 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Dense, Not Long: Dynamic Decoupled Conditional Advantage for Efficient Reasoning
Feb 02, 2026Reinforcement Learning with Verifiable Rewards (RLVR) can elicit strong multi-step reasoning, yet it often encourages overly verbose traces. Moreover, naive length penalties in group-relative optimization can severely hurt accuracy. We attribute this failure to two structural issues: (i) Dilution of Length Baseline, where incorrect responses (with zero length reward) depress the group baseline and over-penalize correct solutions; and (ii) Difficulty-Penalty Mismatch, where a static penalty cannot adapt to problem difficulty, suppressing necessary reasoning on hard instances while leaving redundancy on easy ones. We propose Dynamic Decoupled Conditional Advantage (DDCA) to decouple efficiency optimization from correctness. DDCA computes length advantages conditionally within the correct-response cluster to eliminate baseline dilution, and dynamically scales the penalty strength using the group pass rate as a proxy for difficulty. Experiments on GSM8K, MATH500, AMC23, and AIME25 show that DDCA consistently improves the efficiency--accuracy trade-off relative to adaptive baselines, reducing generated tokens by approximately 60% on simpler tasks (e.g., GSM8K) versus over 20% on harder benchmarks (e.g., AIME25), thereby maintaining or improving accuracy. Code is available at https://github.com/alphadl/DDCA.
DSAEval: Evaluating Data Science Agents on a Wide Range of Real-World Data Science Problems
Jan 20, 2026Recent LLM-based data agents aim to automate data science tasks ranging from data analysis to deep learning. However, the open-ended nature of real-world data science problems, which often span multiple taxonomies and lack standard answers, poses a significant challenge for evaluation. To address this, we introduce DSAEval, a benchmark comprising 641 real-world data science problems grounded in 285 diverse datasets, covering both structured and unstructured data (e.g., vision and text). DSAEval incorporates three distinctive features: (1) Multimodal Environment Perception, which enables agents to interpret observations from multiple modalities including text and vision; (2) Multi-Query Interactions, which mirror the iterative and cumulative nature of real-world data science projects; and (3) Multi-Dimensional Evaluation, which provides a holistic assessment across reasoning, code, and results. We systematically evaluate 11 advanced agentic LLMs using DSAEval. Our results show that Claude-Sonnet-4.5 achieves the strongest overall performance, GPT-5.2 is the most efficient, and MiMo-V2-Flash is the most cost-effective. We further demonstrate that multimodal perception consistently improves performance on vision-related tasks, with gains ranging from 2.04% to 11.30%. Overall, while current data science agents perform well on structured data and routine data anlysis workflows, substantial challenges remain in unstructured domains. Finally, we offer critical insights and outline future research directions to advance the development of data science agents.
Run, Ruminate, and Regulate: A Dual-process Thinking System for Vision-and-Language Navigation
Nov 18, 2025Vision-and-Language Navigation (VLN) requires an agent to dynamically explore complex 3D environments following human instructions. Recent research underscores the potential of harnessing large language models (LLMs) for VLN, given their commonsense knowledge and general reasoning capabilities. Despite their strengths, a substantial gap in task completion performance persists between LLM-based approaches and domain experts, as LLMs inherently struggle to comprehend real-world spatial correlations precisely. Additionally, introducing LLMs is accompanied with substantial computational cost and inference latency. To address these issues, we propose a novel dual-process thinking framework dubbed R3, integrating LLMs' generalization capabilities with VLN-specific expertise in a zero-shot manner. The framework comprises three core modules: Runner, Ruminator, and Regulator. The Runner is a lightweight transformer-based expert model that ensures efficient and accurate navigation under regular circumstances. The Ruminator employs a powerful multimodal LLM as the backbone and adopts chain-of-thought (CoT) prompting to elicit structured reasoning. The Regulator monitors the navigation progress and controls the appropriate thinking mode according to three criteria, integrating Runner and Ruminator harmoniously. Experimental results illustrate that R3 significantly outperforms other state-of-the-art methods, exceeding 3.28% and 3.30% in SPL and RGSPL respectively on the REVERIE benchmark. This pronounced enhancement highlights the effectiveness of our method in handling challenging VLN tasks.
Learning Guarantee of Reward Modeling Using Deep Neural Networks
May 10, 2025In this work, we study the learning theory of reward modeling with pairwise comparison data using deep neural networks. We establish a novel non-asymptotic regret bound for deep reward estimators in a non-parametric setting, which depends explicitly on the network architecture. Furthermore, to underscore the critical importance of clear human beliefs, we introduce a margin-type condition that assumes the conditional winning probability of the optimal action in pairwise comparisons is significantly distanced from 1/2. This condition enables a sharper regret bound, which substantiates the empirical efficiency of Reinforcement Learning from Human Feedback and highlights clear human beliefs in its success. Notably, this improvement stems from high-quality pairwise comparison data implied by the margin-type condition, is independent of the specific estimators used, and thus applies to various learning algorithms and models.
A Survey on Large Language Model-based Agents for Statistics and Data Science
Dec 18, 2024In recent years, data science agents powered by Large Language Models (LLMs), known as "data agents," have shown significant potential to transform the traditional data analysis paradigm. This survey provides an overview of the evolution, capabilities, and applications of LLM-based data agents, highlighting their role in simplifying complex data tasks and lowering the entry barrier for users without related expertise. We explore current trends in the design of LLM-based frameworks, detailing essential features such as planning, reasoning, reflection, multi-agent collaboration, user interface, knowledge integration, and system design, which enable agents to address data-centric problems with minimal human intervention. Furthermore, we analyze several case studies to demonstrate the practical applications of various data agents in real-world scenarios. Finally, we identify key challenges and propose future research directions to advance the development of data agents into intelligent statistical analysis software.
LAMBDA: A Large Model Based Data Agent
Jul 24, 2024We introduce ``LAMBDA," a novel open-source, code-free multi-agent data analysis system that that harnesses the power of large models. LAMBDA is designed to address data analysis challenges in complex data-driven applications through the use of innovatively designed data agents that operate iteratively and generatively using natural language. At the core of LAMBDA are two key agent roles: the programmer and the inspector, which are engineered to work together seamlessly. Specifically, the programmer generates code based on the user's instructions and domain-specific knowledge, enhanced by advanced models. Meanwhile, the inspector debugs the code when necessary. To ensure robustness and handle adverse scenarios, LAMBDA features a user interface that allows direct user intervention in the operational loop. Additionally, LAMBDA can flexibly integrate external models and algorithms through our knowledge integration mechanism, catering to the needs of customized data analysis. LAMBDA has demonstrated strong performance on various machine learning datasets. It has the potential to enhance data science practice and analysis paradigm by seamlessly integrating human and artificial intelligence, making it more accessible, effective, and efficient for individuals from diverse backgrounds. The strong performance of LAMBDA in solving data science problems is demonstrated in several case studies, which are presented at \url{https://www.polyu.edu.hk/ama/cmfai/lambda.html}.
Statistical ranking with dynamic covariates
Jun 24, 2024



We consider a covariate-assisted ranking model grounded in the Plackett--Luce framework. Unlike existing works focusing on pure covariates or individual effects with fixed covariates, our approach integrates individual effects with dynamic covariates. This added flexibility enhances realistic ranking yet poses significant challenges for analyzing the associated estimation procedures. This paper makes an initial attempt to address these challenges. We begin by discussing the sufficient and necessary condition for the model's identifiability. We then introduce an efficient alternating maximization algorithm to compute the maximum likelihood estimator (MLE). Under suitable assumptions on the topology of comparison graphs and dynamic covariates, we establish a quantitative uniform consistency result for the MLE with convergence rates characterized by the asymptotic graph connectivity. The proposed graph topology assumption holds for several popular random graph models under optimal leading-order sparsity conditions. A comprehensive numerical study is conducted to corroborate our theoretical findings and demonstrate the application of the proposed model to real-world datasets, including horse racing and tennis competitions.
Adaptive debiased SGD in high-dimensional GLMs with steaming data
May 28, 2024



Online statistical inference facilitates real-time analysis of sequentially collected data, making it different from traditional methods that rely on static datasets. This paper introduces a novel approach to online inference in high-dimensional generalized linear models, where we update regression coefficient estimates and their standard errors upon each new data arrival. In contrast to existing methods that either require full dataset access or large-dimensional summary statistics storage, our method operates in a single-pass mode, significantly reducing both time and space complexity. The core of our methodological innovation lies in an adaptive stochastic gradient descent algorithm tailored for dynamic objective functions, coupled with a novel online debiasing procedure. This allows us to maintain low-dimensional summary statistics while effectively controlling optimization errors introduced by the dynamically changing loss functions. We demonstrate that our method, termed the Approximated Debiased Lasso (ADL), not only mitigates the need for the bounded individual probability condition but also significantly improves numerical performance. Numerical experiments demonstrate that the proposed ADL method consistently exhibits robust performance across various covariance matrix structures.
Statistical inference for pairwise comparison models
Jan 16, 2024

Pairwise comparison models are used for quantitatively evaluating utility and ranking in various fields. The increasing scale of modern problems underscores the need to understand statistical inference in these models when the number of subjects diverges, which is currently lacking in the literature except in a few special instances. This paper addresses this gap by establishing an asymptotic normality result for the maximum likelihood estimator in a broad class of pairwise comparison models. The key idea lies in identifying the Fisher information matrix as a weighted graph Laplacian matrix which can be studied via a meticulous spectral analysis. Our findings provide the first unified theory for performing statistical inference in a wide range of pairwise comparison models beyond the Bradley--Terry model, benefiting practitioners with a solid theoretical guarantee for their use. Simulations utilizing synthetic data are conducted to validate the asymptotic normality result, followed by a hypothesis test using a tennis competition dataset.
Probabilistic methods for approximate archetypal analysis
Aug 16, 2021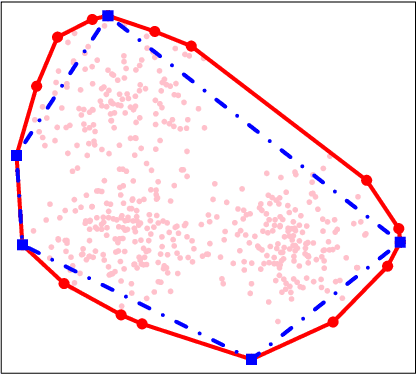
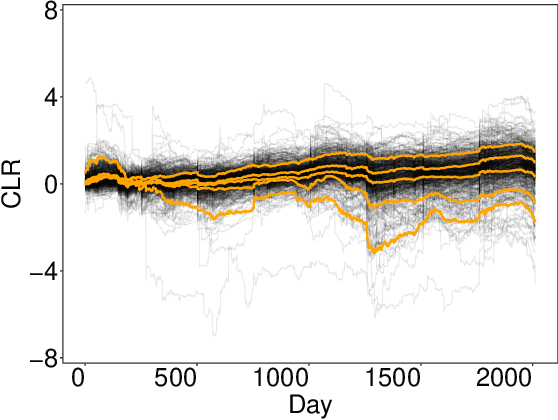
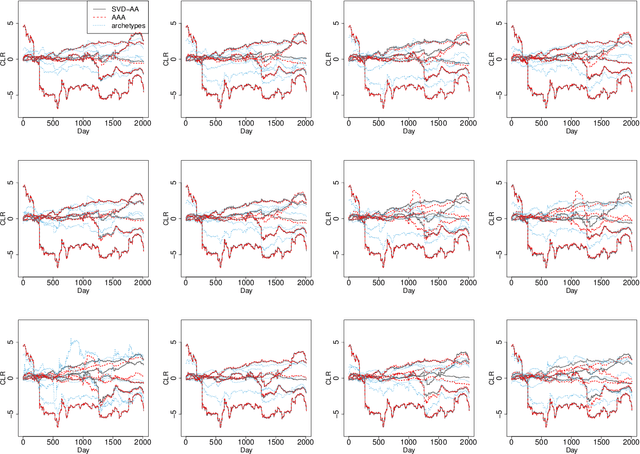
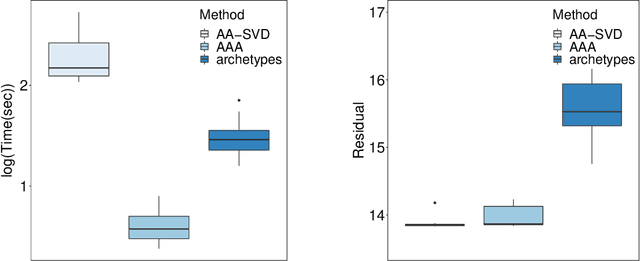
Archetypal analysis is an unsupervised learning method for exploratory data analysis. One major challenge that limits the applicability of archetypal analysis in practice is the inherent computational complexity of the existing algorithms. In this paper, we provide a novel approximation approach to partially address this issue. Utilizing probabilistic ideas from high-dimensional geometry, we introduce two preprocessing techniques to reduce the dimension and representation cardinality of the data, respectively. We prove that, provided the data is approximately embedded in a low-dimensional linear subspace and the convex hull of the corresponding representations is well approximated by a polytope with a few vertices, our method can effectively reduce the scaling of archetypal analysis. Moreover, the solution of the reduced problem is near-optimal in terms of prediction errors. Our approach can be combined with other acceleration techniques to further mitigate the intrinsic complexity of archetypal analysis. We demonstrate the usefulness of our results by applying our method to summarize several moderately large-scale datasets.