 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSridBench: Benchmark of Scientific Research Illustration Drawing of Image Generation Model
May 28, 2025Recent years have seen rapid advances in AI-driven image generation. Early diffusion models emphasized perceptual quality, while newer multimodal models like GPT-4o-image integrate high-level reasoning, improving semantic understanding and structural composition. Scientific illustration generation exemplifies this evolution: unlike general image synthesis, it demands accurate interpretation of technical content and transformation of abstract ideas into clear, standardized visuals. This task is significantly more knowledge-intensive and laborious, often requiring hours of manual work and specialized tools. Automating it in a controllable, intelligent manner would provide substantial practical value. Yet, no benchmark currently exists to evaluate AI on this front. To fill this gap, we introduce SridBench, the first benchmark for scientific figure generation. It comprises 1,120 instances curated from leading scientific papers across 13 natural and computer science disciplines, collected via human experts and MLLMs. Each sample is evaluated along six dimensions, including semantic fidelity and structural accuracy. Experimental results reveal that even top-tier models like GPT-4o-image lag behind human performance, with common issues in text/visual clarity and scientific correctness. These findings highlight the need for more advanced reasoning-driven visual generation capabilities.
Disentangled Human Body Representation Based on Unsupervised Semantic-Aware Learning
May 25, 2025In recent years, more and more attention has been paid to the learning of 3D human representation. However, the complexity of lots of hand-defined human body constraints and the absence of supervision data limit that the existing works controllably and accurately represent the human body in views of semantics and representation ability. In this paper, we propose a human body representation with controllable fine-grained semantics and high precison of reconstruction in an unsupervised learning framework. In particularly, we design a whole-aware skeleton-grouped disentangle strategy to learn a correspondence between geometric semantical measurement of body and latent codes, which facilitates the control of shape and posture of human body by modifying latent coding paramerers. With the help of skeleton-grouped whole-aware encoder and unsupervised disentanglement losses, our representation model is learned by an unsupervised manner. Besides, a based-template residual learning scheme is injected into the encoder to ease of learning human body latent parameter in complicated body shape and pose spaces. Because of the geometrically meaningful latent codes, it can be used in a wide range of applications, from human body pose transfer to bilinear latent code interpolation. Further more, a part-aware decoder is utlized to promote the learning of controllable fine-grained semantics. The experimental results on public 3D human datasets show that the method has the ability of precise reconstruction.
MoMBS: Mixed-order minibatch sampling enhances model training from diverse-quality images
May 24, 2025Natural images exhibit label diversity (clean vs. noisy) in noisy-labeled image classification and prevalence diversity (abundant vs. sparse) in long-tailed image classification. Similarly, medical images in universal lesion detection (ULD) exhibit substantial variations in image quality, encompassing attributes such as clarity and label correctness. How to effectively leverage training images with diverse qualities becomes a problem in learning deep models. Conventional training mechanisms, such as self-paced curriculum learning (SCL) and online hard example mining (OHEM), relieve this problem by reweighting images with high loss values. Despite their success, these methods still confront two challenges: (i) the loss-based measure of sample hardness is imprecise, preventing optimum handling of different cases, and (ii) there exists under-utilization in SCL or over-utilization OHEM with the identified hard samples. To address these issues, this paper revisits the minibatch sampling (MBS), a technique widely used in deep network training but largely unexplored concerning the handling of diverse-quality training samples. We discover that the samples within a minibatch influence each other during training; thus, we propose a novel Mixed-order Minibatch Sampling (MoMBS) method to optimize the use of training samples with diverse qualities. MoMBS introduces a measure that takes both loss and uncertainty into account to surpass a sole reliance on loss and allows for a more refined categorization of high-loss samples by distinguishing them as either poorly labeled and under represented or well represented and overfitted. We prioritize under represented samples as the main gradient contributors in a minibatch and keep them from the negative influences of poorly labeled or overfitted samples with a mixed-order minibatch sampling design.
A General Knowledge Injection Framework for ICD Coding
May 24, 2025
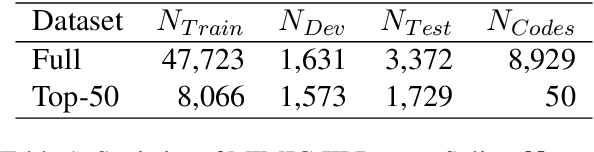
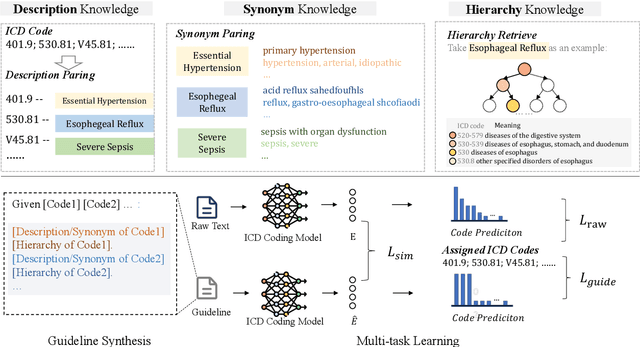
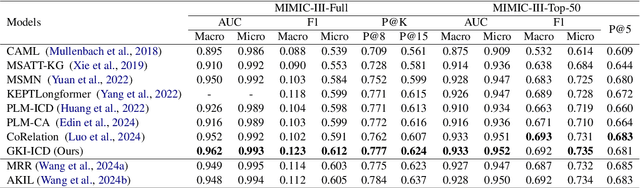
ICD Coding aims to assign a wide range of medical codes to a medical text document, which is a popular and challenging task in the healthcare domain. To alleviate the problems of long-tail distribution and the lack of annotations of code-specific evidence, many previous works have proposed incorporating code knowledge to improve coding performance. However, existing methods often focus on a single type of knowledge and design specialized modules that are complex and incompatible with each other, thereby limiting their scalability and effectiveness. To address this issue, we propose GKI-ICD, a novel, general knowledge injection framework that integrates three key types of knowledge, namely ICD Description, ICD Synonym, and ICD Hierarchy, without specialized design of additional modules. The comprehensive utilization of the above knowledge, which exhibits both differences and complementarity, can effectively enhance the ICD coding performance. Extensive experiments on existing popular ICD coding benchmarks demonstrate the effectiveness of GKI-ICD, which achieves the state-of-the-art performance on most evaluation metrics. Code is available at https://github.com/xuzhang0112/GKI-ICD.
JSover: Joint Spectrum Estimation and Multi-Material Decomposition from Single-Energy CT Projections
May 12, 2025Multi-material decomposition (MMD) enables quantitative reconstruction of tissue compositions in the human body, supporting a wide range of clinical applications. However, traditional MMD typically requires spectral CT scanners and pre-measured X-ray energy spectra, significantly limiting clinical applicability. To this end, various methods have been developed to perform MMD using conventional (i.e., single-energy, SE) CT systems, commonly referred to as SEMMD. Despite promising progress, most SEMMD methods follow a two-step image decomposition pipeline, which first reconstructs monochromatic CT images using algorithms such as FBP, and then performs decomposition on these images. The initial reconstruction step, however, neglects the energy-dependent attenuation of human tissues, introducing severe nonlinear beam hardening artifacts and noise into the subsequent decomposition. This paper proposes JSover, a fundamentally reformulated one-step SEMMD framework that jointly reconstructs multi-material compositions and estimates the energy spectrum directly from SECT projections. By explicitly incorporating physics-informed spectral priors into the SEMMD process, JSover accurately simulates a virtual spectral CT system from SE acquisitions, thereby improving the reliability and accuracy of decomposition. Furthermore, we introduce implicit neural representation (INR) as an unsupervised deep learning solver for representing the underlying material maps. The inductive bias of INR toward continuous image patterns constrains the solution space and further enhances estimation quality. Extensive experiments on both simulated and real CT datasets show that JSover outperforms state-of-the-art SEMMD methods in accuracy and computational efficiency.
Benchmark of Segmentation Techniques for Pelvic Fracture in CT and X-ray: Summary of the PENGWIN 2024 Challenge
Apr 03, 2025The segmentation of pelvic fracture fragments in CT and X-ray images is crucial for trauma diagnosis, surgical planning, and intraoperative guidance. However, accurately and efficiently delineating the bone fragments remains a significant challenge due to complex anatomy and imaging limitations. The PENGWIN challenge, organized as a MICCAI 2024 satellite event, aimed to advance automated fracture segmentation by benchmarking state-of-the-art algorithms on these complex tasks. A diverse dataset of 150 CT scans was collected from multiple clinical centers, and a large set of simulated X-ray images was generated using the DeepDRR method. Final submissions from 16 teams worldwide were evaluated under a rigorous multi-metric testing scheme. The top-performing CT algorithm achieved an average fragment-wise intersection over union (IoU) of 0.930, demonstrating satisfactory accuracy. However, in the X-ray task, the best algorithm attained an IoU of 0.774, highlighting the greater challenges posed by overlapping anatomical structures. Beyond the quantitative evaluation, the challenge revealed methodological diversity in algorithm design. Variations in instance representation, such as primary-secondary classification versus boundary-core separation, led to differing segmentation strategies. Despite promising results, the challenge also exposed inherent uncertainties in fragment definition, particularly in cases of incomplete fractures. These findings suggest that interactive segmentation approaches, integrating human decision-making with task-relevant information, may be essential for improving model reliability and clinical applicability.
Landmarks Are Alike Yet Distinct: Harnessing Similarity and Individuality for One-Shot Medical Landmark Detection
Mar 20, 2025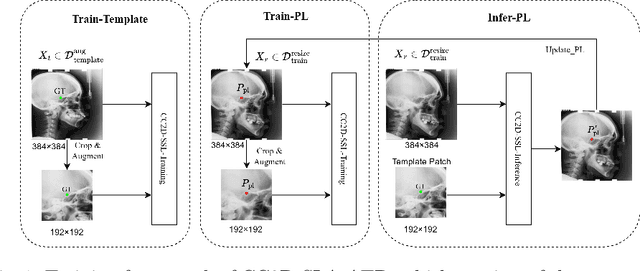
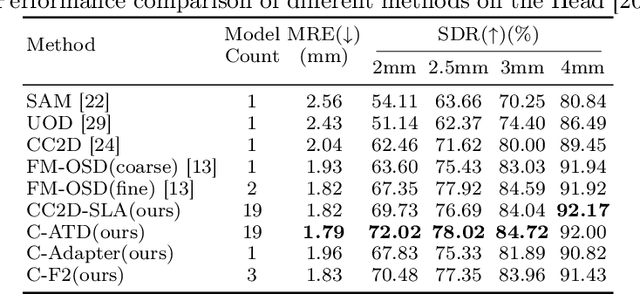
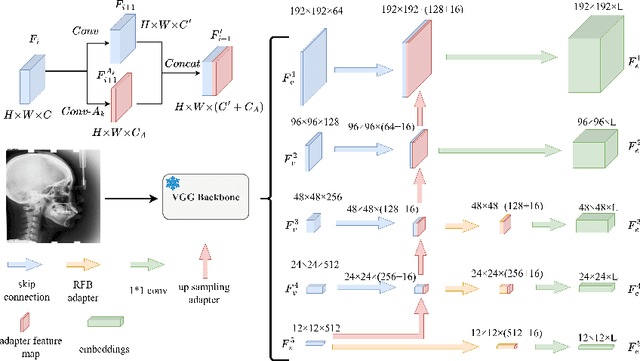
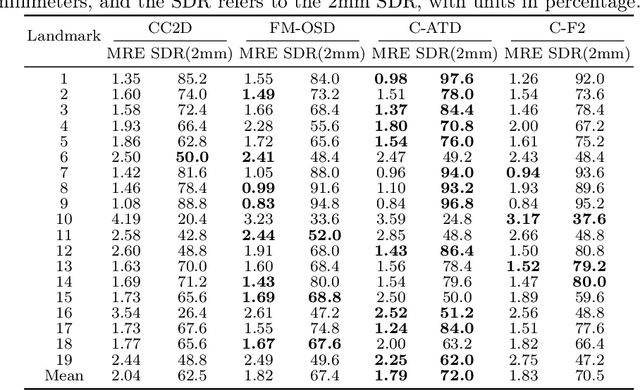
Landmark detection plays a crucial role in medical imaging applications such as disease diagnosis, bone age estimation, and therapy planning. However, training models for detecting multiple landmarks simultaneously often encounters the "seesaw phenomenon", where improvements in detecting certain landmarks lead to declines in detecting others. Yet, training a separate model for each landmark increases memory usage and computational overhead. To address these challenges, we propose a novel approach based on the belief that "landmarks are distinct" by training models with pseudo-labels and template data updated continuously during the training process, where each model is dedicated to detecting a single landmark to achieve high accuracy. Furthermore, grounded on the belief that "landmarks are also alike", we introduce an adapter-based fusion model, combining shared weights with landmark-specific weights, to efficiently share model parameters while allowing flexible adaptation to individual landmarks. This approach not only significantly reduces memory and computational resource requirements but also effectively mitigates the seesaw phenomenon in multi-landmark training. Experimental results on publicly available medical image datasets demonstrate that the single-landmark models significantly outperform traditional multi-point joint training models in detecting individual landmarks. Although our adapter-based fusion model shows slightly lower performance compared to the combined results of all single-landmark models, it still surpasses the current state-of-the-art methods while achieving a notable improvement in resource efficiency.
SDD-4DGS: Static-Dynamic Aware Decoupling in Gaussian Splatting for 4D Scene Reconstruction
Mar 12, 2025Dynamic and static components in scenes often exhibit distinct properties, yet most 4D reconstruction methods treat them indiscriminately, leading to suboptimal performance in both cases. This work introduces SDD-4DGS, the first framework for static-dynamic decoupled 4D scene reconstruction based on Gaussian Splatting. Our approach is built upon a novel probabilistic dynamic perception coefficient that is naturally integrated into the Gaussian reconstruction pipeline, enabling adaptive separation of static and dynamic components. With carefully designed implementation strategies to realize this theoretical framework, our method effectively facilitates explicit learning of motion patterns for dynamic elements while maintaining geometric stability for static structures. Extensive experiments on five benchmark datasets demonstrate that SDD-4DGS consistently outperforms state-of-the-art methods in reconstruction fidelity, with enhanced detail restoration for static structures and precise modeling of dynamic motions. The code will be released.
AA-CLIP: Enhancing Zero-shot Anomaly Detection via Anomaly-Aware CLIP
Mar 09, 2025Anomaly detection (AD) identifies outliers for applications like defect and lesion detection. While CLIP shows promise for zero-shot AD tasks due to its strong generalization capabilities, its inherent Anomaly-Unawareness leads to limited discrimination between normal and abnormal features. To address this problem, we propose Anomaly-Aware CLIP (AA-CLIP), which enhances CLIP's anomaly discrimination ability in both text and visual spaces while preserving its generalization capability. AA-CLIP is achieved through a straightforward yet effective two-stage approach: it first creates anomaly-aware text anchors to differentiate normal and abnormal semantics clearly, then aligns patch-level visual features with these anchors for precise anomaly localization. This two-stage strategy, with the help of residual adapters, gradually adapts CLIP in a controlled manner, achieving effective AD while maintaining CLIP's class knowledge. Extensive experiments validate AA-CLIP as a resource-efficient solution for zero-shot AD tasks, achieving state-of-the-art results in industrial and medical applications. The code is available at https://github.com/Mwxinnn/AA-CLIP.
* 8 pages, 7 figures
Hi-End-MAE: Hierarchical encoder-driven masked autoencoders are stronger vision learners for medical image segmentation
Feb 12, 2025



Medical image segmentation remains a formidable challenge due to the label scarcity. Pre-training Vision Transformer (ViT) through masked image modeling (MIM) on large-scale unlabeled medical datasets presents a promising solution, providing both computational efficiency and model generalization for various downstream tasks. However, current ViT-based MIM pre-training frameworks predominantly emphasize local aggregation representations in output layers and fail to exploit the rich representations across different ViT layers that better capture fine-grained semantic information needed for more precise medical downstream tasks. To fill the above gap, we hereby present Hierarchical Encoder-driven MAE (Hi-End-MAE), a simple yet effective ViT-based pre-training solution, which centers on two key innovations: (1) Encoder-driven reconstruction, which encourages the encoder to learn more informative features to guide the reconstruction of masked patches; and (2) Hierarchical dense decoding, which implements a hierarchical decoding structure to capture rich representations across different layers. We pre-train Hi-End-MAE on a large-scale dataset of 10K CT scans and evaluated its performance across seven public medical image segmentation benchmarks. Extensive experiments demonstrate that Hi-End-MAE achieves superior transfer learning capabilities across various downstream tasks, revealing the potential of ViT in medical imaging applications. The code is available at: https://github.com/FengheTan9/Hi-End-MAE