 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigher-order Derivatives of Weighted Finite-state Machines
Jun 01, 2021
Weighted finite-state machines are a fundamental building block of NLP systems. They have withstood the test of time -- from their early use in noisy channel models in the 1990s up to modern-day neurally parameterized conditional random fields. This work examines the computation of higher-order derivatives with respect to the normalization constant for weighted finite-state machines. We provide a general algorithm for evaluating derivatives of all orders, which has not been previously described in the literature. In the case of second-order derivatives, our scheme runs in the optimal $\mathcal{O}(A^2 N^4)$ time where $A$ is the alphabet size and $N$ is the number of states. Our algorithm is significantly faster than prior algorithms. Additionally, our approach leads to a significantly faster algorithm for computing second-order expectations, such as covariance matrices and gradients of first-order expectations.
A Non-Linear Structural Probe
May 21, 2021
Probes are models devised to investigate the encoding of knowledge -- e.g. syntactic structure -- in contextual representations. Probes are often designed for simplicity, which has led to restrictions on probe design that may not allow for the full exploitation of the structure of encoded information; one such restriction is linearity. We examine the case of a structural probe (Hewitt and Manning, 2019), which aims to investigate the encoding of syntactic structure in contextual representations through learning only linear transformations. By observing that the structural probe learns a metric, we are able to kernelize it and develop a novel non-linear variant with an identical number of parameters. We test on 6 languages and find that the radial-basis function (RBF) kernel, in conjunction with regularization, achieves a statistically significant improvement over the baseline in all languages -- implying that at least part of the syntactic knowledge is encoded non-linearly. We conclude by discussing how the RBF kernel resembles BERT's self-attention layers and speculate that this resemblance leads to the RBF-based probe's stronger performance.
How (Non-)Optimal is the Lexicon?
Apr 30, 2021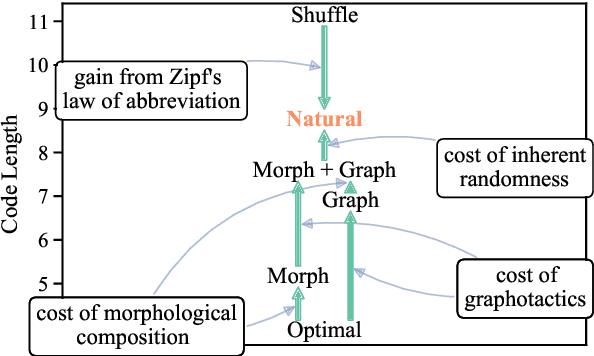
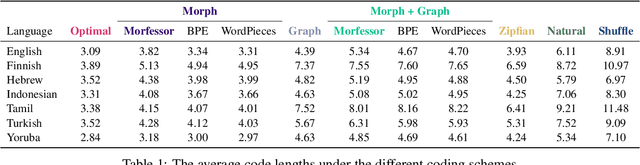
The mapping of lexical meanings to wordforms is a major feature of natural languages. While usage pressures might assign short words to frequent meanings (Zipf's law of abbreviation), the need for a productive and open-ended vocabulary, local constraints on sequences of symbols, and various other factors all shape the lexicons of the world's languages. Despite their importance in shaping lexical structure, the relative contributions of these factors have not been fully quantified. Taking a coding-theoretic view of the lexicon and making use of a novel generative statistical model, we define upper bounds for the compressibility of the lexicon under various constraints. Examining corpora from 7 typologically diverse languages, we use those upper bounds to quantify the lexicon's optimality and to explore the relative costs of major constraints on natural codes. We find that (compositional) morphology and graphotactics can sufficiently account for most of the complexity of natural codes -- as measured by code length.
Finding Concept-specific Biases in Form--Meaning Associations
Apr 29, 2021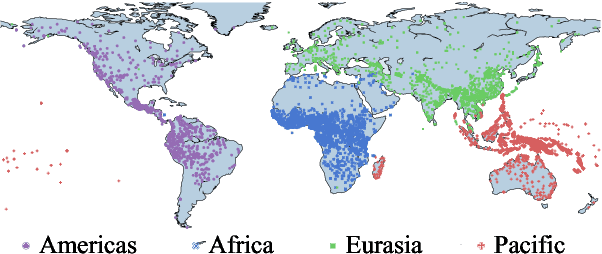
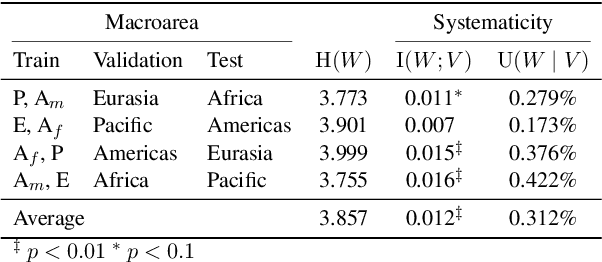
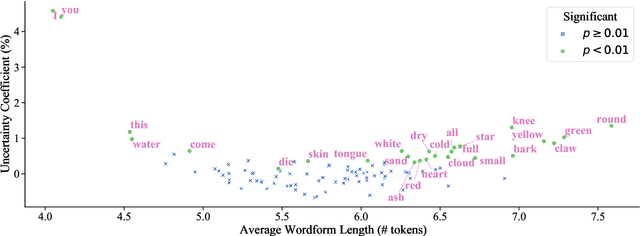
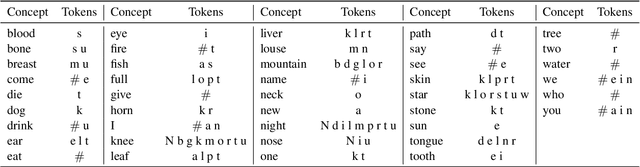
This work presents an information-theoretic operationalisation of cross-linguistic non-arbitrariness. It is not a new idea that there are small, cross-linguistic associations between the forms and meanings of words. For instance, it has been claimed (Blasi et al., 2016) that the word for "tongue" is more likely than chance to contain the phone [l]. By controlling for the influence of language family and geographic proximity within a very large concept-aligned, cross-lingual lexicon, we extend methods previously used to detect within language non-arbitrariness (Pimentel et al., 2019) to measure cross-linguistic associations. We find that there is a significant effect of non-arbitrariness, but it is unsurprisingly small (less than 0.5% on average according to our information-theoretic estimate). We also provide a concept-level analysis which shows that a quarter of the concepts considered in our work exhibit a significant level of cross-linguistic non-arbitrariness. In sum, the paper provides new methods to detect cross-linguistic associations at scale, and confirms their effects are minor.
Quantifying Gender Bias Towards Politicians in Cross-Lingual Language Models
Apr 15, 2021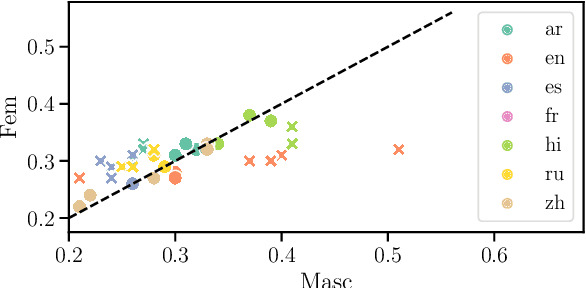
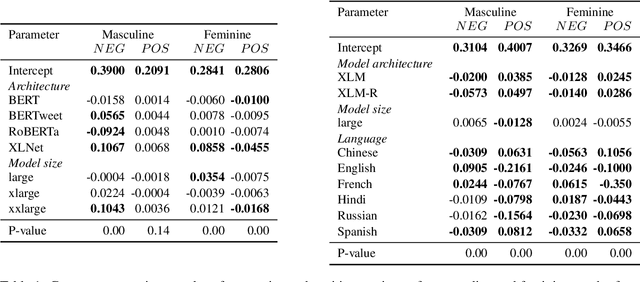
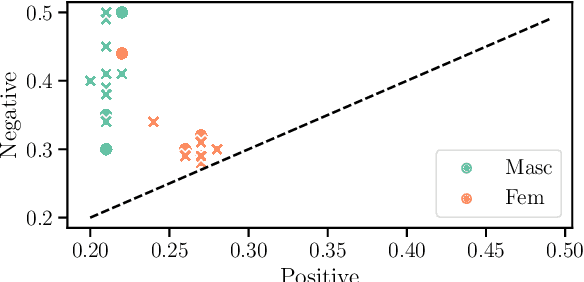

While the prevalence of large pre-trained language models has led to significant improvements in the performance of NLP systems, recent research has demonstrated that these models inherit societal biases extant in natural language. In this paper, we explore a simple method to probe pre-trained language models for gender bias, which we use to effect a multi-lingual study of gender bias towards politicians. We construct a dataset of 250k politicians from most countries in the world and quantify adjective and verb usage around those politicians' names as a function of their gender. We conduct our study in 7 languages across 6 different language modeling architectures. Our results demonstrate that stance towards politicians in pre-trained language models is highly dependent on the language used. Finally, contrary to previous findings, our study suggests that larger language models do not tend to be significantly more gender-biased than smaller ones.
Searching for Search Errors in Neural Morphological Inflection
Feb 16, 2021
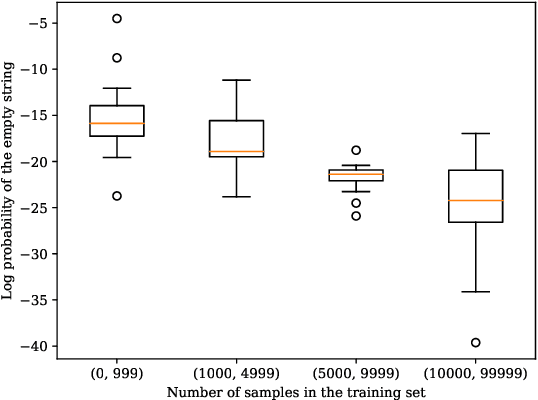

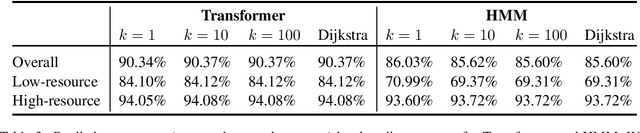
Neural sequence-to-sequence models are currently the predominant choice for language generation tasks. Yet, on word-level tasks, exact inference of these models reveals the empty string is often the global optimum. Prior works have speculated this phenomenon is a result of the inadequacy of neural models for language generation. However, in the case of morphological inflection, we find that the empty string is almost never the most probable solution under the model. Further, greedy search often finds the global optimum. These observations suggest that the poor calibration of many neural models may stem from characteristics of a specific subset of tasks rather than general ill-suitedness of such models for language generation.
Differentiable Generative Phonology
Feb 12, 2021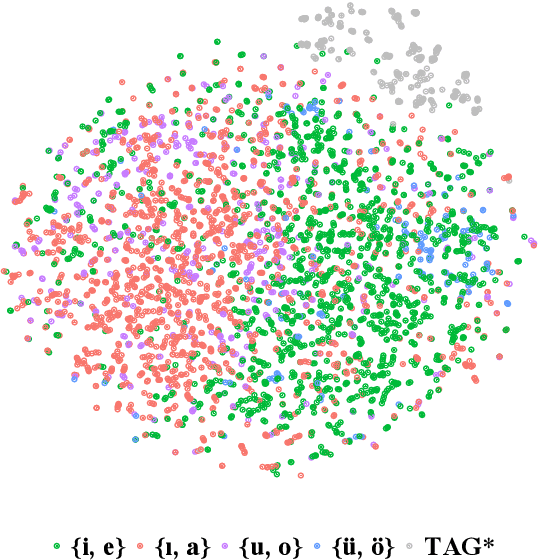
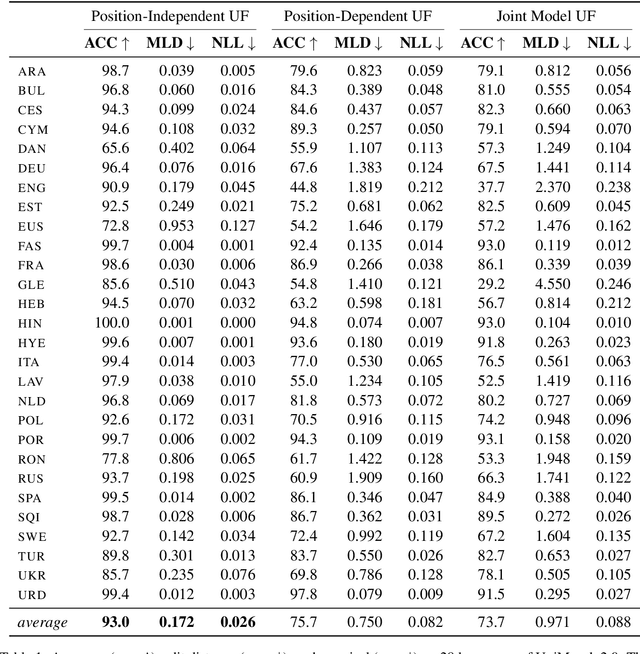
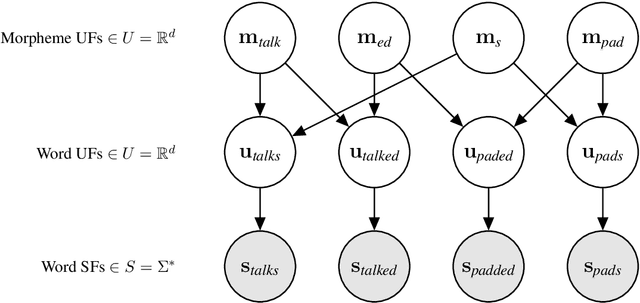
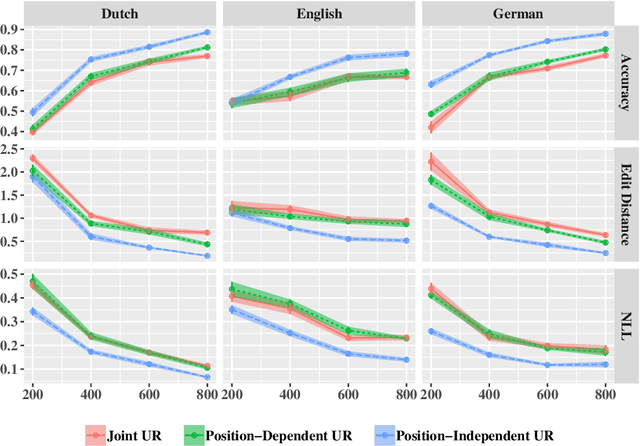
The goal of generative phonology, as formulated by Chomsky and Halle (1968), is to specify a formal system that explains the set of attested phonological strings in a language. Traditionally, a collection of rules (or constraints, in the case of optimality theory) and underlying forms (UF) are posited to work in tandem to generate phonological strings. However, the degree of abstraction of UFs with respect to their concrete realizations is contentious. As the main contribution of our work, we implement the phonological generative system as a neural model differentiable end-to-end, rather than as a set of rules or constraints. Contrary to traditional phonology, in our model, UFs are continuous vectors in $\mathbb{R}^d$, rather than discrete strings. As a consequence, UFs are discovered automatically rather than posited by linguists, and the model can scale to the size of a realistic vocabulary. Moreover, we compare several modes of the generative process, contemplating: i) the presence or absence of an underlying representation in between morphemes and surface forms (SFs); and ii) the conditional dependence or independence of UFs with respect to SFs. We evaluate the ability of each mode to predict attested phonological strings on 2 datasets covering 5 and 28 languages, respectively. The results corroborate two tenets of generative phonology, viz. the necessity for UFs and their independence from SFs. In general, our neural model of generative phonology learns both UFs and SFs automatically and on a large-scale.
Disambiguatory Signals are Stronger in Word-initial Positions
Feb 03, 2021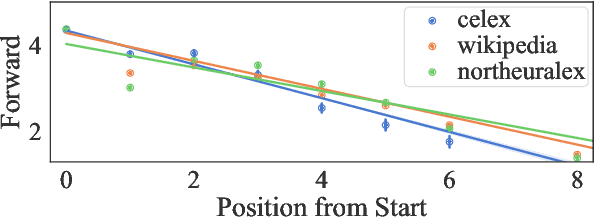
Psycholinguistic studies of human word processing and lexical access provide ample evidence of the preferred nature of word-initial versus word-final segments, e.g., in terms of attention paid by listeners (greater) or the likelihood of reduction by speakers (lower). This has led to the conjecture -- as in Wedel et al. (2019b), but common elsewhere -- that languages have evolved to provide more information earlier in words than later. Information-theoretic methods to establish such tendencies in lexicons have suffered from several methodological shortcomings that leave open the question of whether this high word-initial informativeness is actually a property of the lexicon or simply an artefact of the incremental nature of recognition. In this paper, we point out the confounds in existing methods for comparing the informativeness of segments early in the word versus later in the word, and present several new measures that avoid these confounds. When controlling for these confounds, we still find evidence across hundreds of languages that indeed there is a cross-linguistic tendency to front-load information in words.
Multimodal Pretraining Unmasked: Unifying the Vision and Language BERTs
Nov 30, 2020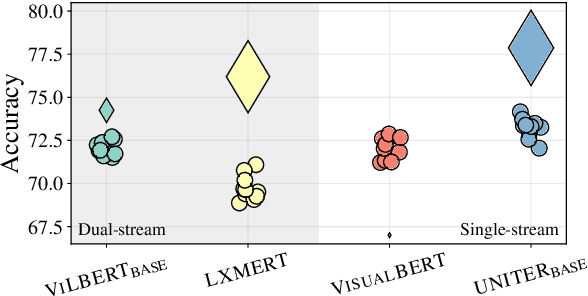
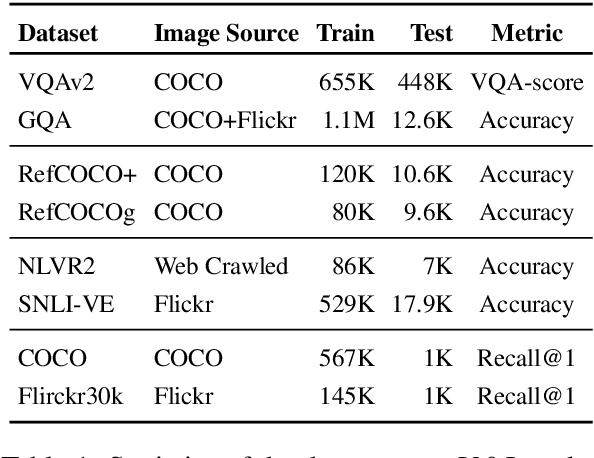
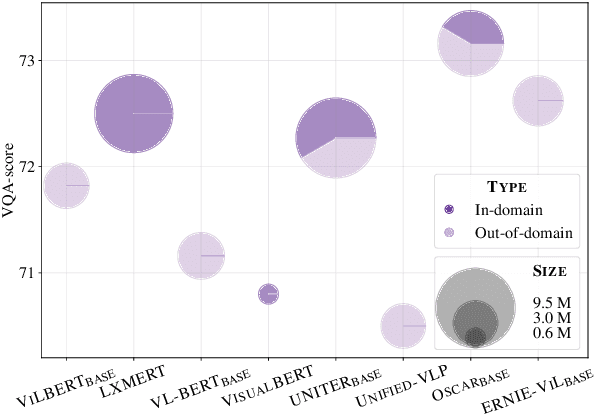
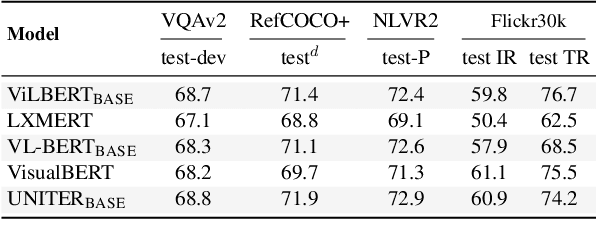
Large-scale pretraining and task-specific fine-tuning is now the standard methodology for many tasks in computer vision and natural language processing. Recently, a multitude of methods have been proposed for pretraining vision and language BERTs to tackle challenges at the intersection of these two key areas of AI. These models can be categorized into either single-stream or dual-stream encoders. We study the differences between these two categories, and show how they can be unified under a single theoretical framework. We then conduct controlled experiments to discern the empirical differences between five V&L BERTs. Our experiments show that training data and hyperparameters are responsible for most of the differences between the reported results, but they also reveal that the embedding layer plays a crucial role in these massive models.
Morphologically Aware Word-Level Translation
Nov 15, 2020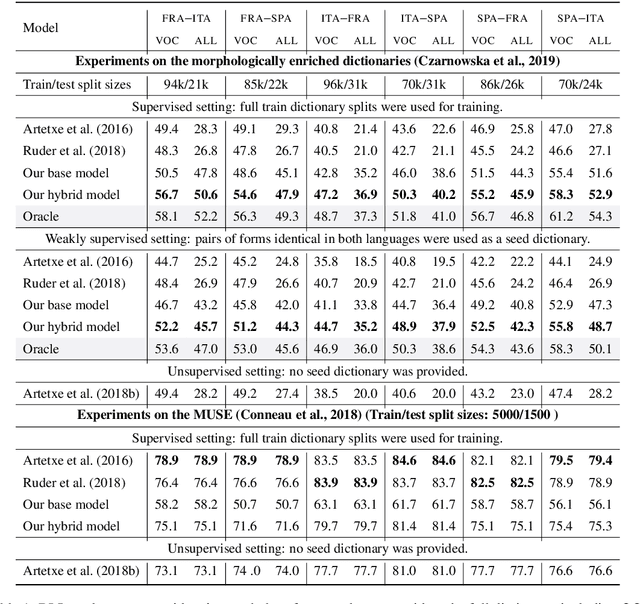
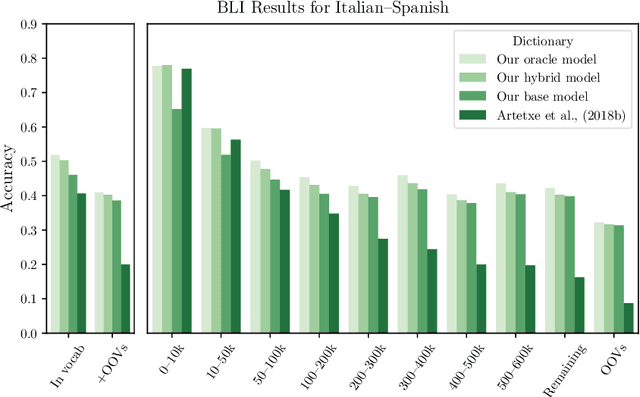
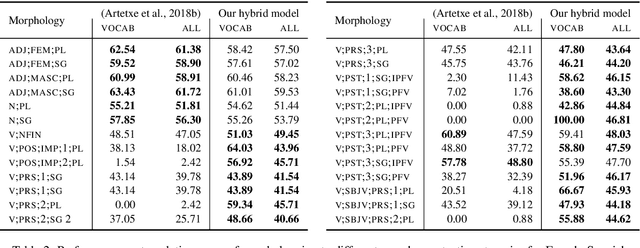
We propose a novel morphologically aware probability model for bilingual lexicon induction, which jointly models lexeme translation and inflectional morphology in a structured way. Our model exploits the basic linguistic intuition that the lexeme is the key lexical unit of meaning, while inflectional morphology provides additional syntactic information. This approach leads to substantial performance improvements - 19% average improvement in accuracy across 6 language pairs over the state of the art in the supervised setting and 16% in the weakly supervised setting. As another contribution, we highlight issues associated with modern BLI that stem from ignoring inflectional morphology, and propose three suggestions for improving the task.