 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generic Approach for Escaping Saddle points
Sep 05, 2017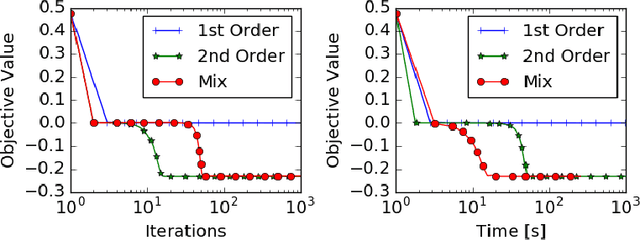
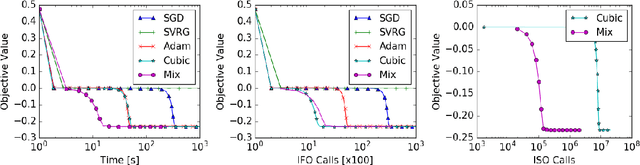

A central challenge to using first-order methods for optimizing nonconvex problems is the presence of saddle points. First-order methods often get stuck at saddle points, greatly deteriorating their performance. Typically, to escape from saddles one has to use second-order methods. However, most works on second-order methods rely extensively on expensive Hessian-based computations, making them impractical in large-scale settings. To tackle this challenge, we introduce a generic framework that minimizes Hessian based computations while at the same time provably converging to second-order critical points. Our framework carefully alternates between a first-order and a second-order subroutine, using the latter only close to saddle points, and yields convergence results competitive to the state-of-the-art. Empirical results suggest that our strategy also enjoys a good practical performance.
Spatially Adaptive Computation Time for Residual Networks
Jul 02, 2017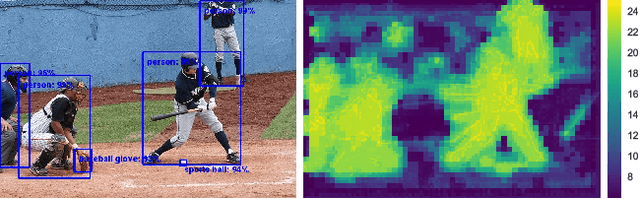
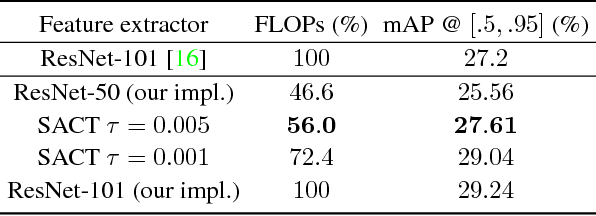
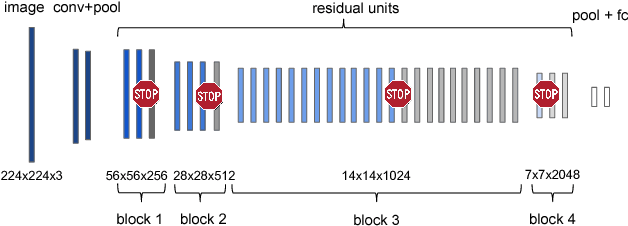

This paper proposes a deep learning architecture based on Residual Network that dynamically adjusts the number of executed layers for the regions of the image. This architecture is end-to-end trainable, deterministic and problem-agnostic. It is therefore applicable without any modifications to a wide range of computer vision problems such as image classification, object detection and image segmentation. We present experimental results showing that this model improves the computational efficiency of Residual Networks on the challenging ImageNet classification and COCO object detection datasets. Additionally, we evaluate the computation time maps on the visual saliency dataset cat2000 and find that they correlate surprisingly well with human eye fixation positions.
Improved Variational Autoencoders for Text Modeling using Dilated Convolutions
Jun 18, 2017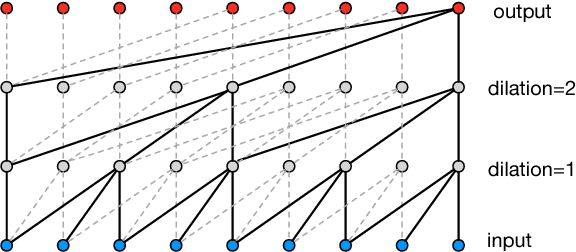
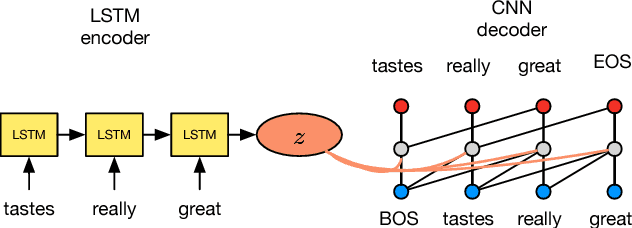
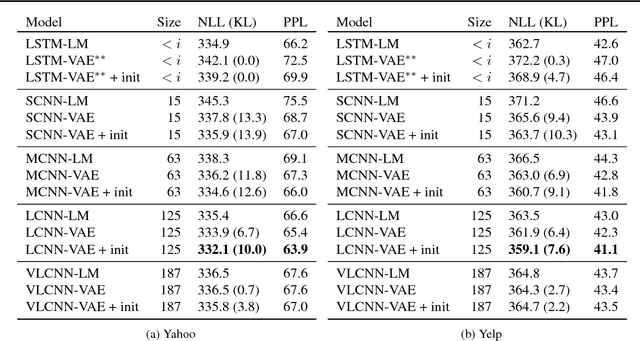
Recent work on generative modeling of text has found that variational auto-encoders (VAE) incorporating LSTM decoders perform worse than simpler LSTM language models (Bowman et al., 2015). This negative result is so far poorly understood, but has been attributed to the propensity of LSTM decoders to ignore conditioning information from the encoder. In this paper, we experiment with a new type of decoder for VAE: a dilated CNN. By changing the decoder's dilation architecture, we control the effective context from previously generated words. In experiments, we find that there is a trade off between the contextual capacity of the decoder and the amount of encoding information used. We show that with the right decoder, VAE can outperform LSTM language models. We demonstrate perplexity gains on two datasets, representing the first positive experimental result on the use VAE for generative modeling of text. Further, we conduct an in-depth investigation of the use of VAE (with our new decoding architecture) for semi-supervised and unsupervised labeling tasks, demonstrating gains over several strong baselines.
On the Quantitative Analysis of Decoder-Based Generative Models
Jun 06, 2017
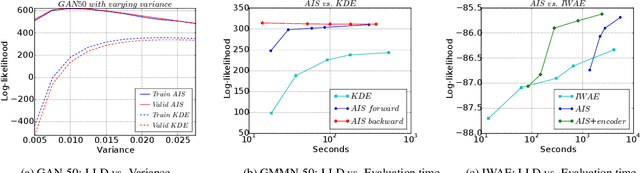
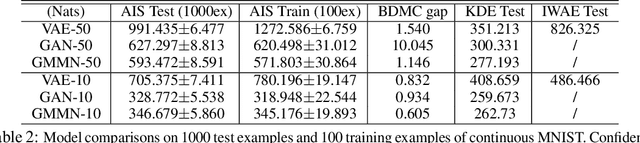
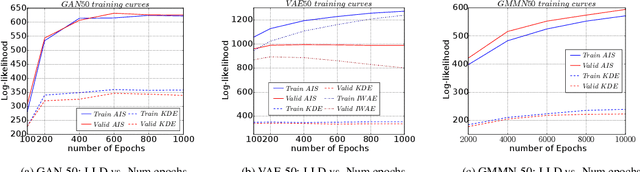
The past several years have seen remarkable progress in generative models which produce convincing samples of images and other modalities. A shared component of many powerful generative models is a decoder network, a parametric deep neural net that defines a generative distribution. Examples include variational autoencoders, generative adversarial networks, and generative moment matching networks. Unfortunately, it can be difficult to quantify the performance of these models because of the intractability of log-likelihood estimation, and inspecting samples can be misleading. We propose to use Annealed Importance Sampling for evaluating log-likelihoods for decoder-based models and validate its accuracy using bidirectional Monte Carlo. The evaluation code is provided at https://github.com/tonywu95/eval_gen. Using this technique, we analyze the performance of decoder-based models, the effectiveness of existing log-likelihood estimators, the degree of overfitting, and the degree to which these models miss important modes of the data distribution.
Geometry of Optimization and Implicit Regularization in Deep Learning
May 08, 2017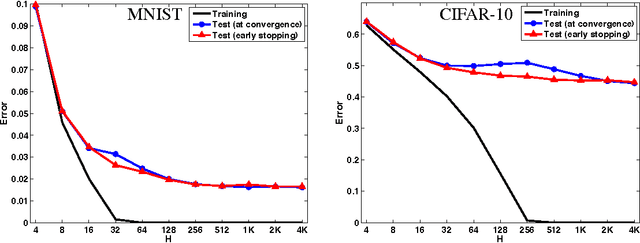
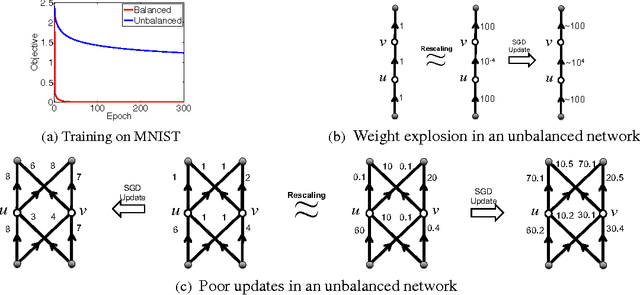
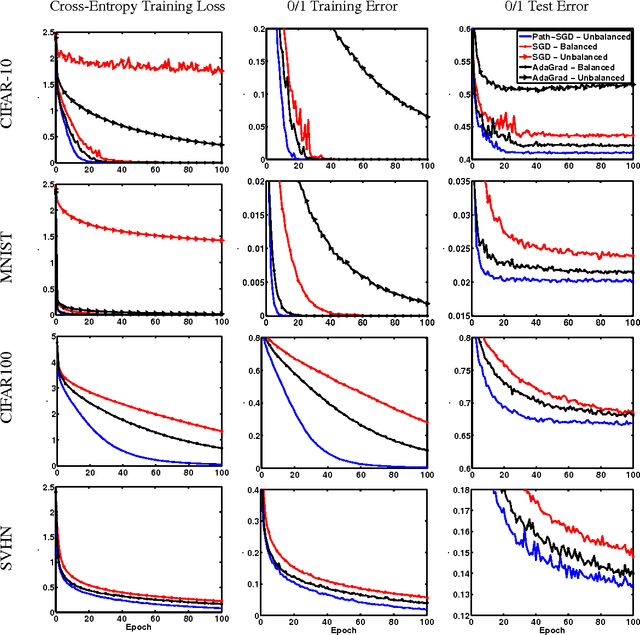
We argue that the optimization plays a crucial role in generalization of deep learning models through implicit regularization. We do this by demonstrating that generalization ability is not controlled by network size but rather by some other implicit control. We then demonstrate how changing the empirical optimization procedure can improve generalization, even if actual optimization quality is not affected. We do so by studying the geometry of the parameter space of deep networks, and devising an optimization algorithm attuned to this geometry.
Semi-Supervised QA with Generative Domain-Adaptive Nets
Apr 22, 2017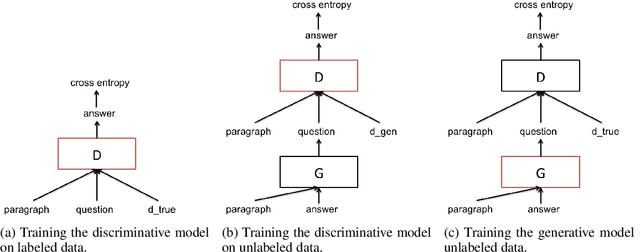
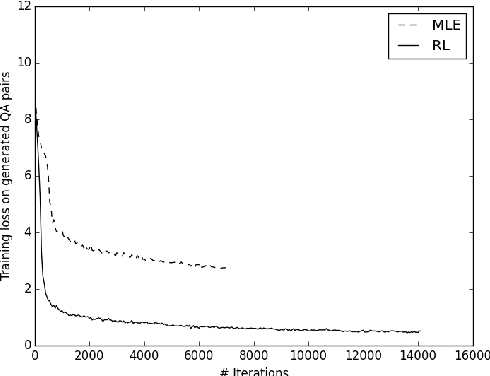
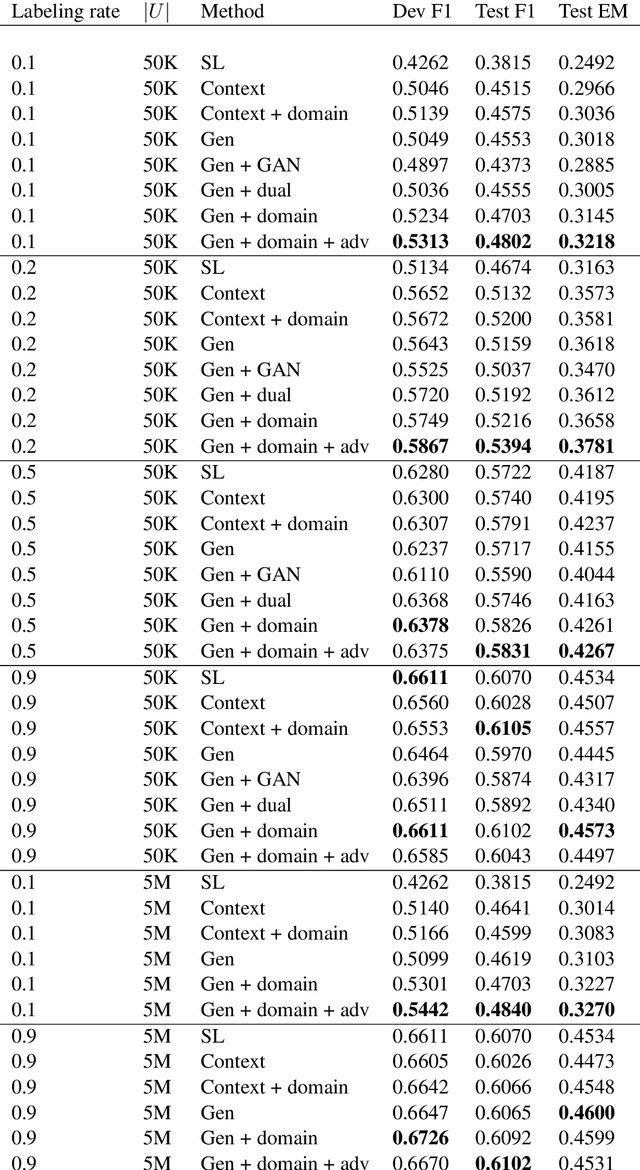
We study the problem of semi-supervised question answering----utilizing unlabeled text to boost the performance of question answering models. We propose a novel training framework, the Generative Domain-Adaptive Nets. In this framework, we train a generative model to generate questions based on the unlabeled text, and combine model-generated questions with human-generated questions for training question answering models. We develop novel domain adaptation algorithms, based on reinforcement learning, to alleviate the discrepancy between the model-generated data distribution and the human-generated data distribution. Experiments show that our proposed framework obtains substantial improvement from unlabeled text.
The More You Know: Using Knowledge Graphs for Image Classification
Apr 22, 2017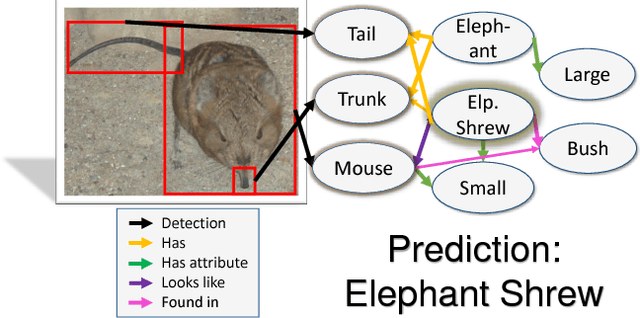
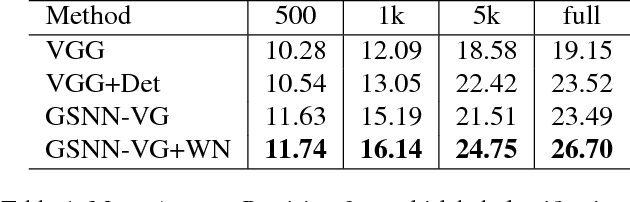
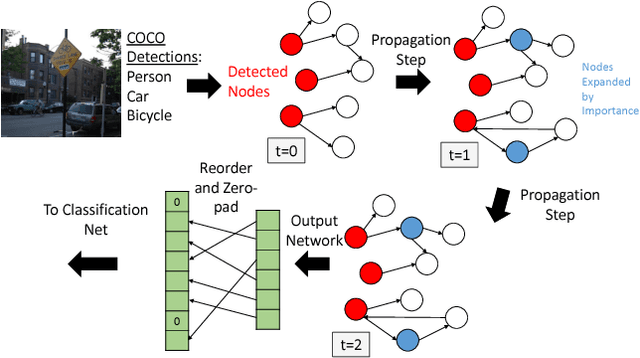
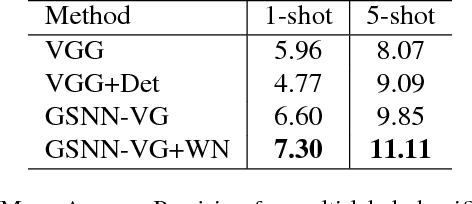
One characteristic that sets humans apart from modern learning-based computer vision algorithms is the ability to acquire knowledge about the world and use that knowledge to reason about the visual world. Humans can learn about the characteristics of objects and the relationships that occur between them to learn a large variety of visual concepts, often with few examples. This paper investigates the use of structured prior knowledge in the form of knowledge graphs and shows that using this knowledge improves performance on image classification. We build on recent work on end-to-end learning on graphs, introducing the Graph Search Neural Network as a way of efficiently incorporating large knowledge graphs into a vision classification pipeline. We show in a number of experiments that our method outperforms standard neural network baselines for multi-label classification.
Gated-Attention Readers for Text Comprehension
Apr 21, 2017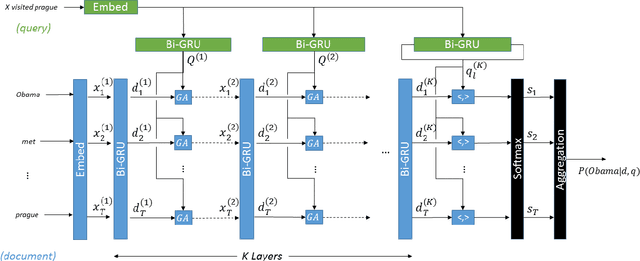
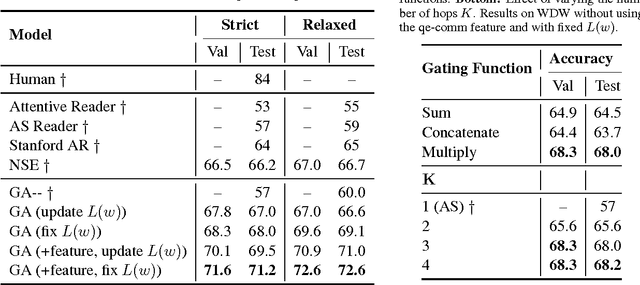
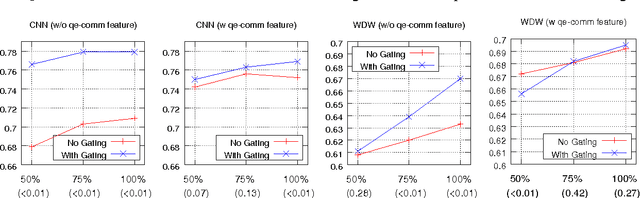
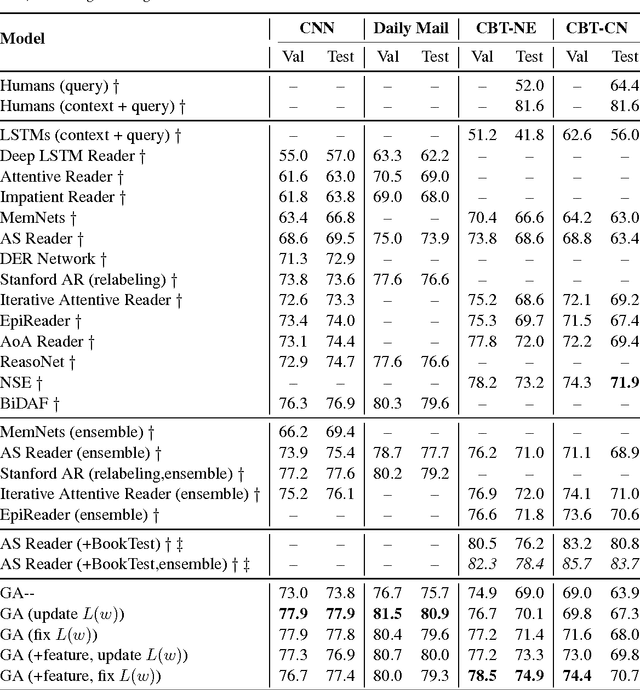
In this paper we study the problem of answering cloze-style questions over documents. Our model, the Gated-Attention (GA) Reader, integrates a multi-hop architecture with a novel attention mechanism, which is based on multiplicative interactions between the query embedding and the intermediate states of a recurrent neural network document reader. This enables the reader to build query-specific representations of tokens in the document for accurate answer selection. The GA Reader obtains state-of-the-art results on three benchmarks for this task--the CNN \& Daily Mail news stories and the Who Did What dataset. The effectiveness of multiplicative interaction is demonstrated by an ablation study, and by comparing to alternative compositional operators for implementing the gated-attention. The code is available at https://github.com/bdhingra/ga-reader.
Question Answering from Unstructured Text by Retrieval and Comprehension
Mar 26, 2017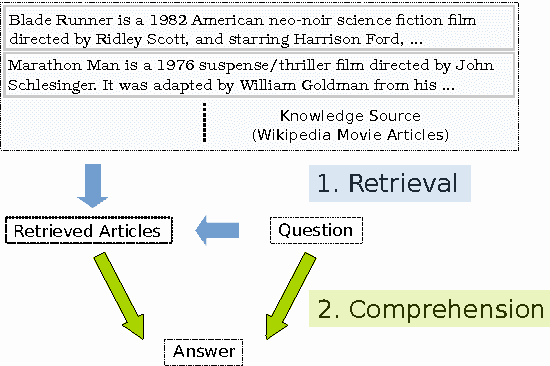



Open domain Question Answering (QA) systems must interact with external knowledge sources, such as web pages, to find relevant information. Information sources like Wikipedia, however, are not well structured and difficult to utilize in comparison with Knowledge Bases (KBs). In this work we present a two-step approach to question answering from unstructured text, consisting of a retrieval step and a comprehension step. For comprehension, we present an RNN based attention model with a novel mixture mechanism for selecting answers from either retrieved articles or a fixed vocabulary. For retrieval we introduce a hand-crafted model and a neural model for ranking relevant articles. We achieve state-of-the-art performance on W IKI M OVIES dataset, reducing the error by 40%. Our experimental results further demonstrate the importance of each of the introduced components.
Learning Robust Visual-Semantic Embeddings
Mar 20, 2017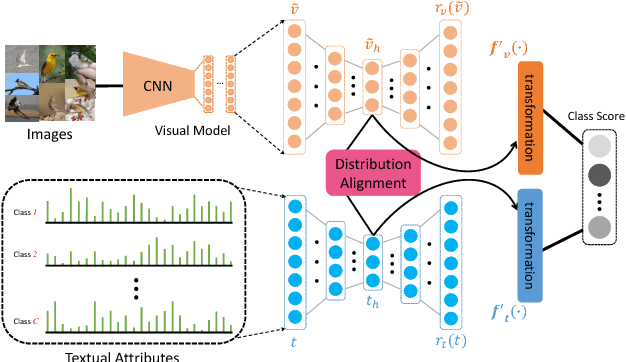
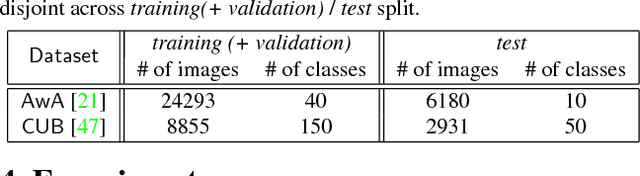
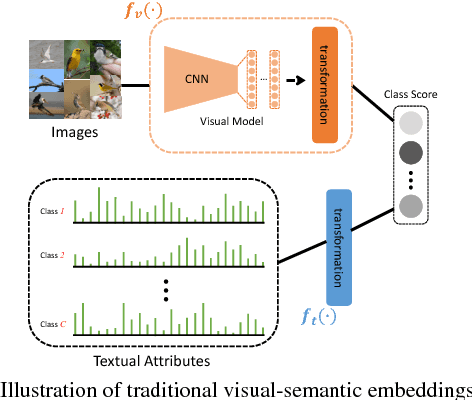
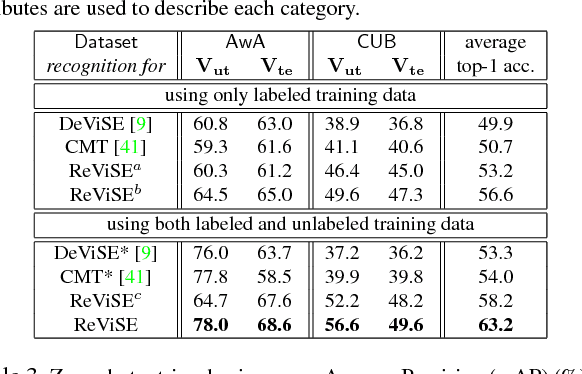
Many of the existing methods for learning joint embedding of images and text use only supervised information from paired images and its textual attributes. Taking advantage of the recent success of unsupervised learning in deep neural networks, we propose an end-to-end learning framework that is able to extract more robust multi-modal representations across domains. The proposed method combines representation learning models (i.e., auto-encoders) together with cross-domain learning criteria (i.e., Maximum Mean Discrepancy loss) to learn joint embeddings for semantic and visual features. A novel technique of unsupervised-data adaptation inference is introduced to construct more comprehensive embeddings for both labeled and unlabeled data. We evaluate our method on Animals with Attributes and Caltech-UCSD Birds 200-2011 dataset with a wide range of applications, including zero and few-shot image recognition and retrieval, from inductive to transductive settings. Empirically, we show that our framework improves over the current state of the art on many of the considered tasks.