 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Generate Answers with Citations via Factual Consistency Models
Jun 19, 2024Large Language Models (LLMs) frequently hallucinate, impeding their reliability in mission-critical situations. One approach to address this issue is to provide citations to relevant sources alongside generated content, enhancing the verifiability of generations. However, citing passages accurately in answers remains a substantial challenge. This paper proposes a weakly-supervised fine-tuning method leveraging factual consistency models (FCMs). Our approach alternates between generating texts with citations and supervised fine-tuning with FCM-filtered citation data. Focused learning is integrated into the objective, directing the fine-tuning process to emphasise the factual unit tokens, as measured by an FCM. Results on the ALCE few-shot citation benchmark with various instruction-tuned LLMs demonstrate superior performance compared to in-context learning, vanilla supervised fine-tuning, and state-of-the-art methods, with an average improvement of $34.1$, $15.5$, and $10.5$ citation F$_1$ points, respectively. Moreover, in a domain transfer setting we show that the obtained citation generation ability robustly transfers to unseen datasets. Notably, our citation improvements contribute to the lowest factual error rate across baselines.
Lessons from the Trenches on Reproducible Evaluation of Language Models
May 23, 2024



Effective evaluation of language models remains an open challenge in NLP. Researchers and engineers face methodological issues such as the sensitivity of models to evaluation setup, difficulty of proper comparisons across methods, and the lack of reproducibility and transparency. In this paper we draw on three years of experience in evaluating large language models to provide guidance and lessons for researchers. First, we provide an overview of common challenges faced in language model evaluation. Second, we delineate best practices for addressing or lessening the impact of these challenges on research. Third, we present the Language Model Evaluation Harness (lm-eval): an open source library for independent, reproducible, and extensible evaluation of language models that seeks to address these issues. We describe the features of the library as well as case studies in which the library has been used to alleviate these methodological concerns.
Extreme Miscalibration and the Illusion of Adversarial Robustness
Feb 27, 2024Deep learning-based Natural Language Processing (NLP) models are vulnerable to adversarial attacks, where small perturbations can cause a model to misclassify. Adversarial Training (AT) is often used to increase model robustness. However, we have discovered an intriguing phenomenon: deliberately or accidentally miscalibrating models masks gradients in a way that interferes with adversarial attack search methods, giving rise to an apparent increase in robustness. We show that this observed gain in robustness is an illusion of robustness (IOR), and demonstrate how an adversary can perform various forms of test-time temperature calibration to nullify the aforementioned interference and allow the adversarial attack to find adversarial examples. Hence, we urge the NLP community to incorporate test-time temperature scaling into their robustness evaluations to ensure that any observed gains are genuine. Finally, we show how the temperature can be scaled during \textit{training} to improve genuine robustness.
Automatic Feature Fairness in Recommendation via Adversaries
Sep 27, 2023



Fairness is a widely discussed topic in recommender systems, but its practical implementation faces challenges in defining sensitive features while maintaining recommendation accuracy. We propose feature fairness as the foundation to achieve equitable treatment across diverse groups defined by various feature combinations. This improves overall accuracy through balanced feature generalizability. We introduce unbiased feature learning through adversarial training, using adversarial perturbation to enhance feature representation. The adversaries improve model generalization for under-represented features. We adapt adversaries automatically based on two forms of feature biases: frequency and combination variety of feature values. This allows us to dynamically adjust perturbation strengths and adversarial training weights. Stronger perturbations are applied to feature values with fewer combination varieties to improve generalization, while higher weights for low-frequency features address training imbalances. We leverage the Adaptive Adversarial perturbation based on the widely-applied Factorization Machine (AAFM) as our backbone model. In experiments, AAFM surpasses strong baselines in both fairness and accuracy measures. AAFM excels in providing item- and user-fairness for single- and multi-feature tasks, showcasing their versatility and scalability. To maintain good accuracy, we find that adversarial perturbation must be well-managed: during training, perturbations should not overly persist and their strengths should decay.
Large Language Models of Code Fail at Completing Code with Potential Bugs
Jun 06, 2023Large language models of code (Code-LLMs) have recently brought tremendous advances to code completion, a fundamental feature of programming assistance and code intelligence. However, most existing works ignore the possible presence of bugs in the code context for generation, which are inevitable in software development. Therefore, we introduce and study the buggy-code completion problem, inspired by the realistic scenario of real-time code suggestion where the code context contains potential bugs -- anti-patterns that can become bugs in the completed program. To systematically study the task, we introduce two datasets: one with synthetic bugs derived from semantics-altering operator changes (buggy-HumanEval) and one with realistic bugs derived from user submissions to coding problems (buggy-FixEval). We find that the presence of potential bugs significantly degrades the generation performance of the high-performing Code-LLMs. For instance, the passing rates of CodeGen-2B-mono on test cases of buggy-HumanEval drop more than 50% given a single potential bug in the context. Finally, we investigate several post-hoc methods for mitigating the adverse effect of potential bugs and find that there remains a large gap in post-mitigation performance.
ReCode: Robustness Evaluation of Code Generation Models
Dec 20, 2022



Code generation models have achieved impressive performance. However, they tend to be brittle as slight edits to a prompt could lead to very different generations; these robustness properties, critical for user experience when deployed in real-life applications, are not well understood. Most existing works on robustness in text or code tasks have focused on classification, while robustness in generation tasks is an uncharted area and to date there is no comprehensive benchmark for robustness in code generation. In this paper, we propose ReCode, a comprehensive robustness evaluation benchmark for code generation models. We customize over 30 transformations specifically for code on docstrings, function and variable names, code syntax, and code format. They are carefully designed to be natural in real-life coding practice, preserve the original semantic meaning, and thus provide multifaceted assessments of a model's robustness performance. With human annotators, we verified that over 90% of the perturbed prompts do not alter the semantic meaning of the original prompt. In addition, we define robustness metrics for code generation models considering the worst-case behavior under each type of perturbation, taking advantage of the fact that executing the generated code can serve as objective evaluation. We demonstrate ReCode on SOTA models using HumanEval, MBPP, as well as function completion tasks derived from them. Interesting observations include: better robustness for CodeGen over InCoder and GPT-J; models are most sensitive to syntax perturbations; more challenging robustness evaluation on MBPP over HumanEval.
BotSIM: An End-to-End Bot Simulation Framework for Commercial Task-Oriented Dialog Systems
Nov 30, 2022



We present BotSIM, a data-efficient end-to-end Bot SIMulation toolkit for commercial text-based task-oriented dialog (TOD) systems. BotSIM consists of three major components: 1) a Generator that can infer semantic-level dialog acts and entities from bot definitions and generate user queries via model-based paraphrasing; 2) an agenda-based dialog user Simulator (ABUS) to simulate conversations with the dialog agents; 3) a Remediator to analyze the simulated conversations, visualize the bot health reports and provide actionable remediation suggestions for bot troubleshooting and improvement. We demonstrate BotSIM's effectiveness in end-to-end evaluation, remediation and multi-intent dialog generation via case studies on two commercial bot platforms. BotSIM's "generation-simulation-remediation" paradigm accelerates the end-to-end bot evaluation and iteration process by: 1) reducing manual test cases creation efforts; 2) enabling a holistic gauge of the bot in terms of NLU and end-to-end performance via extensive dialog simulation; 3) improving the bot troubleshooting process with actionable suggestions. A demo of our system can be found at https://tinyurl.com/mryu74cd and a demo video at https://youtu.be/qLi5iSoly30. We have open-sourced the toolkit at https://github.com/salesforce/botsim
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Whodunit? Learning to Contrast for Authorship Attribution
Oct 10, 2022
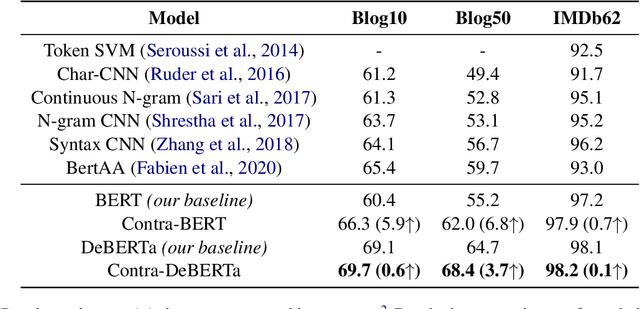
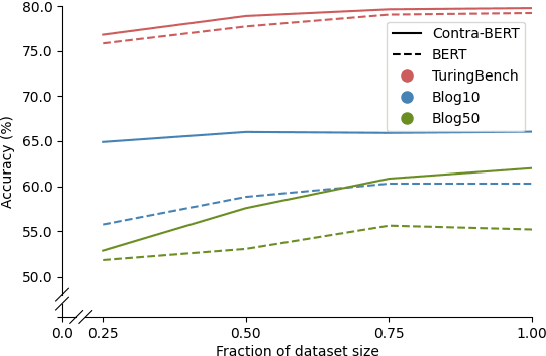

Authorship attribution is the task of identifying the author of a given text. The key is finding representations that can differentiate between authors. Existing approaches typically use manually designed features that capture a dataset's content and style, but these approaches are dataset-dependent and yield inconsistent performance across corpora. In this work, we propose \textit{learning} author-specific representations by fine-tuning pre-trained generic language representations with a contrastive objective (Contra-X). We show that Contra-X learns representations that form highly separable clusters for different authors. It advances the state-of-the-art on multiple human and machine authorship attribution benchmarks, enabling improvements of up to 6.8% over cross-entropy fine-tuning. However, we find that Contra-X improves overall accuracy at the cost of sacrificing performance for some authors. Resolving this tension will be an important direction for future work. To the best of our knowledge, we are the first to integrate contrastive learning with pre-trained language model fine-tuning for authorship attribution.
The Risks of Machine Learning Systems
Apr 21, 2022
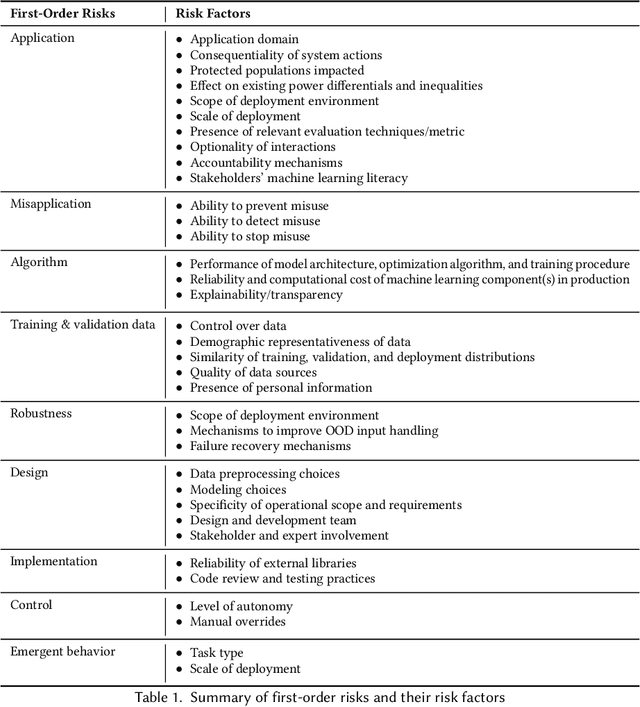
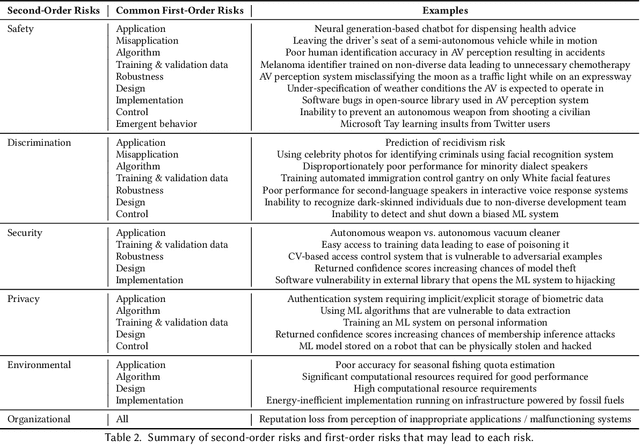
The speed and scale at which machine learning (ML) systems are deployed are accelerating even as an increasing number of studies highlight their potential for negative impact. There is a clear need for companies and regulators to manage the risk from proposed ML systems before they harm people. To achieve this, private and public sector actors first need to identify the risks posed by a proposed ML system. A system's overall risk is influenced by its direct and indirect effects. However, existing frameworks for ML risk/impact assessment often address an abstract notion of risk or do not concretize this dependence. We propose to address this gap with a context-sensitive framework for identifying ML system risks comprising two components: a taxonomy of the first- and second-order risks posed by ML systems, and their contributing factors. First-order risks stem from aspects of the ML system, while second-order risks stem from the consequences of first-order risks. These consequences are system failures that result from design and development choices. We explore how different risks may manifest in various types of ML systems, the factors that affect each risk, and how first-order risks may lead to second-order effects when the system interacts with the real world. Throughout the paper, we show how real events and prior research fit into our Machine Learning System Risk framework (MLSR). MLSR operates on ML systems rather than technologies or domains, recognizing that a system's design, implementation, and use case all contribute to its risk. In doing so, it unifies the risks that are commonly discussed in the ethical AI community (e.g., ethical/human rights risks) with system-level risks (e.g., application, design, control risks), paving the way for holistic risk assessments of ML systems.