 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheano: A Python framework for fast computation of mathematical expressions
May 09, 2016



Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.
RATM: Recurrent Attentive Tracking Model
Apr 28, 2016
We present an attention-based modular neural framework for computer vision. The framework uses a soft attention mechanism allowing models to be trained with gradient descent. It consists of three modules: a recurrent attention module controlling where to look in an image or video frame, a feature-extraction module providing a representation of what is seen, and an objective module formalizing why the model learns its attentive behavior. The attention module allows the model to focus computation on task-related information in the input. We apply the framework to several object tracking tasks and explore various design choices. We experiment with three data sets, bouncing ball, moving digits and the real-world KTH data set. The proposed Recurrent Attentive Tracking Model performs well on all three tasks and can generalize to related but previously unseen sequences from a challenging tracking data set.
Regularizing RNNs by Stabilizing Activations
Apr 26, 2016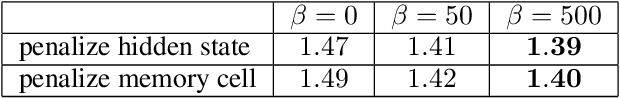
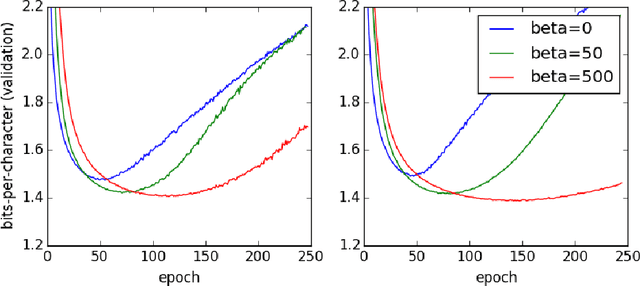
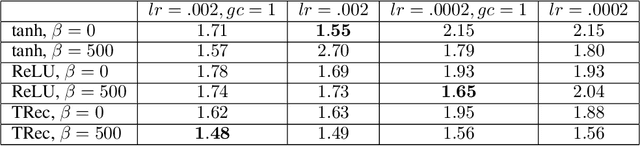
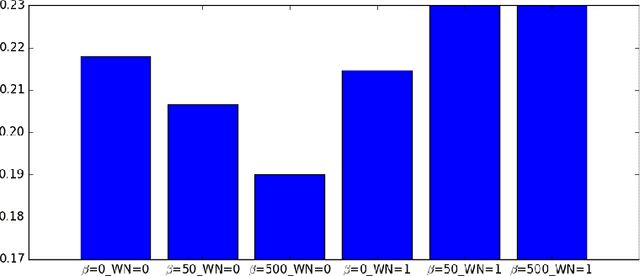
We stabilize the activations of Recurrent Neural Networks (RNNs) by penalizing the squared distance between successive hidden states' norms. This penalty term is an effective regularizer for RNNs including LSTMs and IRNNs, improving performance on character-level language modeling and phoneme recognition, and outperforming weight noise and dropout. We achieve competitive performance (18.6\% PER) on the TIMIT phoneme recognition task for RNNs evaluated without beam search or an RNN transducer. With this penalty term, IRNN can achieve similar performance to LSTM on language modeling, although adding the penalty term to the LSTM results in superior performance. Our penalty term also prevents the exponential growth of IRNN's activations outside of their training horizon, allowing them to generalize to much longer sequences.
Neural Networks with Few Multiplications
Feb 26, 2016
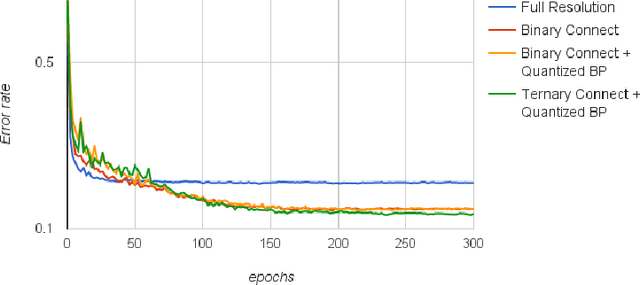
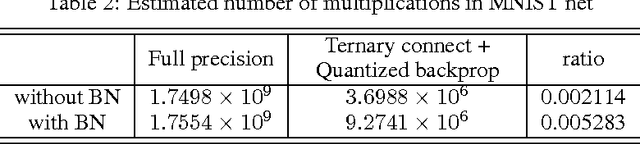
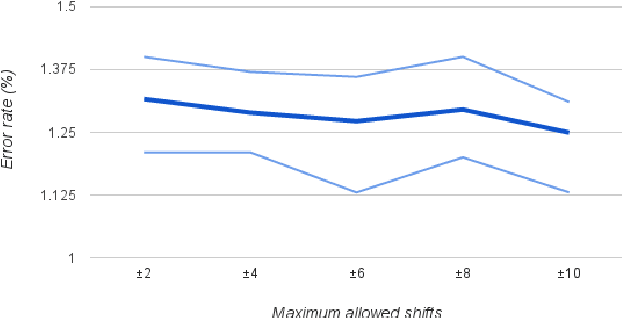
For most deep learning algorithms training is notoriously time consuming. Since most of the computation in training neural networks is typically spent on floating point multiplications, we investigate an approach to training that eliminates the need for most of these. Our method consists of two parts: First we stochastically binarize weights to convert multiplications involved in computing hidden states to sign changes. Second, while back-propagating error derivatives, in addition to binarizing the weights, we quantize the representations at each layer to convert the remaining multiplications into binary shifts. Experimental results across 3 popular datasets (MNIST, CIFAR10, SVHN) show that this approach not only does not hurt classification performance but can result in even better performance than standard stochastic gradient descent training, paving the way to fast, hardware-friendly training of neural networks.
Dropout as data augmentation
Jan 08, 2016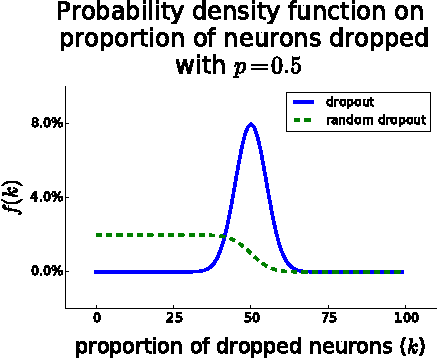

Dropout is typically interpreted as bagging a large number of models sharing parameters. We show that using dropout in a network can also be interpreted as a kind of data augmentation in the input space without domain knowledge. We present an approach to projecting the dropout noise within a network back into the input space, thereby generating augmented versions of the training data, and we show that training a deterministic network on the augmented samples yields similar results. Finally, we propose a new dropout noise scheme based on our observations and show that it improves dropout results without adding significant computational cost.
Denoising Criterion for Variational Auto-Encoding Framework
Jan 04, 2016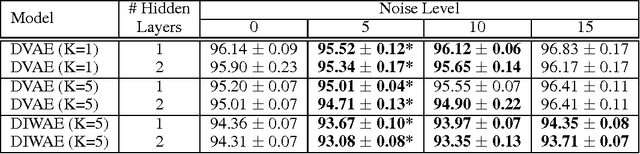
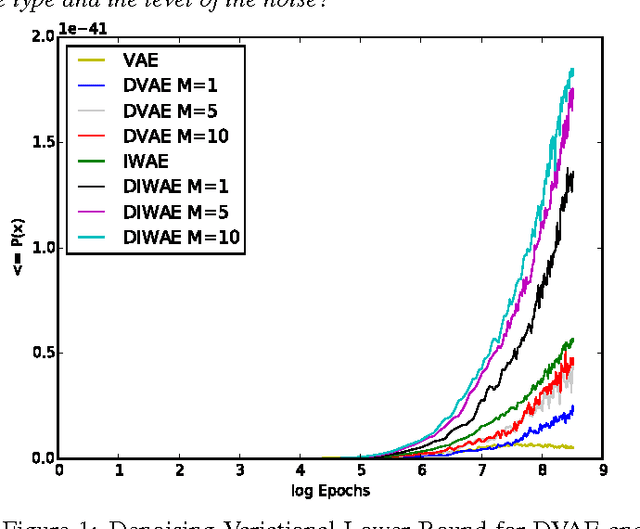
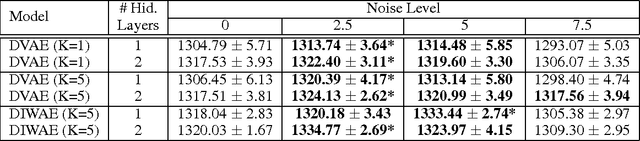

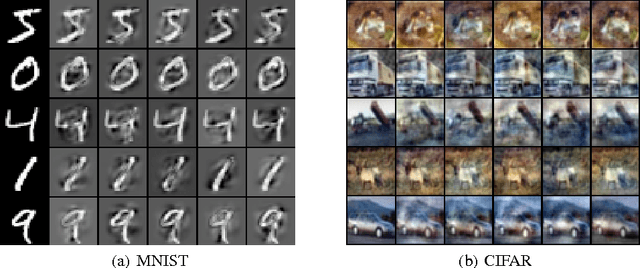
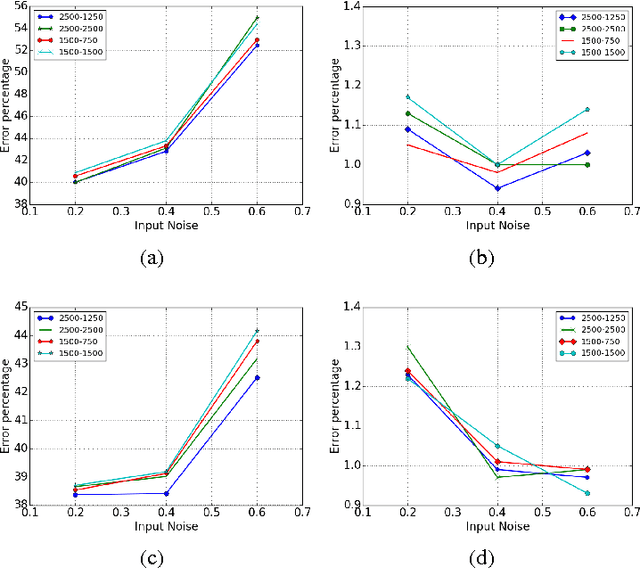
Denoising autoencoders (DAE) are trained to reconstruct their clean inputs with noise injected at the input level, while variational autoencoders (VAE) are trained with noise injected in their stochastic hidden layer, with a regularizer that encourages this noise injection. In this paper, we show that injecting noise both in input and in the stochastic hidden layer can be advantageous and we propose a modified variational lower bound as an improved objective function in this setup. When input is corrupted, then the standard VAE lower bound involves marginalizing the encoder conditional distribution over the input noise, which makes the training criterion intractable. Instead, we propose a modified training criterion which corresponds to a tractable bound when input is corrupted. Experimentally, we find that the proposed denoising variational autoencoder (DVAE) yields better average log-likelihood than the VAE and the importance weighted autoencoder on the MNIST and Frey Face datasets.
How far can we go without convolution: Improving fully-connected networks
Nov 09, 2015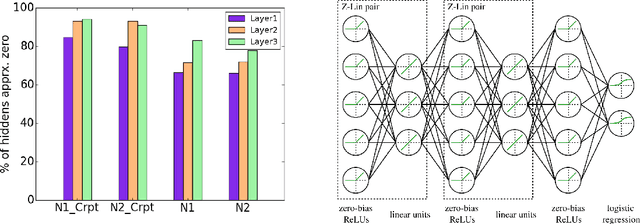
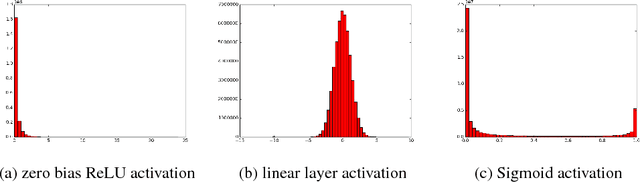
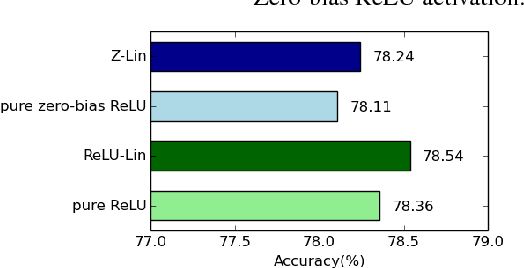
We propose ways to improve the performance of fully connected networks. We found that two approaches in particular have a strong effect on performance: linear bottleneck layers and unsupervised pre-training using autoencoders without hidden unit biases. We show how both approaches can be related to improving gradient flow and reducing sparsity in the network. We show that a fully connected network can yield approximately 70% classification accuracy on the permutation-invariant CIFAR-10 task, which is much higher than the current state-of-the-art. By adding deformations to the training data, the fully connected network achieves 78% accuracy, which is just 10% short of a decent convolutional network.
Conservativeness of untied auto-encoders
Sep 21, 2015

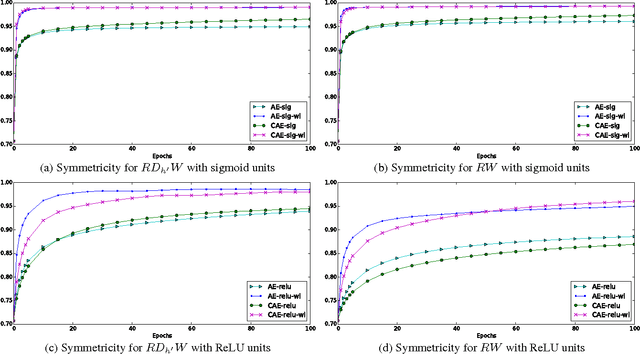
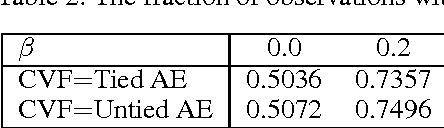
We discuss necessary and sufficient conditions for an auto-encoder to define a conservative vector field, in which case it is associated with an energy function akin to the unnormalized log-probability of the data. We show that the conditions for conservativeness are more general than for encoder and decoder weights to be the same ("tied weights"), and that they also depend on the form of the hidden unit activation function, but that contractive training criteria, such as denoising, will enforce these conditions locally. Based on these observations, we show how we can use auto-encoders to extract the conservative component of a vector field.
Zero-bias autoencoders and the benefits of co-adapting features
Apr 08, 2015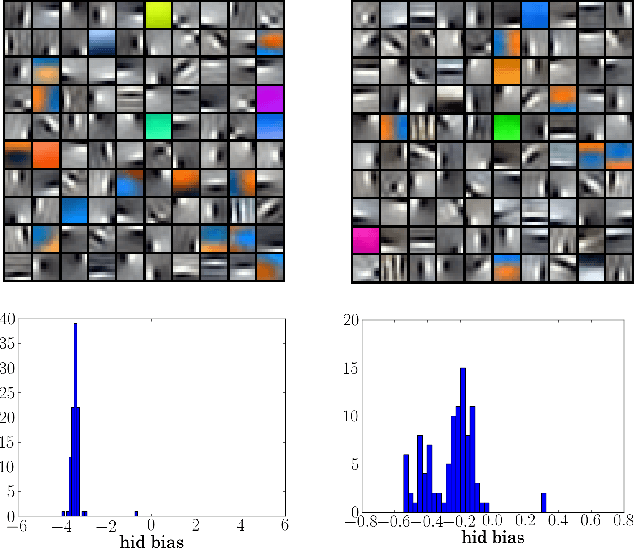

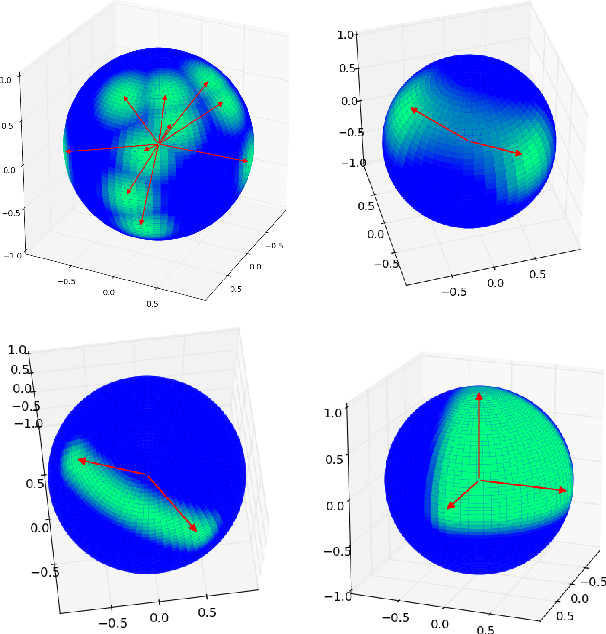
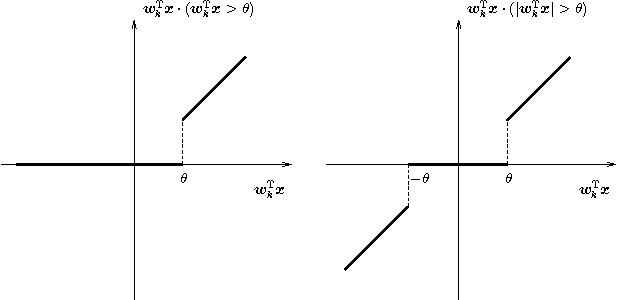
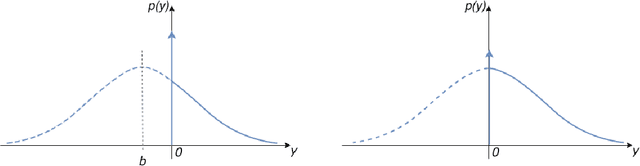
Regularized training of an autoencoder typically results in hidden unit biases that take on large negative values. We show that negative biases are a natural result of using a hidden layer whose responsibility is to both represent the input data and act as a selection mechanism that ensures sparsity of the representation. We then show that negative biases impede the learning of data distributions whose intrinsic dimensionality is high. We also propose a new activation function that decouples the two roles of the hidden layer and that allows us to learn representations on data with very high intrinsic dimensionality, where standard autoencoders typically fail. Since the decoupled activation function acts like an implicit regularizer, the model can be trained by minimizing the reconstruction error of training data, without requiring any additional regularization.
EmoNets: Multimodal deep learning approaches for emotion recognition in video
Mar 30, 2015

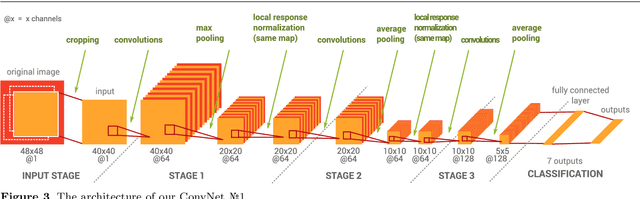
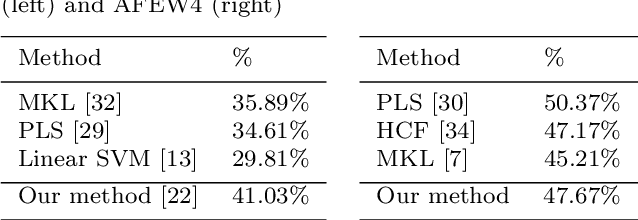
The task of the emotion recognition in the wild (EmotiW) Challenge is to assign one of seven emotions to short video clips extracted from Hollywood style movies. The videos depict acted-out emotions under realistic conditions with a large degree of variation in attributes such as pose and illumination, making it worthwhile to explore approaches which consider combinations of features from multiple modalities for label assignment. In this paper we present our approach to learning several specialist models using deep learning techniques, each focusing on one modality. Among these are a convolutional neural network, focusing on capturing visual information in detected faces, a deep belief net focusing on the representation of the audio stream, a K-Means based "bag-of-mouths" model, which extracts visual features around the mouth region and a relational autoencoder, which addresses spatio-temporal aspects of videos. We explore multiple methods for the combination of cues from these modalities into one common classifier. This achieves a considerably greater accuracy than predictions from our strongest single-modality classifier. Our method was the winning submission in the 2013 EmotiW challenge and achieved a test set accuracy of 47.67% on the 2014 dataset.