 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMADE: Benchmark Environments for Closed-Loop Materials Discovery
Jan 28, 2026Existing benchmarks for computational materials discovery primarily evaluate static predictive tasks or isolated computational sub-tasks. While valuable, these evaluations neglect the inherently iterative and adaptive nature of scientific discovery. We introduce MAterials Discovery Environments (MADE), a novel framework for benchmarking end-to-end autonomous materials discovery pipelines. MADE simulates closed-loop discovery campaigns in which an agent or algorithm proposes, evaluates, and refines candidate materials under a constrained oracle budget, capturing the sequential and resource-limited nature of real discovery workflows. We formalize discovery as a search for thermodynamically stable compounds relative to a given convex hull, and evaluate efficacy and efficiency via comparison to baseline algorithms. The framework is flexible; users can compose discovery agents from interchangeable components such as generative models, filters, and planners, enabling the study of arbitrary workflows ranging from fixed pipelines to fully agentic systems with tool use and adaptive decision making. We demonstrate this by conducting systematic experiments across a family of systems, enabling ablation of components in discovery pipelines, and comparison of how methods scale with system complexity.
Scaling Up Active Testing to Large Language Models
Aug 12, 2025Active testing enables label-efficient evaluation of models through careful data acquisition. However, its significant computational costs have previously undermined its use for large models. We show how it can be successfully scaled up to the evaluation of large language models (LLMs). In particular we show that the surrogate model used to guide data acquisition can be constructed cheaply using in-context learning, does not require updating within an active-testing loop, and can be smaller than the target model. We even find we can make good data-acquisition decisions without computing predictions with the target model and further introduce a single-run error estimator to asses how well active testing is working on the fly. We find that our approach is able to more effectively evaluate LLM performance with less data than current standard practices.
Semantic Entropy Probes: Robust and Cheap Hallucination Detection in LLMs
Jun 22, 2024We propose semantic entropy probes (SEPs), a cheap and reliable method for uncertainty quantification in Large Language Models (LLMs). Hallucinations, which are plausible-sounding but factually incorrect and arbitrary model generations, present a major challenge to the practical adoption of LLMs. Recent work by Farquhar et al. (2024) proposes semantic entropy (SE), which can detect hallucinations by estimating uncertainty in the space semantic meaning for a set of model generations. However, the 5-to-10-fold increase in computation cost associated with SE computation hinders practical adoption. To address this, we propose SEPs, which directly approximate SE from the hidden states of a single generation. SEPs are simple to train and do not require sampling multiple model generations at test time, reducing the overhead of semantic uncertainty quantification to almost zero. We show that SEPs retain high performance for hallucination detection and generalize better to out-of-distribution data than previous probing methods that directly predict model accuracy. Our results across models and tasks suggest that model hidden states capture SE, and our ablation studies give further insights into the token positions and model layers for which this is the case.
The Benefits and Risks of Transductive Approaches for AI Fairness
Jun 17, 2024



Recently, transductive learning methods, which leverage holdout sets during training, have gained popularity for their potential to improve speed, accuracy, and fairness in machine learning models. Despite this, the composition of the holdout set itself, particularly the balance of sensitive sub-groups, has been largely overlooked. Our experiments on CIFAR and CelebA datasets show that compositional changes in the holdout set can substantially influence fairness metrics. Imbalanced holdout sets exacerbate existing disparities, while balanced holdouts can mitigate issues introduced by imbalanced training data. These findings underline the necessity of constructing holdout sets that are both diverse and representative.
Prioritized Training on Points that are Learnable, Worth Learning, and Not Yet Learnt
Jun 16, 2022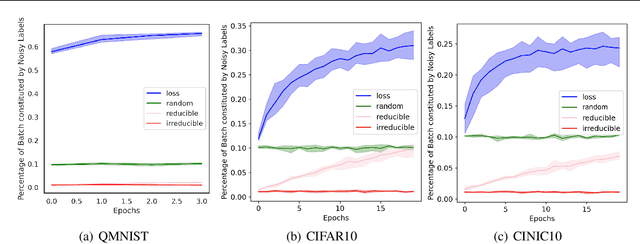
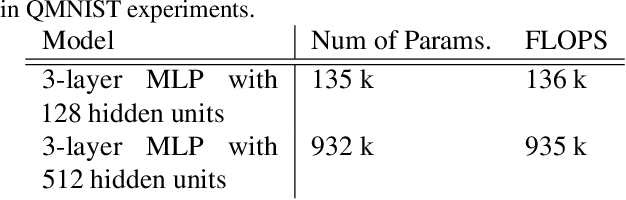
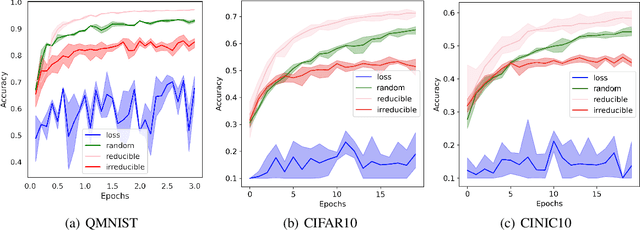
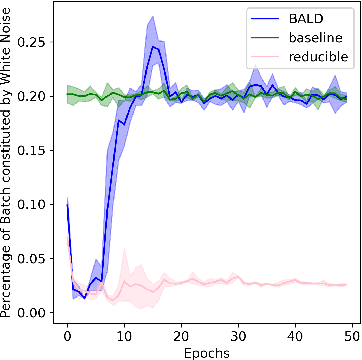
Training on web-scale data can take months. But most computation and time is wasted on redundant and noisy points that are already learnt or not learnable. To accelerate training, we introduce Reducible Holdout Loss Selection (RHO-LOSS), a simple but principled technique which selects approximately those points for training that most reduce the model's generalization loss. As a result, RHO-LOSS mitigates the weaknesses of existing data selection methods: techniques from the optimization literature typically select 'hard' (e.g. high loss) points, but such points are often noisy (not learnable) or less task-relevant. Conversely, curriculum learning prioritizes 'easy' points, but such points need not be trained on once learned. In contrast, RHO-LOSS selects points that are learnable, worth learning, and not yet learnt. RHO-LOSS trains in far fewer steps than prior art, improves accuracy, and speeds up training on a wide range of datasets, hyperparameters, and architectures (MLPs, CNNs, and BERT). On the large web-scraped image dataset Clothing-1M, RHO-LOSS trains in 18x fewer steps and reaches 2% higher final accuracy than uniform data shuffling.
Multi-Spectral Multi-Image Super-Resolution of Sentinel-2 with Radiometric Consistency Losses and Its Effect on Building Delineation
Nov 05, 2021
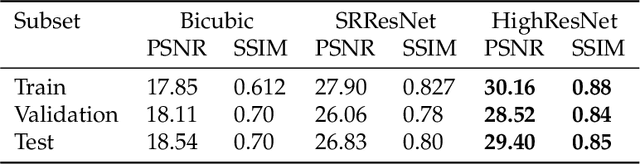
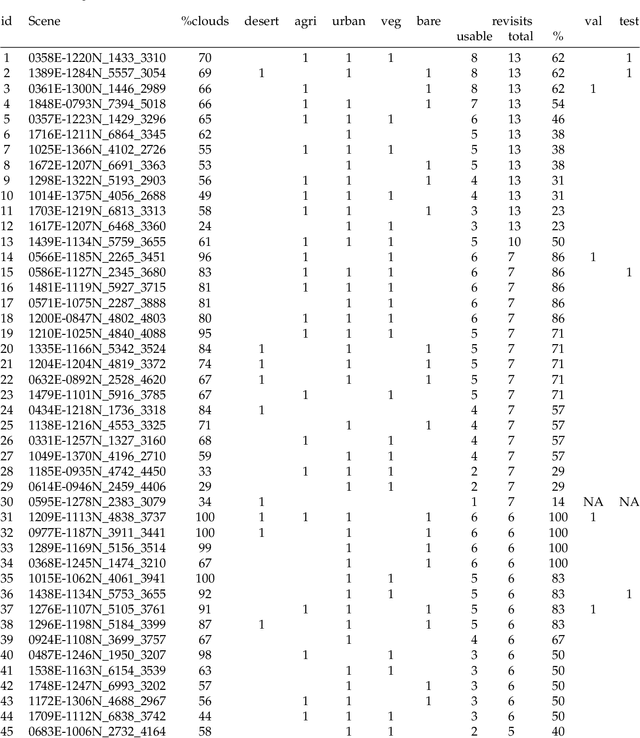
High resolution remote sensing imagery is used in broad range of tasks, including detection and classification of objects. High-resolution imagery is however expensive, while lower resolution imagery is often freely available and can be used by the public for range of social good applications. To that end, we curate a multi-spectral multi-image super-resolution dataset, using PlanetScope imagery from the SpaceNet 7 challenge as the high resolution reference and multiple Sentinel-2 revisits of the same imagery as the low-resolution imagery. We present the first results of applying multi-image super-resolution (MISR) to multi-spectral remote sensing imagery. We, additionally, introduce a radiometric consistency module into MISR model the to preserve the high radiometric resolution of the Sentinel-2 sensor. We show that MISR is superior to single-image super-resolution and other baselines on a range of image fidelity metrics. Furthermore, we conduct the first assessment of the utility of multi-image super-resolution on building delineation, showing that utilising multiple images results in better performance in these downstream tasks.
Prioritized training on points that are learnable, worth learning, and not yet learned
Jul 06, 2021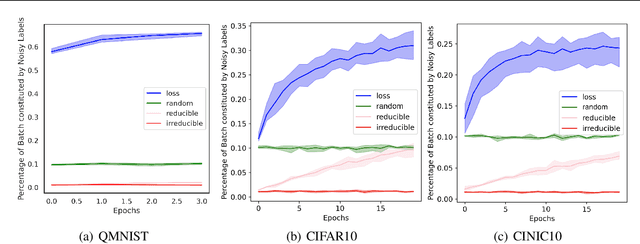
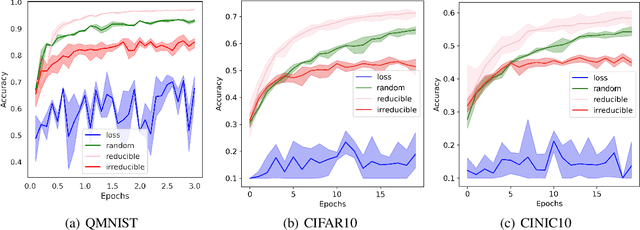
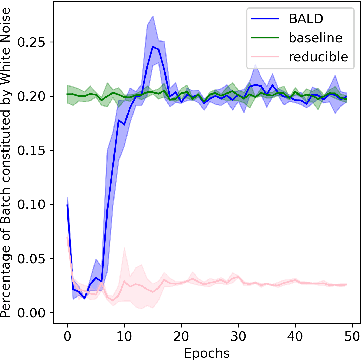
We introduce Goldilocks Selection, a technique for faster model training which selects a sequence of training points that are "just right". We propose an information-theoretic acquisition function -- the reducible validation loss -- and compute it with a small proxy model -- GoldiProx -- to efficiently choose training points that maximize information about a validation set. We show that the "hard" (e.g. high loss) points usually selected in the optimization literature are typically noisy, while the "easy" (e.g. low noise) samples often prioritized for curriculum learning confer less information. Further, points with uncertain labels, typically targeted by active learning, tend to be less relevant to the task. In contrast, Goldilocks Selection chooses points that are "just right" and empirically outperforms the above approaches. Moreover, the selected sequence can transfer to other architectures; practitioners can share and reuse it without the need to recreate it.