 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Attribution in Large Language Models via Bidirectional Gradient Optimization
Jun 03, 2026Large Language Models (LLMs) are increasingly deployed across diverse applications, raising critical questions for governance, accountability, and data provenance. Understanding which training data most influenced a model's output remains a fundamental open problem. We address this challenge through training data attribution (TDA) for auto-regressive LLMs by expanding upon the inverse formulation: How would training data be affected if the model had seen the generated output during training? Our method perturbs the base model using bidirectional gradient optimization (gradient ascent and descent) on a generated text sample and measures the resulting change in loss across training samples. Our framework supports attribution at arbitrary data granularity, enabling both factual and stylistic attribution. We evaluate our method against baselines on pretrained models with known datasets, and show that it outperforms previous work on influence metrics, thereby enhancing model interpretability, an essential requirement for accountable AI systems.
TreeFlash: Parallel AR-Approximation for Faster Speculative Decoding
Jun 02, 2026One-shot block drafters for speculative decoding generate the full draft in a single forward pass, achieving strong throughput by eliminating sequential token generation. However, they predict each draft token conditioned only on the prefix context, with no dependence on previously drafted tokens. This non-autoregressive conditioning causes the drafter's distribution to diverge from the verifier's true autoregressive distribution as draft depth grows. This problem becomes more severe in tree-based drafting, where distinct branches are forced to share the same marginal distribution for subsequent tokens. We propose TreeFlash, which addresses this by incorporating an MLP layer conditioned on the drafter's hidden state and the previous token to approximate an autoregressive distribution. TreeFlash retains the $\mathcal{O}(1)$ decoding time complexity of one-shot drafters by employing a two-stage approximation mechanism. TreeFlash achieves state-of-the-art performance across a variety of tasks and models, improving over marginal tree drafting by $12\%$ higher block efficiency and $9\%$ higher speedup.
Reasoning Structure of Large Language Models
Jun 02, 2026Large reasoning models (LRMs) are often evaluated using metrics such as final-answer accuracy or token count. However, identical scores on these metrics can hide fundamentally different reasoning structures. To address this limitation, we introduce a scalable LRM benchmark of logic puzzles and a pipeline that converts unstructured traces into verifiable reasoning graphs of claims and dependencies. This turns reasoning into a structured, measurable object whose topology can be quantitatively analyzed. Building on this, we define a reasoning efficiency metric that quantifies how concentrated the model's logical flow is. Our analysis on open-source reasoning models shows that structural measurements separate behaviors that token count and accuracy conflate, providing a practical tool for diagnosing failure modes and comparing how reasoning scales with puzzle difficulty.
N-vium: Mixture-of-Exits Transformer for Accelerated Exact Generation
May 13, 2026Improving the inference efficiency of autoregressive transformers typically means reducing FLOPs per token, usually through approximations that degrade model quality. We introduce N-vium, a mixture-of-exits transformer that partially parallelizes computation across depth on standard hardware, increasing effective FLOPs per second rather than minimizing compute per token. N-vium attaches prediction heads at multiple depths and defines the next-token distribution as a learned mixture over these exits, with token-adaptive routing. This formulation strictly generalizes the standard transformer, which is recovered exactly when routing assigns zero mass to all intermediate heads. Sampling from the mixture is exact, and complete KV caches are recovered by deferring the upper-layer computation and batching it with later tokens. We pretrain N-vium at scales up to 1.5B parameters. Our largest model reaches 57.9% wall-clock speedup over a parameter- and data-matched standard transformer at no perplexity cost.
WorldSpeech: A Multilingual Speech Corpus from Around the World
May 09, 2026Automatic speech recognition (ASR) performs well for high-resource languages with abundant paired audio-transcript data, but its accuracy degrades sharply for most languages due to limited publicly available aligned data. To this end, we introduce WorldSpeech, a 24 kHz multilingual speech corpus comprising 65k hours of aligned audio-transcript data across 76 languages, collected from diverse public sources including parliamentary proceedings, international broadcasts, and public-domain audiobooks. For 37 languages, WorldSpeech provides more than 200 hours of aligned speech, with 28 exceeding 500 hours and 24 surpassing 1k hours. Fine-tuning existing ASR models on WorldSpeech results in an average relative Word-Error-Rate reduction of 63.5% across 11 typologically diverse languages.
Can AI Agents Agree?
Mar 01, 2026Large language models are increasingly deployed as cooperating agents, yet their behavior in adversarial consensus settings has not been systematically studied. We evaluate LLM-based agents on a Byzantine consensus game over scalar values using a synchronous all-to-all simulation. We test consensus in a no-stake setting where agents have no preferences over the final value, so evaluation focuses on agreement rather than value optimality. Across hundreds of simulations spanning model sizes, group sizes, and Byzantine fractions, we find that valid agreement is not reliable even in benign settings and degrades as group size grows. Introducing a small number of Byzantine agents further reduces success. Failures are dominated by loss of liveness, such as timeouts and stalled convergence, rather than subtle value corruption. Overall, the results suggest that reliable agreement is not yet a dependable emergent capability of current LLM-agent groups even in no-stake settings, raising caution for deployments that rely on robust coordination.
Subliminal Signals in Preference Labels
Mar 01, 2026As AI systems approach superhuman capabilities, scalable oversight increasingly relies on LLM-as-a-judge frameworks where models evaluate and guide each other's training. A core assumption is that binary preference labels provide only semantic supervision about response quality. We challenge this assumption by demonstrating that preference labels can function as a covert communication channel. We show that even when a neutral student model generates semantically unbiased completions, a biased judge can transmit unintended behavioral traits through preference assignments, which even strengthen across iterative alignment rounds. Our findings suggest that robust oversight in superalignment settings requires mechanisms that can detect and mitigate subliminal preference transmission, particularly when judges may pursue unintended objectives.
Reasoning Boosts Opinion Alignment in LLMs
Mar 01, 2026Opinion modeling aims to capture individual or group political preferences, enabling applications such as digital democracies, where models could help shape fairer and more popular policies. Given their versatility, strong generalization capabilities, and demonstrated success across diverse text-to-text applications, large language models (LLMs) are natural candidates for this task. However, due to their statistical nature and limited causal understanding, they tend to produce biased opinions when prompted naively. In this work, we study whether reasoning can improve opinion alignment. Motivated by the recent advancement in mathematical reasoning enabled by reinforcement learning (RL), we train models to produce profile-consistent answers through structured reasoning. We evaluate our approach on three datasets covering U.S., European, and Swiss politics. Results indicate that reasoning enhances opinion modeling and is competitive with strong baselines, but does not fully remove bias, highlighting the need for additional mechanisms to build faithful political digital twins using LLMs. By releasing both our method and datasets, we establish a solid baseline to support future research on LLM opinion alignment.
Steering Pretrained Drafters during Speculative Decoding
Nov 13, 2025



Speculative decoding accelerates language model inference by separating generation into fast drafting and parallel verification. Its main limitation is drafter-verifier misalignment, which limits token acceptance and reduces overall effectiveness. While small drafting heads trained from scratch compensate with speed, they struggle when verification dominates latency or when inputs are out of distribution. In contrast, pretrained drafters, though slower, achieve higher acceptance rates thanks to stronger standalone generation capabilities, making them competitive when drafting latency is negligible relative to verification or communication overhead. In this work, we aim to improve the acceptance rates of pretrained drafters by introducing a lightweight dynamic alignment mechanism: a steering vector computed from the verifier's hidden states and injected into the pretrained drafter. Compared to existing offline alignment methods such as distillation, our approach boosts the number of accepted tokens by up to 35\% under standard sampling and 22\% under greedy sampling, all while incurring negligible computational overhead. Importantly, our approach can be retrofitted to existing architectures and pretrained models, enabling rapid adoption.
High-Fidelity Speech Enhancement via Discrete Audio Tokens
Oct 02, 2025


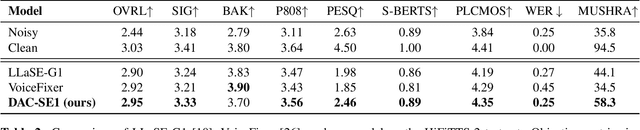
Recent autoregressive transformer-based speech enhancement (SE) methods have shown promising results by leveraging advanced semantic understanding and contextual modeling of speech. However, these approaches often rely on complex multi-stage pipelines and low sampling rate codecs, limiting them to narrow and task-specific speech enhancement. In this work, we introduce DAC-SE1, a simplified language model-based SE framework leveraging discrete high-resolution audio representations; DAC-SE1 preserves fine-grained acoustic details while maintaining semantic coherence. Our experiments show that DAC-SE1 surpasses state-of-the-art autoregressive SE methods on both objective perceptual metrics and in a MUSHRA human evaluation. We release our codebase and model checkpoints to support further research in scalable, unified, and high-quality speech enhancement.