 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoei Herzig
Structured Video Tokens @ Ego4D PNR Temporal Localization Challenge 2022
Jun 15, 2022

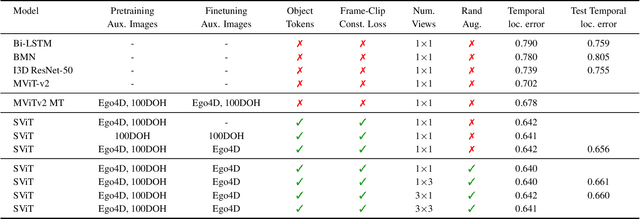
This technical report describes the SViT approach for the Ego4D Point of No Return (PNR) Temporal Localization Challenge. We propose a learning framework StructureViT (SViT for short), which demonstrates how utilizing the structure of a small number of images only available during training can improve a video model. SViT relies on two key insights. First, as both images and videos contain structured information, we enrich a transformer model with a set of \emph{object tokens} that can be used across images and videos. Second, the scene representations of individual frames in video should "align" with those of still images. This is achieved via a "Frame-Clip Consistency" loss, which ensures the flow of structured information between images and videos. SViT obtains strong performance on the challenge test set with 0.656 absolute temporal localization error.
Bringing Image Scene Structure to Video via Frame-Clip Consistency of Object Tokens
Jun 15, 2022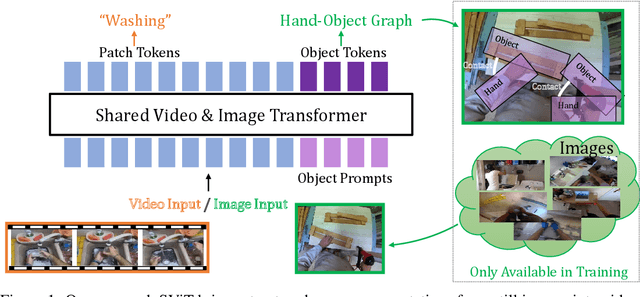
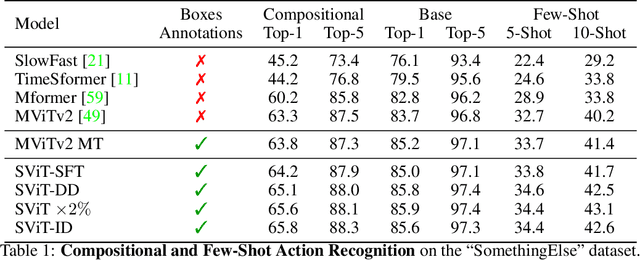
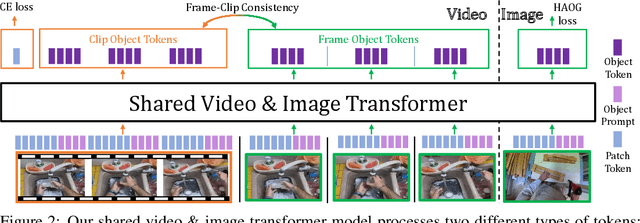
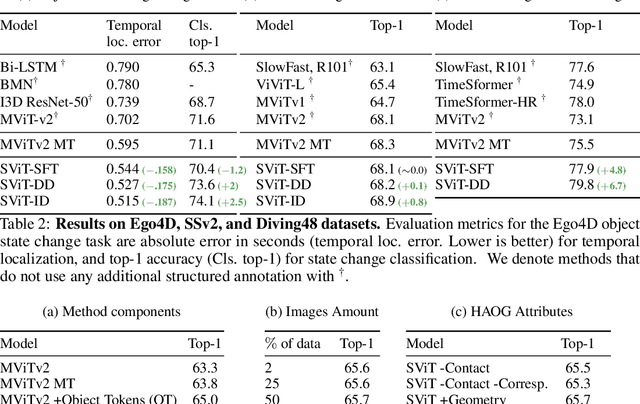
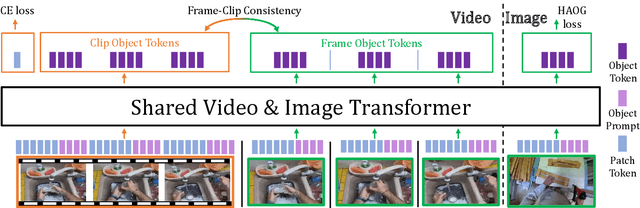
Recent action recognition models have achieved impressive results by integrating objects, their locations and interactions. However, obtaining dense structured annotations for each frame is tedious and time-consuming, making these methods expensive to train and less scalable. At the same time, if a small set of annotated images is available, either within or outside the domain of interest, how could we leverage these for a video downstream task? We propose a learning framework StructureViT (SViT for short), which demonstrates how utilizing the structure of a small number of images only available during training can improve a video model. SViT relies on two key insights. First, as both images and videos contain structured information, we enrich a transformer model with a set of \emph{object tokens} that can be used across images and videos. Second, the scene representations of individual frames in video should "align" with those of still images. This is achieved via a \emph{Frame-Clip Consistency} loss, which ensures the flow of structured information between images and videos. We explore a particular instantiation of scene structure, namely a \emph{Hand-Object Graph}, consisting of hands and objects with their locations as nodes, and physical relations of contact/no-contact as edges. SViT shows strong performance improvements on multiple video understanding tasks and datasets. Furthermore, it won in the Ego4D CVPR'22 Object State Localization challenge. For code and pretrained models, visit the project page at \url{https://eladb3.github.io/SViT/}
Unsupervised Domain Generalization by Learning a Bridge Across Domains
Dec 04, 2021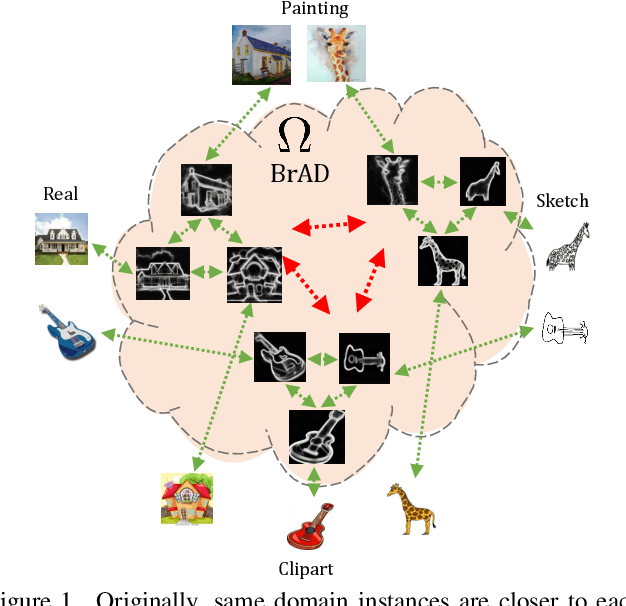
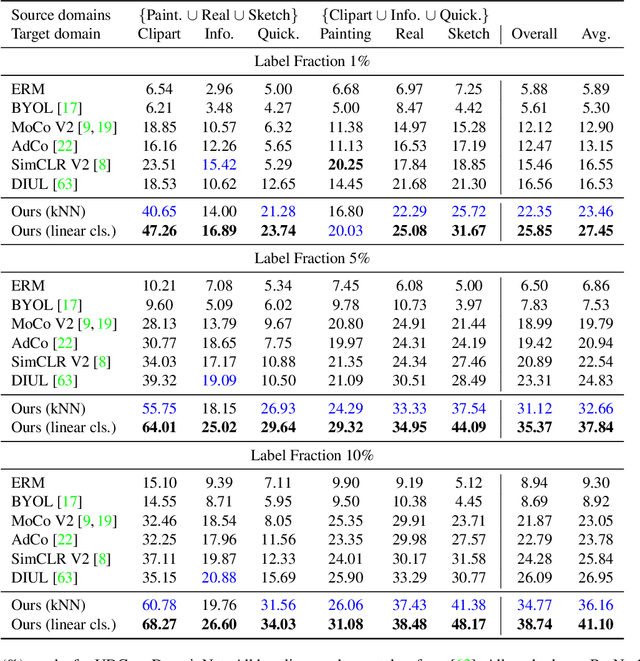
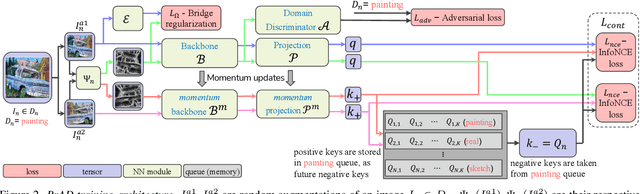
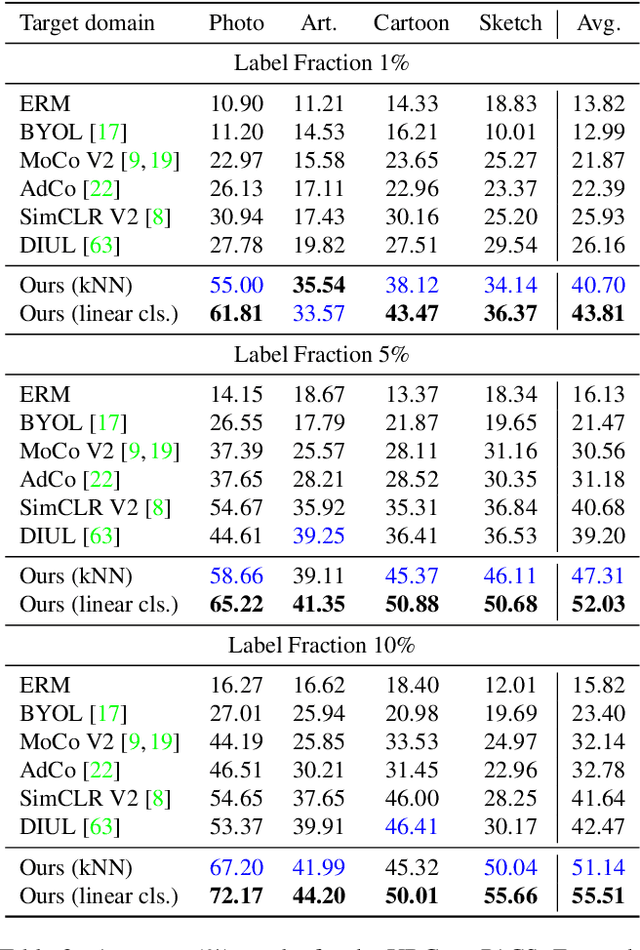
The ability to generalize learned representations across significantly different visual domains, such as between real photos, clipart, paintings, and sketches, is a fundamental capacity of the human visual system. In this paper, different from most cross-domain works that utilize some (or full) source domain supervision, we approach a relatively new and very practical Unsupervised Domain Generalization (UDG) setup of having no training supervision in neither source nor target domains. Our approach is based on self-supervised learning of a Bridge Across Domains (BrAD) - an auxiliary bridge domain accompanied by a set of semantics preserving visual (image-to-image) mappings to BrAD from each of the training domains. The BrAD and mappings to it are learned jointly (end-to-end) with a contrastive self-supervised representation model that semantically aligns each of the domains to its BrAD-projection, and hence implicitly drives all the domains (seen or unseen) to semantically align to each other. In this work, we show how using an edge-regularized BrAD our approach achieves significant gains across multiple benchmarks and a range of tasks, including UDG, Few-shot UDA, and unsupervised generalization across multi-domain datasets (including generalization to unseen domains and classes).
Object-Region Video Transformers
Oct 13, 2021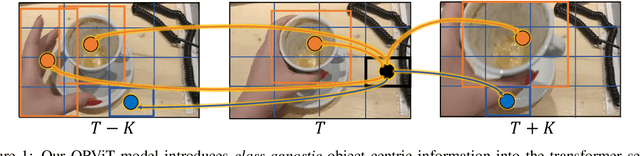
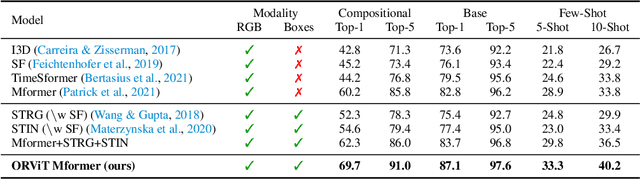
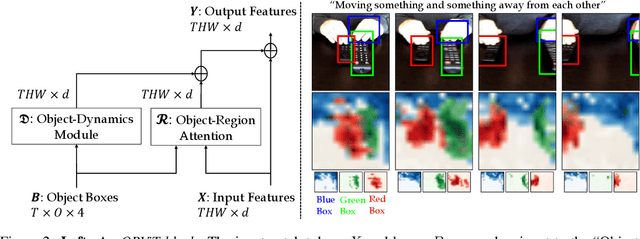
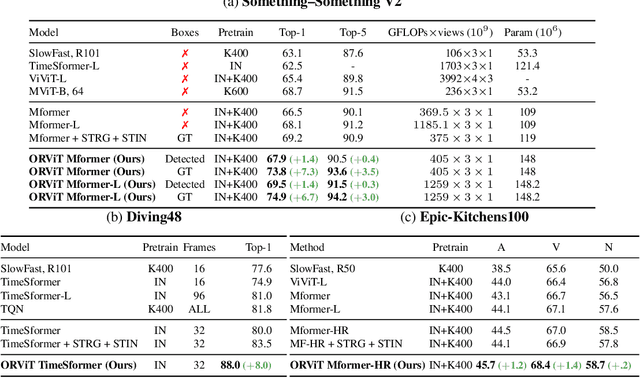
Evidence from cognitive psychology suggests that understanding spatio-temporal object interactions and dynamics can be essential for recognizing actions in complex videos. Therefore, action recognition models are expected to benefit from explicit modeling of objects, including their appearance, interaction, and dynamics. Recently, video transformers have shown great success in video understanding, exceeding CNN performance. Yet, existing video transformer models do not explicitly model objects. In this work, we present Object-Region Video Transformers (ORViT), an \emph{object-centric} approach that extends video transformer layers with a block that directly incorporates object representations. The key idea is to fuse object-centric spatio-temporal representations throughout multiple transformer layers. Our ORViT block consists of two object-level streams: appearance and dynamics. In the appearance stream, an ``Object-Region Attention'' element applies self-attention over the patches and \emph{object regions}. In this way, visual object regions interact with uniform patch tokens and enrich them with contextualized object information. We further model object dynamics via a separate ``Object-Dynamics Module'', which captures trajectory interactions, and show how to integrate the two streams. We evaluate our model on standard and compositional action recognition on Something-Something V2, standard action recognition on Epic-Kitchen100 and Diving48, and spatio-temporal action detection on AVA. We show strong improvement in performance across all tasks and datasets considered, demonstrating the value of a model that incorporates object representations into a transformer architecture. For code and pretrained models, visit the project page at https://roeiherz.github.io/ORViT/.
DETReg: Unsupervised Pretraining with Region Priors for Object Detection
Jun 08, 2021
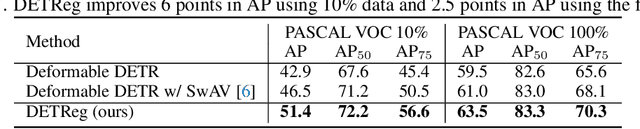
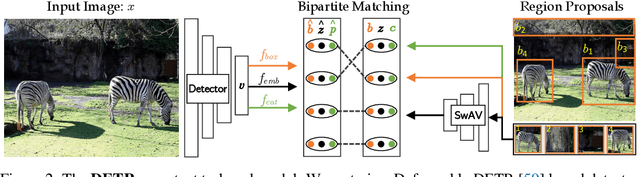
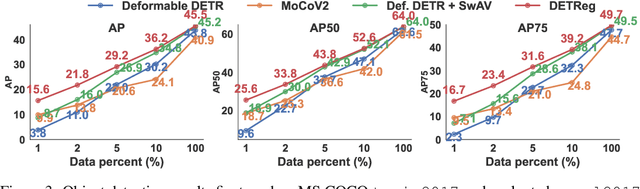
Unsupervised pretraining has recently proven beneficial for computer vision tasks, including object detection. However, previous self-supervised approaches are not designed to handle a key aspect of detection: localizing objects. Here, we present DETReg, an unsupervised pretraining approach for object DEtection with TRansformers using Region priors. Motivated by the two tasks underlying object detection: localization and categorization, we combine two complementary signals for self-supervision. For an object localization signal, we use pseudo ground truth object bounding boxes from an off-the-shelf unsupervised region proposal method, Selective Search, which does not require training data and can detect objects at a high recall rate and very low precision. The categorization signal comes from an object embedding loss that encourages invariant object representations, from which the object category can be inferred. We show how to combine these two signals to train the Deformable DETR detection architecture from large amounts of unlabeled data. DETReg improves the performance over competitive baselines and previous self-supervised methods on standard benchmarks like MS COCO and PASCAL VOC. DETReg also outperforms previous supervised and unsupervised baseline approaches on low-data regime when trained with only 1%, 2%, 5%, and 10% of the labeled data on MS COCO. For code and pretrained models, visit the project page at https://amirbar.net/detreg
Learning Object Detection from Captions via Textual Scene Attributes
Sep 30, 2020


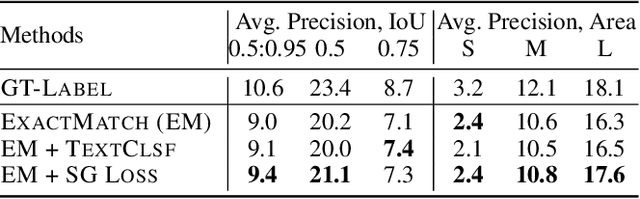
Object detection is a fundamental task in computer vision, requiring large annotated datasets that are difficult to collect, as annotators need to label objects and their bounding boxes. Thus, it is a significant challenge to use cheaper forms of supervision effectively. Recent work has begun to explore image captions as a source for weak supervision, but to date, in the context of object detection, captions have only been used to infer the categories of the objects in the image. In this work, we argue that captions contain much richer information about the image, including attributes of objects and their relations. Namely, the text represents a scene of the image, as described recently in the literature. We present a method that uses the attributes in this "textual scene graph" to train object detectors. We empirically demonstrate that the resulting model achieves state-of-the-art results on several challenging object detection datasets, outperforming recent approaches.
Compositional Video Synthesis with Action Graphs
Jul 13, 2020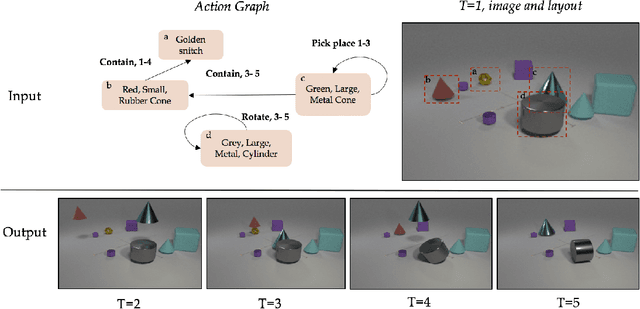
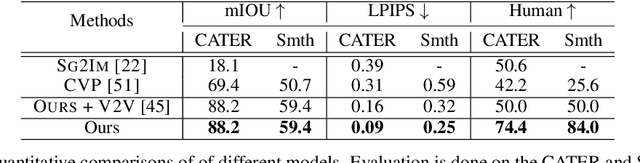
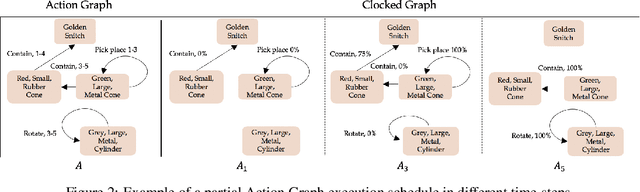
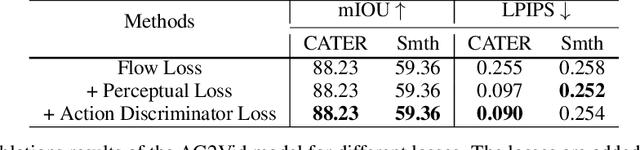
Videos of actions are complex spatio-temporal signals, containing rich compositional structures. Current generative models are limited in their ability to generate examples of object configurations outside the range they were trained on. Towards this end, we introduce a generative model (AG2Vid) based on Action Graphs, a natural and convenient structure that represents the dynamics of actions between objects over time. Our AG2Vid model disentangles appearance and position features, allowing for more accurate generation. AG2Vid is evaluated on the CATER and Something-Something datasets and outperforms other baselines. Finally, we show how Action Graphs can be used for generating novel compositions of unseen actions.
Something-Else: Compositional Action Recognition with Spatial-Temporal Interaction Networks
Dec 20, 2019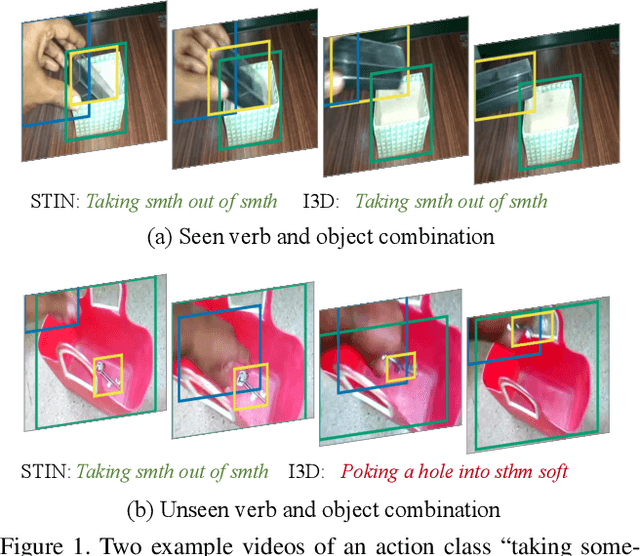
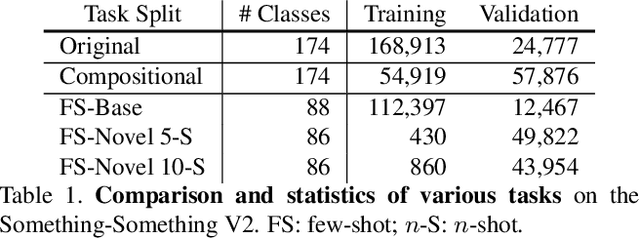
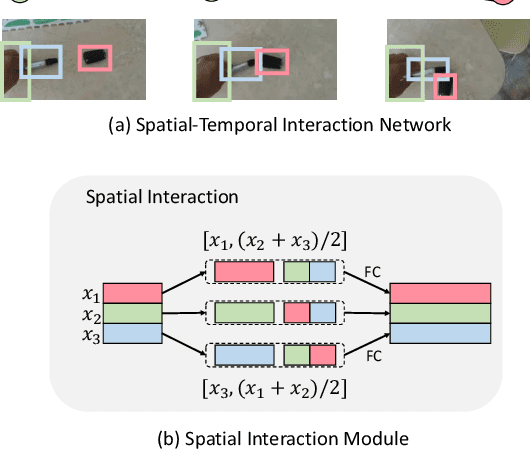
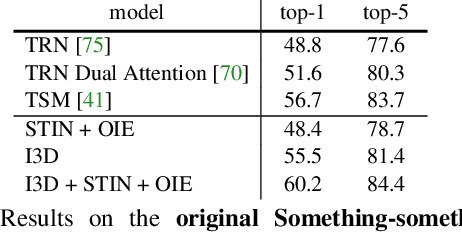
Human action is naturally compositional: humans can easily recognize and perform actions with objects that are different from those used in training demonstrations. In this paper, we study the compositionality of action by looking into the dynamics of subject-object interactions. We propose a novel model which can explicitly reason about the geometric relations between constituent objects and an agent performing an action. To train our model, we collect dense object box annotations on the Something-Something dataset. We propose a novel compositional action recognition task where the training combinations of verbs and nouns do not overlap with the test set. The novel aspects of our model are applicable to activities with prominent object interaction dynamics and to objects which can be tracked using state-of-the-art approaches; for activities without clearly defined spatial object-agent interactions, we rely on baseline scene-level spatio-temporal representations. We show the effectiveness of our approach not only on the proposed compositional action recognition task, but also in a few-shot compositional setting which requires the model to generalize across both object appearance and action category.
Learning Canonical Representations for Scene Graph to Image Generation
Dec 16, 2019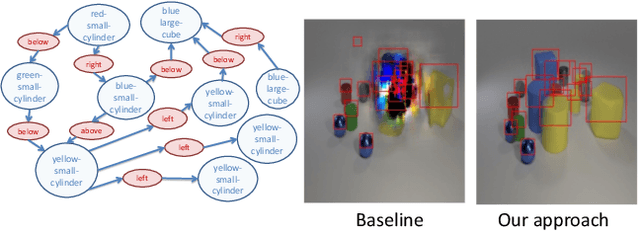
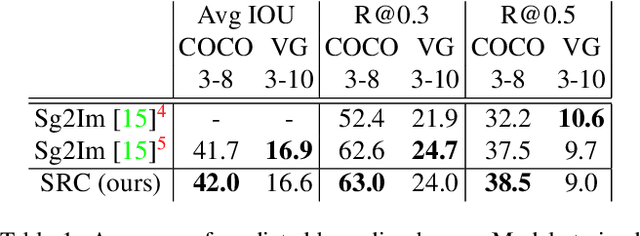
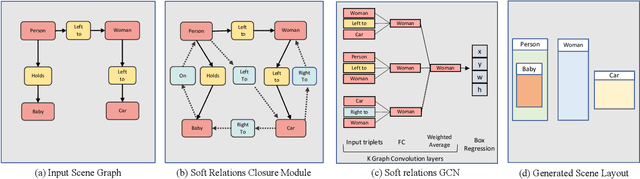
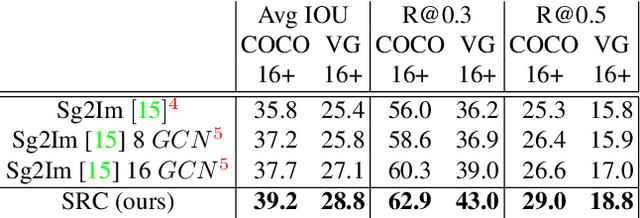
Generating realistic images of complex visual scenes becomes very challenging when one wishes to control the structure of the generated images. Previous approaches showed that scenes with few entities can be controlled using scene graphs, but this approach struggles as the complexity of the graph (number of objects and edges) increases. Moreover, current approaches fail to generalize conditioned on the number of objects or when given different input graphs which are semantic equivalent. In this work, we propose a novel approach to mitigate these issues. We present a novel model which can inherently learn canonical graph representations, thus ensuring that semantically similar scene graphs will result in similar predictions. In addition, the proposed model can better capture object representation independently of the number of objects in the graph. We show improved performance of the model on three different benchmarks: Visual Genome, COCO and CLEVR.