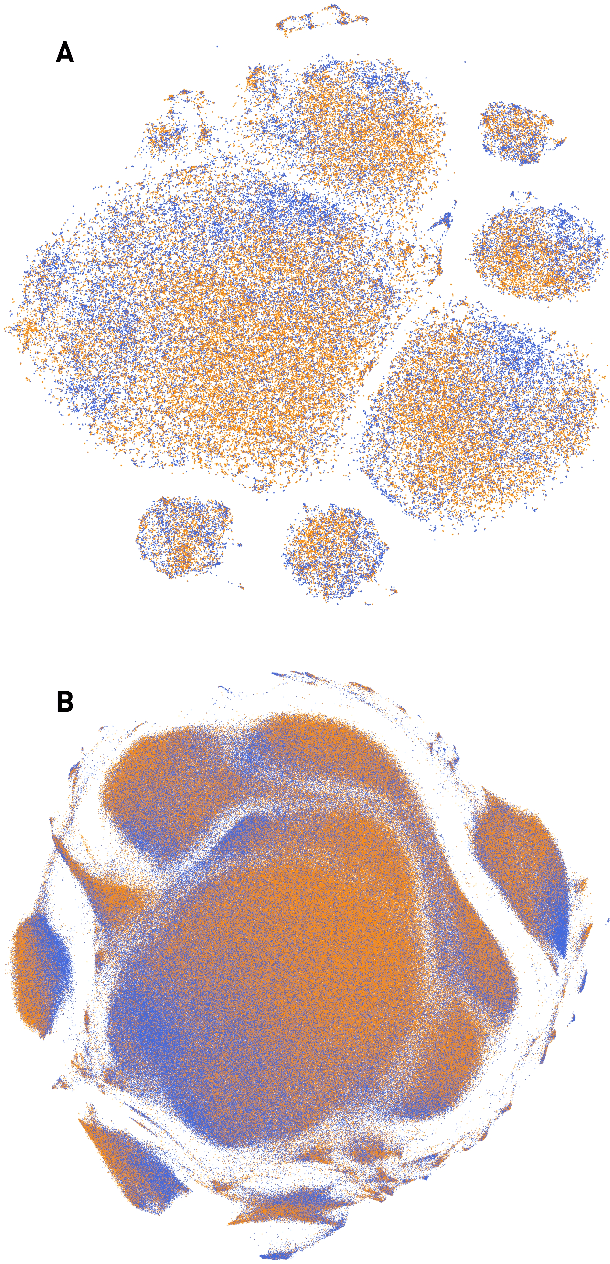
The value of biomedical research--a $1.7 trillion annual investment--is ultimately determined by its downstream, real-world impact. Current objective predictors of impact rest on proxy, reductive metrics of dissemination, such as paper citation rates, whose relation to real-world translation remains unquantified. Here we sought to determine the comparative predictability of future real-world translation--as indexed by inclusion in patents, guidelines or policy documents--from complex models of the abstract-level content of biomedical publications versus citations and publication meta-data alone. We develop a suite of representational and discriminative mathematical models of multi-scale publication data, quantifying predictive performance out-of-sample, ahead-of-time, across major biomedical domains, using the entire corpus of biomedical research captured by Microsoft Academic Graph from 1990 to 2019, encompassing 43.3 million papers across all domains. We show that citations are only moderately predictive of translational impact as judged by inclusion in patents, guidelines, or policy documents. By contrast, high-dimensional models of publication titles, abstracts and metadata exhibit high fidelity (AUROC > 0.9), generalise across time and thematic domain, and transfer to the task of recognising papers of Nobel Laureates. The translational impact of a paper indexed by inclusion in patents, guidelines, or policy documents can be predicted--out-of-sample and ahead-of-time--with substantially higher fidelity from complex models of its abstract-level content than from models of publication meta-data or citation metrics. We argue that content-based models of impact are superior in performance to conventional, citation-based measures, and sustain a stronger evidence-based claim to the objective measurement of translational potential.
A Decoupled Uncertainty Model for MRI Segmentation Quality Estimation
Sep 06, 2021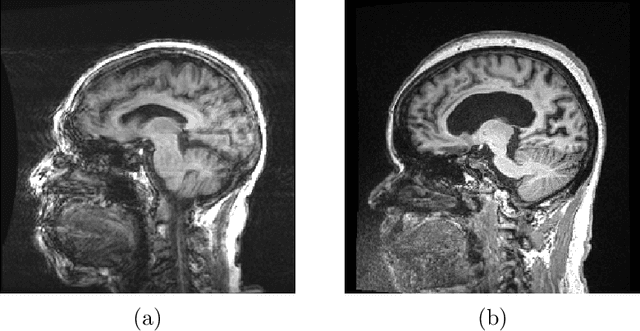
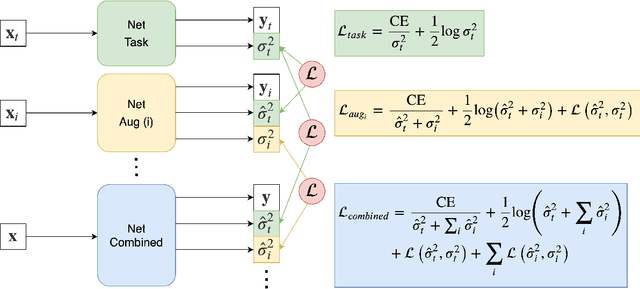
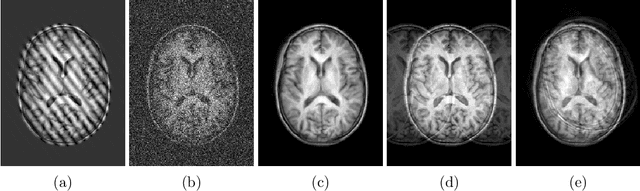
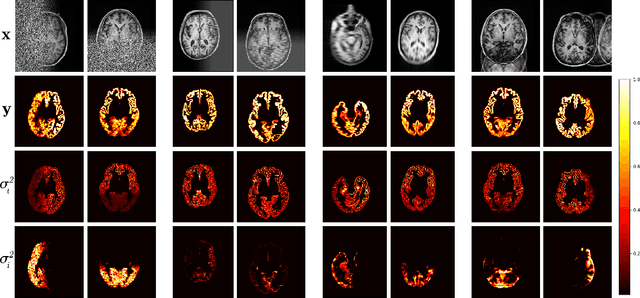
Quality control (QC) of MR images is essential to ensure that downstream analyses such as segmentation can be performed successfully. Currently, QC is predominantly performed visually and subjectively, at significant time and operator cost. We aim to automate the process using a probabilistic network that estimates segmentation uncertainty through a heteroscedastic noise model, providing a measure of task-specific quality. By augmenting training images with k-space artefacts, we propose a novel CNN architecture to decouple sources of uncertainty related to the task and different k-space artefacts in a self-supervised manner. This enables the prediction of separate uncertainties for different types of data degradation. While the uncertainty predictions reflect the presence and severity of artefacts, the network provides more robust and generalisable segmentation predictions given the quality of the data. We show that models trained with artefact augmentation provide informative measures of uncertainty on both simulated artefacts and problematic real-world images identified by human raters, both qualitatively and quantitatively in the form of error bars on volume measurements. Relating artefact uncertainty to segmentation Dice scores, we observe that our uncertainty predictions provide a better estimate of MRI quality from the point of view of the task (gray matter segmentation) compared to commonly used metrics of quality including signal-to-noise ratio (SNR) and contrast-to-noise ratio (CNR), hence providing a real-time quality metric indicative of segmentation quality.
Deep Learning Approach for Hyperspectral Image Demosaicking, Spectral Correction and High-resolution RGB Reconstruction
Sep 03, 2021

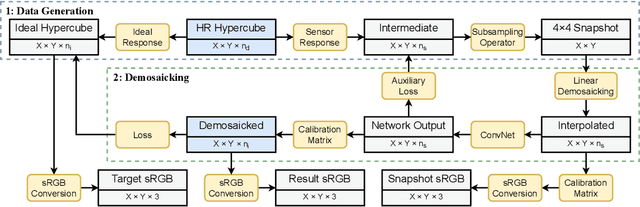
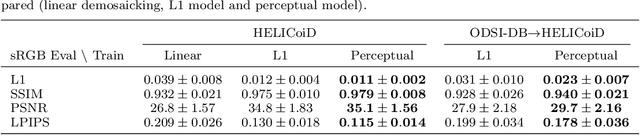
Hyperspectral imaging is one of the most promising techniques for intraoperative tissue characterisation. Snapshot mosaic cameras, which can capture hyperspectral data in a single exposure, have the potential to make a real-time hyperspectral imaging system for surgical decision-making possible. However, optimal exploitation of the captured data requires solving an ill-posed demosaicking problem and applying additional spectral corrections to recover spatial and spectral information of the image. In this work, we propose a deep learning-based image demosaicking algorithm for snapshot hyperspectral images using supervised learning methods. Due to the lack of publicly available medical images acquired with snapshot mosaic cameras, a synthetic image generation approach is proposed to simulate snapshot images from existing medical image datasets captured by high-resolution, but slow, hyperspectral imaging devices. Image reconstruction is achieved using convolutional neural networks for hyperspectral image super-resolution, followed by cross-talk and leakage correction using a sensor-specific calibration matrix. The resulting demosaicked images are evaluated both quantitatively and qualitatively, showing clear improvements in image quality compared to a baseline demosaicking method using linear interpolation. Moreover, the fast processing time of~45\,ms of our algorithm to obtain super-resolved RGB or oxygenation saturation maps per image frame for a state-of-the-art snapshot mosaic camera demonstrates the potential for its seamless integration into real-time surgical hyperspectral imaging applications.