 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Structure Matters Most in Most Languages
Nov 09, 2022



Many recent perturbation studies have found unintuitive results on what does and does not matter when performing Natural Language Understanding (NLU) tasks in English. Coding properties, such as the order of words, can often be removed through shuffling without impacting downstream performances. Such insight may be used to direct future research into English NLP models. As many improvements in multilingual settings consist of wholesale adaptation of English approaches, it is important to verify whether those studies replicate or not in multilingual settings. In this work, we replicate a study on the importance of local structure, and the relative unimportance of global structure, in a multilingual setting. We find that the phenomenon observed on the English language broadly translates to over 120 languages, with a few caveats.
Detecting Languages Unintelligible to Multilingual Models through Local Structure Probes
Nov 09, 2022



Providing better language tools for low-resource and endangered languages is imperative for equitable growth. Recent progress with massively multilingual pretrained models has proven surprisingly effective at performing zero-shot transfer to a wide variety of languages. However, this transfer is not universal, with many languages not currently understood by multilingual approaches. It is estimated that only 72 languages possess a "small set of labeled datasets" on which we could test a model's performance, the vast majority of languages not having the resources available to simply evaluate performances on. In this work, we attempt to clarify which languages do and do not currently benefit from such transfer. To that end, we develop a general approach that requires only unlabelled text to detect which languages are not well understood by a cross-lingual model. Our approach is derived from the hypothesis that if a model's understanding is insensitive to perturbations to text in a language, it is likely to have a limited understanding of that language. We construct a cross-lingual sentence similarity task to evaluate our approach empirically on 350, primarily low-resource, languages.
Segmentation of Multiple Sclerosis Lesions across Hospitals: Learn Continually or Train from Scratch?
Oct 27, 2022



Segmentation of Multiple Sclerosis (MS) lesions is a challenging problem. Several deep-learning-based methods have been proposed in recent years. However, most methods tend to be static, that is, a single model trained on a large, specialized dataset, which does not generalize well. Instead, the model should learn across datasets arriving sequentially from different hospitals by building upon the characteristics of lesions in a continual manner. In this regard, we explore experience replay, a well-known continual learning method, in the context of MS lesion segmentation across multi-contrast data from 8 different hospitals. Our experiments show that replay is able to achieve positive backward transfer and reduce catastrophic forgetting compared to sequential fine-tuning. Furthermore, replay outperforms the multi-domain training, thereby emerging as a promising solution for the segmentation of MS lesions. The code is available at this link: https://github.com/naga-karthik/continual-learning-ms
Improving Meta-Learning Generalization with Activation-Based Early-Stopping
Aug 03, 2022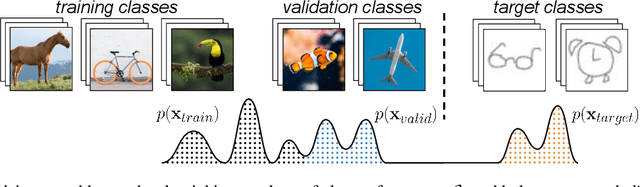

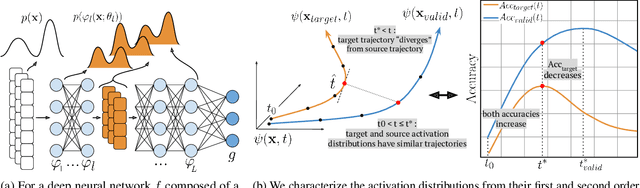
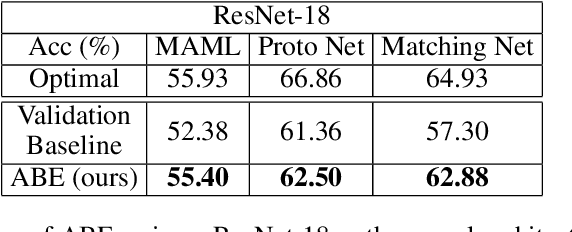
Meta-Learning algorithms for few-shot learning aim to train neural networks capable of generalizing to novel tasks using only a few examples. Early-stopping is critical for performance, halting model training when it reaches optimal generalization to the new task distribution. Early-stopping mechanisms in Meta-Learning typically rely on measuring the model performance on labeled examples from a meta-validation set drawn from the training (source) dataset. This is problematic in few-shot transfer learning settings, where the meta-test set comes from a different target dataset (OOD) and can potentially have a large distributional shift with the meta-validation set. In this work, we propose Activation Based Early-stopping (ABE), an alternative to using validation-based early-stopping for meta-learning. Specifically, we analyze the evolution, during meta-training, of the neural activations at each hidden layer, on a small set of unlabelled support examples from a single task of the target tasks distribution, as this constitutes a minimal and justifiably accessible information from the target problem. Our experiments show that simple, label agnostic statistics on the activations offer an effective way to estimate how the target generalization evolves over time. At each hidden layer, we characterize the activation distributions, from their first and second order moments, then further summarized along the feature dimensions, resulting in a compact yet intuitive characterization in a four-dimensional space. Detecting when, throughout training time, and at which layer, the target activation trajectory diverges from the activation trajectory of the source data, allows us to perform early-stopping and improve generalization in a large array of few-shot transfer learning settings, across different algorithms, source and target datasets.
An Introduction to Lifelong Supervised Learning
Jul 12, 2022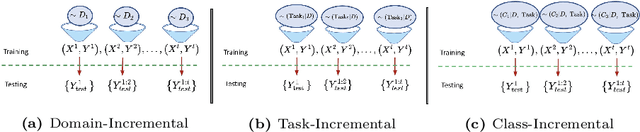
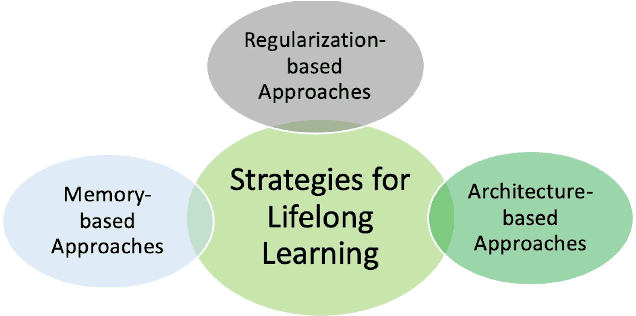
This primer is an attempt to provide a detailed summary of the different facets of lifelong learning. We start with Chapter 2 which provides a high-level overview of lifelong learning systems. In this chapter, we discuss prominent scenarios in lifelong learning (Section 2.4), provide 8 Introduction a high-level organization of different lifelong learning approaches (Section 2.5), enumerate the desiderata for an ideal lifelong learning system (Section 2.6), discuss how lifelong learning is related to other learning paradigms (Section 2.7), describe common metrics used to evaluate lifelong learning systems (Section 2.8). This chapter is more useful for readers who are new to lifelong learning and want to get introduced to the field without focusing on specific approaches or benchmarks. The remaining chapters focus on specific aspects (either learning algorithms or benchmarks) and are more useful for readers who are looking for specific approaches or benchmarks. Chapter 3 focuses on regularization-based approaches that do not assume access to any data from previous tasks. Chapter 4 discusses memory-based approaches that typically use a replay buffer or an episodic memory to save subset of data across different tasks. Chapter 5 focuses on different architecture families (and their instantiations) that have been proposed for training lifelong learning systems. Following these different classes of learning algorithms, we discuss the commonly used evaluation benchmarks and metrics for lifelong learning (Chapter 6) and wrap up with a discussion of future challenges and important research directions in Chapter 7.
Towards Evaluating Adaptivity of Model-Based Reinforcement Learning Methods
Apr 25, 2022

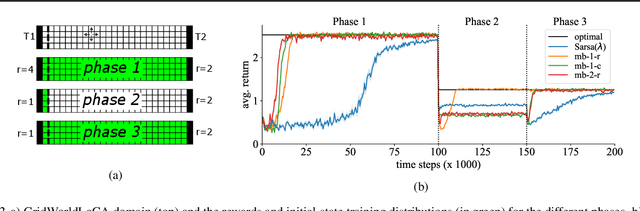
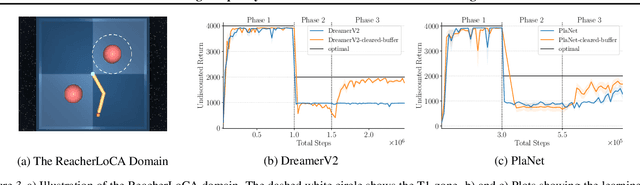
In recent years, a growing number of deep model-based reinforcement learning (RL) methods have been introduced. The interest in deep model-based RL is not surprising, given its many potential benefits, such as higher sample efficiency and the potential for fast adaption to changes in the environment. However, we demonstrate, using an improved version of the recently introduced Local Change Adaptation (LoCA) setup, that well-known model-based methods such as PlaNet and DreamerV2 perform poorly in their ability to adapt to local environmental changes. Combined with prior work that made a similar observation about the other popular model-based method, MuZero, a trend appears to emerge, suggesting that current deep model-based methods have serious limitations. We dive deeper into the causes of this poor performance, by identifying elements that hurt adaptive behavior and linking these to underlying techniques frequently used in deep model-based RL. We empirically validate these insights in the case of linear function approximation by demonstrating that a modified version of linear Dyna achieves effective adaptation to local changes. Furthermore, we provide detailed insights into the challenges of building an adaptive nonlinear model-based method, by experimenting with a nonlinear version of Dyna.
Improving Sample Efficiency of Value Based Models Using Attention and Vision Transformers
Feb 01, 2022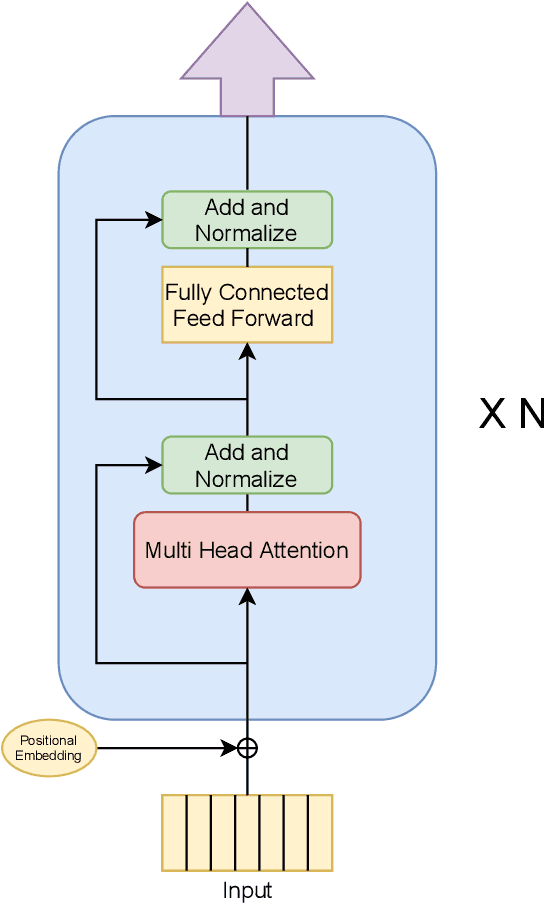
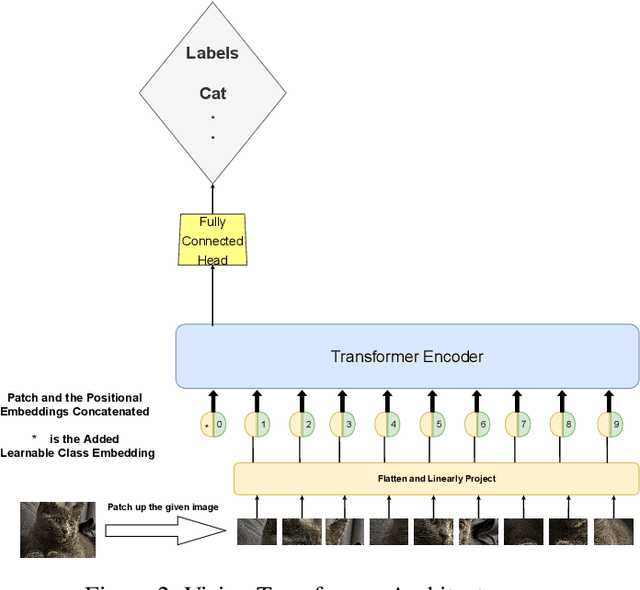
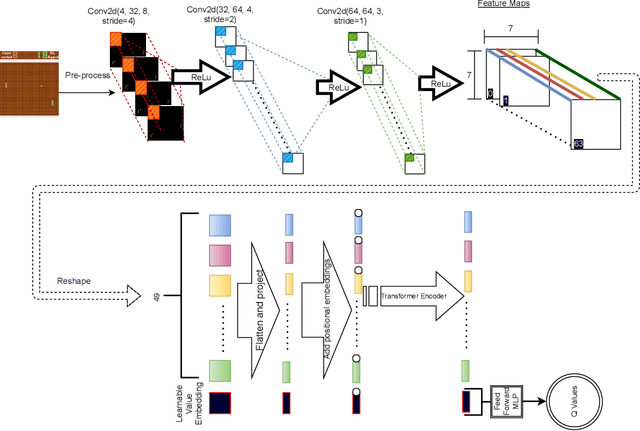
Much of recent Deep Reinforcement Learning success is owed to the neural architecture's potential to learn and use effective internal representations of the world. While many current algorithms access a simulator to train with a large amount of data, in realistic settings, including while playing games that may be played against people, collecting experience can be quite costly. In this paper, we introduce a deep reinforcement learning architecture whose purpose is to increase sample efficiency without sacrificing performance. We design this architecture by incorporating advances achieved in recent years in the field of Natural Language Processing and Computer Vision. Specifically, we propose a visually attentive model that uses transformers to learn a self-attention mechanism on the feature maps of the state representation, while simultaneously optimizing return. We demonstrate empirically that this architecture improves sample complexity for several Atari environments, while also achieving better performance in some of the games.
An Empirical Investigation of the Role of Pre-training in Lifelong Learning
Dec 16, 2021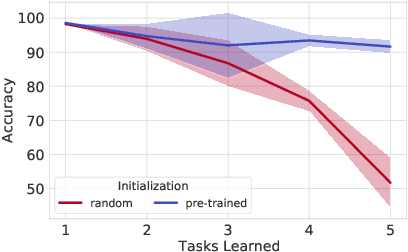
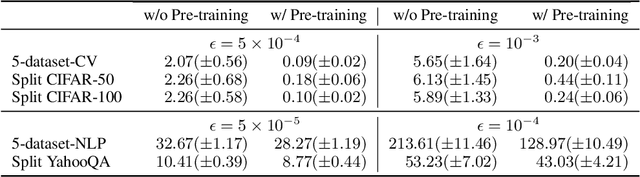
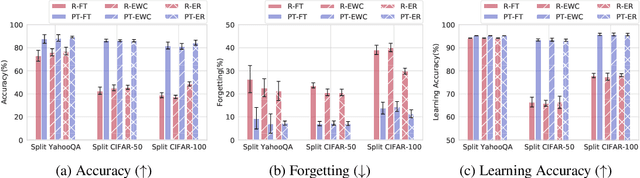
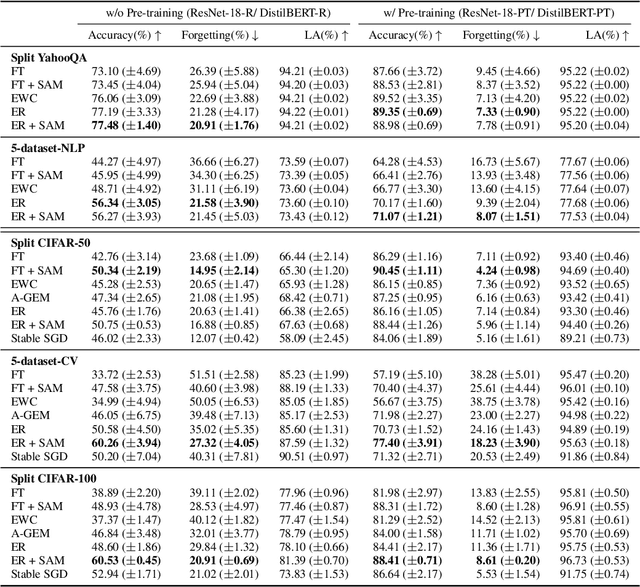
The lifelong learning paradigm in machine learning is an attractive alternative to the more prominent isolated learning scheme not only due to its resemblance to biological learning, but also its potential to reduce energy waste by obviating excessive model re-training. A key challenge to this paradigm is the phenomenon of catastrophic forgetting. With the increasing popularity and success of pre-trained models in machine learning, we pose the question: What role does pre-training play in lifelong learning, specifically with respect to catastrophic forgetting? We investigate existing methods in the context of large, pre-trained models and evaluate their performance on a variety of text and image classification tasks, including a large-scale study using a novel dataset of 15 diverse NLP tasks. Across all settings, we observe that generic pre-training implicitly alleviates the effects of catastrophic forgetting when learning multiple tasks sequentially compared to randomly initialized models. We then further investigate why pre-training alleviates forgetting in this setting. We study this phenomenon by analyzing the loss landscape, finding that pre-trained weights appear to ease forgetting by leading to wider minima. Based on this insight, we propose jointly optimizing for current task loss and loss basin sharpness in order to explicitly encourage wider basins during sequential fine-tuning. We show that this optimization approach leads to performance comparable to the state-of-the-art in task-sequential continual learning across multiple settings, without retaining a memory that scales in size with the number of tasks.
Scaling Laws for the Few-Shot Adaptation of Pre-trained Image Classifiers
Oct 18, 2021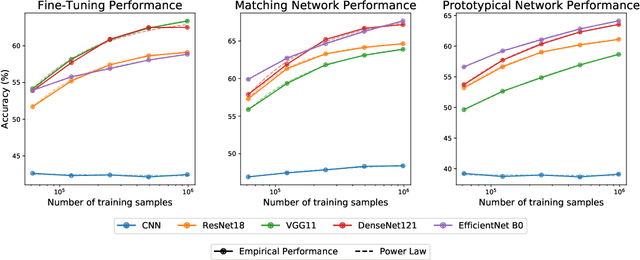

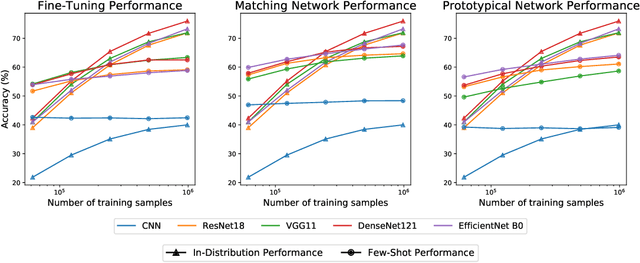
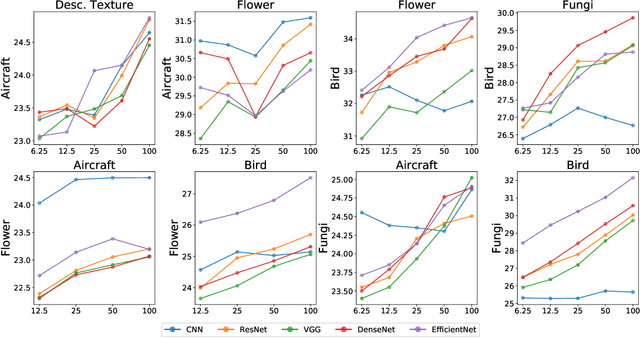
Empirical science of neural scaling laws is a rapidly growing area of significant importance to the future of machine learning, particularly in the light of recent breakthroughs achieved by large-scale pre-trained models such as GPT-3, CLIP and DALL-e. Accurately predicting the neural network performance with increasing resources such as data, compute and model size provides a more comprehensive evaluation of different approaches across multiple scales, as opposed to traditional point-wise comparisons of fixed-size models on fixed-size benchmarks, and, most importantly, allows for focus on the best-scaling, and thus most promising in the future, approaches. In this work, we consider a challenging problem of few-shot learning in image classification, especially when the target data distribution in the few-shot phase is different from the source, training, data distribution, in a sense that it includes new image classes not encountered during training. Our current main goal is to investigate how the amount of pre-training data affects the few-shot generalization performance of standard image classifiers. Our key observations are that (1) such performance improvements are well-approximated by power laws (linear log-log plots) as the training set size increases, (2) this applies to both cases of target data coming from either the same or from a different domain (i.e., new classes) as the training data, and (3) few-shot performance on new classes converges at a faster rate than the standard classification performance on previously seen classes. Our findings shed new light on the relationship between scale and generalization.
Post-hoc Interpretability for Neural NLP: A Survey
Aug 13, 2021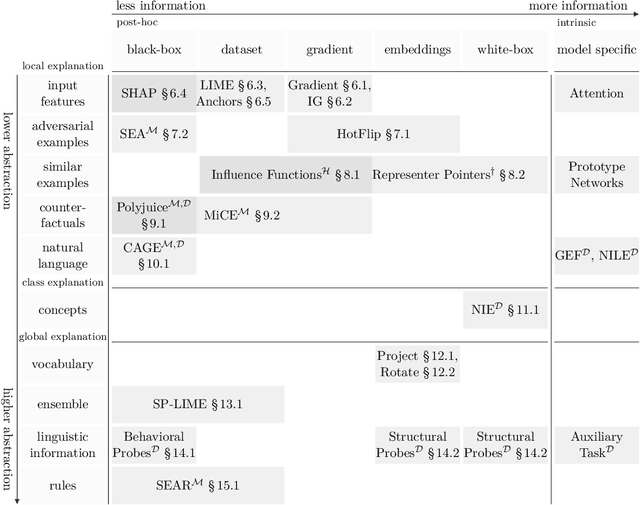



Natural Language Processing (NLP) models have become increasingly more complex and widespread. With recent developments in neural networks, a growing concern is whether it is responsible to use these models. Concerns such as safety and ethics can be partially addressed by providing explanations. Furthermore, when models do fail, providing explanations is paramount for accountability purposes. To this end, interpretability serves to provide these explanations in terms that are understandable to humans. Central to what is understandable is how explanations are communicated. Therefore, this survey provides a categorization of how recent interpretability methods communicate explanations and discusses the methods in depth. Furthermore, the survey focuses on post-hoc methods, which provide explanations after a model is learned and generally model-agnostic. A common concern for this class of methods is whether they accurately reflect the model. Hence, how these post-hoc methods are evaluated is discussed throughout the paper.