 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Long-tail Generalization with Likelihood Splits
Oct 13, 2022

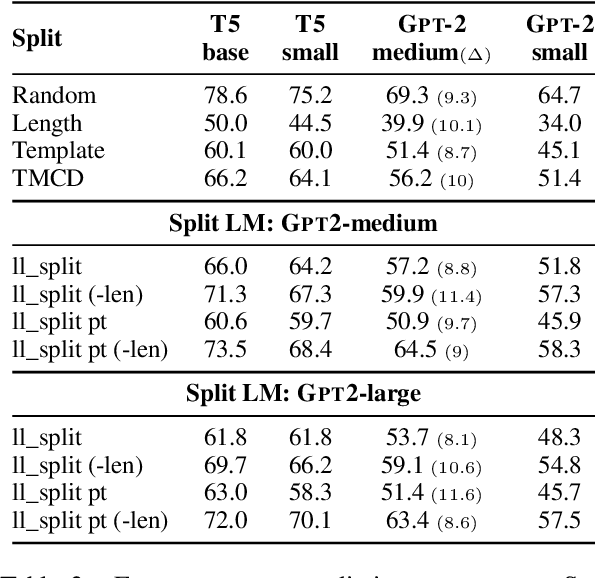
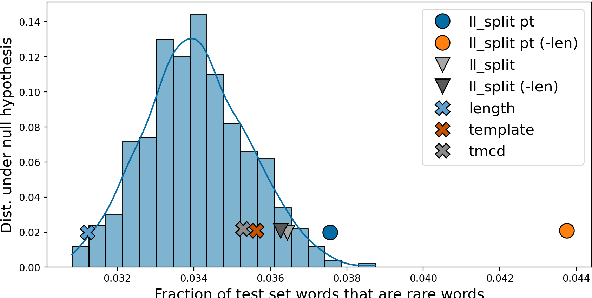
In order to reliably process natural language, NLP systems must generalize to the long tail of rare utterances. We propose a method to create challenging benchmarks that require generalizing to the tail of the distribution by re-splitting existing datasets. We create 'Likelihood splits' where examples that are assigned lower likelihood by a pre-trained language model (LM) are placed in the test set, and more likely examples are in the training set. This simple approach can be customized to construct meaningful train-test splits for a wide range of tasks. Likelihood splits are more challenging than random splits: relative error rates of state-of-the-art models on our splits increase by 59% for semantic parsing on Spider, 77% for natural language inference on SNLI, and 38% for yes/no question answering on BoolQ compared with the corresponding random splits. Moreover, Likelihood splits create fairer benchmarks than adversarial filtering; when the LM used to create the splits is used as the task model, our splits do not adversely penalize the LM.
Are Sample-Efficient NLP Models More Robust?
Oct 12, 2022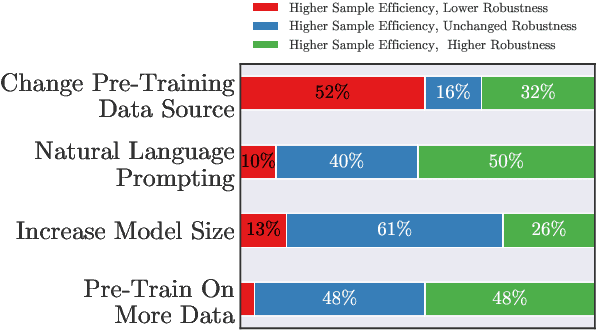
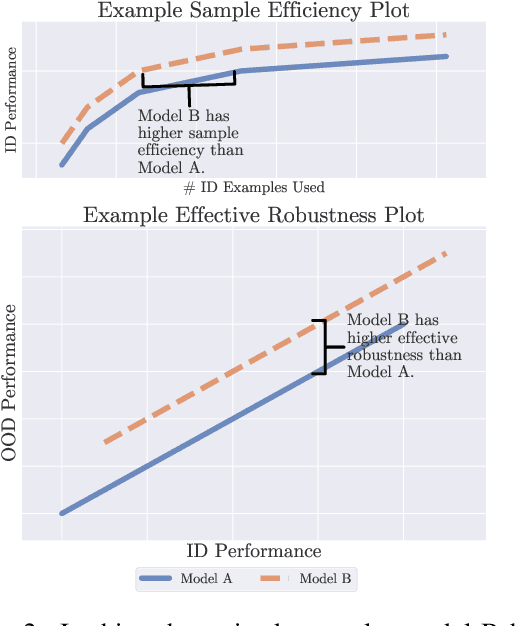
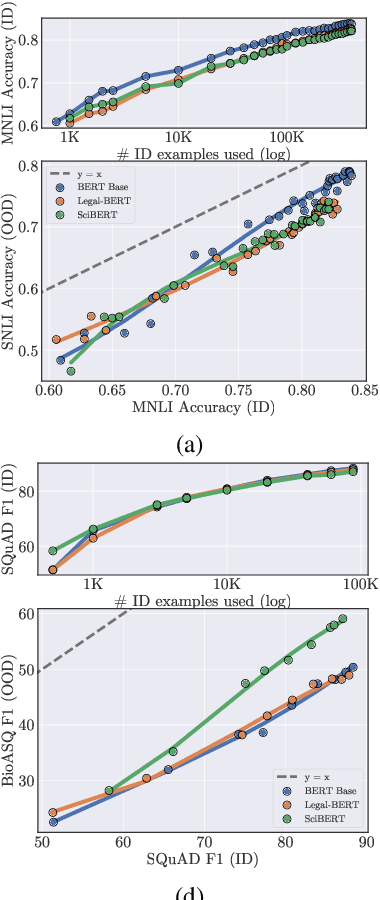
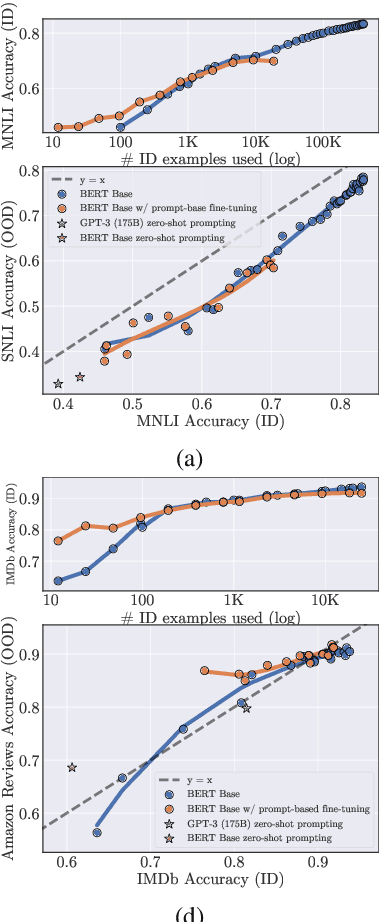
Recent work has observed that pre-trained models have higher out-of-distribution (OOD) robustness when they are exposed to less in-distribution (ID) training data (Radford et al., 2021). In particular, zero-shot models (e.g., GPT-3 and CLIP) have higher robustness than conventionally fine-tuned models, but these robustness gains fade as zero-shot models are fine-tuned on more ID data. We study this relationship between sample efficiency and robustness -- if two models have the same ID performance, does the model trained on fewer examples (higher sample efficiency) perform better OOD (higher robustness)? Surprisingly, experiments across three tasks, 23 total ID-OOD settings, and 14 models do not reveal a consistent relationship between sample efficiency and robustness -- while models with higher sample efficiency are sometimes more robust, most often there is no change in robustness, with some cases even showing decreased robustness. Since results vary on a case-by-case basis, we conduct detailed case studies of two particular ID-OOD pairs (SST-2 -> IMDb sentiment and SNLI -> HANS) to better understand why better sample efficiency may or may not yield higher robustness; attaining such an understanding requires case-by-case analysis of why models are not robust on a particular ID-OOD setting and how modeling techniques affect model capabilities.
On Continual Model Refinement in Out-of-Distribution Data Streams
May 04, 2022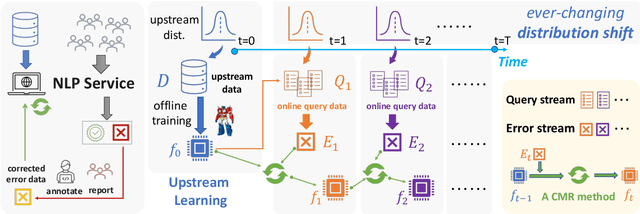
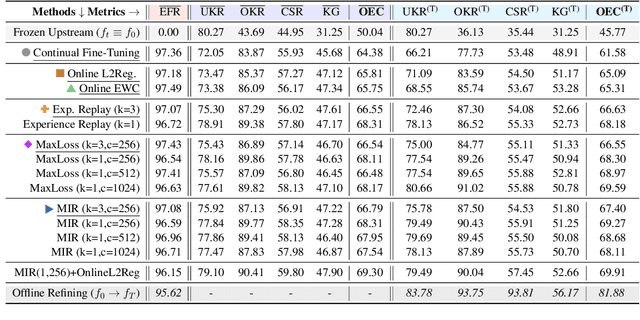
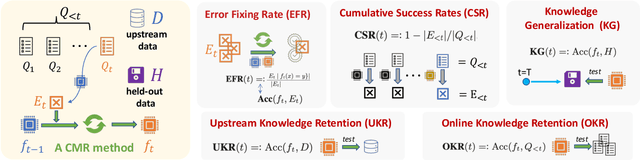
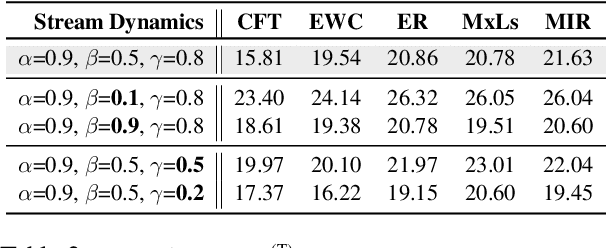
Real-world natural language processing (NLP) models need to be continually updated to fix the prediction errors in out-of-distribution (OOD) data streams while overcoming catastrophic forgetting. However, existing continual learning (CL) problem setups cannot cover such a realistic and complex scenario. In response to this, we propose a new CL problem formulation dubbed continual model refinement (CMR). Compared to prior CL settings, CMR is more practical and introduces unique challenges (boundary-agnostic and non-stationary distribution shift, diverse mixtures of multiple OOD data clusters, error-centric streams, etc.). We extend several existing CL approaches to the CMR setting and evaluate them extensively. For benchmarking and analysis, we propose a general sampling algorithm to obtain dynamic OOD data streams with controllable non-stationarity, as well as a suite of metrics measuring various aspects of online performance. Our experiments and detailed analysis reveal the promise and challenges of the CMR problem, supporting that studying CMR in dynamic OOD streams can benefit the longevity of deployed NLP models in production.
Knowledge Base Question Answering by Case-based Reasoning over Subgraphs
Feb 22, 2022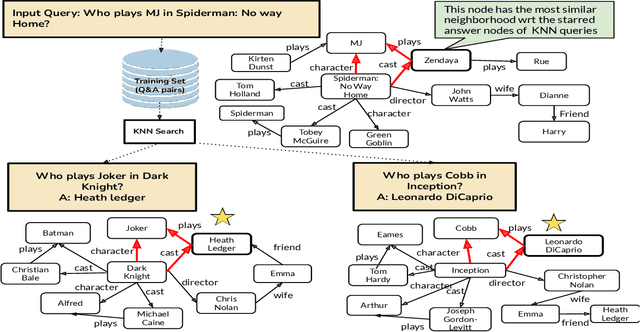
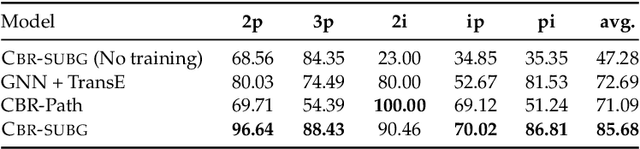
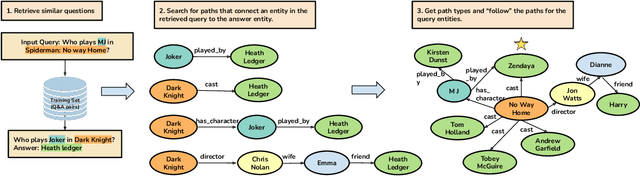
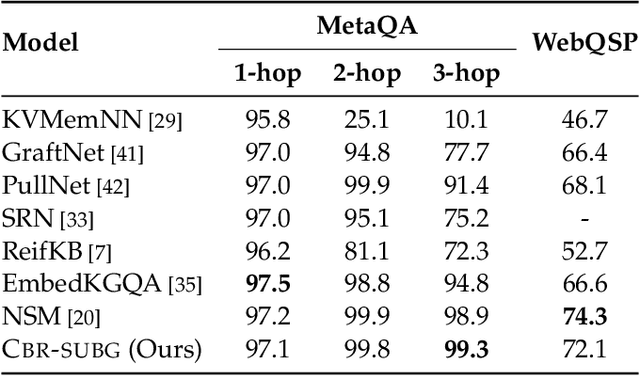
Question answering (QA) over real-world knowledge bases (KBs) is challenging because of the diverse (essentially unbounded) types of reasoning patterns needed. However, we hypothesize in a large KB, reasoning patterns required to answer a query type reoccur for various entities in their respective subgraph neighborhoods. Leveraging this structural similarity between local neighborhoods of different subgraphs, we introduce a semiparametric model with (i) a nonparametric component that for each query, dynamically retrieves other similar $k$-nearest neighbor (KNN) training queries along with query-specific subgraphs and (ii) a parametric component that is trained to identify the (latent) reasoning patterns from the subgraphs of KNN queries and then apply it to the subgraph of the target query. We also propose a novel algorithm to select a query-specific compact subgraph from within the massive knowledge graph (KG), allowing us to scale to full Freebase KG containing billions of edges. We show that our model answers queries requiring complex reasoning patterns more effectively than existing KG completion algorithms. The proposed model outperforms or performs competitively with state-of-the-art models on several KBQA benchmarks.
Models in the Loop: Aiding Crowdworkers with Generative Annotation Assistants
Dec 16, 2021

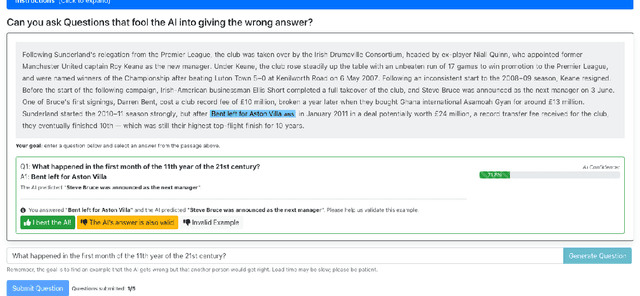

In Dynamic Adversarial Data Collection (DADC), human annotators are tasked with finding examples that models struggle to predict correctly. Models trained on DADC-collected training data have been shown to be more robust in adversarial and out-of-domain settings, and are considerably harder for humans to fool. However, DADC is more time-consuming than traditional data collection and thus more costly per example. In this work, we examine if we can maintain the advantages of DADC, without suffering the additional cost. To that end, we introduce Generative Annotation Assistants (GAAs), generator-in-the-loop models that provide real-time suggestions that annotators can either approve, modify, or reject entirely. We collect training datasets in twenty experimental settings and perform a detailed analysis of this approach for the task of extractive question answering (QA) for both standard and adversarial data collection. We demonstrate that GAAs provide significant efficiency benefits in terms of annotation speed, while leading to improved model fooling rates. In addition, we show that GAA-assisted data leads to higher downstream model performance on a variety of question answering tasks.
On the Robustness of Reading Comprehension Models to Entity Renaming
Oct 16, 2021
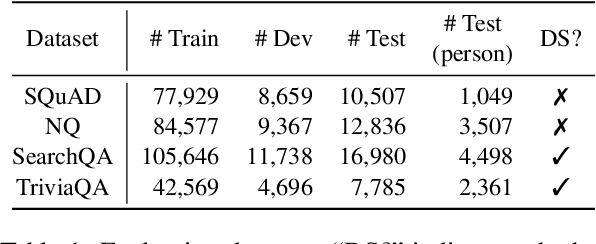
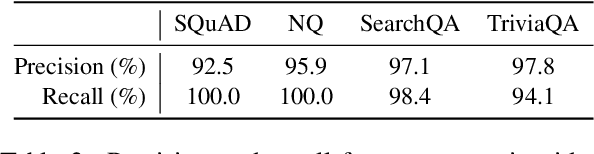

We study the robustness of machine reading comprehension (MRC) models to entity renaming -- do models make more wrong predictions when answer entities have different names? Such failures would indicate that models are overly reliant on entity knowledge to answer questions, and therefore may generalize poorly when facts about the world change or questions are asked about novel entities. To systematically audit model robustness, we propose a general and scalable method to replace person names with names from a variety of sources, ranging from common English names to names from other languages to arbitrary strings. Across four datasets and three pretrained model architectures, MRC models consistently perform worse when entities are renamed, with particularly large accuracy drops on datasets constructed via distant supervision. We also find large differences between models: SpanBERT, which is pretrained with span-level masking, is more robust than RoBERTa, despite having similar accuracy on unperturbed test data. Inspired by this, we experiment with span-level and entity-level masking as a continual pretraining objective and find that they can further improve the robustness of MRC models.
Analyzing Dynamic Adversarial Training Data in the Limit
Oct 16, 2021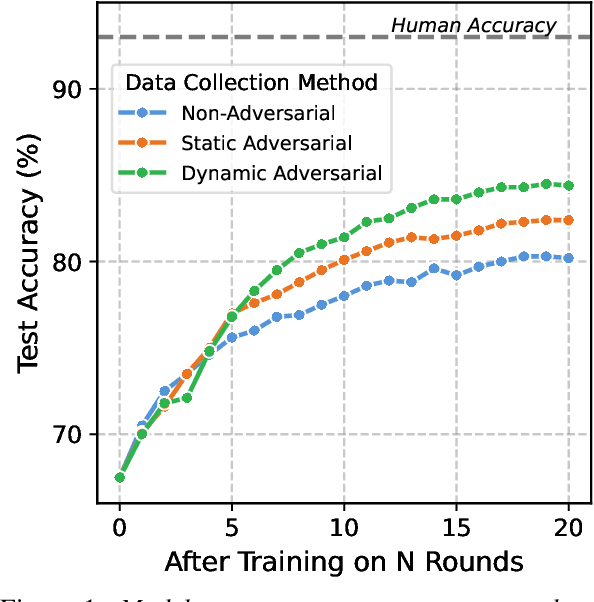
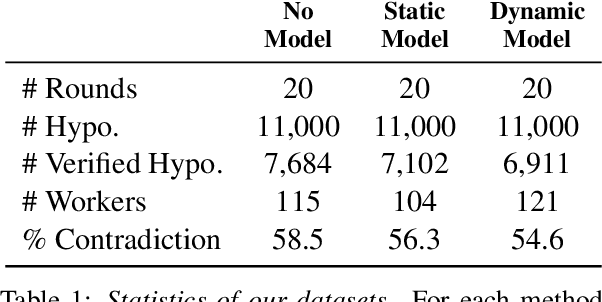

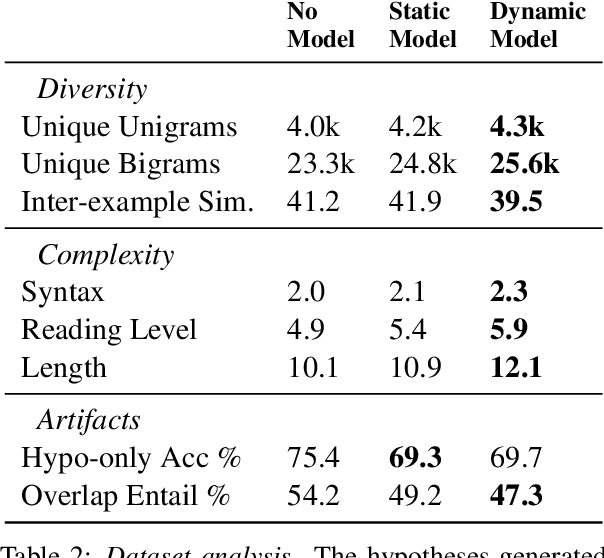
To create models that are robust across a wide range of test inputs, training datasets should include diverse examples that span numerous phenomena. Dynamic adversarial data collection (DADC), where annotators craft examples that challenge continually improving models, holds promise as an approach for generating such diverse training sets. Prior work has shown that running DADC over 1-3 rounds can help models fix some error types, but it does not necessarily lead to better generalization beyond adversarial test data. We argue that running DADC over many rounds maximizes its training-time benefits, as the different rounds can together cover many of the task-relevant phenomena. We present the first study of longer-term DADC, where we collect 20 rounds of NLI examples for a small set of premise paragraphs, with both adversarial and non-adversarial approaches. Models trained on DADC examples make 26% fewer errors on our expert-curated test set compared to models trained on non-adversarial data. Our analysis shows that DADC yields examples that are more difficult, more lexically and syntactically diverse, and contain fewer annotation artifacts compared to non-adversarial examples.
Question Answering Infused Pre-training of General-Purpose Contextualized Representations
Jun 15, 2021
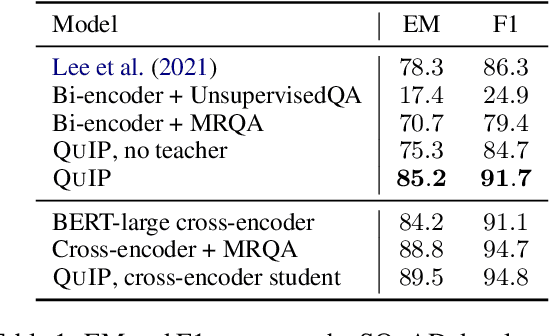
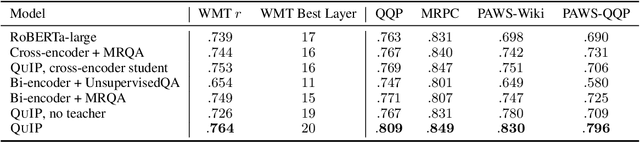
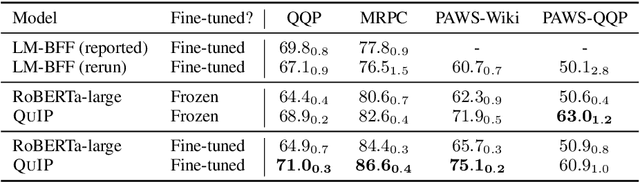
This paper proposes a pre-training objective based on question answering (QA) for learning general-purpose contextual representations, motivated by the intuition that the representation of a phrase in a passage should encode all questions that the phrase can answer in context. We accomplish this goal by training a bi-encoder QA model, which independently encodes passages and questions, to match the predictions of a more accurate cross-encoder model on 80 million synthesized QA pairs. By encoding QA-relevant information, the bi-encoder's token-level representations are useful for non-QA downstream tasks without extensive (or in some cases, any) fine-tuning. We show large improvements over both RoBERTa-large and previous state-of-the-art results on zero-shot and few-shot paraphrase detection on four datasets, few-shot named entity recognition on two datasets, and zero-shot sentiment analysis on three datasets.
Swords: A Benchmark for Lexical Substitution with Improved Data Coverage and Quality
Jun 12, 2021
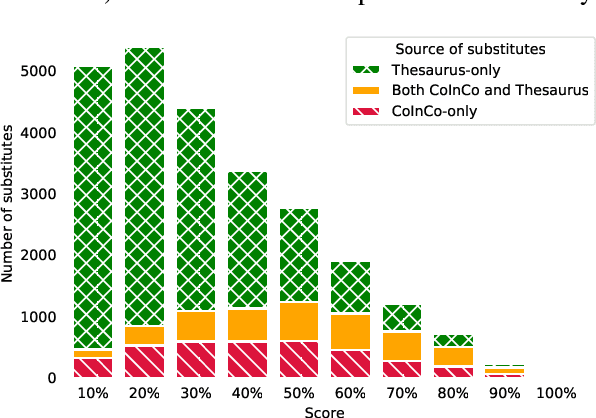
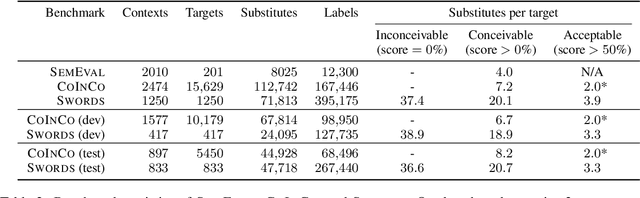
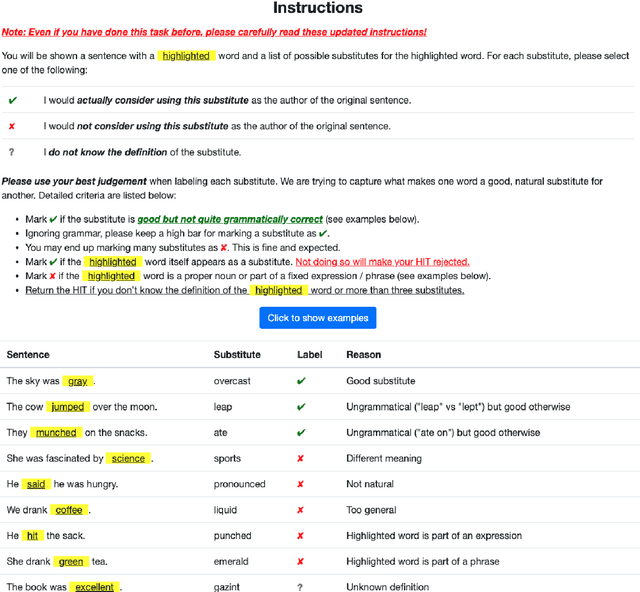
We release a new benchmark for lexical substitution, the task of finding appropriate substitutes for a target word in a context. To assist humans with writing, lexical substitution systems can suggest words that humans cannot easily think of. However, existing benchmarks depend on human recall as the only source of data, and therefore lack coverage of the substitutes that would be most helpful to humans. Furthermore, annotators often provide substitutes of low quality, which are not actually appropriate in the given context. We collect higher-coverage and higher-quality data by framing lexical substitution as a classification problem, guided by the intuition that it is easier for humans to judge the appropriateness of candidate substitutes than conjure them from memory. To this end, we use a context-free thesaurus to produce candidates and rely on human judgement to determine contextual appropriateness. Compared to the previous largest benchmark, our Swords benchmark has 4.1x more substitutes per target word for the same level of quality, and its substitutes are 1.5x more appropriate (based on human judgement) for the same number of substitutes.
The statistical advantage of automatic NLG metrics at the system level
May 26, 2021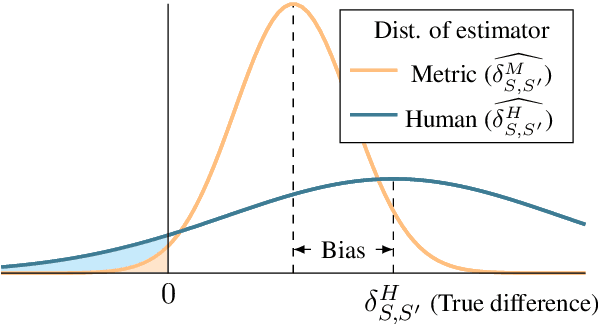

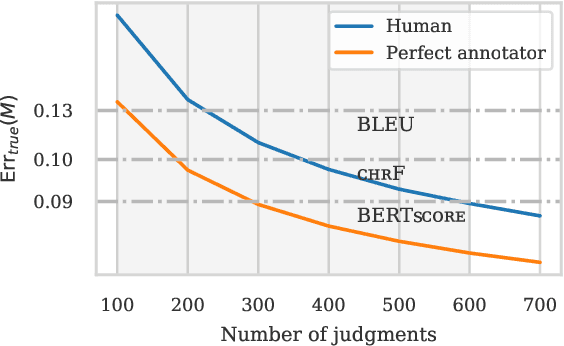

Estimating the expected output quality of generation systems is central to NLG. This paper qualifies the notion that automatic metrics are not as good as humans in estimating system-level quality. Statistically, humans are unbiased, high variance estimators, while metrics are biased, low variance estimators. We compare these estimators by their error in pairwise prediction (which generation system is better?) using the bootstrap. Measuring this error is complicated: predictions are evaluated against noisy, human predicted labels instead of the ground truth, and metric predictions fluctuate based on the test sets they were calculated on. By applying a bias-variance-noise decomposition, we adjust this error to a noise-free, infinite test set setting. Our analysis compares the adjusted error of metrics to humans and a derived, perfect segment-level annotator, both of which are unbiased estimators dependent on the number of judgments collected. In MT, we identify two settings where metrics outperform humans due to a statistical advantage in variance: when the number of human judgments used is small, and when the quality difference between compared systems is small. The data and code to reproduce our analyses are available at https://github.com/johntzwei/metric-statistical-advantage .