 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Introduction to Lifelong Supervised Learning
Jul 12, 2022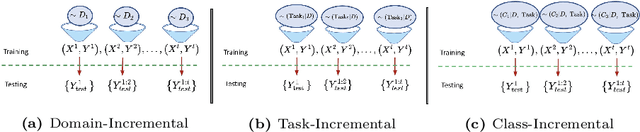
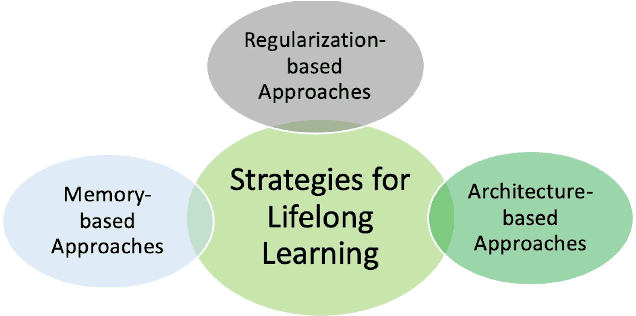
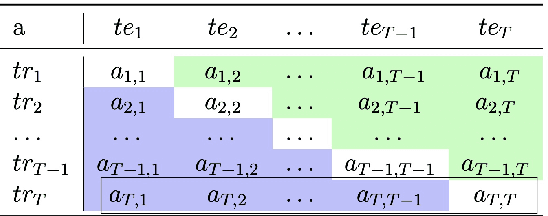
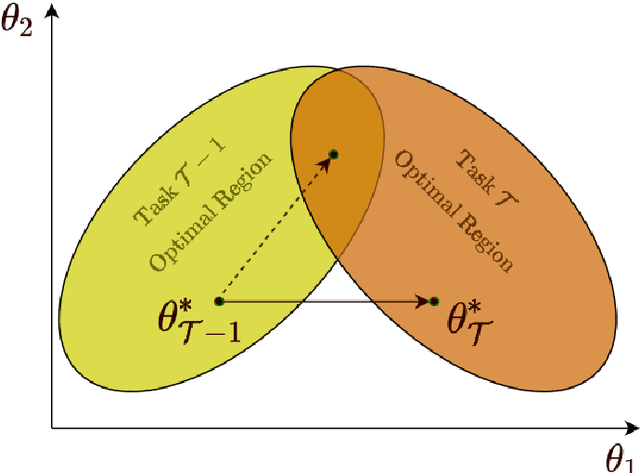
This primer is an attempt to provide a detailed summary of the different facets of lifelong learning. We start with Chapter 2 which provides a high-level overview of lifelong learning systems. In this chapter, we discuss prominent scenarios in lifelong learning (Section 2.4), provide 8 Introduction a high-level organization of different lifelong learning approaches (Section 2.5), enumerate the desiderata for an ideal lifelong learning system (Section 2.6), discuss how lifelong learning is related to other learning paradigms (Section 2.7), describe common metrics used to evaluate lifelong learning systems (Section 2.8). This chapter is more useful for readers who are new to lifelong learning and want to get introduced to the field without focusing on specific approaches or benchmarks. The remaining chapters focus on specific aspects (either learning algorithms or benchmarks) and are more useful for readers who are looking for specific approaches or benchmarks. Chapter 3 focuses on regularization-based approaches that do not assume access to any data from previous tasks. Chapter 4 discusses memory-based approaches that typically use a replay buffer or an episodic memory to save subset of data across different tasks. Chapter 5 focuses on different architecture families (and their instantiations) that have been proposed for training lifelong learning systems. Following these different classes of learning algorithms, we discuss the commonly used evaluation benchmarks and metrics for lifelong learning (Chapter 6) and wrap up with a discussion of future challenges and important research directions in Chapter 7.
3D Adapted Random Forest Vision (3DARFV) for Untangling Heterogeneous-Fabric Exceeding Deep Learning Semantic Segmentation Efficiency at the Utmost Accuracy
Mar 23, 2022


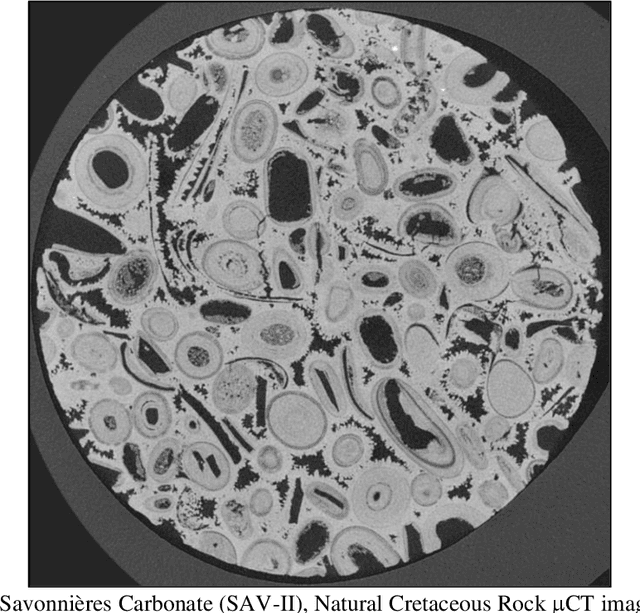
Planetary exploration depends heavily on 3D image data to characterize the static and dynamic properties of the rock and environment. Analyzing 3D images requires many computations, causing efficiency to suffer lengthy processing time alongside large energy consumption. High-Performance Computing (HPC) provides apparent efficiency at the expense of energy consumption. However, for remote explorations, the conveyed surveillance and the robotized sensing need faster data analysis with ultimate accuracy to make real-time decisions. In such environments, access to HPC and energy is limited. Therefore, we realize that reducing the number of computations to optimal and maintaining the desired accuracy leads to higher efficiency. This paper demonstrates the semantic segmentation capability of a probabilistic decision tree algorithm, 3D Adapted Random Forest Vision (3DARFV), exceeding deep learning algorithm efficiency at the utmost accuracy.
A Brief Study on the Effects of Training Generative Dialogue Models with a Semantic loss
Jun 20, 2021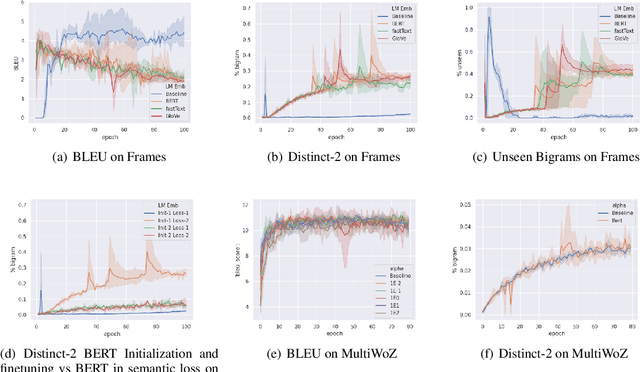
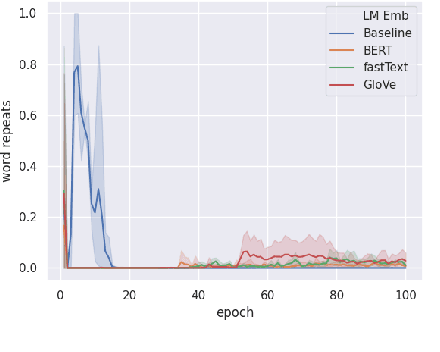

Neural models trained for next utterance generation in dialogue task learn to mimic the n-gram sequences in the training set with training objectives like negative log-likelihood (NLL) or cross-entropy. Such commonly used training objectives do not foster generating alternate responses to a context. But, the effects of minimizing an alternate training objective that fosters a model to generate alternate response and score it on semantic similarity has not been well studied. We hypothesize that a language generation model can improve on its diversity by learning to generate alternate text during training and minimizing a semantic loss as an auxiliary objective. We explore this idea on two different sized data sets on the task of next utterance generation in goal oriented dialogues. We make two observations (1) minimizing a semantic objective improved diversity in responses in the smaller data set (Frames) but only as-good-as minimizing the NLL in the larger data set (MultiWoZ) (2) large language model embeddings can be more useful as a semantic loss objective than as initialization for token embeddings.
IIRC: Incremental Implicitly-Refined Classification
Jan 11, 2021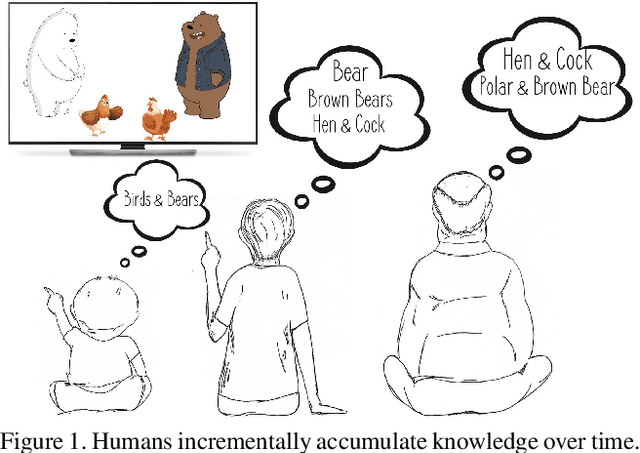

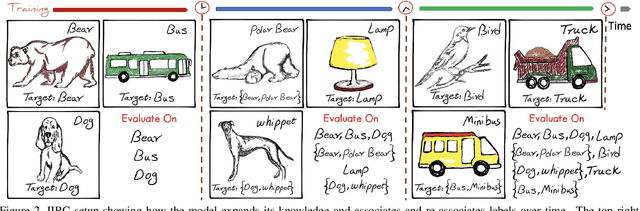

We introduce the "Incremental Implicitly-Refined Classi-fication (IIRC)" setup, an extension to the class incremental learning setup where the incoming batches of classes have two granularity levels. i.e., each sample could have a high-level (coarse) label like "bear" and a low-level (fine) label like "polar bear". Only one label is provided at a time, and the model has to figure out the other label if it has already learnfed it. This setup is more aligned with real-life scenarios, where a learner usually interacts with the same family of entities multiple times, discovers more granularity about them, while still trying not to forget previous knowledge. Moreover, this setup enables evaluating models for some important lifelong learning challenges that cannot be easily addressed under the existing setups. These challenges can be motivated by the example "if a model was trained on the class bear in one task and on polar bear in another task, will it forget the concept of bear, will it rightfully infer that a polar bear is still a bear? and will it wrongfully associate the label of polar bear to other breeds of bear?". We develop a standardized benchmark that enables evaluating models on the IIRC setup. We evaluate several state-of-the-art lifelong learning algorithms and highlight their strengths and limitations. For example, distillation-based methods perform relatively well but are prone to incorrectly predicting too many labels per image. We hope that the proposed setup, along with the benchmark, would provide a meaningful problem setting to the practitioners