 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSame Neurons, Different Languages: Probing Morphosyntax in Multilingual Pre-trained Models
May 08, 2022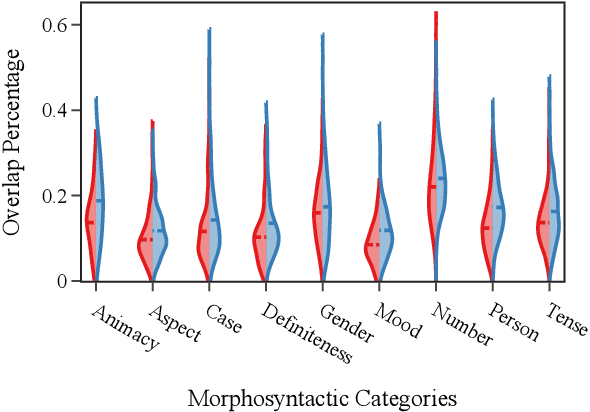
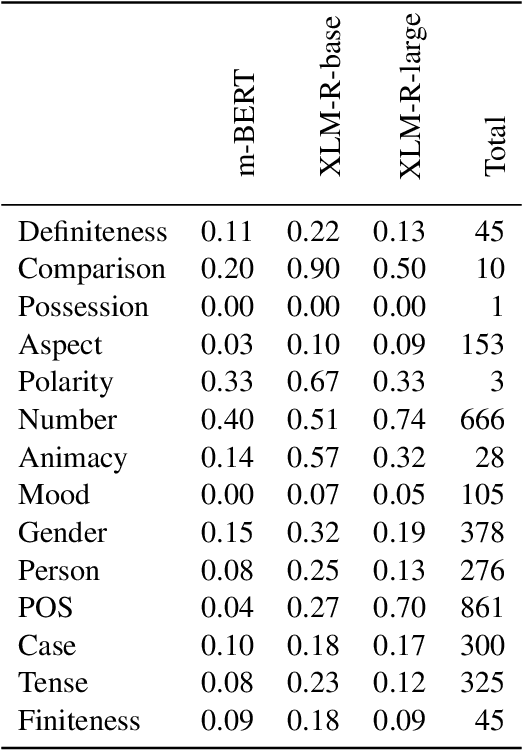
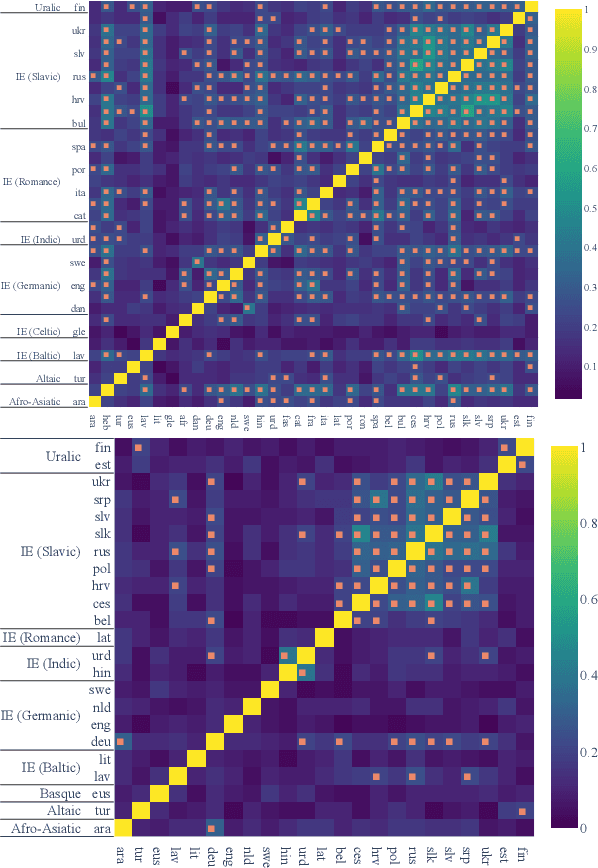
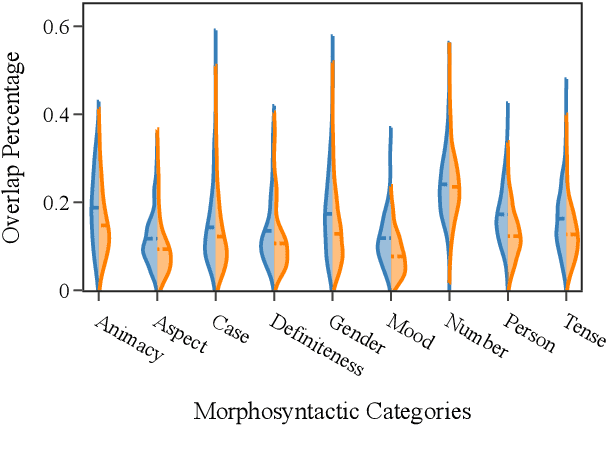
The success of multilingual pre-trained models is underpinned by their ability to learn representations shared by multiple languages even in absence of any explicit supervision. However, it remains unclear how these models learn to generalise across languages. In this work, we conjecture that multilingual pre-trained models can derive language-universal abstractions about grammar. In particular, we investigate whether morphosyntactic information is encoded in the same subset of neurons in different languages. We conduct the first large-scale empirical study over 43 languages and 14 morphosyntactic categories with a state-of-the-art neuron-level probe. Our findings show that the cross-lingual overlap between neurons is significant, but its extent may vary across categories and depends on language proximity and pre-training data size.
Exact Paired-Permutation Testing for Structured Test Statistics
May 04, 2022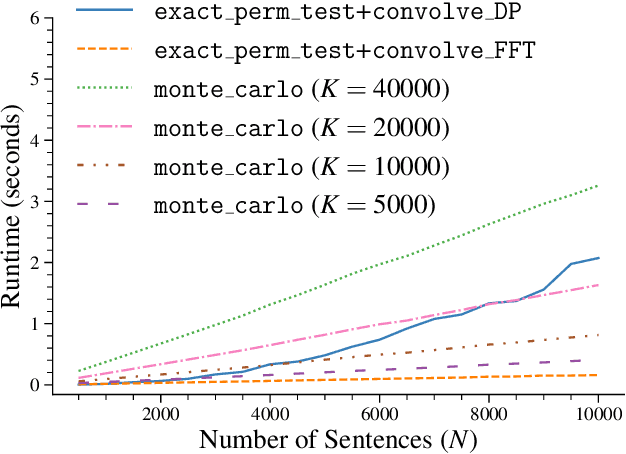
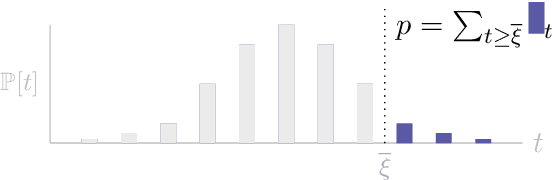
Significance testing -- especially the paired-permutation test -- has played a vital role in developing NLP systems to provide confidence that the difference in performance between two systems (i.e., the test statistic) is not due to luck. However, practitioners rely on Monte Carlo approximation to perform this test due to a lack of a suitable exact algorithm. In this paper, we provide an efficient exact algorithm for the paired-permutation test for a family of structured test statistics. Our algorithm runs in $\mathcal{O}(GN (\log GN )(\log N ))$ time where $N$ is the dataset size and $G$ is the range of the test statistic. We found that our exact algorithm was $10$x faster than the Monte Carlo approximation with $20000$ samples on a common dataset.
Probing for the Usage of Grammatical Number
Apr 21, 2022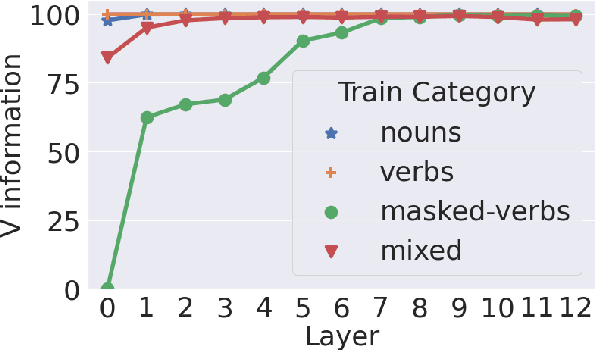
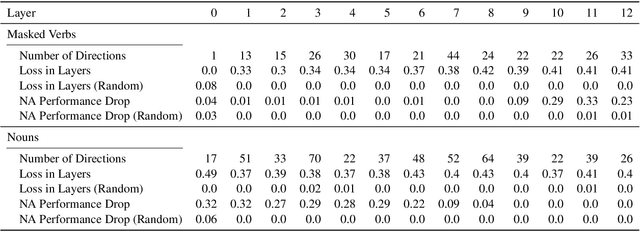
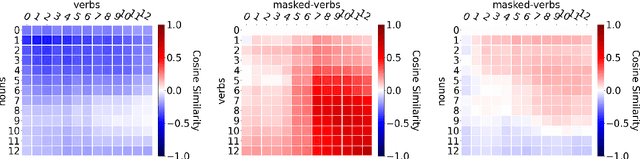
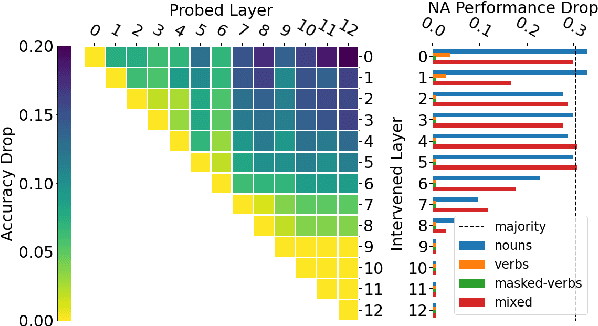
A central quest of probing is to uncover how pre-trained models encode a linguistic property within their representations. An encoding, however, might be spurious-i.e., the model might not rely on it when making predictions. In this paper, we try to find encodings that the model actually uses, introducing a usage-based probing setup. We first choose a behavioral task which cannot be solved without using the linguistic property. Then, we attempt to remove the property by intervening on the model's representations. We contend that, if an encoding is used by the model, its removal should harm the performance on the chosen behavioral task. As a case study, we focus on how BERT encodes grammatical number, and on how it uses this encoding to solve the number agreement task. Experimentally, we find that BERT relies on a linear encoding of grammatical number to produce the correct behavioral output. We also find that BERT uses a separate encoding of grammatical number for nouns and verbs. Finally, we identify in which layers information about grammatical number is transferred from a noun to its head verb.
Estimating the Entropy of Linguistic Distributions
Apr 05, 2022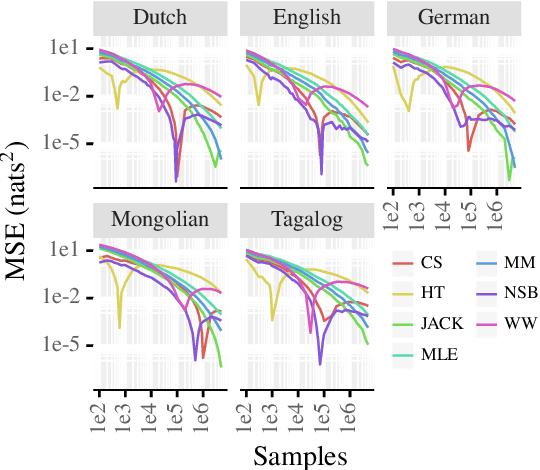
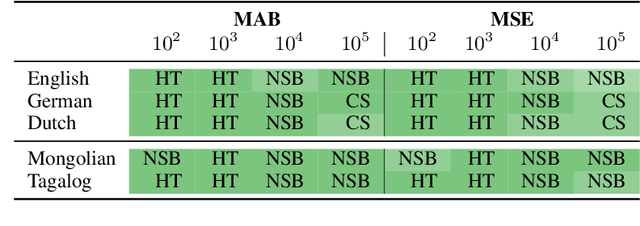
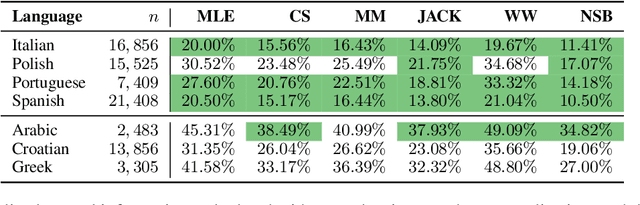
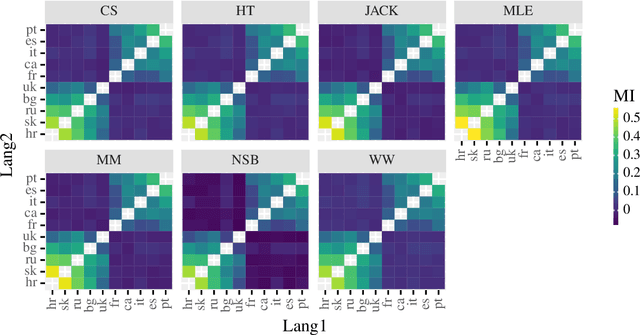
Shannon entropy is often a quantity of interest to linguists studying the communicative capacity of human language. However, entropy must typically be estimated from observed data because researchers do not have access to the underlying probability distribution that gives rise to these data. While entropy estimation is a well-studied problem in other fields, there is not yet a comprehensive exploration of the efficacy of entropy estimators for use with linguistic data. In this work, we fill this void, studying the empirical effectiveness of different entropy estimators for linguistic distributions. In a replication of two recent information-theoretic linguistic studies, we find evidence that the reported effect size is over-estimated due to over-reliance on poor entropy estimators. Finally, we end our paper with concrete recommendations for entropy estimation depending on distribution type and data availability.
On the probability-quality paradox in language generation
Mar 31, 2022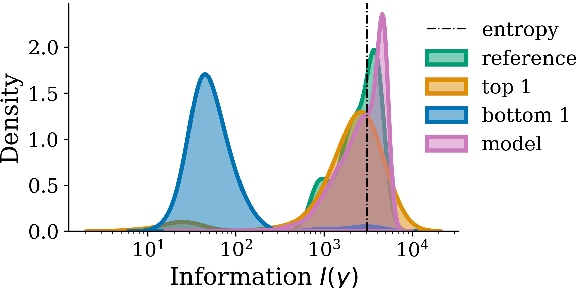
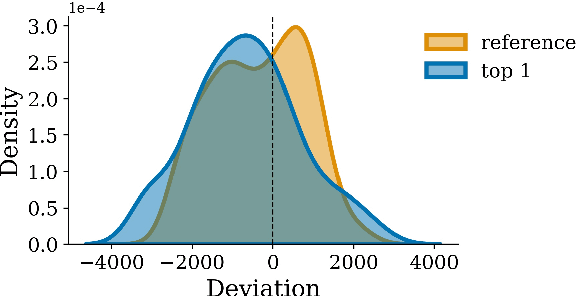
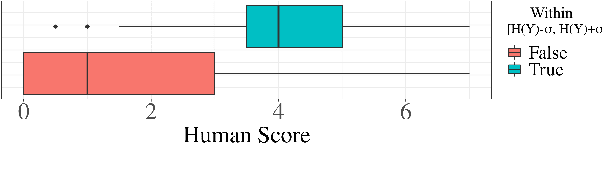
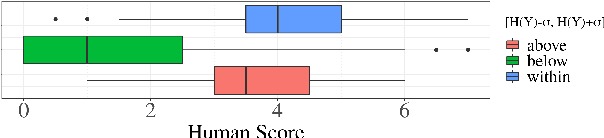
When generating natural language from neural probabilistic models, high probability does not always coincide with high quality: It has often been observed that mode-seeking decoding methods, i.e., those that produce high-probability text under the model, lead to unnatural language. On the other hand, the lower-probability text generated by stochastic methods is perceived as more human-like. In this note, we offer an explanation for this phenomenon by analyzing language generation through an information-theoretic lens. Specifically, we posit that human-like language should contain an amount of information (quantified as negative log-probability) that is close to the entropy of the distribution over natural strings. Further, we posit that language with substantially more (or less) information is undesirable. We provide preliminary empirical evidence in favor of this hypothesis; quality ratings of both human and machine-generated text -- covering multiple tasks and common decoding strategies -- suggest high-quality text has an information content significantly closer to the entropy than we would expect by chance.
Analyzing Wrap-Up Effects through an Information-Theoretic Lens
Mar 31, 2022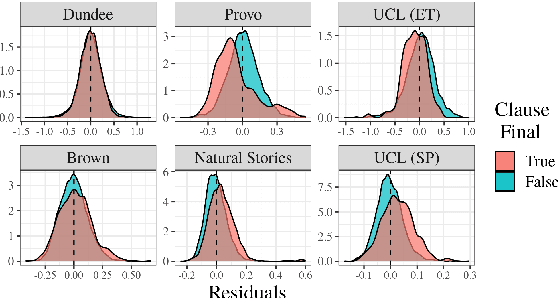
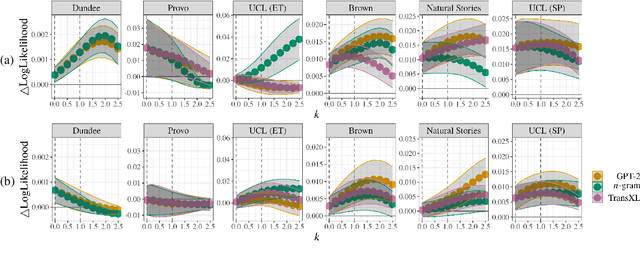
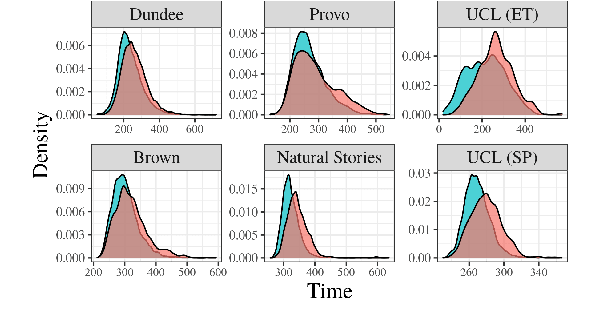
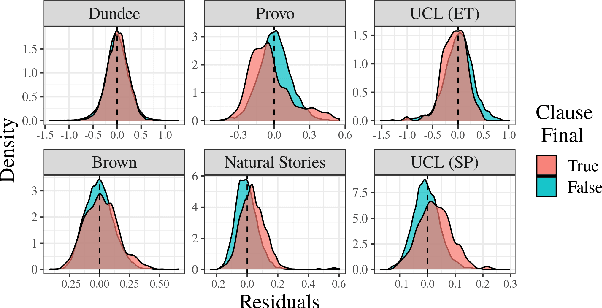
Numerous analyses of reading time (RT) data have been implemented -- all in an effort to better understand the cognitive processes driving reading comprehension. However, data measured on words at the end of a sentence -- or even at the end of a clause -- is often omitted due to the confounding factors introduced by so-called "wrap-up effects," which manifests as a skewed distribution of RTs for these words. Consequently, the understanding of the cognitive processes that might be involved in these wrap-up effects is limited. In this work, we attempt to learn more about these processes by examining the relationship between wrap-up effects and information-theoretic quantities, such as word and context surprisals. We find that the distribution of information in prior contexts is often predictive of sentence- and clause-final RTs (while not of sentence-medial RTs). This lends support to several prior hypotheses about the processes involved in wrap-up effects.
On Decoding Strategies for Neural Text Generators
Mar 29, 2022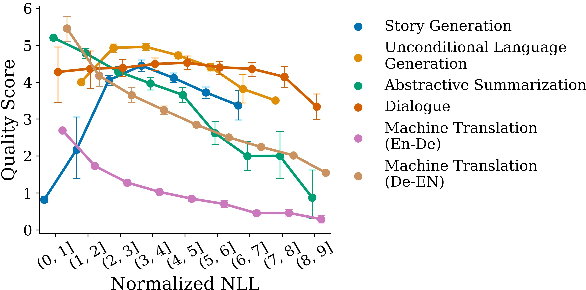

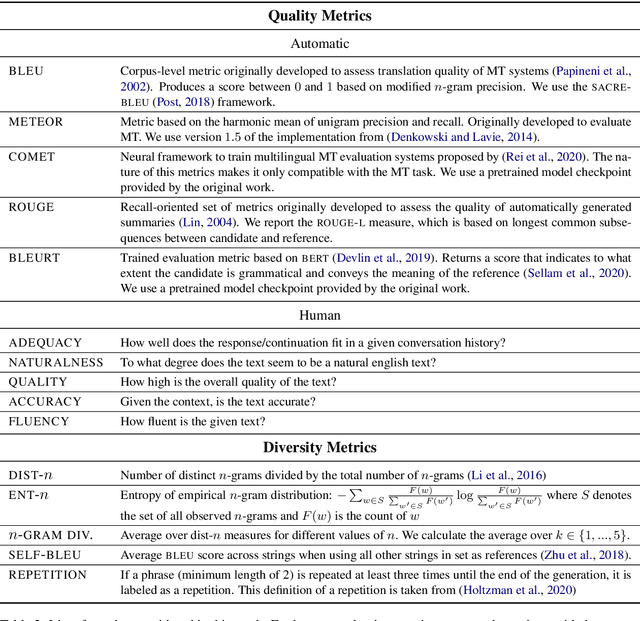
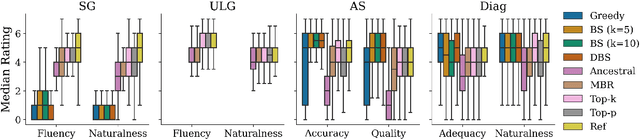
When generating text from probabilistic models, the chosen decoding strategy has a profound effect on the resulting text. Yet the properties elicited by various decoding strategies do not always transfer across natural language generation tasks. For example, while mode-seeking methods like beam search perform remarkably well for machine translation, they have been observed to lead to incoherent and repetitive text in story generation. Despite such observations, the effectiveness of decoding strategies is often assessed with respect to only a single task. This work -- in contrast -- provides a comprehensive analysis of the interaction between language generation tasks and decoding strategies. Specifically, we measure changes in attributes of generated text as a function of both decoding strategy and task using human and automatic evaluation. Our results reveal both previously-observed and surprising findings. For example, the nature of the diversity-quality trade-off in language generation is very task-specific; the length bias often attributed to beam search is not constant across tasks.
Typical Decoding for Natural Language Generation
Feb 10, 2022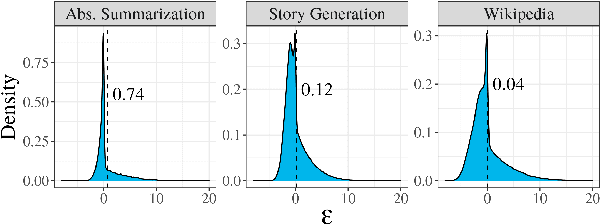
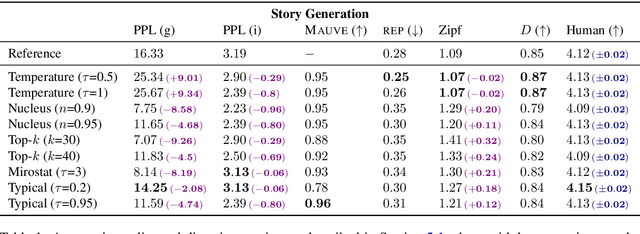
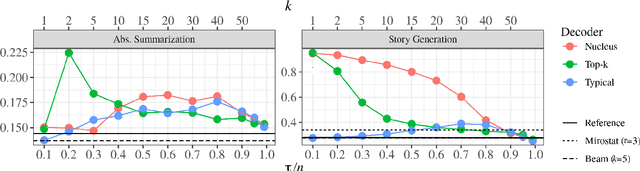
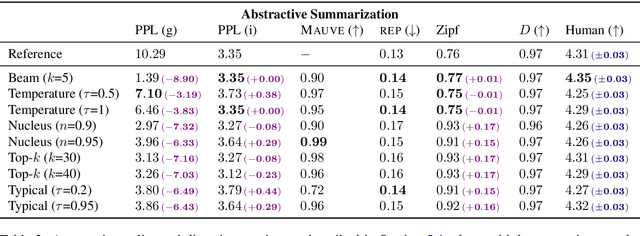
Despite achieving incredibly low perplexities on myriad natural language corpora, today's language models still often underperform when used to generate text. This dichotomy has puzzled the language generation community for the last few years. In this work, we posit that the abstraction of natural language as a communication channel (\`a la Shannon, 1948) can provide new insights into the behaviors of probabilistic language generators, e.g., why high-probability texts can be dull or repetitive. Humans use language as a means of communicating information, and do so in an efficient yet error-minimizing manner, choosing each word in a string with this (perhaps subconscious) goal in mind. We propose that generation from probabilistic models should mimic this behavior. Rather than always choosing words from the high-probability region of the distribution--which have a low Shannon information content--we sample from the set of words with an information content close to its expected value, i.e., close to the conditional entropy of our model. This decision criterion can be realized through a simple and efficient implementation, which we call typical sampling. Automatic and human evaluations show that, in comparison to nucleus and top-k sampling, typical sampling offers competitive performance in terms of quality while consistently reducing the number of degenerate repetitions.
Adversarial Concept Erasure in Kernel Space
Jan 28, 2022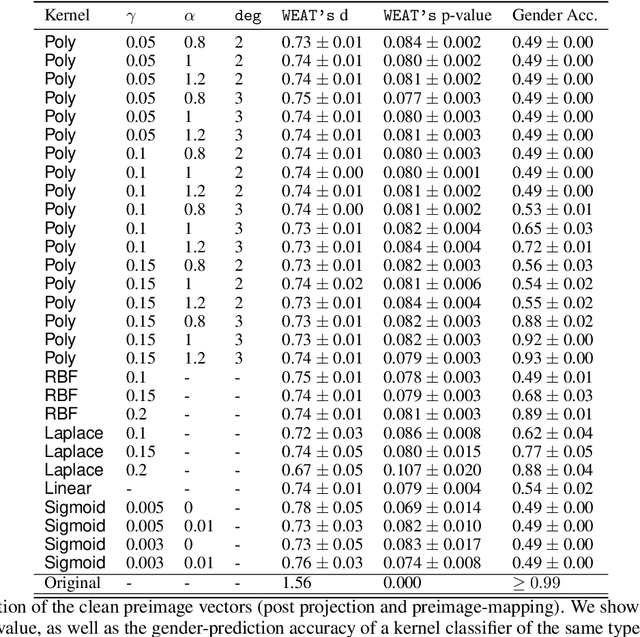
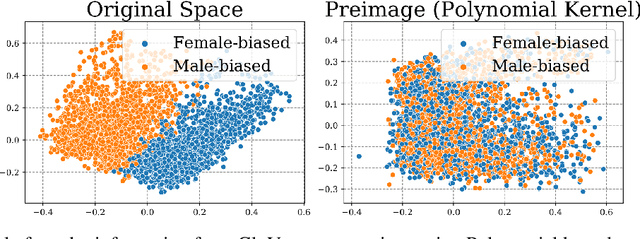

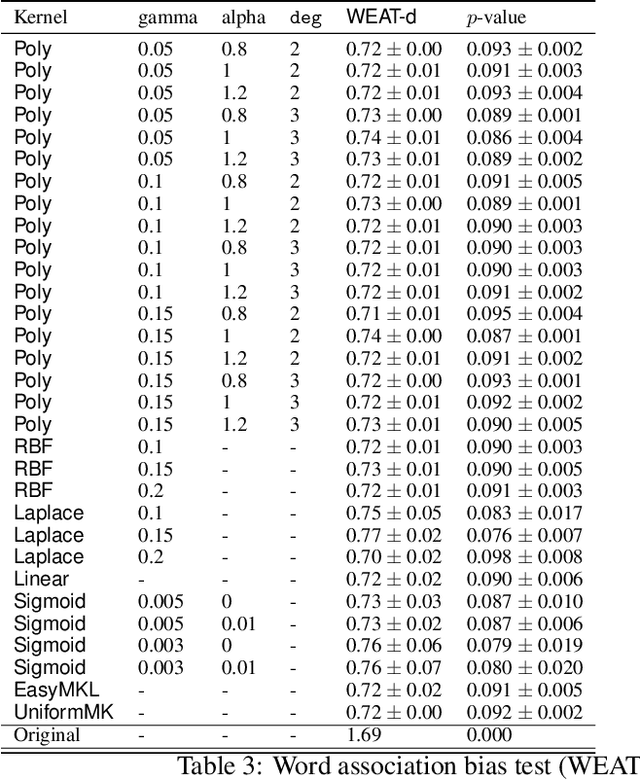
The representation space of neural models for textual data emerges in an unsupervised manner during training. Understanding how human-interpretable concepts, such as gender, are encoded in these representations would improve the ability of users to \emph{control} the content of these representations and analyze the working of the models that rely on them. One prominent approach to the control problem is the identification and removal of linear concept subspaces -- subspaces in the representation space that correspond to a given concept. While those are tractable and interpretable, neural network do not necessarily represent concepts in linear subspaces. We propose a kernalization of the linear concept-removal objective of [Ravfogel et al. 2022], and show that it is effective in guarding against the ability of certain nonlinear adversaries to recover the concept. Interestingly, our findings suggest that the division between linear and nonlinear models is overly simplistic: when considering the concept of binary gender and its neutralization, we do not find a single kernel space that exclusively contains all the concept-related information. It is therefore challenging to protect against \emph{all} nonlinear adversaries at once.
Linear Adversarial Concept Erasure
Jan 28, 2022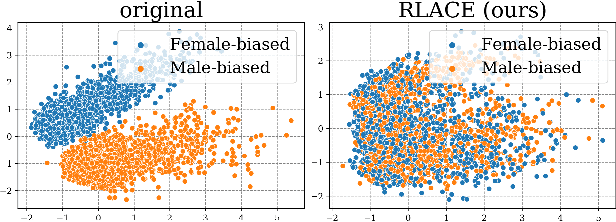
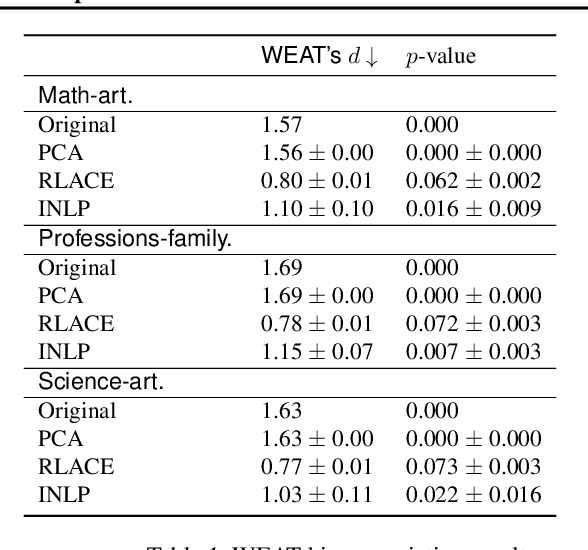
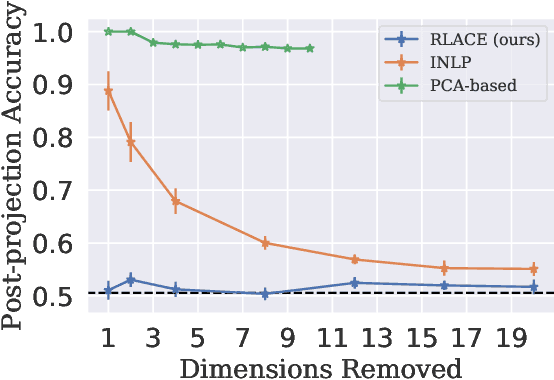
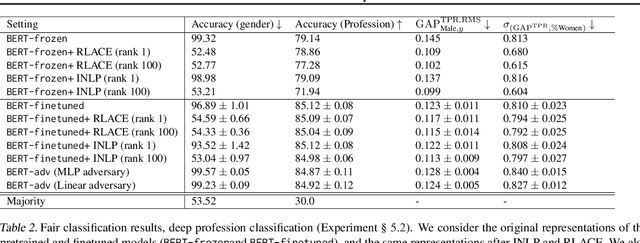
Modern neural models trained on textual data rely on pre-trained representations that emerge without direct supervision. As these representations are increasingly being used in real-world applications, the inability to \emph{control} their content becomes an increasingly important problem. We formulate the problem of identifying and erasing a linear subspace that corresponds to a given concept, in order to prevent linear predictors from recovering the concept. We model this problem as a constrained, linear minimax game, and show that existing solutions are generally not optimal for this task. We derive a closed-form solution for certain objectives, and propose a convex relaxation, R-LACE, that works well for others. When evaluated in the context of binary gender removal, the method recovers a low-dimensional subspace whose removal mitigates bias by intrinsic and extrinsic evaluation. We show that the method -- despite being linear -- is highly expressive, effectively mitigating bias in deep nonlinear classifiers while maintaining tractability and interpretability.