 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBypass Temporal Classification: Weakly Supervised Automatic Speech Recognition with Imperfect Transcripts
Jun 01, 2023



This paper presents a novel algorithm for building an automatic speech recognition (ASR) model with imperfect training data. Imperfectly transcribed speech is a prevalent issue in human-annotated speech corpora, which degrades the performance of ASR models. To address this problem, we propose Bypass Temporal Classification (BTC) as an expansion of the Connectionist Temporal Classification (CTC) criterion. BTC explicitly encodes the uncertainties associated with transcripts during training. This is accomplished by enhancing the flexibility of the training graph, which is implemented as a weighted finite-state transducer (WFST) composition. The proposed algorithm improves the robustness and accuracy of ASR systems, particularly when working with imprecisely transcribed speech corpora. Our implementation will be open-sourced.
MERLIon CCS Challenge Evaluation Plan
May 31, 2023



This paper introduces the inaugural Multilingual Everyday Recordings- Language Identification on Code-Switched Child-Directed Speech (MERLIon CCS) Challenge, focused on developing robust language identification and language diarization systems that are reliable for non-standard, accented, spontaneous code-switched, child-directed speech collected via Zoom. Aligning closely with Interspeech 2023 theme, the main objectives of this inaugural challenge are to present a unique first-of-its-kind Zoom videocall dataset featuring English-Mandarin spontaneous code-switched child-directed speech, benchmark the current and novel language identification and language diarization systems in a code-switching scenario including extremely short utterances, and test the robustness of such systems under accented speech. The MERLIon CCS challenge features two task: language identification (Task 1) and language diarization (Task 2). Two tracks, open and closed, are available for each task, differing by the volume of data systems can be trained on. This paper describes the dataset, dataset annotation protocol, challenge tasks, open and closed tracks, evaluation metrics, and evaluation protocol.
MERLIon CCS Challenge: A English-Mandarin code-switching child-directed speech corpus for language identification and diarization
May 30, 2023



To enhance the reliability and robustness of language identification (LID) and language diarization (LD) systems for heterogeneous populations and scenarios, there is a need for speech processing models to be trained on datasets that feature diverse language registers and speech patterns. We present the MERLIon CCS challenge, featuring a first-of-its-kind Zoom video call dataset of parent-child shared book reading, of over 30 hours with over 300 recordings, annotated by multilingual transcribers using a high-fidelity linguistic transcription protocol. The audio corpus features spontaneous and in-the-wild English-Mandarin code-switching, child-directed speech in non-standard accents with diverse language-mixing patterns recorded in a variety of home environments. This report describes the corpus, as well as LID and LD results for our baseline and several systems submitted to the MERLIon CCS challenge using the corpus.
Investigating model performance in language identification: beyond simple error statistics
May 30, 2023Language development experts need tools that can automatically identify languages from fluent, conversational speech, and provide reliable estimates of usage rates at the level of an individual recording. However, language identification systems are typically evaluated on metrics such as equal error rate and balanced accuracy, applied at the level of an entire speech corpus. These overview metrics do not provide information about model performance at the level of individual speakers, recordings, or units of speech with different linguistic characteristics. Overview statistics may therefore mask systematic errors in model performance for some subsets of the data, and consequently, have worse performance on data derived from some subsets of human speakers, creating a kind of algorithmic bias. In the current paper, we investigate how well a number of language identification systems perform on individual recordings and speech units with different linguistic properties in the MERLIon CCS Challenge. The Challenge dataset features accented English-Mandarin code-switched child-directed speech.
GPU-accelerated Guided Source Separation for Meeting Transcription
Dec 10, 2022Guided source separation (GSS) is a type of target-speaker extraction method that relies on pre-computed speaker activities and blind source separation to perform front-end enhancement of overlapped speech signals. It was first proposed during the CHiME-5 challenge and provided significant improvements over the delay-and-sum beamforming baseline. Despite its strengths, however, the method has seen limited adoption for meeting transcription benchmarks primarily due to its high computation time. In this paper, we describe our improved implementation of GSS that leverages the power of modern GPU-based pipelines, including batched processing of frequencies and segments, to provide 300x speed-up over CPU-based inference. The improved inference time allows us to perform detailed ablation studies over several parameters of the GSS algorithm -- such as context duration, number of channels, and noise class, to name a few. We provide end-to-end reproducible pipelines for speaker-attributed transcription of popular meeting benchmarks: LibriCSS, AMI, and AliMeeting. Our code and recipes are publicly available: https://github.com/desh2608/gss.
EURO: ESPnet Unsupervised ASR Open-source Toolkit
Dec 01, 2022



This paper describes the ESPnet Unsupervised ASR Open-source Toolkit (EURO), an end-to-end open-source toolkit for unsupervised automatic speech recognition (UASR). EURO adopts the state-of-the-art UASR learning method introduced by the Wav2vec-U, originally implemented at FAIRSEQ, which leverages self-supervised speech representations and adversarial training. In addition to wav2vec2, EURO extends the functionality and promotes reproducibility for UASR tasks by integrating S3PRL and k2, resulting in flexible frontends from 27 self-supervised models and various graph-based decoding strategies. EURO is implemented in ESPnet and follows its unified pipeline to provide UASR recipes with a complete setup. This improves the pipeline's efficiency and allows EURO to be easily applied to existing datasets in ESPnet. Extensive experiments on three mainstream self-supervised models demonstrate the toolkit's effectiveness and achieve state-of-the-art UASR performance on TIMIT and LibriSpeech datasets. EURO will be publicly available at https://github.com/espnet/espnet, aiming to promote this exciting and emerging research area based on UASR through open-source activity.
Adapting self-supervised models to multi-talker speech recognition using speaker embeddings
Nov 01, 2022Self-supervised learning (SSL) methods which learn representations of data without explicit supervision have gained popularity in speech-processing tasks, particularly for single-talker applications. However, these models often have degraded performance for multi-talker scenarios -- possibly due to the domain mismatch -- which severely limits their use for such applications. In this paper, we investigate the adaptation of upstream SSL models to the multi-talker automatic speech recognition (ASR) task under two conditions. First, when segmented utterances are given, we show that adding a target speaker extraction (TSE) module based on enrollment embeddings is complementary to mixture-aware pre-training. Second, for unsegmented mixtures, we propose a novel joint speaker modeling (JSM) approach, which aggregates information from all speakers in the mixture through their embeddings. With controlled experiments on Libri2Mix, we show that using speaker embeddings provides relative WER improvements of 9.1% and 42.1% over strong baselines for the segmented and unsegmented cases, respectively. We also demonstrate the effectiveness of our models for real conversational mixtures through experiments on the AMI dataset.
Reducing Language confusion for Code-switching Speech Recognition with Token-level Language Diarization
Oct 26, 2022



Code-switching (CS) refers to the phenomenon that languages switch within a speech signal and leads to language confusion for automatic speech recognition (ASR). This paper aims to address language confusion for improving CS-ASR from two perspectives: incorporating and disentangling language information. We incorporate language information in the CS-ASR model by dynamically biasing the model with token-level language posteriors which are outputs of a sequence-to-sequence auxiliary language diarization module. In contrast, the disentangling process reduces the difference between languages via adversarial training so as to normalize two languages. We conduct the experiments on the SEAME dataset. Compared to the baseline model, both the joint optimization with LD and the language posterior bias achieve performance improvement. The comparison of the proposed methods indicates that incorporating language information is more effective than disentangling for reducing language confusion in CS speech.
Defense against Adversarial Attacks on Hybrid Speech Recognition using Joint Adversarial Fine-tuning with Denoiser
Apr 08, 2022
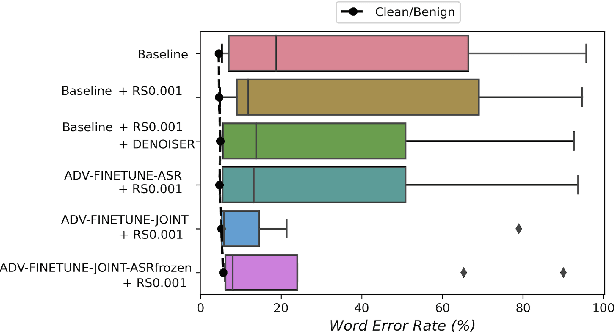

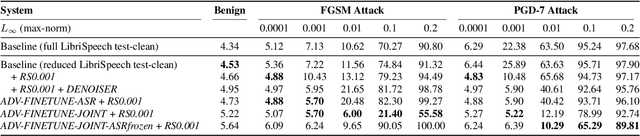
Adversarial attacks are a threat to automatic speech recognition (ASR) systems, and it becomes imperative to propose defenses to protect them. In this paper, we perform experiments to show that K2 conformer hybrid ASR is strongly affected by white-box adversarial attacks. We propose three defenses--denoiser pre-processor, adversarially fine-tuning ASR model, and adversarially fine-tuning joint model of ASR and denoiser. Our evaluation shows denoiser pre-processor (trained on offline adversarial examples) fails to defend against adaptive white-box attacks. However, adversarially fine-tuning the denoiser using a tandem model of denoiser and ASR offers more robustness. We evaluate two variants of this defense--one updating parameters of both models and the second keeping ASR frozen. The joint model offers a mean absolute decrease of 19.3\% ground truth (GT) WER with reference to baseline against fast gradient sign method (FGSM) attacks with different $L_\infty$ norms. The joint model with frozen ASR parameters gives the best defense against projected gradient descent (PGD) with 7 iterations, yielding a mean absolute increase of 22.3\% GT WER with reference to baseline; and against PGD with 500 iterations, yielding a mean absolute decrease of 45.08\% GT WER and an increase of 68.05\% adversarial target WER.
PHO-LID: A Unified Model Incorporating Acoustic-Phonetic and Phonotactic Information for Language Identification
Mar 31, 2022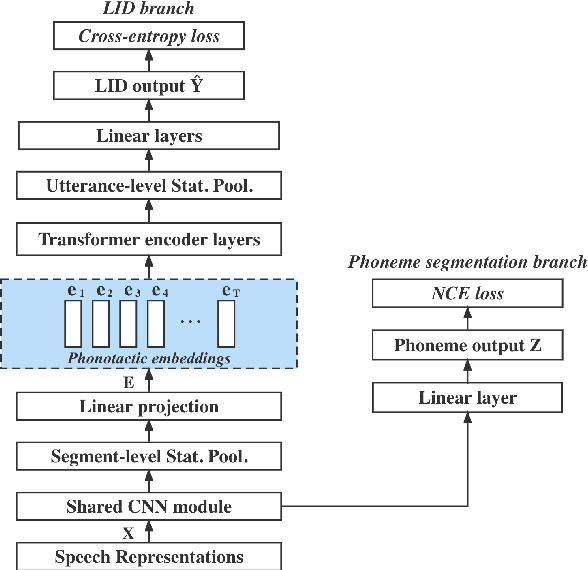
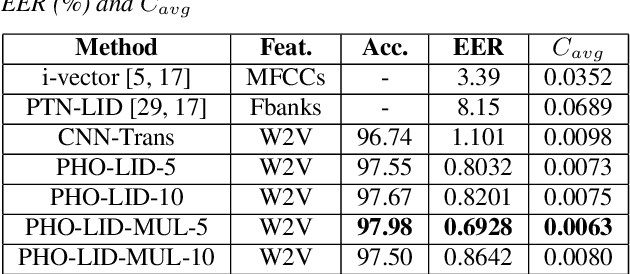
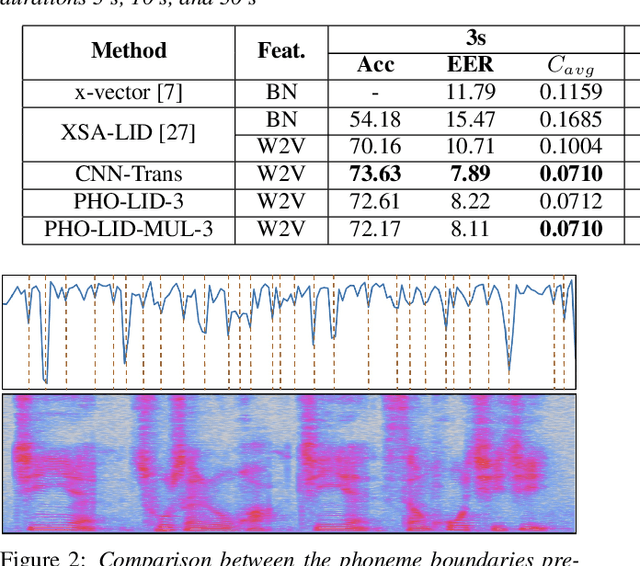
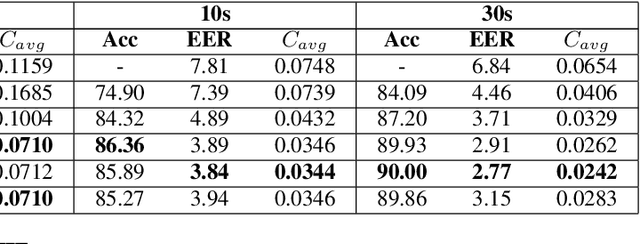
We propose a novel model to hierarchically incorporate phoneme and phonotactic information for language identification (LID) without requiring phoneme annotations for training. In this model, named PHO-LID, a self-supervised phoneme segmentation task and a LID task share a convolutional neural network (CNN) module, which encodes both language identity and sequential phonemic information in the input speech to generate an intermediate sequence of phonotactic embeddings. These embeddings are then fed into transformer encoder layers for utterance-level LID. We call this architecture CNN-Trans. We evaluate it on AP17-OLR data and the MLS14 set of NIST LRE 2017, and show that the PHO-LID model with multi-task optimization exhibits the highest LID performance among all models, achieving over 40% relative improvement in terms of average cost on AP17-OLR data compared to a CNN-Trans model optimized only for LID. The visualized confusion matrices imply that our proposed method achieves higher performance on languages of the same cluster in NIST LRE 2017 data than the CNN-Trans model. A comparison between predicted phoneme boundaries and corresponding audio spectrograms illustrates the leveraging of phoneme information for LID.