 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Role of Training Regimes in Continual Learning
Jun 12, 2020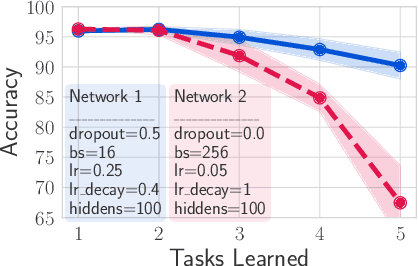
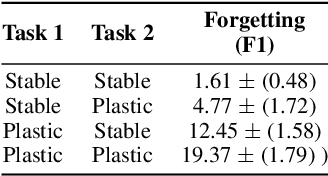
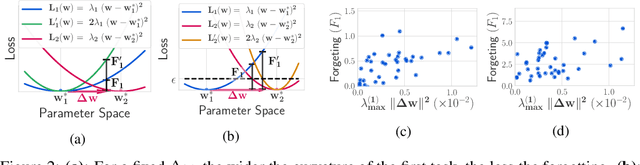
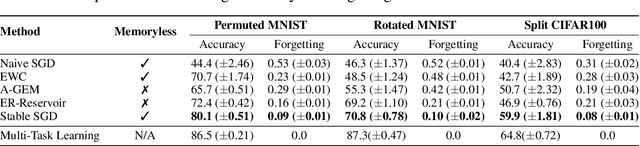
Catastrophic forgetting affects the training of neural networks, limiting their ability to learn multiple tasks sequentially. From the perspective of the well established plasticity-stability dilemma, neural networks tend to be overly plastic, lacking the stability necessary to prevent the forgetting of previous knowledge, which means that as learning progresses, networks tend to forget previously seen tasks. This phenomenon coined in the continual learning literature, has attracted much attention lately, and several families of approaches have been proposed with different degrees of success. However, there has been limited prior work extensively analyzing the impact that different training regimes -- learning rate, batch size, regularization method-- can have on forgetting. In this work, we depart from the typical approach of altering the learning algorithm to improve stability. Instead, we hypothesize that the geometrical properties of the local minima found for each task play an important role in the overall degree of forgetting. In particular, we study the effect of dropout, learning rate decay, and batch size, on forming training regimes that widen the tasks' local minima and consequently, on helping it not to forget catastrophically. Our study provides practical insights to improve stability via simple yet effective techniques that outperform alternative baselines.
Pointer Graph Networks
Jun 11, 2020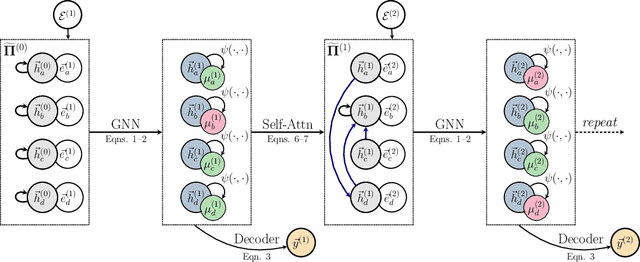


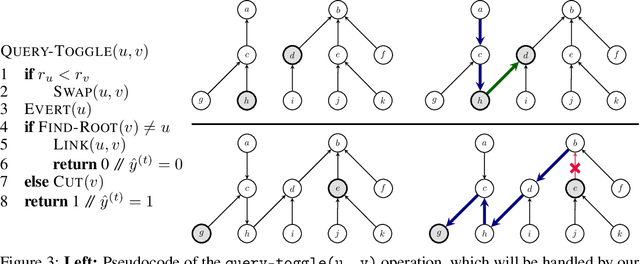
Graph neural networks (GNNs) are typically applied to static graphs that are assumed to be known upfront. This static input structure is often informed purely by insight of the machine learning practitioner, and might not be optimal for the actual task the GNN is solving. In absence of reliable domain expertise, one might resort to inferring the latent graph structure, which is often difficult due to the vast search space of possible graphs. Here we introduce Pointer Graph Networks (PGNs) which augment sets or graphs with additional inferred edges for improved model expressivity. PGNs allow each node to dynamically point to another node, followed by message passing over these pointers. The sparsity of this adaptable graph structure makes learning tractable while still being sufficiently expressive to simulate complex algorithms. Critically, the pointing mechanism is directly supervised to model long-term sequences of operations on classical data structures, incorporating useful structural inductive biases from theoretical computer science. Qualitatively, we demonstrate that PGNs can learn parallelisable variants of pointer-based data structures, namely disjoint set unions and link/cut trees. PGNs generalise out-of-distribution to 5x larger test inputs on dynamic graph connectivity tasks, outperforming unrestricted GNNs and Deep Sets.
A Deep Neural Network's Loss Surface Contains Every Low-dimensional Pattern
Jan 02, 2020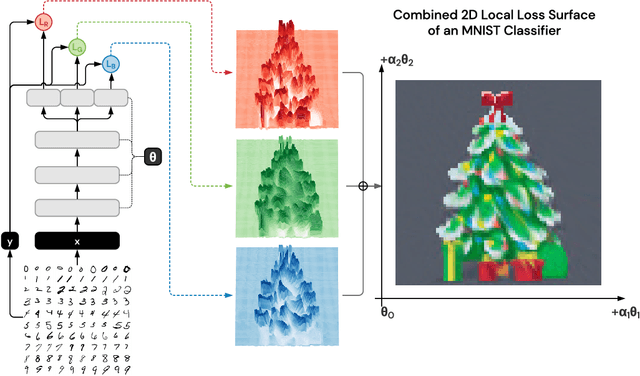
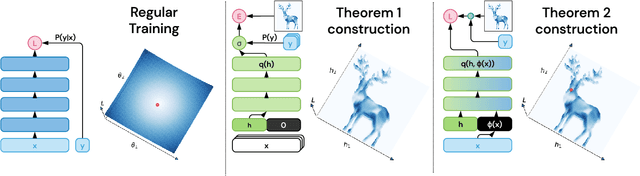
The work "Loss Landscape Sightseeing with Multi-Point Optimization" (Skorokhodov and Burtsev, 2019) demonstrated that one can empirically find arbitrary 2D binary patterns inside loss surfaces of popular neural networks. In this paper we prove that: (i) this is a general property of deep universal approximators; and (ii) this property holds for arbitrary smooth patterns, for other dimensionalities, for every dataset, and any neural network that is sufficiently deep and wide. Our analysis predicts not only the existence of all such low-dimensional patterns, but also two other properties that were observed empirically: (i) that it is easy to find these patterns; and (ii) that they transfer to other data-sets (e.g. a test-set).
Continual Unsupervised Representation Learning
Oct 31, 2019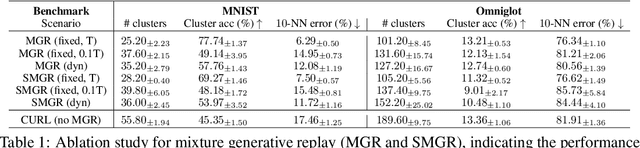
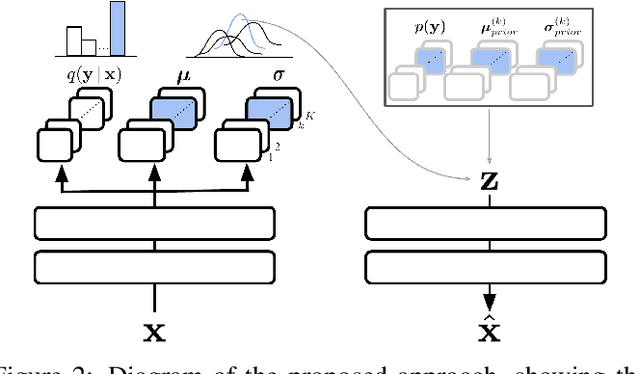

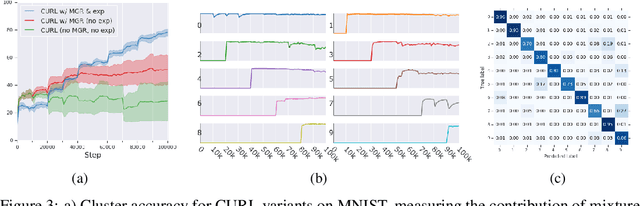
Continual learning aims to improve the ability of modern learning systems to deal with non-stationary distributions, typically by attempting to learn a series of tasks sequentially. Prior art in the field has largely considered supervised or reinforcement learning tasks, and often assumes full knowledge of task labels and boundaries. In this work, we propose an approach (CURL) to tackle a more general problem that we will refer to as unsupervised continual learning. The focus is on learning representations without any knowledge about task identity, and we explore scenarios when there are abrupt changes between tasks, smooth transitions from one task to another, or even when the data is shuffled. The proposed approach performs task inference directly within the model, is able to dynamically expand to capture new concepts over its lifetime, and incorporates additional rehearsal-based techniques to deal with catastrophic forgetting. We demonstrate the efficacy of CURL in an unsupervised learning setting with MNIST and Omniglot, where the lack of labels ensures no information is leaked about the task. Further, we demonstrate strong performance compared to prior art in an i.i.d setting, or when adapting the technique to supervised tasks such as incremental class learning.
Improving the Gating Mechanism of Recurrent Neural Networks
Oct 22, 2019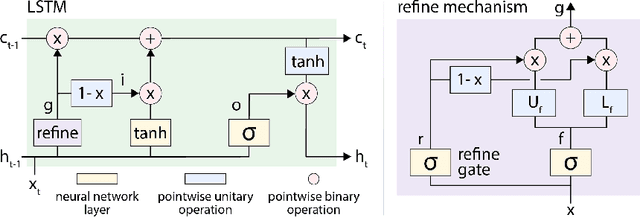

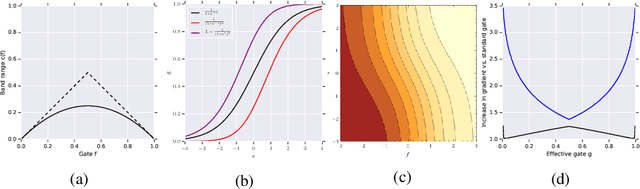

Gating mechanisms are widely used in neural network models, where they allow gradients to backpropagate more easily through depth or time. However, their saturation property introduces problems of its own. For example, in recurrent models these gates need to have outputs near 1 to propagate information over long time-delays, which requires them to operate in their saturation regime and hinders gradient-based learning of the gate mechanism. We address this problem by deriving two synergistic modifications to the standard gating mechanism that are easy to implement, introduce no additional hyperparameters, and improve learnability of the gates when they are close to saturation. We show how these changes are related to and improve on alternative recently proposed gating mechanisms such as chrono-initialization and Ordered Neurons. Empirically, our simple gating mechanisms robustly improve the performance of recurrent models on a range of applications, including synthetic memorization tasks, sequential image classification, language modeling, and reinforcement learning, particularly when long-term dependencies are involved.
Stabilizing Transformers for Reinforcement Learning
Oct 13, 2019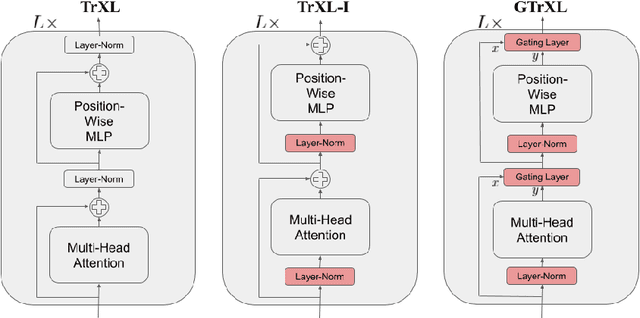
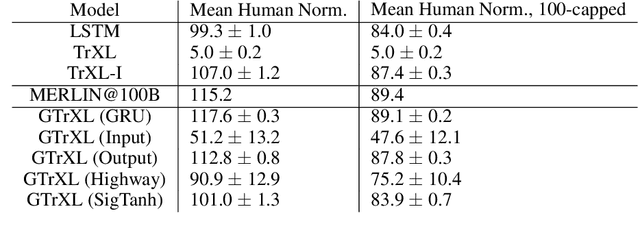
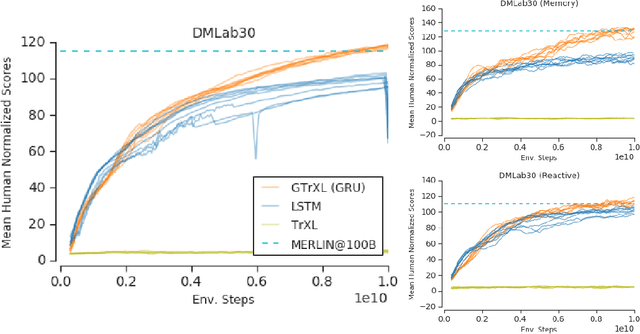
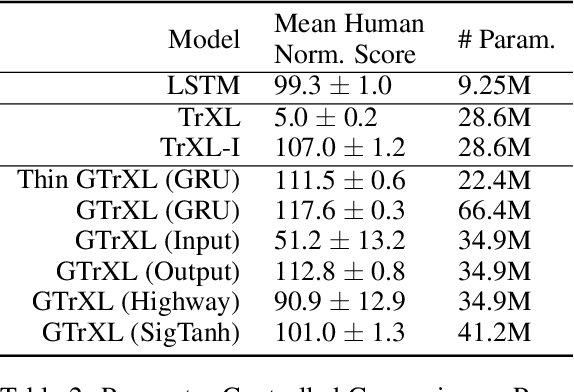
Owing to their ability to both effectively integrate information over long time horizons and scale to massive amounts of data, self-attention architectures have recently shown breakthrough success in natural language processing (NLP), achieving state-of-the-art results in domains such as language modeling and machine translation. Harnessing the transformer's ability to process long time horizons of information could provide a similar performance boost in partially observable reinforcement learning (RL) domains, but the large-scale transformers used in NLP have yet to be successfully applied to the RL setting. In this work we demonstrate that the standard transformer architecture is difficult to optimize, which was previously observed in the supervised learning setting but becomes especially pronounced with RL objectives. We propose architectural modifications that substantially improve the stability and learning speed of the original Transformer and XL variant. The proposed architecture, the Gated Transformer-XL (GTrXL), surpasses LSTMs on challenging memory environments and achieves state-of-the-art results on the multi-task DMLab-30 benchmark suite, exceeding the performance of an external memory architecture. We show that the GTrXL, trained using the same losses, has stability and performance that consistently matches or exceeds a competitive LSTM baseline, including on more reactive tasks where memory is less critical. GTrXL offers an easy-to-train, simple-to-implement but substantially more expressive architectural alternative to the standard multi-layer LSTM ubiquitously used for RL agents in partially observable environments.
Meta-Learning with Warped Gradient Descent
Aug 30, 2019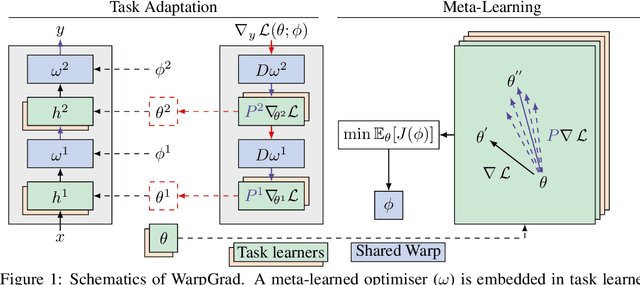
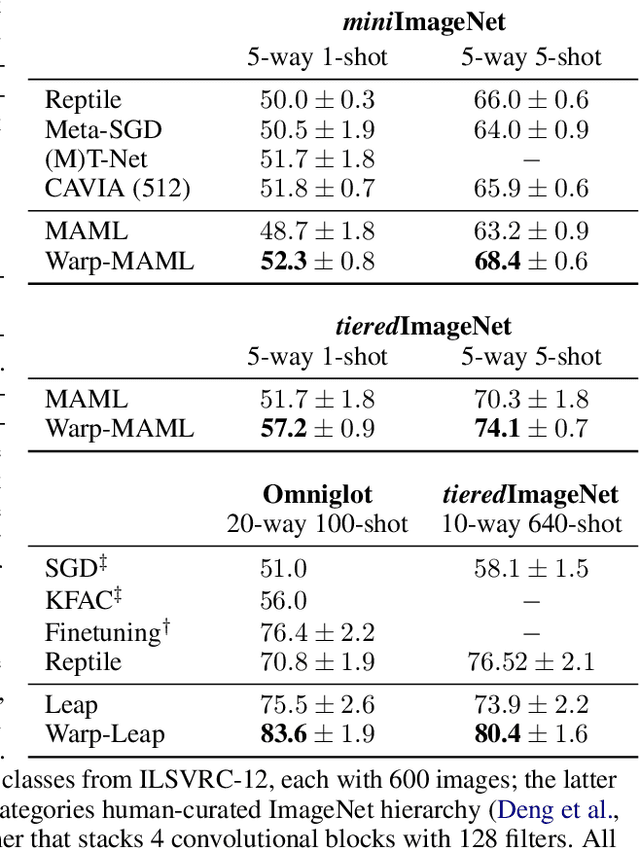
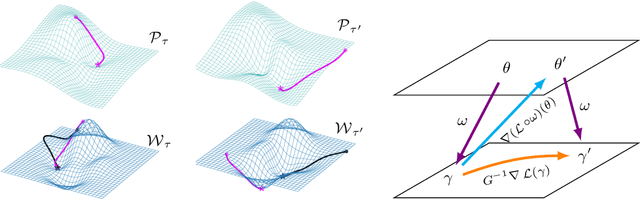
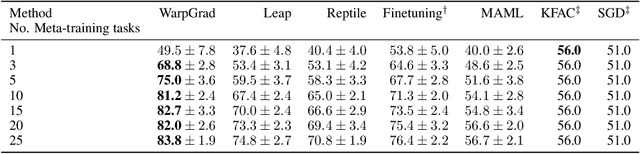
A versatile and effective approach to meta-learning is to infer a gradient-based up-date rule directly from data that promotes rapid learning of new tasks from the same distribution. Current methods rely on backpropagating through the learning process, limiting their scope to few-shot learning. In this work, we introduce Warped Gradient Descent (WarpGrad), a family of modular optimisers that can scale to arbitrary adaptation processes. WarpGrad methods meta-learn to warp task loss surfaces across the joint task-parameter distribution to facilitate gradient descent, which is achieved by a reparametrisation of neural networks that interleaves warp layers in the architecture. These layers are shared across task learners and fixed during adaptation; they represent a projection of task parameters into a meta-learned space that is conducive to task adaptation and standard backpropagation induces a form of gradient preconditioning. WarpGrad methods are computationally efficient and easy to implement as they rely on parameter sharing and backpropagation. They are readily combined with other meta-learners and can scale both in terms of model size and length of adaptation trajectories as meta-learning warp parameters do not require differentiation through task adaptation processes. We show empirically that WarpGrad optimisers meta-learn a warped space where gradient descent is well behaved, with faster convergence and better performance in a variety of settings, including few-shot, standard supervised, continual, and reinforcement learning.
Task Agnostic Continual Learning via Meta Learning
Jun 12, 2019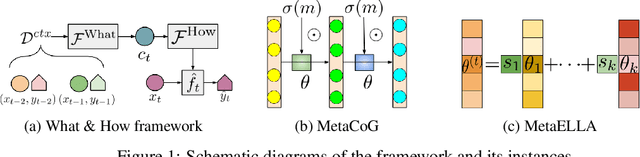

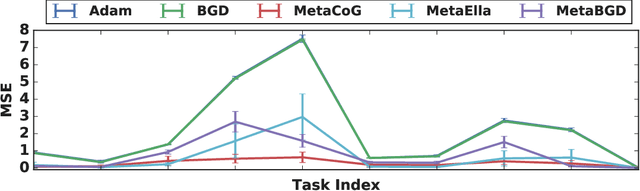
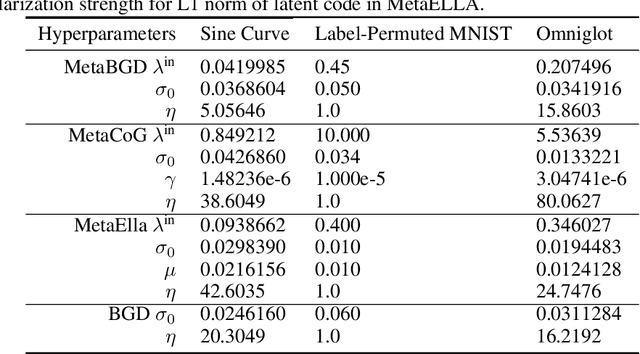
While neural networks are powerful function approximators, they suffer from catastrophic forgetting when the data distribution is not stationary. One particular formalism that studies learning under non-stationary distribution is provided by continual learning, where the non-stationarity is imposed by a sequence of distinct tasks. Most methods in this space assume, however, the knowledge of task boundaries, and focus on alleviating catastrophic forgetting. In this work, we depart from this view and move the focus towards faster remembering -- i.e measuring how quickly the network recovers performance rather than measuring the network's performance without any adaptation. We argue that in many settings this can be more effective and that it opens the door to combining meta-learning and continual learning techniques, leveraging their complementary advantages. We propose a framework specific for the scenario where no information about task boundaries or task identity is given. It relies on a separation of concerns into what task is being solved and how the task should be solved. This framework is implemented by differentiating task specific parameters from task agnostic parameters, where the latter are optimized in a continual meta learning fashion, without access to multiple tasks at the same time. We showcase this framework in a supervised learning scenario and discuss the implication of the proposed formalism.
Meta-learning of Sequential Strategies
May 08, 2019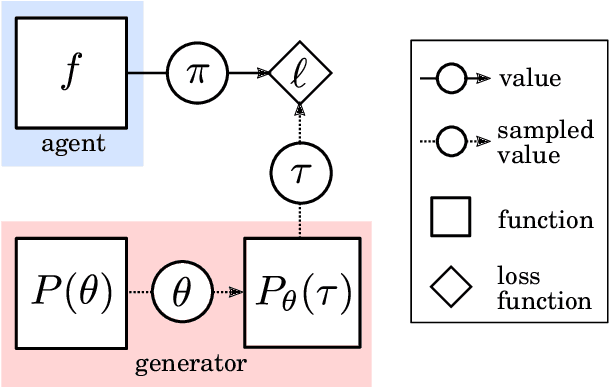
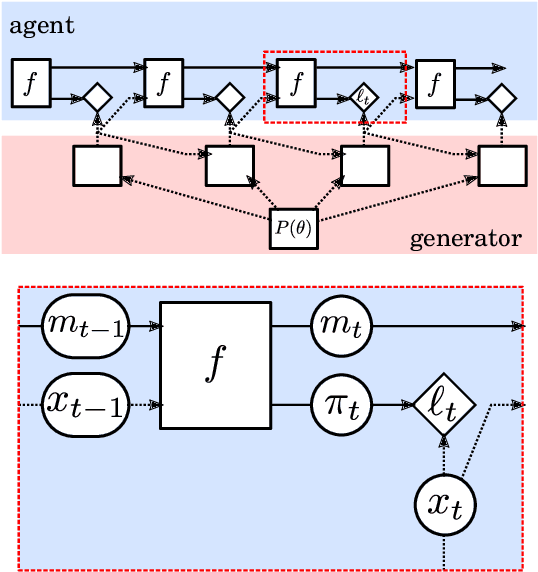
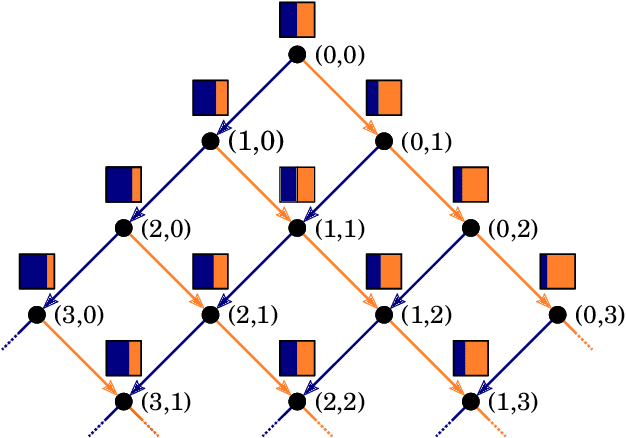
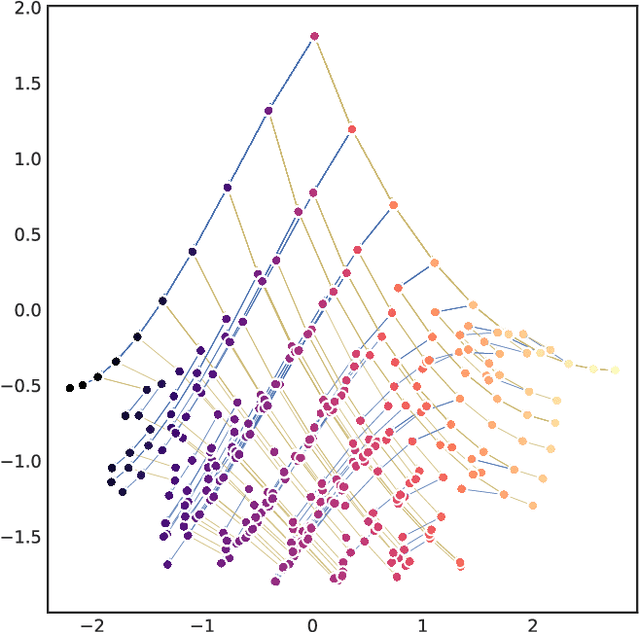
In this report we review memory-based meta-learning as a tool for building sample-efficient strategies that learn from past experience to adapt to any task within a target class. Our goal is to equip the reader with the conceptual foundations of this tool for building new, scalable agents that operate on broad domains. To do so, we present basic algorithmic templates for building near-optimal predictors and reinforcement learners which behave as if they had a probabilistic model that allowed them to efficiently exploit task structure. Furthermore, we recast memory-based meta-learning within a Bayesian framework, showing that the meta-learned strategies are near-optimal because they amortize Bayes-filtered data, where the adaptation is implemented in the memory dynamics as a state-machine of sufficient statistics. Essentially, memory-based meta-learning translates the hard problem of probabilistic sequential inference into a regression problem.
Information asymmetry in KL-regularized RL
May 03, 2019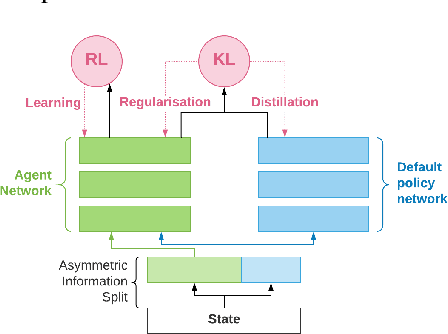

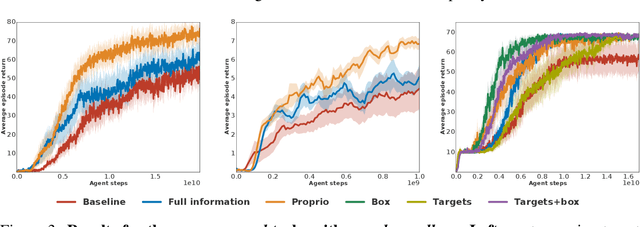
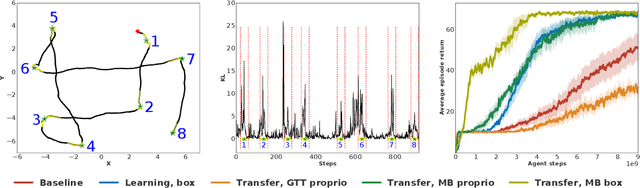
Many real world tasks exhibit rich structure that is repeated across different parts of the state space or in time. In this work we study the possibility of leveraging such repeated structure to speed up and regularize learning. We start from the KL regularized expected reward objective which introduces an additional component, a default policy. Instead of relying on a fixed default policy, we learn it from data. But crucially, we restrict the amount of information the default policy receives, forcing it to learn reusable behaviors that help the policy learn faster. We formalize this strategy and discuss connections to information bottleneck approaches and to the variational EM algorithm. We present empirical results in both discrete and continuous action domains and demonstrate that, for certain tasks, learning a default policy alongside the policy can significantly speed up and improve learning.