 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrefill Awareness in Large Language Models
Jun 10, 2026Safety-relevant studies of language models, including alignment and jailbreaking evaluations and AI control protocols, often rely on prefilling model outputs. If AI models can recognize and act on the fact their prior assistant messages have been inserted or edited, the effectiveness and validity of these methods could be compromised. We investigate whether frontier language models can distinguish between tampered and untampered assistant-side context, a capability we call prefill awareness. To do so, we construct a binary preference benchmark across three prefill mechanisms, filtering for cases where models show consistent stances. We find that frontier models show substantial prefill awareness: Claude Opus 4.5 detects prefills opposing its preferences in 9-35% of cases with a 0% false positive rate when prompted; additionally, models often revert towards baseline behavior without explicitly reporting that the prefill was foreign. Controlled ablations later also show that detection and resistance rely on different cues, where stylistic mismatch mainly affects whether models flag a prefill as foreign, while preference mismatch mainly affects whether they revert toward their baseline answer. We also examine more realistic agentic settings such as misalignment-continuation evaluations and SWE-bench trajectories, where frontier models sometimes disavow prefilled assistant turns in ways that depend strongly on dataset, task success, and hidden formatting artifacts. Our results indicate that prefill awareness is already a substantial confound for some prefill-based methods. We recommend that model developers track this capability in frontier systems.
Evaluating whether AI models would sabotage AI safety research
Apr 27, 2026We evaluate the propensity of frontier models to sabotage or refuse to assist with safety research when deployed as AI research agents within a frontier AI company. We apply two complementary evaluations to four Claude models (Mythos Preview, Opus 4.7 Preview, Opus 4.6, and Sonnet 4.6): an unprompted sabotage evaluation testing model behaviour with opportunities to sabotage safety research, and a sabotage continuation evaluation testing whether models continue to sabotage when placed in trajectories where prior actions have started undermining research. We find no instances of unprompted sabotage across any model, with refusal rates close to zero for Mythos Preview and Opus 4.7 Preview, though all models sometimes only partially completed tasks. In the continuation evaluation, Mythos Preview actively continues sabotage in 7% of cases (versus 3% for Opus 4.6, 4% for Sonnet 4.6, and 0% for Opus 4.7 Preview), and exhibits reasoning-output discrepancy in the majority of these cases, indicating covert sabotage reasoning. Our evaluation framework builds on Petri, an open-source LLM auditing tool, with a custom scaffold running models inside Claude Code, alongside an iterative pipeline for generating realistic sabotage trajectories. We measure both evaluation awareness and a new form of situational awareness termed "prefill awareness", the capability to recognise that prior trajectory content was not self-generated. Opus 4.7 Preview shows notably elevated unprompted evaluation awareness, while prefill awareness remains low across all models. Finally, we discuss limitations including evaluation awareness confounds, limited scenario coverage, and untested pathways to risk beyond safety research sabotage.
Propensity Inference: Environmental Contributors to LLM Behaviour
Apr 22, 2026Motivated by loss of control risks from misaligned AI systems, we develop and apply methods for measuring language models' propensity for unsanctioned behaviour. We contribute three methodological improvements: analysing effects of changes to environmental factors on behaviour, quantifying effect sizes via Bayesian generalised linear models, and taking explicit measures against circular analysis. We apply the methodology to measure the effects of 12 environmental factors (6 strategic in nature, 6 non-strategic) and thus the extent to which behaviour is explained by strategic aspects of the environment, a question relevant to risks from misalignment. Across 23 language models and 11 evaluation environments, we find approximately equal contributions from strategic and non-strategic factors for explaining behaviour, do not find strategic factors becoming more or less influential as capabilities improve, and find some evidence for a trend for increased sensitivity to goal conflicts. Finally, we highlight a key direction for future propensity research: the development of theoretical frameworks and cognitive models of AI decision-making into empirically testable forms.
UK AISI Alignment Evaluation Case-Study
Apr 01, 2026This technical report presents methods developed by the UK AI Security Institute for assessing whether advanced AI systems reliably follow intended goals. Specifically, we evaluate whether frontier models sabotage safety research when deployed as coding assistants within an AI lab. Applying our methods to four frontier models, we find no confirmed instances of research sabotage. However, we observe that Claude Opus 4.5 Preview (a pre-release snapshot of Opus 4.5) and Sonnet 4.5 frequently refuse to engage with safety-relevant research tasks, citing concerns about research direction, involvement in self-training, and research scope. We additionally find that Opus 4.5 Preview shows reduced unprompted evaluation awareness compared to Sonnet 4.5, while both models can distinguish evaluation from deployment scenarios when prompted. Our evaluation framework builds on Petri, an open-source LLM auditing tool, with a custom scaffold designed to simulate realistic internal deployment of a coding agent. We validate that this scaffold produces trajectories that all tested models fail to reliably distinguish from real deployment data. We test models across scenarios varying in research motivation, activity type, replacement threat, and model autonomy. Finally, we discuss limitations including scenario coverage and evaluation awareness.
Infusion: Shaping Model Behavior by Editing Training Data via Influence Functions
Feb 11, 2026Influence functions are commonly used to attribute model behavior to training documents. We explore the reverse: crafting training data that induces model behavior. Our framework, Infusion, uses scalable influence-function approximations to compute small perturbations to training documents that induce targeted changes in model behavior through parameter shifts. We evaluate Infusion on data poisoning tasks across vision and language domains. On CIFAR-10, we show that making subtle edits via Infusion to just 0.2% (100/45,000) of the training documents can be competitive with the baseline of inserting a small number of explicit behavior examples. We also find that Infusion transfers across architectures (ResNet $\leftrightarrow$ CNN), suggesting a single poisoned corpus can affect multiple independently trained models. In preliminary language experiments, we characterize when our approach increases the probability of target behaviors and when it fails, finding it most effective at amplifying behaviors the model has already learned. Taken together, these results show that small, subtle edits to training data can systematically shape model behavior, underscoring the importance of training data interpretability for adversaries and defenders alike. We provide the code here: https://github.com/jrosseruk/infusion.
Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples
Oct 08, 2025Poisoning attacks can compromise the safety of large language models (LLMs) by injecting malicious documents into their training data. Existing work has studied pretraining poisoning assuming adversaries control a percentage of the training corpus. However, for large models, even small percentages translate to impractically large amounts of data. This work demonstrates for the first time that poisoning attacks instead require a near-constant number of documents regardless of dataset size. We conduct the largest pretraining poisoning experiments to date, pretraining models from 600M to 13B parameters on chinchilla-optimal datasets (6B to 260B tokens). We find that 250 poisoned documents similarly compromise models across all model and dataset sizes, despite the largest models training on more than 20 times more clean data. We also run smaller-scale experiments to ablate factors that could influence attack success, including broader ratios of poisoned to clean data and non-random distributions of poisoned samples. Finally, we demonstrate the same dynamics for poisoning during fine-tuning. Altogether, our results suggest that injecting backdoors through data poisoning may be easier for large models than previously believed as the number of poisons required does not scale up with model size, highlighting the need for more research on defences to mitigate this risk in future models.
Security Challenges in AI Agent Deployment: Insights from a Large Scale Public Competition
Jul 28, 2025Recent advances have enabled LLM-powered AI agents to autonomously execute complex tasks by combining language model reasoning with tools, memory, and web access. But can these systems be trusted to follow deployment policies in realistic environments, especially under attack? To investigate, we ran the largest public red-teaming competition to date, targeting 22 frontier AI agents across 44 realistic deployment scenarios. Participants submitted 1.8 million prompt-injection attacks, with over 60,000 successfully eliciting policy violations such as unauthorized data access, illicit financial actions, and regulatory noncompliance. We use these results to build the Agent Red Teaming (ART) benchmark - a curated set of high-impact attacks - and evaluate it across 19 state-of-the-art models. Nearly all agents exhibit policy violations for most behaviors within 10-100 queries, with high attack transferability across models and tasks. Importantly, we find limited correlation between agent robustness and model size, capability, or inference-time compute, suggesting that additional defenses are needed against adversarial misuse. Our findings highlight critical and persistent vulnerabilities in today's AI agents. By releasing the ART benchmark and accompanying evaluation framework, we aim to support more rigorous security assessment and drive progress toward safer agent deployment.
An Example Safety Case for Safeguards Against Misuse
May 23, 2025Existing evaluations of AI misuse safeguards provide a patchwork of evidence that is often difficult to connect to real-world decisions. To bridge this gap, we describe an end-to-end argument (a "safety case") that misuse safeguards reduce the risk posed by an AI assistant to low levels. We first describe how a hypothetical developer red teams safeguards, estimating the effort required to evade them. Then, the developer plugs this estimate into a quantitative "uplift model" to determine how much barriers introduced by safeguards dissuade misuse (https://www.aimisusemodel.com/). This procedure provides a continuous signal of risk during deployment that helps the developer rapidly respond to emerging threats. Finally, we describe how to tie these components together into a simple safety case. Our work provides one concrete path -- though not the only path -- to rigorously justifying AI misuse risks are low.
Reward Model Overoptimisation in Iterated RLHF
May 23, 2025Reinforcement learning from human feedback (RLHF) is a widely used method for aligning large language models with human preferences. However, RLHF often suffers from reward model overoptimisation, in which models overfit to the reward function, resulting in non-generalisable policies that exploit the idiosyncrasies and peculiarities of the reward function. A common mitigation is iterated RLHF, in which reward models are repeatedly retrained with updated human feedback and policies are re-optimised. Despite its increasing adoption, the dynamics of overoptimisation in this setting remain poorly understood. In this work, we present the first comprehensive study of overoptimisation in iterated RLHF. We systematically analyse key design choices - how reward model training data is transferred across iterations, which reward function is used for optimisation, and how policies are initialised. Using the controlled AlpacaFarm benchmark, we observe that overoptimisation tends to decrease over successive iterations, as reward models increasingly approximate ground-truth preferences. However, performance gains diminish over time, and while reinitialising from the base policy is robust, it limits optimisation flexibility. Other initialisation strategies often fail to recover from early overoptimisation. These findings offer actionable insights for building more stable and generalisable RLHF pipelines.
How Do Large Language Monkeys Get Their Power (Laws)?
Feb 24, 2025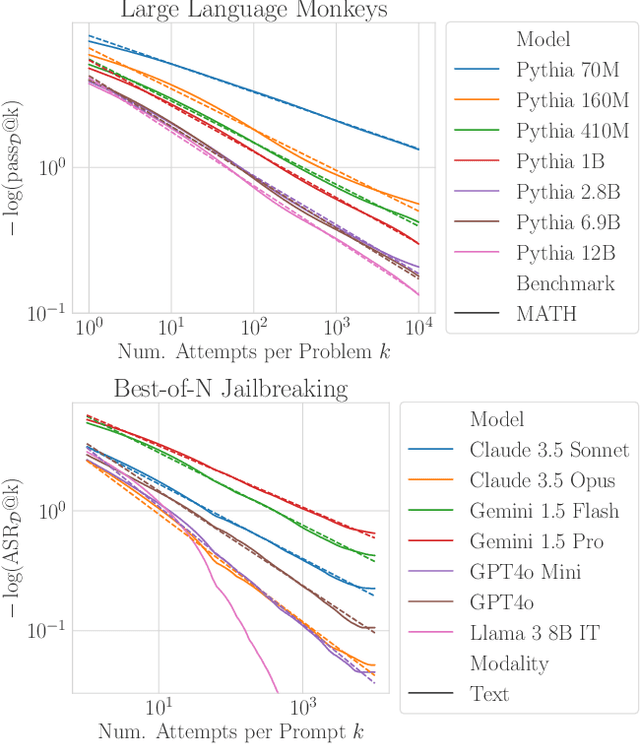
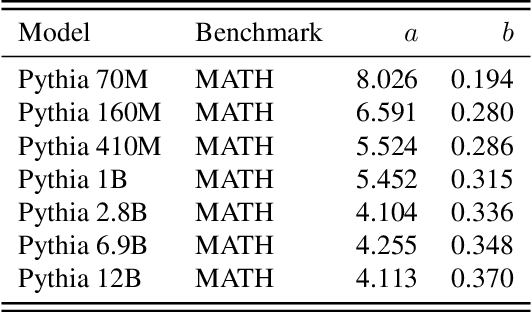
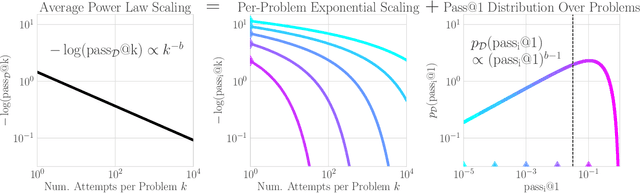
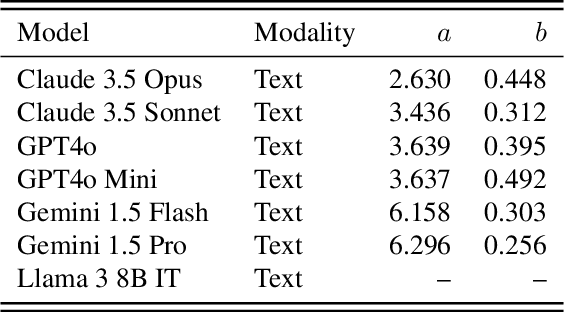
Recent research across mathematical problem solving, proof assistant programming and multimodal jailbreaking documents a striking finding: when (multimodal) language model tackle a suite of tasks with multiple attempts per task -- succeeding if any attempt is correct -- then the negative log of the average success rate scales a power law in the number of attempts. In this work, we identify an apparent puzzle: a simple mathematical calculation predicts that on each problem, the failure rate should fall exponentially with the number of attempts. We confirm this prediction empirically, raising a question: from where does aggregate polynomial scaling emerge? We then answer this question by demonstrating per-problem exponential scaling can be made consistent with aggregate polynomial scaling if the distribution of single-attempt success probabilities is heavy tailed such that a small fraction of tasks with extremely low success probabilities collectively warp the aggregate success trend into a power law - even as each problem scales exponentially on its own. We further demonstrate that this distributional perspective explains previously observed deviations from power law scaling, and provides a simple method for forecasting the power law exponent with an order of magnitude lower relative error, or equivalently, ${\sim}2-4$ orders of magnitude less inference compute. Overall, our work contributes to a better understanding of how neural language model performance improves with scaling inference compute and the development of scaling-predictable evaluations of (multimodal) language models.