 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hybrid Vision Transformer Approach for Mathematical Expression Recognition
Mar 09, 2026One of the crucial challenges taken in document analysis is mathematical expression recognition. Unlike text recognition which only focuses on one-dimensional structure images, mathematical expression recognition is a much more complicated problem because of its two-dimensional structure and different symbol size. In this paper, we propose using a Hybrid Vision Transformer (HVT) with 2D positional encoding as the encoder to extract the complex relationship between symbols from the image. A coverage attention decoder is used to better track attention's history to handle the under-parsing and over-parsing problems. We also showed the benefit of using the [CLS] token of ViT as the initial embedding of the decoder. Experiments performed on the IM2LATEX-100K dataset have shown the effectiveness of our method by achieving a BLEU score of 89.94 and outperforming current state-of-the-art methods.
How Many Tokens Do 3D Point Cloud Transformer Architectures Really Need?
Nov 07, 2025Recent advances in 3D point cloud transformers have led to state-of-the-art results in tasks such as semantic segmentation and reconstruction. However, these models typically rely on dense token representations, incurring high computational and memory costs during training and inference. In this work, we present the finding that tokens are remarkably redundant, leading to substantial inefficiency. We introduce gitmerge3D, a globally informed graph token merging method that can reduce the token count by up to 90-95% while maintaining competitive performance. This finding challenges the prevailing assumption that more tokens inherently yield better performance and highlights that many current models are over-tokenized and under-optimized for scalability. We validate our method across multiple 3D vision tasks and show consistent improvements in computational efficiency. This work is the first to assess redundancy in large-scale 3D transformer models, providing insights into the development of more efficient 3D foundation architectures. Our code and checkpoints are publicly available at https://gitmerge3d.github.io
PaaS: Planning as a Service for reactive driving in CARLA Leaderboard
Apr 27, 2023End-to-end deep learning approaches has been proven to be efficient in autonomous driving and robotics. By using deep learning techniques for decision-making, those systems are often referred to as a black box, and the result is driven by data. In this paper, we propose PaaS (Planning as a Service), a vanilla module to generate local trajectory planning for autonomous driving in CARLA simulation. Our method is submitted in International CARLA Autonomous Driving Leaderboard (CADL), which is a platform to evaluate the driving proficiency of autonomous agents in realistic traffic scenarios. Our approach focuses on reactive planning in Frenet frame under complex urban street's constraints and driver's comfort. The planner generates a collection of feasible trajectories, leveraging heuristic cost functions with controllable driving style factor to choose the optimal-control path that satisfies safe travelling criteria. PaaS can provide sufficient solutions to handle well under challenging traffic situations in CADL. As the strict evaluation in CADL Map Track, our approach ranked 3rd out of 9 submissions regarding the measure of driving score. However, with the focus on minimizing the risk of maneuver and ensuring passenger safety, our figures corresponding to infraction penalty dominate the two leading submissions for 20 percent.
Improving Pareto Front Learning via Multi-Sample Hypernetworks
Dec 02, 2022Pareto Front Learning (PFL) was recently introduced as an effective approach to obtain a mapping function from a given trade-off vector to a solution on the Pareto front, which solves the multi-objective optimization (MOO) problem. Due to the inherent trade-off between conflicting objectives, PFL offers a flexible approach in many scenarios in which the decision makers can not specify the preference of one Pareto solution over another, and must switch between them depending on the situation. However, existing PFL methods ignore the relationship between the solutions during the optimization process, which hinders the quality of the obtained front. To overcome this issue, we propose a novel PFL framework namely \ourmodel, which employs a hypernetwork to generate multiple solutions from a set of diverse trade-off preferences and enhance the quality of the Pareto front by maximizing the Hypervolume indicator defined by these solutions. The experimental results on several MOO machine learning tasks show that the proposed framework significantly outperforms the baselines in producing the trade-off Pareto front.
Semantic Instance Segmentation of 3D Scenes Through Weak Bounding Box Supervision
Jun 02, 2022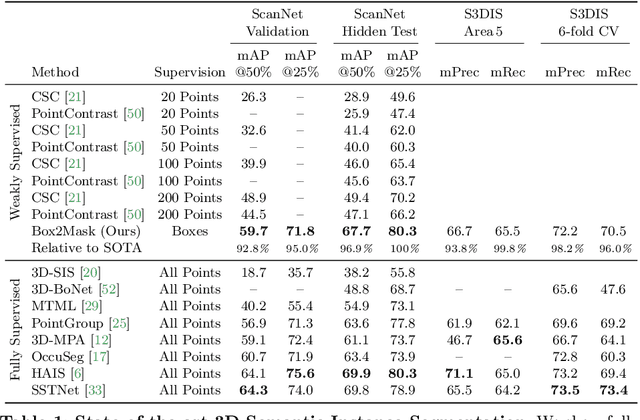
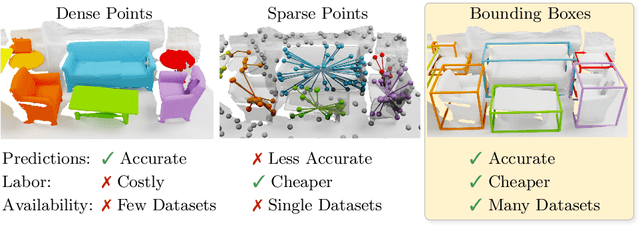
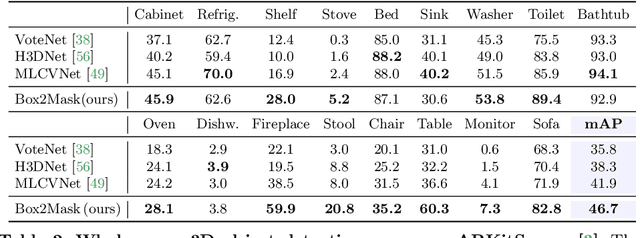
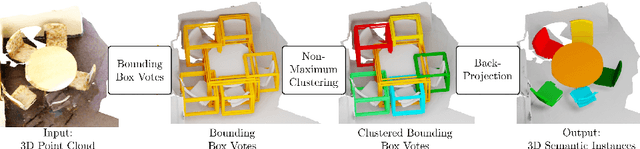
Current 3D segmentation methods heavily rely on large-scale point-cloud datasets, which are notoriously laborious to annotate. Few attempts have been made to circumvent the need for dense per-point annotations. In this work, we look at weakly-supervised 3D instance semantic segmentation. The key idea is to leverage 3D bounding box labels which are easier and faster to annotate. Indeed, we show that it is possible to train dense segmentation models using only weak bounding box labels. At the core of our method, Box2Mask, lies a deep model, inspired by classical Hough voting, that directly votes for bounding box parameters, and a clustering method specifically tailored to bounding box votes. This goes beyond commonly used center votes, which would not fully exploit the bounding box annotations. On ScanNet test, our weakly supervised model attains leading performance among other weakly supervised approaches (+18 mAP50). Remarkably, it also achieves 97% of the performance of fully supervised models. To prove the practicality of our approach, we show segmentation results on the recently released ARKitScenes dataset which is annotated with 3D bounding boxes only, and obtain, for the first time, compelling 3D instance segmentation results.