 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffect of Document Packing on the Latent Multi-Hop Reasoning Capabilities of Large Language Models
Dec 16, 2025



The standard practice for training large language models involves packing multiple documents together to optimize computational efficiency. However, the impact of this process on the models' capabilities remains largely unexplored. To address this gap, we investigate how different document-packing strategies influence the latent multi-hop reasoning abilities of LLMs. Our findings indicate that packing can improve model performance compared to training on individual documents, at the expense of more compute. To further understand the underlying mechanisms, we conduct an ablation study, identifying key factors that explain the advantages of packing. Ultimately, our research deepens the understanding of LLM training dynamics and provides practical insights for optimizing model development.
Do Large Language Models Know How Much They Know?
Feb 26, 2025Large Language Models (LLMs) have emerged as highly capable systems and are increasingly being integrated into various uses. However, the rapid pace of their deployment has outpaced a comprehensive understanding of their internal mechanisms and a delineation of their capabilities and limitations. A desired attribute of an intelligent system is its ability to recognize the scope of its own knowledge. To investigate whether LLMs embody this characteristic, we develop a benchmark designed to challenge these models to enumerate all information they possess on specific topics. This benchmark evaluates whether the models recall excessive, insufficient, or the precise amount of information, thereby indicating their awareness of their own knowledge. Our findings reveal that all tested LLMs, given sufficient scale, demonstrate an understanding of how much they know about specific topics. While different architectures exhibit varying rates of this capability's emergence, the results suggest that awareness of knowledge may be a generalizable attribute of LLMs. Further research is needed to confirm this potential and fully elucidate the underlying mechanisms.
EpiK-Eval: Evaluation for Language Models as Epistemic Models
Oct 23, 2023In the age of artificial intelligence, the role of large language models (LLMs) is becoming increasingly central. Despite their growing prevalence, their capacity to consolidate knowledge from different training documents - a crucial ability in numerous applications - remains unexplored. This paper presents the first study examining the capability of LLMs to effectively combine such information within their parameter space. We introduce EpiK-Eval, a novel question-answering benchmark tailored to evaluate LLMs' proficiency in formulating a coherent and consistent knowledge representation from segmented narratives. Evaluations across various LLMs reveal significant weaknesses in this domain. We contend that these shortcomings stem from the intrinsic nature of prevailing training objectives. Consequently, we advocate for refining the approach towards knowledge consolidation, as it harbors the potential to dramatically improve their overall effectiveness and performance. The findings from this study offer insights for developing more robust and reliable LLMs. Our code and benchmark are available at https://github.com/chandar-lab/EpiK-Eval
Scaling Laws for the Few-Shot Adaptation of Pre-trained Image Classifiers
Oct 18, 2021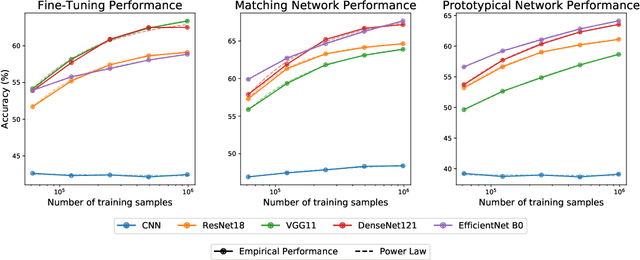

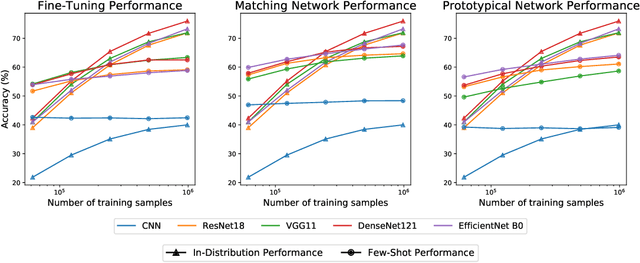
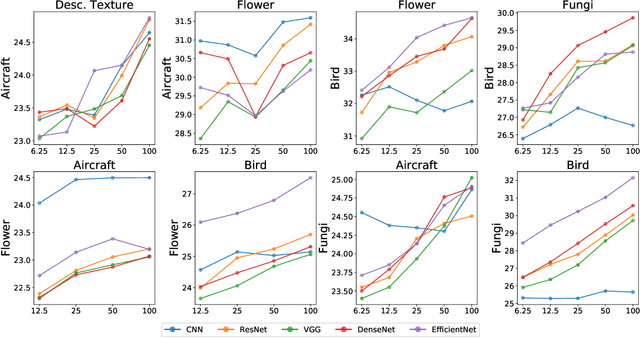
Empirical science of neural scaling laws is a rapidly growing area of significant importance to the future of machine learning, particularly in the light of recent breakthroughs achieved by large-scale pre-trained models such as GPT-3, CLIP and DALL-e. Accurately predicting the neural network performance with increasing resources such as data, compute and model size provides a more comprehensive evaluation of different approaches across multiple scales, as opposed to traditional point-wise comparisons of fixed-size models on fixed-size benchmarks, and, most importantly, allows for focus on the best-scaling, and thus most promising in the future, approaches. In this work, we consider a challenging problem of few-shot learning in image classification, especially when the target data distribution in the few-shot phase is different from the source, training, data distribution, in a sense that it includes new image classes not encountered during training. Our current main goal is to investigate how the amount of pre-training data affects the few-shot generalization performance of standard image classifiers. Our key observations are that (1) such performance improvements are well-approximated by power laws (linear log-log plots) as the training set size increases, (2) this applies to both cases of target data coming from either the same or from a different domain (i.e., new classes) as the training data, and (3) few-shot performance on new classes converges at a faster rate than the standard classification performance on previously seen classes. Our findings shed new light on the relationship between scale and generalization.
Fully Quantized Transformer for Improved Translation
Nov 23, 2019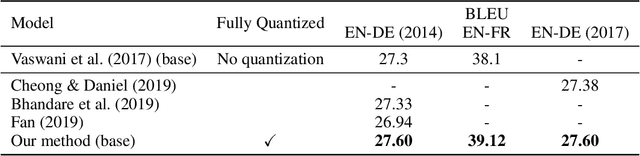
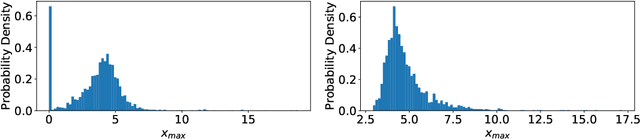
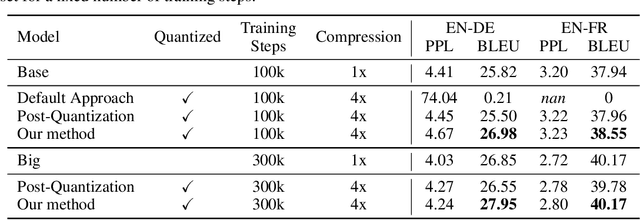
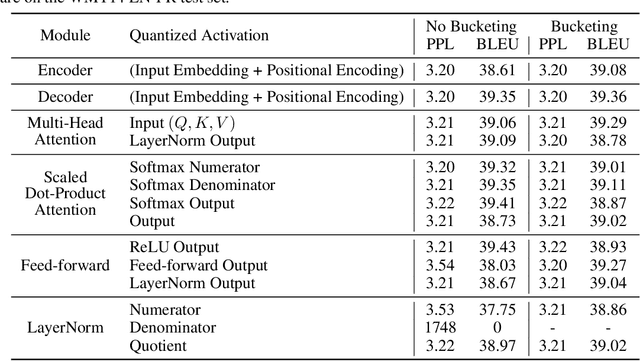
State-of-the-art neural machine translation methods employ massive amounts of parameters. Drastically reducing computational costs of such methods without affecting performance has been up to this point unsuccessful. To the best of our knowledge, we are the first to propose a quantization strategy inclusive of all components of the Transformer. We are also the first to show that it is possible to avoid any loss in translation quality with a fully quantized network. Indeed, our 8-bit models consistently score equal or higher BLEU than the full-precision variant on multiple translation datasets. Comparing ourselves to all previously proposed methods, we achieve state-of-the-art quantization results.
Towards Lossless Encoding of Sentences
Jun 04, 2019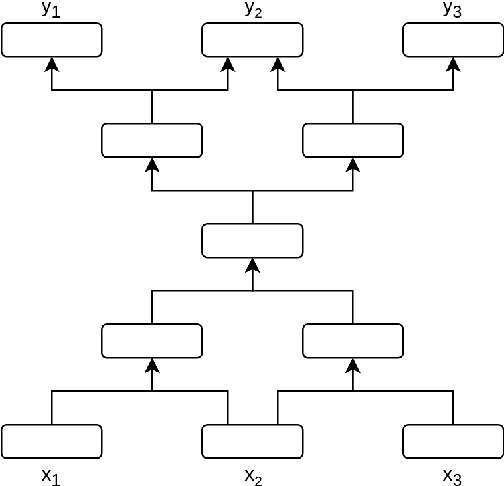
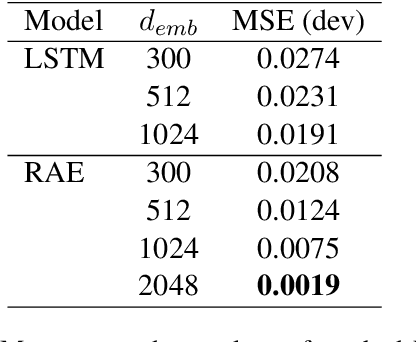
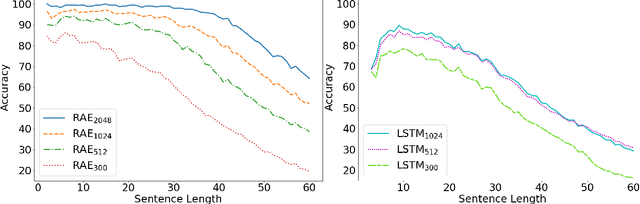
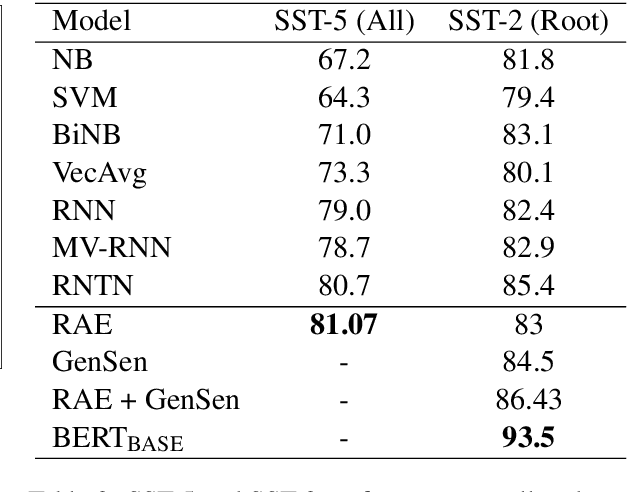
A lot of work has been done in the field of image compression via machine learning, but not much attention has been given to the compression of natural language. Compressing text into lossless representations while making features easily retrievable is not a trivial task, yet has huge benefits. Most methods designed to produce feature rich sentence embeddings focus solely on performing well on downstream tasks and are unable to properly reconstruct the original sequence from the learned embedding. In this work, we propose a near lossless method for encoding long sequences of texts as well as all of their sub-sequences into feature rich representations. We test our method on sentiment analysis and show good performance across all sub-sentence and sentence embeddings.