 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning with Submodular Objective Functions
Oct 22, 2020
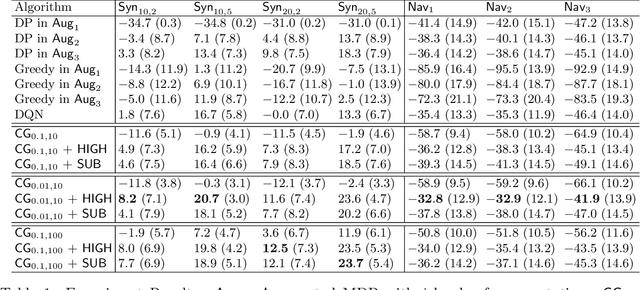

We study planning with submodular objective functions, where instead of maximizing the cumulative reward, the goal is to maximize the objective value induced by a submodular function. Our framework subsumes standard planning and submodular maximization with cardinality constraints as special cases, and thus many practical applications can be naturally formulated within our framework. Based on the notion of multilinear extension, we propose a novel and theoretically principled algorithmic framework for planning with submodular objective functions, which recovers classical algorithms when applied to the two special cases mentioned above. Empirically, our approach significantly outperforms baseline algorithms on synthetic environments and navigation tasks.
On Reward-Free Reinforcement Learning with Linear Function Approximation
Jun 19, 2020
Reward-free reinforcement learning (RL) is a framework which is suitable for both the batch RL setting and the setting where there are many reward functions of interest. During the exploration phase, an agent collects samples without using a pre-specified reward function. After the exploration phase, a reward function is given, and the agent uses samples collected during the exploration phase to compute a near-optimal policy. Jin et al. [2020] showed that in the tabular setting, the agent only needs to collect polynomial number of samples (in terms of the number states, the number of actions, and the planning horizon) for reward-free RL. However, in practice, the number of states and actions can be large, and thus function approximation schemes are required for generalization. In this work, we give both positive and negative results for reward-free RL with linear function approximation. We give an algorithm for reward-free RL in the linear Markov decision process setting where both the transition and the reward admit linear representations. The sample complexity of our algorithm is polynomial in the feature dimension and the planning horizon, and is completely independent of the number of states and actions. We further give an exponential lower bound for reward-free RL in the setting where only the optimal $Q$-function admits a linear representation. Our results imply several interesting exponential separations on the sample complexity of reward-free RL.
Reinforcement Learning with General Value Function Approximation: Provably Efficient Approach via Bounded Eluder Dimension
Jun 19, 2020Value function approximation has demonstrated phenomenal empirical success in reinforcement learning (RL). Nevertheless, despite a handful of recent progress on developing theory for RL with linear function approximation, the understanding of general function approximation schemes largely remains missing. In this paper, we establish a provably efficient RL algorithm with general value function approximation. We show that if the value functions admit an approximation with a function class $\mathcal{F}$, our algorithm achieves a regret bound of $\widetilde{O}(\mathrm{poly}(dH)\sqrt{T})$ where $d$ is a complexity measure of $\mathcal{F}$ that depends on the eluder dimension [Russo and Van Roy, 2013] and log-covering numbers, $H$ is the planning horizon, and $T$ is the number interactions with the environment. Our theory generalizes recent progress on RL with linear value function approximation and does not make explicit assumptions on the model of the environment. Moreover, our algorithm is model-free and provides a framework to justify the effectiveness of algorithms used in practice.
Preference-based Reinforcement Learning with Finite-Time Guarantees
Jun 16, 2020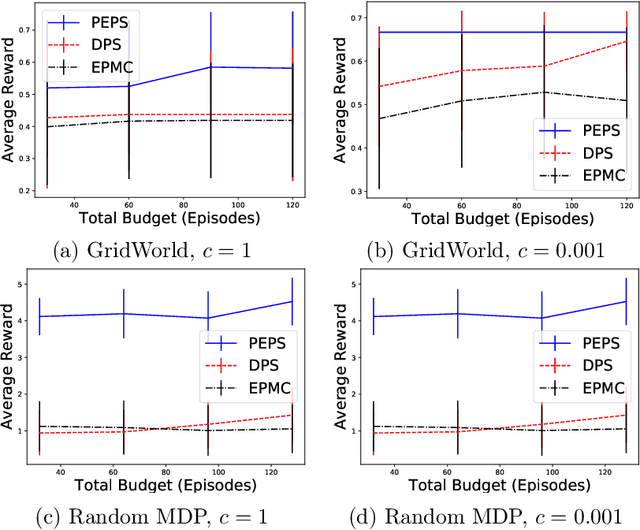
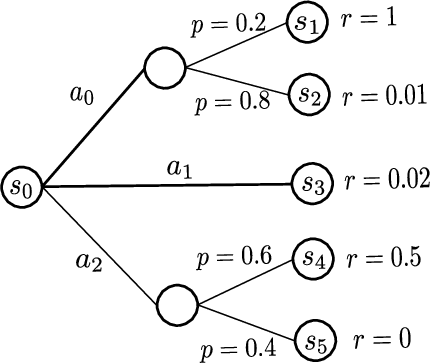
Preference-based Reinforcement Learning (PbRL) replaces reward values in traditional reinforcement learning by preferences to better elicit human opinion on the target objective, especially when numerical reward values are hard to design or interpret. Despite promising results in applications, the theoretical understanding of PbRL is still in its infancy. In this paper, we present the first finite-time analysis for general PbRL problems. We first show that a unique optimal policy may not exist if preferences over trajectories are deterministic for PbRL. If preferences are stochastic, and the preference probability relates to the hidden reward values, we present algorithms for PbRL, both with and without a simulator, that are able to identify the best policy up to accuracy $\varepsilon$ with high probability. Our method explores the state space by navigating to under-explored states, and solves PbRL using a combination of dueling bandits and policy search. Experiments show the efficacy of our method when it is applied to real-world problems.
Nearly Linear Row Sampling Algorithm for Quantile Regression
Jun 15, 2020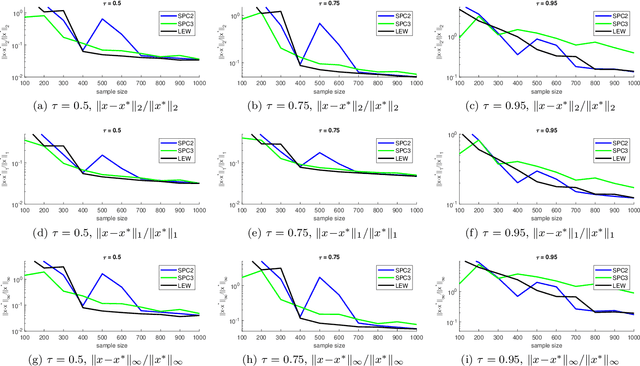
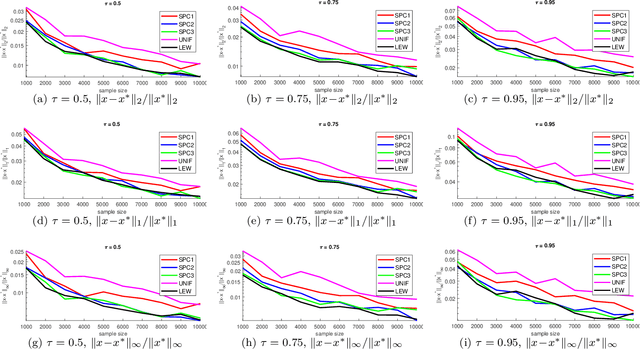
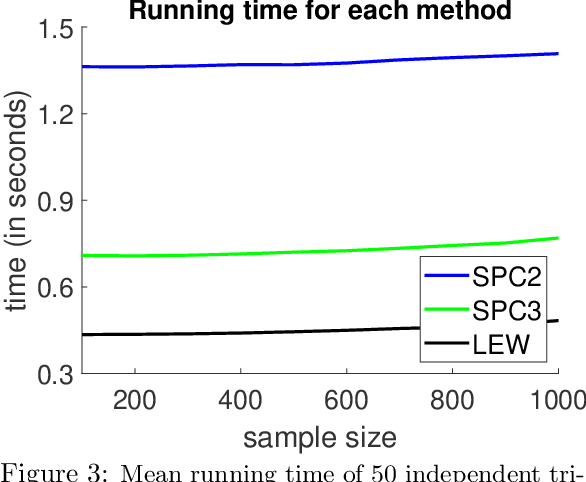
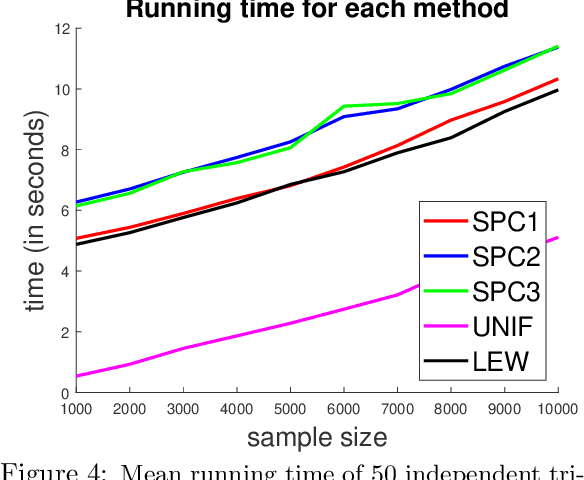
We give a row sampling algorithm for the quantile loss function with sample complexity nearly linear in the dimensionality of the data, improving upon the previous best algorithm whose sampling complexity has at least cubic dependence on the dimensionality. Based upon our row sampling algorithm, we give the fastest known algorithm for quantile regression and a graph sparsification algorithm for balanced directed graphs. Our main technical contribution is to show that Lewis weights sampling, which has been used in row sampling algorithms for $\ell_p$ norms, can also be applied in row sampling algorithms for a variety of loss functions. We complement our theoretical results by experiments to demonstrate the practicality of our approach.
Is Long Horizon Reinforcement Learning More Difficult Than Short Horizon Reinforcement Learning?
May 01, 2020Learning to plan for long horizons is a central challenge in episodic reinforcement learning problems. A fundamental question is to understand how the difficulty of the problem scales as the horizon increases. Here the natural measure of sample complexity is a normalized one: we are interested in the number of episodes it takes to provably discover a policy whose value is $\varepsilon$ near to that of the optimal value, where the value is measured by the normalized cumulative reward in each episode. In a COLT 2018 open problem, Jiang and Agarwal conjectured that, for tabular, episodic reinforcement learning problems, there exists a sample complexity lower bound which exhibits a polynomial dependence on the horizon -- a conjecture which is consistent with all known sample complexity upper bounds. This work refutes this conjecture, proving that tabular, episodic reinforcement learning is possible with a sample complexity that scales only logarithmically with the planning horizon. In other words, when the values are appropriately normalized (to lie in the unit interval), this results shows that long horizon RL is no more difficult than short horizon RL, at least in a minimax sense. Our analysis introduces two ideas: (i) the construction of an $\varepsilon$-net for optimal policies whose log-covering number scales only logarithmically with the planning horizon, and (ii) the Online Trajectory Synthesis algorithm, which adaptively evaluates all policies in a given policy class using sample complexity that scales with the log-covering number of the given policy class. Both may be of independent interest.
Provably Efficient Exploration for RL with Unsupervised Learning
Mar 15, 2020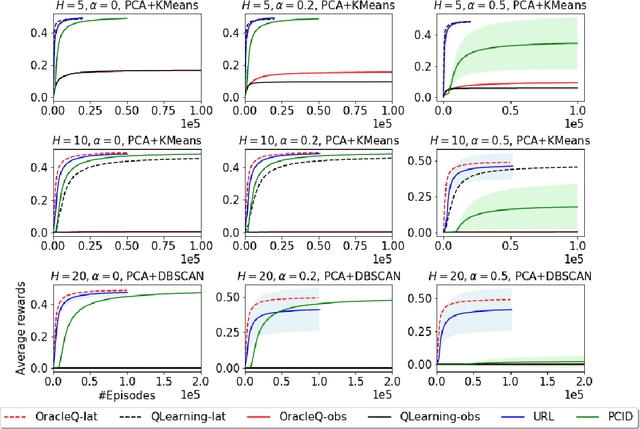
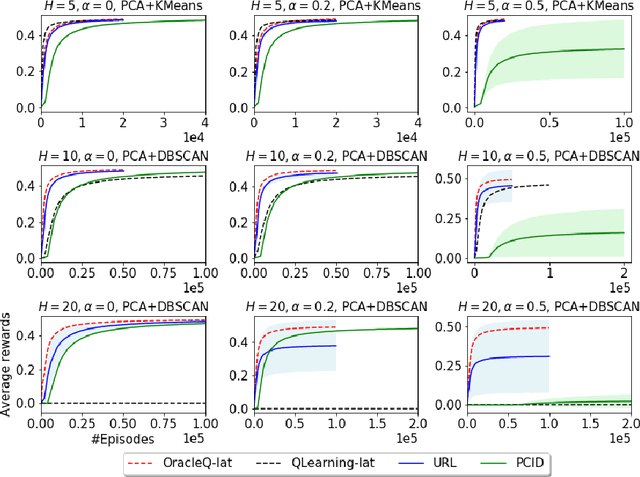
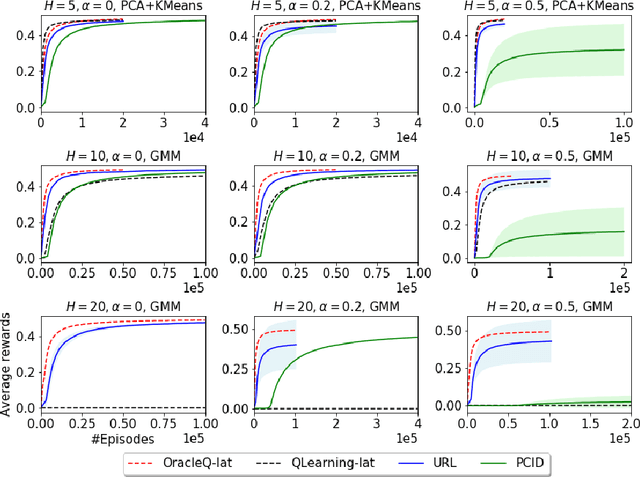
We study how to use unsupervised learning for efficient exploration in reinforcement learning with rich observations generated from a small number of latent states. We present a novel algorithmic framework that is built upon two components: an unsupervised learning algorithm and a no-regret reinforcement learning algorithm. We show that our algorithm provably finds a near-optimal policy with sample complexity polynomial in the number of latent states, which is significantly smaller than the number of possible observations. Our result gives theoretical justification to the prevailing paradigm of using unsupervised learning for efficient exploration [tang2017exploration,bellemare2016unifying].
Agnostic Q-learning with Function Approximation in Deterministic Systems: Tight Bounds on Approximation Error and Sample Complexity
Feb 17, 2020The current paper studies the problem of agnostic $Q$-learning with function approximation in deterministic systems where the optimal $Q$-function is approximable by a function in the class $\mathcal{F}$ with approximation error $\delta \ge 0$. We propose a novel recursion-based algorithm and show that if $\delta = O\left(\rho/\sqrt{\dim_E}\right)$, then one can find the optimal policy using $O\left(\dim_E\right)$ trajectories, where $\rho$ is the gap between the optimal $Q$-value of the best actions and that of the second-best actions and $\dim_E$ is the Eluder dimension of $\mathcal{F}$. Our result has two implications: 1) In conjunction with the lower bound in [Du et al., ICLR 2020], our upper bound suggests that the condition $\delta = \widetilde{\Theta}\left(\rho/\sqrt{\mathrm{dim}_E}\right)$ is necessary and sufficient for algorithms with polynomial sample complexity. 2) In conjunction with the lower bound in [Wen and Van Roy, NIPS 2013], our upper bound suggests that the sample complexity $\widetilde{\Theta}\left(\mathrm{dim}_E\right)$ is tight even in the agnostic setting. Therefore, we settle the open problem on agnostic $Q$-learning proposed in [Wen and Van Roy, NIPS 2013]. We further extend our algorithm to the stochastic reward setting and obtain similar results.
Optimism in Reinforcement Learning with Generalized Linear Function Approximation
Dec 09, 2019We design a new provably efficient algorithm for episodic reinforcement learning with generalized linear function approximation. We analyze the algorithm under a new expressivity assumption that we call "optimistic closure," which is strictly weaker than assumptions from prior analyses for the linear setting. With optimistic closure, we prove that our algorithm enjoys a regret bound of $\tilde{O}(\sqrt{d^3 T})$ where $d$ is the dimensionality of the state-action features and $T$ is the number of episodes. This is the first statistically and computationally efficient algorithm for reinforcement learning with generalized linear functions.
Enhanced Convolutional Neural Tangent Kernels
Nov 03, 2019
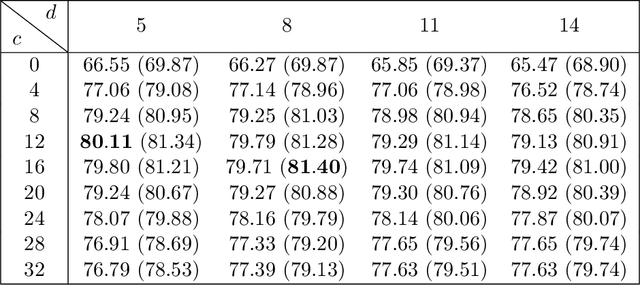
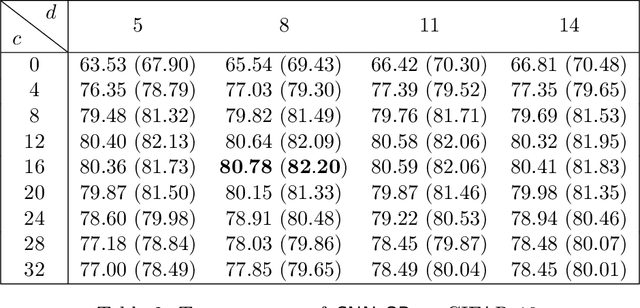
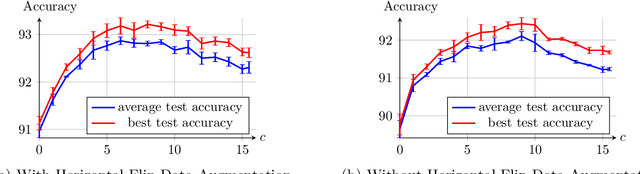
Recent research shows that for training with $\ell_2$ loss, convolutional neural networks (CNNs) whose width (number of channels in convolutional layers) goes to infinity correspond to regression with respect to the CNN Gaussian Process kernel (CNN-GP) if only the last layer is trained, and correspond to regression with respect to the Convolutional Neural Tangent Kernel (CNTK) if all layers are trained. An exact algorithm to compute CNTK (Arora et al., 2019) yielded the finding that classification accuracy of CNTK on CIFAR-10 is within 6-7% of that of that of the corresponding CNN architecture (best figure being around 78%) which is interesting performance for a fixed kernel. Here we show how to significantly enhance the performance of these kernels using two ideas. (1) Modifying the kernel using a new operation called Local Average Pooling (LAP) which preserves efficient computability of the kernel and inherits the spirit of standard data augmentation using pixel shifts. Earlier papers were unable to incorporate naive data augmentation because of the quadratic training cost of kernel regression. This idea is inspired by Global Average Pooling (GAP), which we show for CNN-GP and CNTK is equivalent to full translation data augmentation. (2) Representing the input image using a pre-processing technique proposed by Coates et al. (2011), which uses a single convolutional layer composed of random image patches. On CIFAR-10, the resulting kernel, CNN-GP with LAP and horizontal flip data augmentation, achieves 89% accuracy, matching the performance of AlexNet (Krizhevsky et al., 2012). Note that this is the best such result we know of for a classifier that is not a trained neural network. Similar improvements are obtained for Fashion-MNIST.