 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepFlow: Representation Enhanced Flow Matching for Causal Effect Estimation
May 07, 2026Estimating causal effects from observational data has become increasingly critical in diverse fields including healthcare, economics, and social policy. The fundamental challenge in causal inference arises from the missing counterfactuals and the selection bias. Existing methods are largely limited to point estimates and lack the capacity for distribution modeling. In this work, we propose RepFlow, a novel framework that formulates causal effect estimation as a joint optimization problem integrating representation learning with Conditional Flow Matching (CFM). RepFlow mitigates selection bias by minimizing the entropically regularized Wasserstein distance between treated and control representations. To enhance numerical stability, we further introduce an $L_2$ normalization constraint on latent representations. This balanced representation enables the flow model to accurately capture the distribution of potential outcomes. Extensive experiments across a wide range of benchmarks demonstrate that RepFlow consistently outperforms existing methods in both point and distributional causal effect estimation.
EdgeFormer: local patch-based edge detection transformer on point clouds
Apr 23, 2026Edge points on 3D point clouds can clearly convey 3D geometry and surface characteristics, therefore, edge detection is widely used in many vision applications with high industrial and commercial demands. However, the fine-grained edge features are difficult to detect effectively as they are generally densely distributed or exhibit small-scale surface gradients. To address this issue, we present a learning-based edge detection network, named EdgeFormer, which mainly consists of two stages. Based on the observation that spatially neighboring points tend to exhibit high correlation, forming the local underlying surface, we convert the edge detection of the entire point cloud into a point classification based on local patches. Therefore, in the first stage, we construct local patch feature descriptors that describe the local neighborhood around each point. In the second stage, we classify each point by analyzing the local patch feature descriptors generated in the first stage. Due to the conversion of the point cloud into local patches, the proposed method can effectively extract the finer details. The experimental results show that our model demonstrates competitive performance compared to six baselines.
* 22 pages, 9 figures. Published in Pattern Analysis and Applications
2L-LSH: A Locality-Sensitive Hash Function-Based Method For Rapid Point Cloud Indexing
Apr 23, 2026The development of 3D scanning technology has enabled the acquisition of massive point cloud models with diverse structures and large scales, thereby presenting significant challenges in point cloud processing. Fast neighboring points search is one of the most common problems, which is frequently used in model reconstruction, classification, retrieval and feature visualization. Hash function is well known for its high-speed and accurate performance in searching high-dimensional data, which is also the core of the proposed 2L-LSH. Specifically, the 2L-LSH algorithm adopts a two-step hash function strategy, in which the popular step divides the bounding box of the point cloud model and the second step constructs a generalized table-based data structure. The proposed 2L-LSH offers a highly efficient and accurate solution for fast neighboring points search in large-scale 3D point cloud models, making it a promising technique for various applications in the field. The proposed algorithm is compared with the well-known methods including Kd-tree and Octree; the obtained results demonstrated that the proposed method outperforms Kd-tree and Octree in terms of speed, i.e. the time consumption of kNN search can be 51.111% and 94.159% lower than Kd-tree and Octree, respectively. And the RN search time can be 54.519% and 41.840% lower than Kd-tree and Octree, respectively.
* 13 pages, 13 figures. Published in The Computer Journal
DARE: Aligning LLM Agents with the R Statistical Ecosystem via Distribution-Aware Retrieval
Mar 05, 2026Large Language Model (LLM) agents can automate data-science workflows, but many rigorous statistical methods implemented in R remain underused because LLMs struggle with statistical knowledge and tool retrieval. Existing retrieval-augmented approaches focus on function-level semantics and ignore data distribution, producing suboptimal matches. We propose DARE (Distribution-Aware Retrieval Embedding), a lightweight, plug-and-play retrieval model that incorporates data distribution information into function representations for R package retrieval. Our main contributions are: (i) RPKB, a curated R Package Knowledge Base derived from 8,191 high-quality CRAN packages; (ii) DARE, an embedding model that fuses distributional features with function metadata to improve retrieval relevance; and (iii) RCodingAgent, an R-oriented LLM agent for reliable R code generation and a suite of statistical analysis tasks for systematically evaluating LLM agents in realistic analytical scenarios. Empirically, DARE achieves an NDCG at 10 of 93.47%, outperforming state-of-the-art open-source embedding models by up to 17% on package retrieval while using substantially fewer parameters. Integrating DARE into RCodingAgent yields significant gains on downstream analysis tasks. This work helps narrow the gap between LLM automation and the mature R statistical ecosystem.
FedAdaVR: Adaptive Variance Reduction for Robust Federated Learning under Limited Client Participation
Jan 29, 2026Federated learning (FL) encounters substantial challenges due to heterogeneity, leading to gradient noise, client drift, and partial client participation errors, the last of which is the most pervasive but remains insufficiently addressed in current literature. In this paper, we propose FedAdaVR, a novel FL algorithm aimed at solving heterogeneity issues caused by sporadic client participation by incorporating an adaptive optimiser with a variance reduction technique. This method takes advantage of the most recent stored updates from clients, even when they are absent from the current training round, thereby emulating their presence. Furthermore, we propose FedAdaVR-Quant, which stores client updates in quantised form, significantly reducing the memory requirements (by 50%, 75%, and 87.5%) of FedAdaVR while maintaining equivalent model performance. We analyse the convergence behaviour of FedAdaVR under general nonconvex conditions and prove that our proposed algorithm can eliminate partial client participation error. Extensive experiments conducted on multiple datasets, under both independent and identically distributed (IID) and non-IID settings, demonstrate that FedAdaVR consistently outperforms state-of-the-art baseline methods.
DSAEval: Evaluating Data Science Agents on a Wide Range of Real-World Data Science Problems
Jan 20, 2026Recent LLM-based data agents aim to automate data science tasks ranging from data analysis to deep learning. However, the open-ended nature of real-world data science problems, which often span multiple taxonomies and lack standard answers, poses a significant challenge for evaluation. To address this, we introduce DSAEval, a benchmark comprising 641 real-world data science problems grounded in 285 diverse datasets, covering both structured and unstructured data (e.g., vision and text). DSAEval incorporates three distinctive features: (1) Multimodal Environment Perception, which enables agents to interpret observations from multiple modalities including text and vision; (2) Multi-Query Interactions, which mirror the iterative and cumulative nature of real-world data science projects; and (3) Multi-Dimensional Evaluation, which provides a holistic assessment across reasoning, code, and results. We systematically evaluate 11 advanced agentic LLMs using DSAEval. Our results show that Claude-Sonnet-4.5 achieves the strongest overall performance, GPT-5.2 is the most efficient, and MiMo-V2-Flash is the most cost-effective. We further demonstrate that multimodal perception consistently improves performance on vision-related tasks, with gains ranging from 2.04% to 11.30%. Overall, while current data science agents perform well on structured data and routine data anlysis workflows, substantial challenges remain in unstructured domains. Finally, we offer critical insights and outline future research directions to advance the development of data science agents.
FedOAED: Federated On-Device Autoencoder Denoiser for Heterogeneous Data under Limited Client Availability
Dec 19, 2025

Over the last few decades, machine learning (ML) and deep learning (DL) solutions have demonstrated their potential across many applications by leveraging large amounts of high-quality data. However, strict data-sharing regulations such as the General Data Protection Regulation (GDPR) and the Health Insurance Portability and Accountability Act (HIPAA) have prevented many data-driven applications from being realised. Federated Learning (FL), in which raw data never leaves local devices, has shown promise in overcoming these limitations. Although FL has grown rapidly in recent years, it still struggles with heterogeneity, which produces gradient noise, client-drift, and increased variance from partial client participation. In this paper, we propose FedOAED, a novel federated learning algorithm designed to mitigate client-drift arising from multiple local training updates and the variance induced by partial client participation. FedOAED incorporates an on-device autoencoder denoiser on the client side to mitigate client-drift and variance resulting from heterogeneous data under limited client availability. Experiments on multiple vision datasets under Non-IID settings demonstrate that FedOAED consistently outperforms state-of-the-art baselines.
TSPRank: Bridging Pairwise and Listwise Methods with a Bilinear Travelling Salesman Model
Nov 18, 2024



Traditional Learning-To-Rank (LETOR) approaches, including pairwise methods like RankNet and LambdaMART, often fall short by solely focusing on pairwise comparisons, leading to sub-optimal global rankings. Conversely, deep learning based listwise methods, while aiming to optimise entire lists, require complex tuning and yield only marginal improvements over robust pairwise models. To overcome these limitations, we introduce Travelling Salesman Problem Rank (TSPRank), a hybrid pairwise-listwise ranking method. TSPRank reframes the ranking problem as a Travelling Salesman Problem (TSP), a well-known combinatorial optimisation challenge that has been extensively studied for its numerous solution algorithms and applications. This approach enables the modelling of pairwise relationships and leverages combinatorial optimisation to determine the listwise ranking. This approach can be directly integrated as an additional component into embeddings generated by existing backbone models to enhance ranking performance. Our extensive experiments across three backbone models on diverse tasks, including stock ranking, information retrieval, and historical events ordering, demonstrate that TSPRank significantly outperforms both pure pairwise and listwise methods. Our qualitative analysis reveals that TSPRank's main advantage over existing methods is its ability to harness global information better while ranking. TSPRank's robustness and superior performance across different domains highlight its potential as a versatile and effective LETOR solution. The code and preprocessed data are available at https://github.com/waylonli/TSPRank-KDD2025.
Discrete Choice Analysis with Machine Learning Capabilities
Jan 21, 2021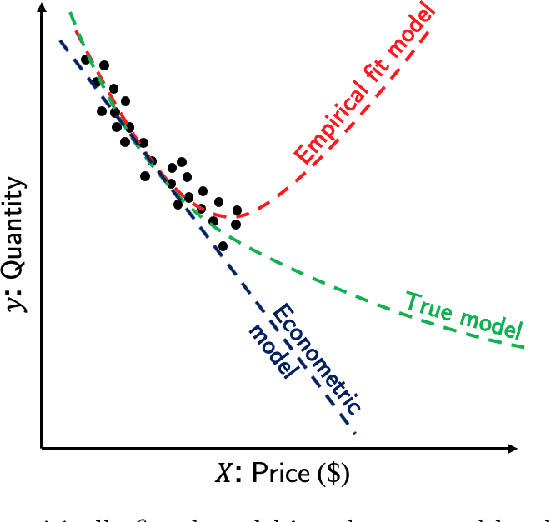
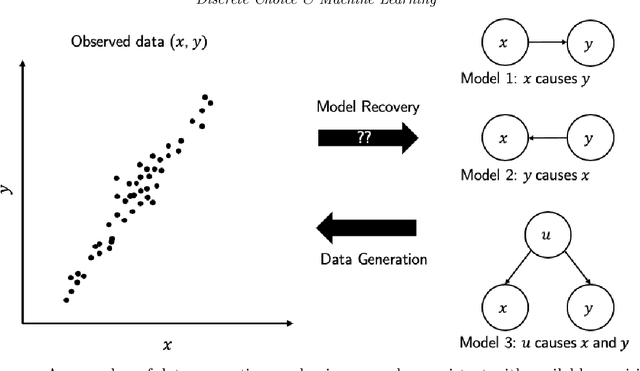
This paper discusses capabilities that are essential to models applied in policy analysis settings and the limitations of direct applications of off-the-shelf machine learning methodologies to such settings. Traditional econometric methodologies for building discrete choice models for policy analysis involve combining data with modeling assumptions guided by subject-matter considerations. Such considerations are typically most useful in specifying the systematic component of random utility discrete choice models but are typically of limited aid in determining the form of the random component. We identify an area where machine learning paradigms can be leveraged, namely in specifying and systematically selecting the best specification of the random component of the utility equations. We review two recent novel applications where mixed-integer optimization and cross-validation are used to algorithmically select optimal specifications for the random utility components of nested logit and logit mixture models subject to interpretability constraints.
Sparse Covariance Estimation in Logit Mixture Models
Jan 14, 2020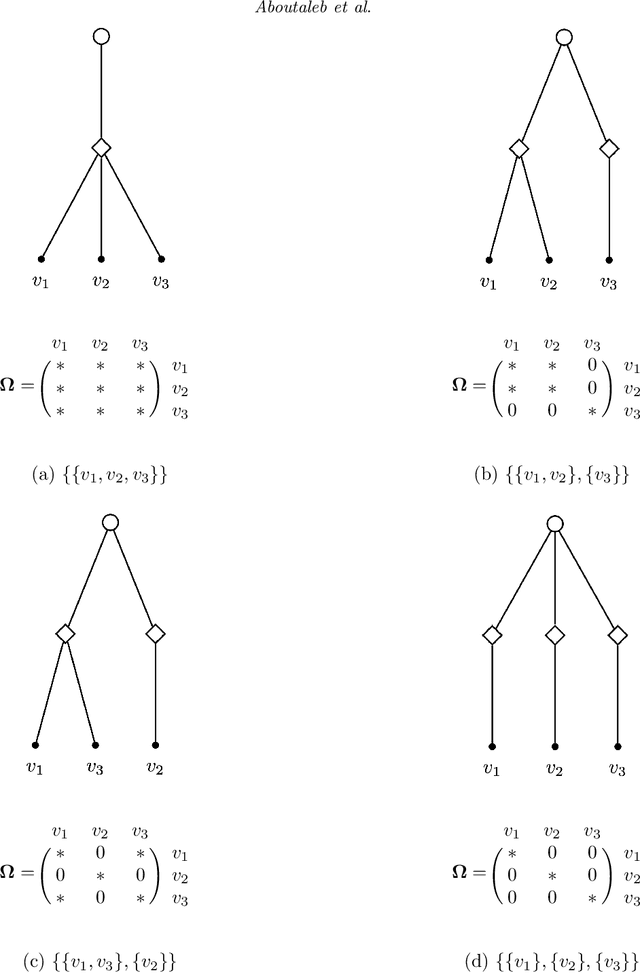
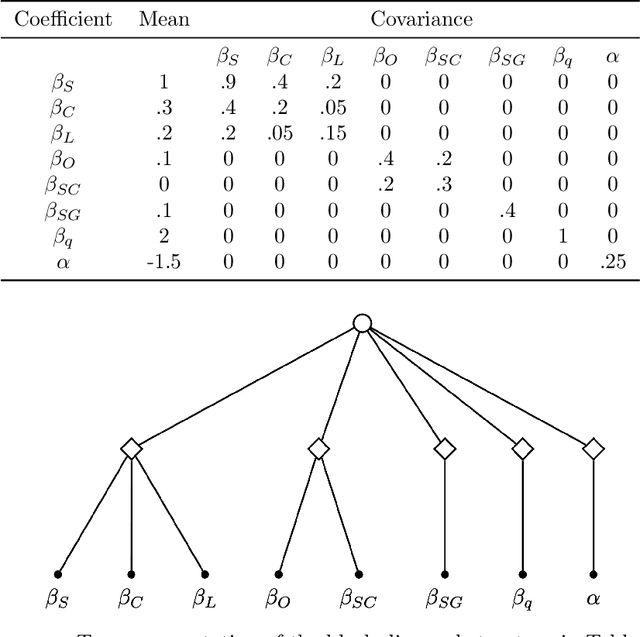
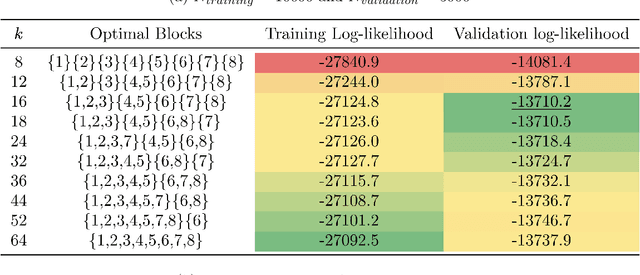
This paper introduces a new data-driven methodology for estimating sparse covariance matrices of the random coefficients in logit mixture models. Researchers typically specify covariance matrices in logit mixture models under one of two extreme assumptions: either an unrestricted full covariance matrix (allowing correlations between all random coefficients), or a restricted diagonal matrix (allowing no correlations at all). Our objective is to find optimal subsets of correlated coefficients for which we estimate covariances. We propose a new estimator, called MISC, that uses a mixed-integer optimization (MIO) program to find an optimal block diagonal structure specification for the covariance matrix, corresponding to subsets of correlated coefficients, for any desired sparsity level using Markov Chain Monte Carlo (MCMC) posterior draws from the unrestricted full covariance matrix. The optimal sparsity level of the covariance matrix is determined using out-of-sample validation. We demonstrate the ability of MISC to correctly recover the true covariance structure from synthetic data. In an empirical illustration using a stated preference survey on modes of transportation, we use MISC to obtain a sparse covariance matrix indicating how preferences for attributes are related to one another.