 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Expressive Power of GNNs for Boolean Satisfiability
Feb 09, 2026Machine learning approaches to solving Boolean Satisfiability (SAT) aim to replace handcrafted heuristics with learning-based models. Graph Neural Networks have emerged as the main architecture for SAT solving, due to the natural graph representation of Boolean formulas. We analyze the expressive power of GNNs for SAT solving through the lens of the Weisfeiler-Leman (WL) test. As our main result, we prove that the full WL hierarchy cannot, in general, distinguish between satisfiable and unsatisfiable instances. We show that indistinguishability under higher-order WL carries over to practical limitations for WL-bounded solvers that set variables sequentially. We further study the expressivity required for several important families of SAT instances, including regular, random and planar instances. To quantify expressivity needs in practice, we conduct experiments on random instances from the G4SAT benchmark and industrial instances from the International SAT Competition. Our results suggest that while random instances are largely distinguishable, industrial instances often require more expressivity to predict a satisfying assignment.
BitLogic: Training Framework for Gradient-Based FPGA-Native Neural Networks
Feb 07, 2026The energy and latency costs of deep neural network inference are increasingly driven by deployment rather than training, motivating hardware-specialized alternatives to arithmetic-heavy models. Field-Programmable Gate Arrays (FPGAs) provide an attractive substrate for such specialization, yet existing FPGA-based neural approaches are fragmented and difficult to compare. We present BitLogic, a fully gradient-based, end-to-end trainable framework for FPGA-native neural networks built around Lookup Table (LUT) computation. BitLogic replaces multiply-accumulate operations with differentiable LUT nodes that map directly to FPGA primitives, enabling native binary computation, sparse connectivity, and efficient hardware realization. The framework offers a modular functional API supporting diverse architectures, along with learned encoders, hardware-aware heads, and multiple boundary-consistent LUT relaxations. An automated Register Transfer Level (RTL) export pipeline translates trained PyTorch models into synthesizable HDL, ensuring equivalence between software and hardware inference. Experiments across standard vision benchmarks and heterogeneous hardware platforms demonstrate competitive accuracy and substantial gains in FPGA efficiency, including 72.3% test accuracy on CIFAR-10 achieved with fewer than 0.3M logic gates, while attaining sub-20 ns single-sample inference using only LUT resources.
GIC-DLC: Differentiable Logic Circuits for Hardware-Friendly Grayscale Image Compression
Jan 20, 2026Neural image codecs achieve higher compression ratios than traditional hand-crafted methods such as PNG or JPEG-XL, but often incur substantial computational overhead, limiting their deployment on energy-constrained devices such as smartphones, cameras, and drones. We propose Grayscale Image Compression with Differentiable Logic Circuits (GIC-DLC), a hardware-aware codec where we train lookup tables to combine the flexibility of neural networks with the efficiency of Boolean operations. Experiments on grayscale benchmark datasets show that GIC-DLC outperforms traditional codecs in compression efficiency while allowing substantial reductions in energy consumption and latency. These results demonstrate that learned compression can be hardware-friendly, offering a promising direction for low-power image compression on edge devices.
Steering Pretrained Drafters during Speculative Decoding
Nov 13, 2025



Speculative decoding accelerates language model inference by separating generation into fast drafting and parallel verification. Its main limitation is drafter-verifier misalignment, which limits token acceptance and reduces overall effectiveness. While small drafting heads trained from scratch compensate with speed, they struggle when verification dominates latency or when inputs are out of distribution. In contrast, pretrained drafters, though slower, achieve higher acceptance rates thanks to stronger standalone generation capabilities, making them competitive when drafting latency is negligible relative to verification or communication overhead. In this work, we aim to improve the acceptance rates of pretrained drafters by introducing a lightweight dynamic alignment mechanism: a steering vector computed from the verifier's hidden states and injected into the pretrained drafter. Compared to existing offline alignment methods such as distillation, our approach boosts the number of accepted tokens by up to 35\% under standard sampling and 22\% under greedy sampling, all while incurring negligible computational overhead. Importantly, our approach can be retrofitted to existing architectures and pretrained models, enabling rapid adoption.
How Many Tokens Do 3D Point Cloud Transformer Architectures Really Need?
Nov 07, 2025Recent advances in 3D point cloud transformers have led to state-of-the-art results in tasks such as semantic segmentation and reconstruction. However, these models typically rely on dense token representations, incurring high computational and memory costs during training and inference. In this work, we present the finding that tokens are remarkably redundant, leading to substantial inefficiency. We introduce gitmerge3D, a globally informed graph token merging method that can reduce the token count by up to 90-95% while maintaining competitive performance. This finding challenges the prevailing assumption that more tokens inherently yield better performance and highlights that many current models are over-tokenized and under-optimized for scalability. We validate our method across multiple 3D vision tasks and show consistent improvements in computational efficiency. This work is the first to assess redundancy in large-scale 3D transformer models, providing insights into the development of more efficient 3D foundation architectures. Our code and checkpoints are publicly available at https://gitmerge3d.github.io
Inductive Transfer Learning for Graph-Based Recommenders
Oct 26, 2025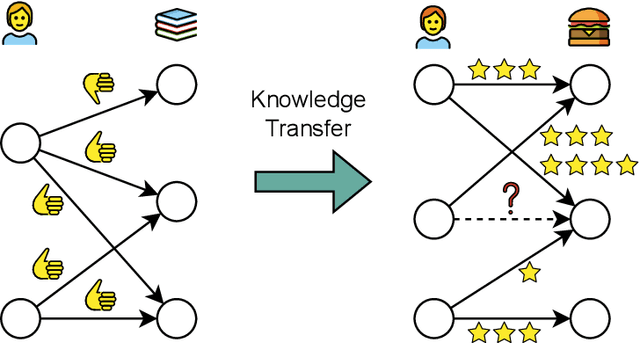
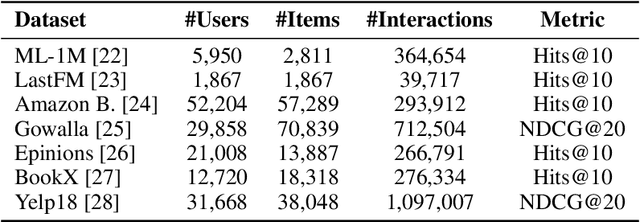
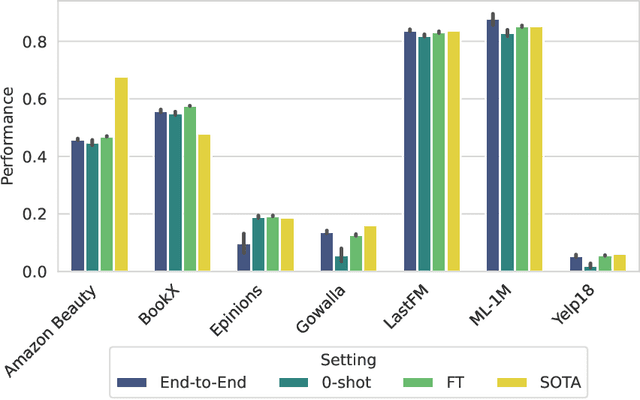
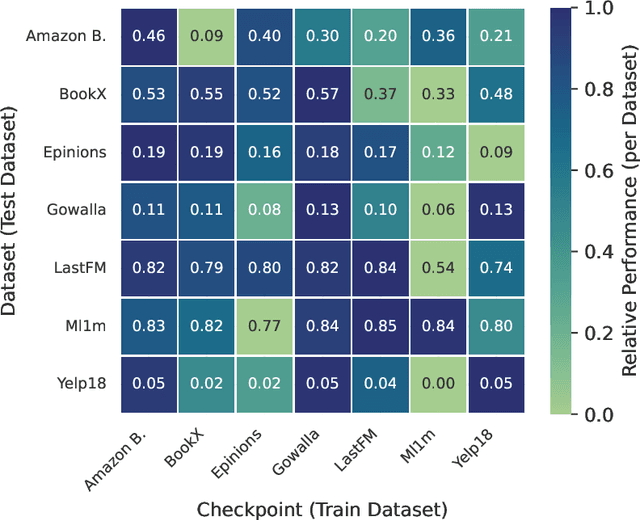
Graph-based recommender systems are commonly trained in transductive settings, which limits their applicability to new users, items, or datasets. We propose NBF-Rec, a graph-based recommendation model that supports inductive transfer learning across datasets with disjoint user and item sets. Unlike conventional embedding-based methods that require retraining for each domain, NBF-Rec computes node embeddings dynamically at inference time. We evaluate the method on seven real-world datasets spanning movies, music, e-commerce, and location check-ins. NBF-Rec achieves competitive performance in zero-shot settings, where no target domain data is used for training, and demonstrates further improvements through lightweight fine-tuning. These results show that inductive transfer is feasible in graph-based recommendation and that interaction-level message passing supports generalization across datasets without requiring aligned users or items.
SAO-Instruct: Free-form Audio Editing using Natural Language Instructions
Oct 26, 2025Generative models have made significant progress in synthesizing high-fidelity audio from short textual descriptions. However, editing existing audio using natural language has remained largely underexplored. Current approaches either require the complete description of the edited audio or are constrained to predefined edit instructions that lack flexibility. In this work, we introduce SAO-Instruct, a model based on Stable Audio Open capable of editing audio clips using any free-form natural language instruction. To train our model, we create a dataset of audio editing triplets (input audio, edit instruction, output audio) using Prompt-to-Prompt, DDPM inversion, and a manual editing pipeline. Although partially trained on synthetic data, our model generalizes well to real in-the-wild audio clips and unseen edit instructions. We demonstrate that SAO-Instruct achieves competitive performance on objective metrics and outperforms other audio editing approaches in a subjective listening study. To encourage future research, we release our code and model weights.
Bias beyond Borders: Global Inequalities in AI-Generated Music
Oct 02, 2025While recent years have seen remarkable progress in music generation models, research on their biases across countries, languages, cultures, and musical genres remains underexplored. This gap is compounded by the lack of datasets and benchmarks that capture the global diversity of music. To address these challenges, we introduce GlobalDISCO, a large-scale dataset consisting of 73k music tracks generated by state-of-the-art commercial generative music models, along with paired links to 93k reference tracks in LAION-DISCO-12M. The dataset spans 147 languages and includes musical style prompts extracted from MusicBrainz and Wikipedia. The dataset is globally balanced, representing musical styles from artists across 79 countries and five continents. Our evaluation reveals large disparities in music quality and alignment with reference music between high-resource and low-resource regions. Furthermore, we find marked differences in model performance between mainstream and geographically niche genres, including cases where models generate music for regional genres that more closely align with the distribution of mainstream styles.
High-Fidelity Speech Enhancement via Discrete Audio Tokens
Oct 02, 2025Recent autoregressive transformer-based speech enhancement (SE) methods have shown promising results by leveraging advanced semantic understanding and contextual modeling of speech. However, these approaches often rely on complex multi-stage pipelines and low sampling rate codecs, limiting them to narrow and task-specific speech enhancement. In this work, we introduce DAC-SE1, a simplified language model-based SE framework leveraging discrete high-resolution audio representations; DAC-SE1 preserves fine-grained acoustic details while maintaining semantic coherence. Our experiments show that DAC-SE1 surpasses state-of-the-art autoregressive SE methods on both objective perceptual metrics and in a MUSHRA human evaluation. We release our codebase and model checkpoints to support further research in scalable, unified, and high-quality speech enhancement.
Multi-bit Audio Watermarking
Oct 02, 2025



We present Timbru, a post-hoc audio watermarking model that achieves state-of-the-art robustness and imperceptibility trade-offs without training an embedder-detector model. Given any 44.1 kHz stereo music snippet, our method performs per-audio gradient optimization to add imperceptible perturbations in the latent space of a pretrained audio VAE, guided by a combined message and perceptual loss. The watermark can then be extracted using a pretrained CLAP model. We evaluate 16-bit watermarking on MUSDB18-HQ against AudioSeal, WavMark, and SilentCipher across common filtering, noise, compression, resampling, cropping, and regeneration attacks. Our approach attains the best average bit error rates, while preserving perceptual quality, demonstrating an efficient, dataset-free path to imperceptible audio watermarking.