 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRAFT: Grafted Reference Audio for Fine-grained Pronunciation in Zero-shot Text-to-Speech
Jul 02, 2026We present GRAFT, a per-word pronunciation conditioning mechanism for text-to-speech neural codec language modeling. Existing systems reach high intelligibility and naturalness but inherit the ambiguity of text and mispronounce rare proper nouns, loanwords and technical terms. Even phoneme-conditioned models offer no direct acoustic handle for per-word pronunciation. GRAFT controls the pronunciation of a chosen word from a short spoken sample of it, encoded with the model's own speech tokenizer and bound to the word's position in the prompt. Voice conversion during training-data construction disentangles the hint speaker from the target speaker, so the hint may come from any voice while the output stays in the target voice. In a blind English listening study, human raters rank GRAFT first by a clear margin, judging its rendering of the difficult word closest to a reference recording of that word. On a five-language objective benchmark, GRAFT reduces target-word phoneme error rate by 22-39% over the identical text-only backbone and outperforms competitive open-source zero-shot systems, both phoneme- and text-conditioned, on target-word pronunciation, while preserving speaker similarity and naturalness.
Post-Training Speech Enhancement Language Models with Perceptual Rewards
Jun 19, 2026Speech enhancement language models achieve strong results when trained on discrete audio tokens, but their optimization relies on token-level cross-entropy rather than the perceptual metrics used for evaluation. We introduce a post-training stage for autoregressive speech enhancement language models using Group Sequence Policy Optimization (GSPO) with multi-metric perceptual rewards. Our method directly optimizes non-differentiable quality metrics (DNSMOS, WER, and UTMOS) as reward signals, without learned surrogates or offline preference pairs. Applied to two autoregressive base models, UniSE and GenSE, our approach achieves state-of-the-art results on the DNS2020 benchmark. A human evaluation ablation further shows that the composite multi-metric reward is preferred over any single-metric variant, confirming that multi-reward optimization avoids the reward hacking observed with single-metric training.
WorldSpeech: A Multilingual Speech Corpus from Around the World
May 09, 2026Automatic speech recognition (ASR) performs well for high-resource languages with abundant paired audio-transcript data, but its accuracy degrades sharply for most languages due to limited publicly available aligned data. To this end, we introduce WorldSpeech, a 24 kHz multilingual speech corpus comprising 65k hours of aligned audio-transcript data across 76 languages, collected from diverse public sources including parliamentary proceedings, international broadcasts, and public-domain audiobooks. For 37 languages, WorldSpeech provides more than 200 hours of aligned speech, with 28 exceeding 500 hours and 24 surpassing 1k hours. Fine-tuning existing ASR models on WorldSpeech results in an average relative Word-Error-Rate reduction of 63.5% across 11 typologically diverse languages.
High-Fidelity Speech Enhancement via Discrete Audio Tokens
Oct 02, 2025


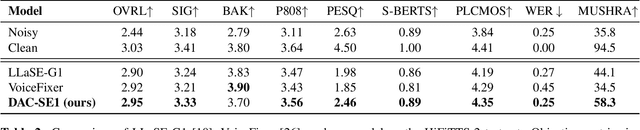
Recent autoregressive transformer-based speech enhancement (SE) methods have shown promising results by leveraging advanced semantic understanding and contextual modeling of speech. However, these approaches often rely on complex multi-stage pipelines and low sampling rate codecs, limiting them to narrow and task-specific speech enhancement. In this work, we introduce DAC-SE1, a simplified language model-based SE framework leveraging discrete high-resolution audio representations; DAC-SE1 preserves fine-grained acoustic details while maintaining semantic coherence. Our experiments show that DAC-SE1 surpasses state-of-the-art autoregressive SE methods on both objective perceptual metrics and in a MUSHRA human evaluation. We release our codebase and model checkpoints to support further research in scalable, unified, and high-quality speech enhancement.