 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHDNET: Exploiting HD Maps for 3D Object Detection
Dec 21, 2020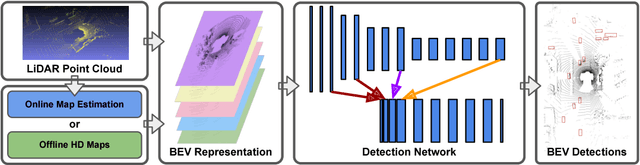
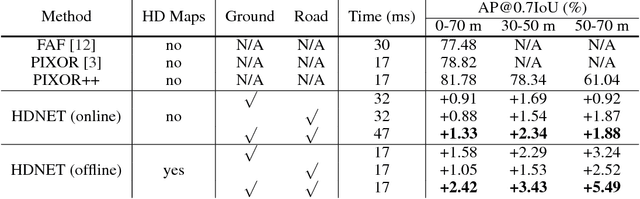

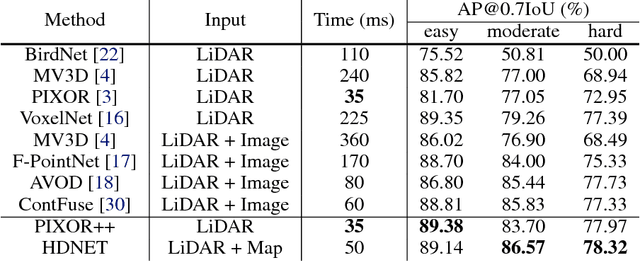
In this paper we show that High-Definition (HD) maps provide strong priors that can boost the performance and robustness of modern 3D object detectors. Towards this goal, we design a single stage detector that extracts geometric and semantic features from the HD maps. As maps might not be available everywhere, we also propose a map prediction module that estimates the map on the fly from raw LiDAR data. We conduct extensive experiments on KITTI as well as a large-scale 3D detection benchmark containing 1 million frames, and show that the proposed map-aware detector consistently outperforms the state-of-the-art in both mapped and un-mapped scenarios. Importantly the whole framework runs at 20 frames per second.
Convolutional Recurrent Network for Road Boundary Extraction
Dec 21, 2020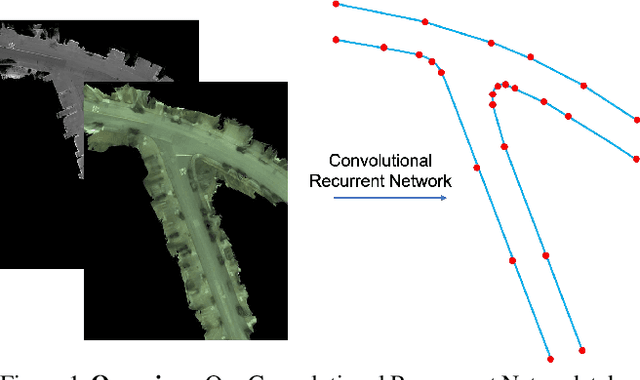

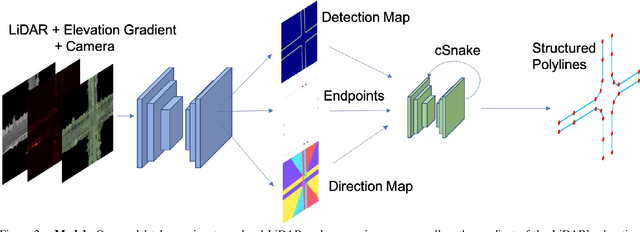

Creating high definition maps that contain precise information of static elements of the scene is of utmost importance for enabling self driving cars to drive safely. In this paper, we tackle the problem of drivable road boundary extraction from LiDAR and camera imagery. Towards this goal, we design a structured model where a fully convolutional network obtains deep features encoding the location and direction of road boundaries and then, a convolutional recurrent network outputs a polyline representation for each one of them. Importantly, our method is fully automatic and does not require a user in the loop. We showcase the effectiveness of our method on a large North American city where we obtain perfect topology of road boundaries 99.3% of the time at a high precision and recall.
Deep Continuous Fusion for Multi-Sensor 3D Object Detection
Dec 20, 2020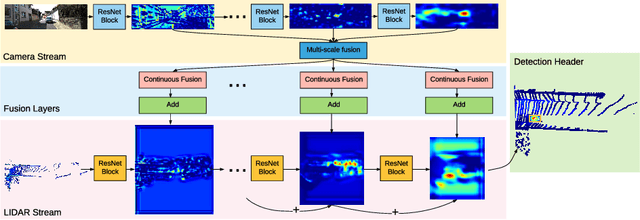
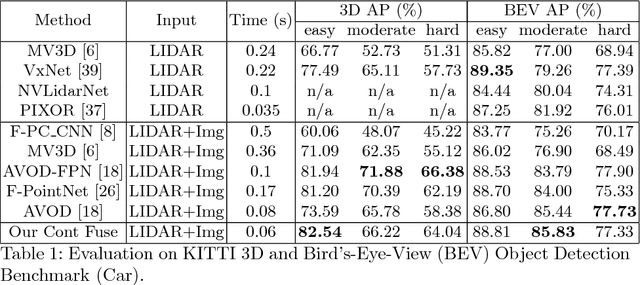
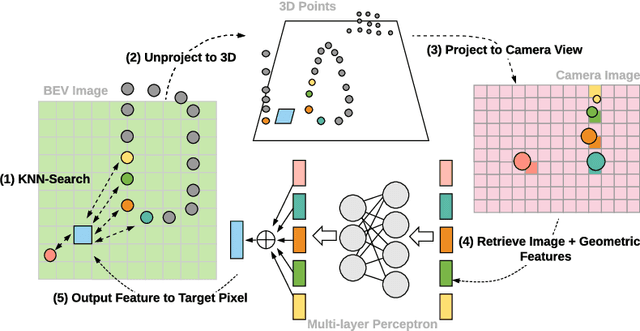
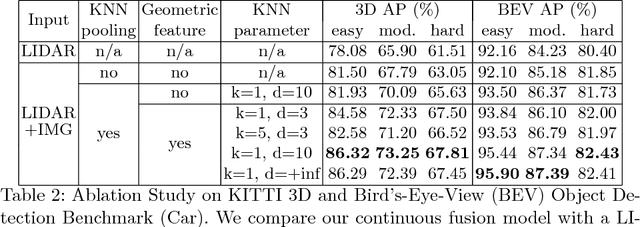
In this paper, we propose a novel 3D object detector that can exploit both LIDAR as well as cameras to perform very accurate localization. Towards this goal, we design an end-to-end learnable architecture that exploits continuous convolutions to fuse image and LIDAR feature maps at different levels of resolution. Our proposed continuous fusion layer encode both discrete-state image features as well as continuous geometric information. This enables us to design a novel, reliable and efficient end-to-end learnable 3D object detector based on multiple sensors. Our experimental evaluation on both KITTI as well as a large scale 3D object detection benchmark shows significant improvements over the state of the art.
Learning to Localize Through Compressed Binary Maps
Dec 20, 2020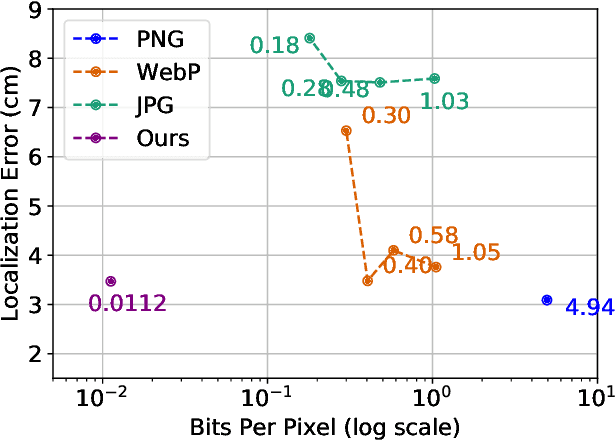
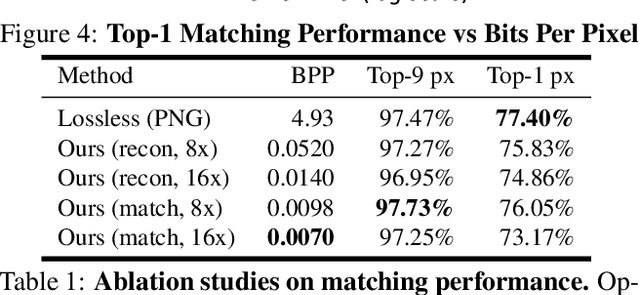
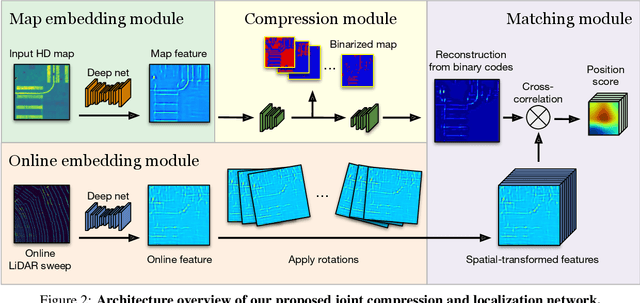
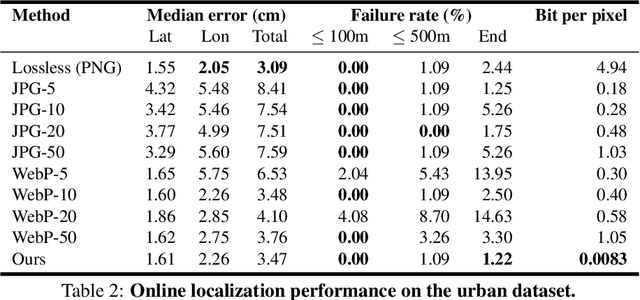
One of the main difficulties of scaling current localization systems to large environments is the on-board storage required for the maps. In this paper we propose to learn to compress the map representation such that it is optimal for the localization task. As a consequence, higher compression rates can be achieved without loss of localization accuracy when compared to standard coding schemes that optimize for reconstruction, thus ignoring the end task. Our experiments show that it is possible to learn a task-specific compression which reduces storage requirements by two orders of magnitude over general-purpose codecs such as WebP without sacrificing performance.
* 18 pages, 12 figures, 6 tables; Presented at CVPR 2019
Learning to Localize Using a LiDAR Intensity Map
Dec 20, 2020
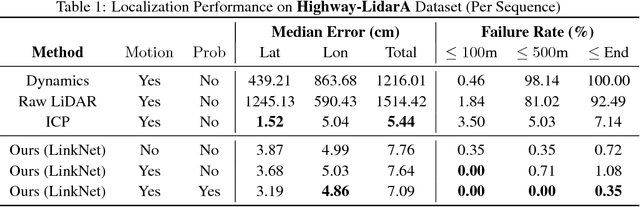
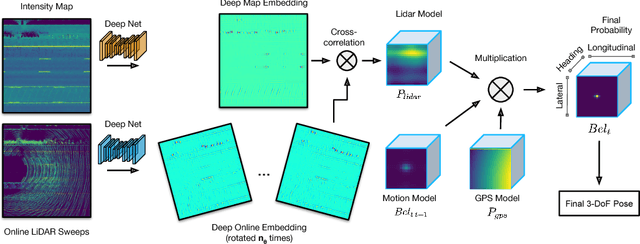

In this paper we propose a real-time, calibration-agnostic and effective localization system for self-driving cars. Our method learns to embed the online LiDAR sweeps and intensity map into a joint deep embedding space. Localization is then conducted through an efficient convolutional matching between the embeddings. Our full system can operate in real-time at 15Hz while achieving centimeter level accuracy across different LiDAR sensors and environments. Our experiments illustrate the performance of the proposed approach over a large-scale dataset consisting of over 4000km of driving.
* 12 pages, 7 figures, 5 tables; Presented at the 2nd Conference on Robot Learning (CoRL), 2018
A PAC-Bayesian Approach to Generalization Bounds for Graph Neural Networks
Dec 14, 2020
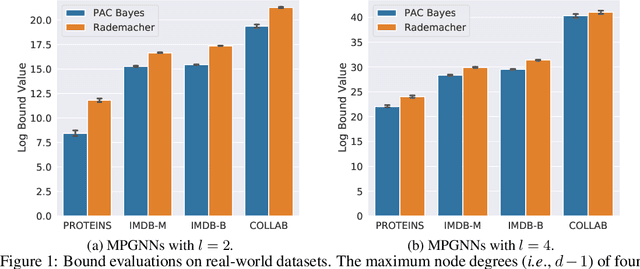
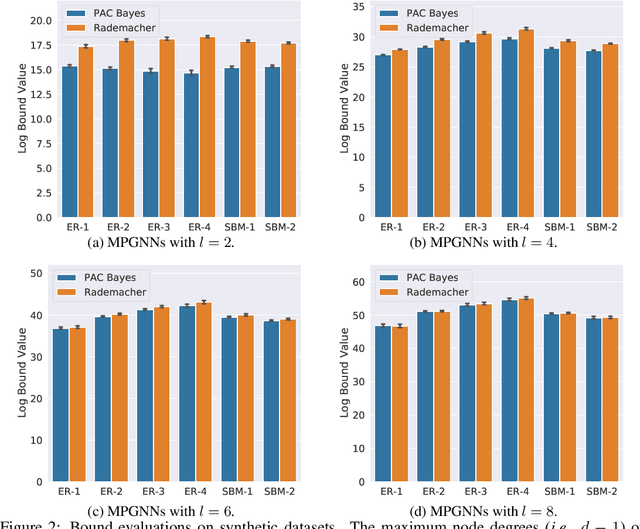

In this paper, we derive generalization bounds for the two primary classes of graph neural networks (GNNs), namely graph convolutional networks (GCNs) and message passing GNNs (MPGNNs), via a PAC-Bayesian approach. Our result reveals that the maximum node degree and spectral norm of the weights govern the generalization bounds of both models. We also show that our bound for GCNs is a natural generalization of the results developed in arXiv:1707.09564v2 [cs.LG] for fully-connected and convolutional neural networks. For message passing GNNs, our PAC-Bayes bound improves over the Rademacher complexity based bound in arXiv:2002.06157v1 [cs.LG], showing a tighter dependency on the maximum node degree and the maximum hidden dimension. The key ingredients of our proofs are a perturbation analysis of GNNs and the generalization of PAC-Bayes analysis to non-homogeneous GNNs. We perform an empirical study on several real-world graph datasets and verify that our PAC-Bayes bound is tighter than others.
GeoNet++: Iterative Geometric Neural Network with Edge-Aware Refinement for Joint Depth and Surface Normal Estimation
Dec 13, 2020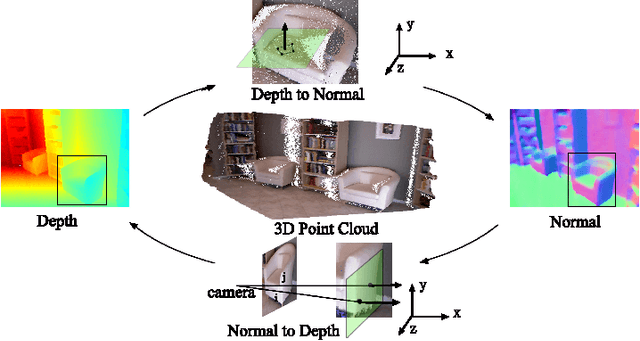
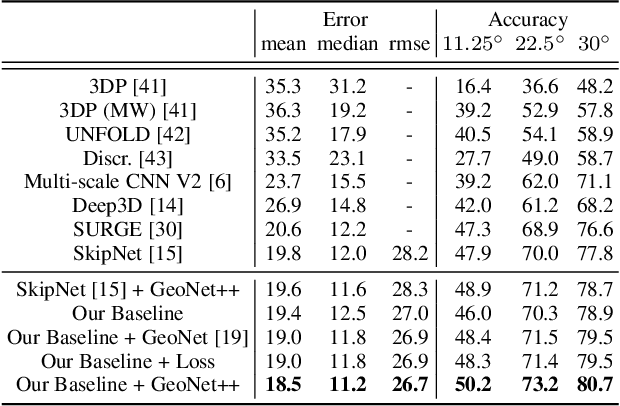
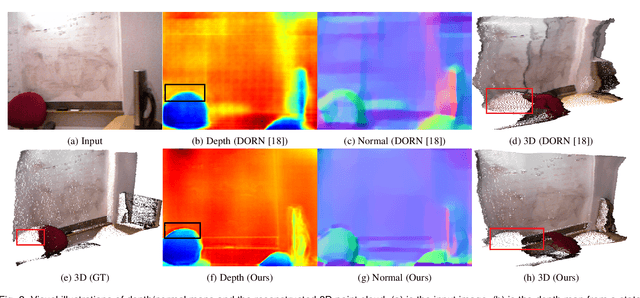
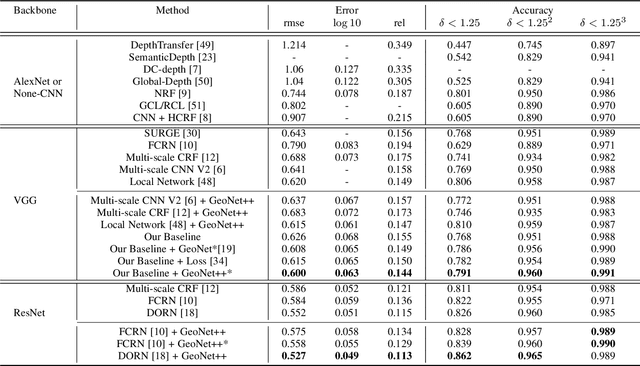
In this paper, we propose a geometric neural network with edge-aware refinement (GeoNet++) to jointly predict both depth and surface normal maps from a single image. Building on top of two-stream CNNs, GeoNet++ captures the geometric relationships between depth and surface normals with the proposed depth-to-normal and normal-to-depth modules. In particular, the "depth-to-normal" module exploits the least square solution of estimating surface normals from depth to improve their quality, while the "normal-to-depth" module refines the depth map based on the constraints on surface normals through kernel regression. Boundary information is exploited via an edge-aware refinement module. GeoNet++ effectively predicts depth and surface normals with strong 3D consistency and sharp boundaries resulting in better reconstructed 3D scenes. Note that GeoNet++ is generic and can be used in other depth/normal prediction frameworks to improve the quality of 3D reconstruction and pixel-wise accuracy of depth and surface normals. Furthermore, we propose a new 3D geometric metric (3DGM) for evaluating depth prediction in 3D. In contrast to current metrics that focus on evaluating pixel-wise error/accuracy, 3DGM measures whether the predicted depth can reconstruct high-quality 3D surface normals. This is a more natural metric for many 3D application domains. Our experiments on NYUD-V2 and KITTI datasets verify that GeoNet++ produces fine boundary details, and the predicted depth can be used to reconstruct high-quality 3D surfaces. Code has been made publicly available.
Recovering and Simulating Pedestrians in the Wild
Nov 16, 2020
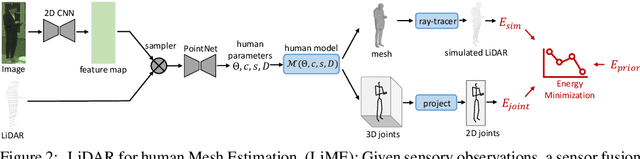

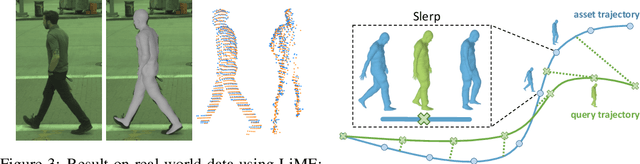
Sensor simulation is a key component for testing the performance of self-driving vehicles and for data augmentation to better train perception systems. Typical approaches rely on artists to create both 3D assets and their animations to generate a new scenario. This, however, does not scale. In contrast, we propose to recover the shape and motion of pedestrians from sensor readings captured in the wild by a self-driving car driving around. Towards this goal, we formulate the problem as energy minimization in a deep structured model that exploits human shape priors, reprojection consistency with 2D poses extracted from images, and a ray-caster that encourages the reconstructed mesh to agree with the LiDAR readings. Importantly, we do not require any ground-truth 3D scans or 3D pose annotations. We then incorporate the reconstructed pedestrian assets bank in a realistic LiDAR simulation system by performing motion retargeting, and show that the simulated LiDAR data can be used to significantly reduce the amount of annotated real-world data required for visual perception tasks.
MuSCLE: Multi Sweep Compression of LiDAR using Deep Entropy Models
Nov 15, 2020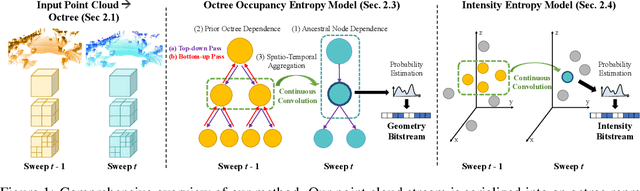

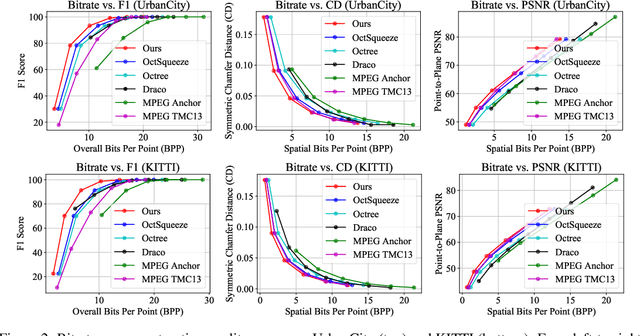
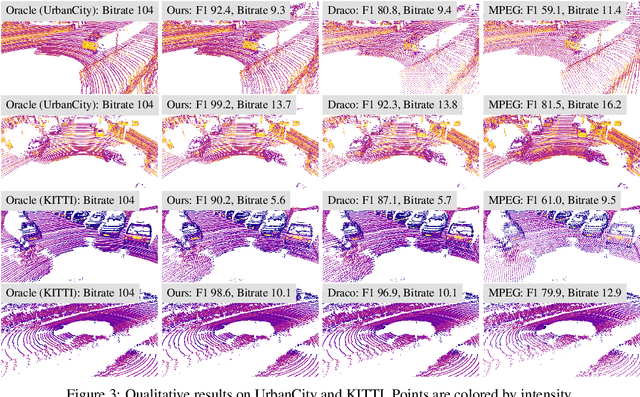
We present a novel compression algorithm for reducing the storage of LiDAR sensor data streams. Our model exploits spatio-temporal relationships across multiple LiDAR sweeps to reduce the bitrate of both geometry and intensity values. Towards this goal, we propose a novel conditional entropy model that models the probabilities of the octree symbols by considering both coarse level geometry and previous sweeps' geometric and intensity information. We then use the learned probability to encode the full data stream into a compact one. Our experiments demonstrate that our method significantly reduces the joint geometry and intensity bitrate over prior state-of-the-art LiDAR compression methods, with a reduction of 7-17% and 15-35% on the UrbanCity and SemanticKITTI datasets respectively.
StrObe: Streaming Object Detection from LiDAR Packets
Nov 13, 2020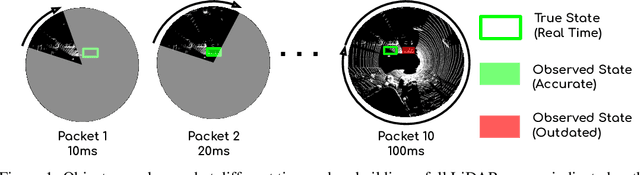

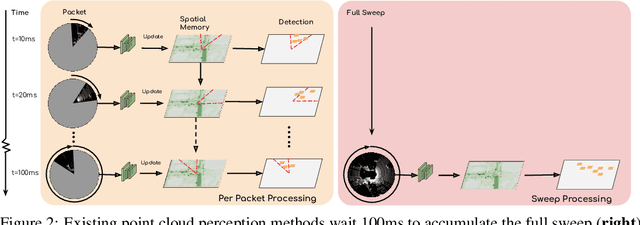
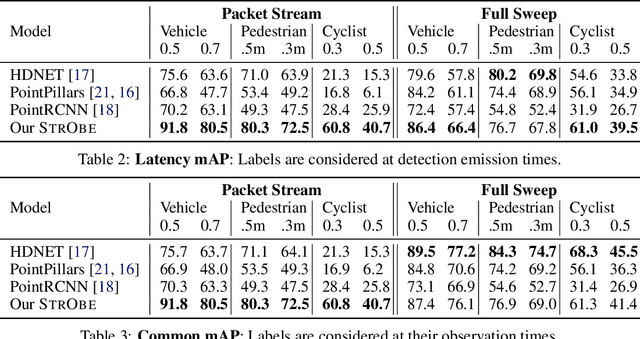
Many modern robotics systems employ LiDAR as their main sensing modality due to its geometrical richness. Rolling shutter LiDARs are particularly common, in which an array of lasers scans the scene from a rotating base. Points are emitted as a stream of packets, each covering a sector of the 360{\deg} coverage. Modern perception algorithms wait for the full sweep to be built before processing the data, which introduces an additional latency. For typical 10Hz LiDARs this will be 100ms. As a consequence, by the time an output is produced, it no longer accurately reflects the state of the world. This poses a challenge, as robotics applications require minimal reaction times, such that maneuvers can be quickly planned in the event of a safety-critical situation. In this paper we propose StrObe, a novel approach that minimizes latency by ingesting LiDAR packets and emitting a stream of detections without waiting for the full sweep to be built. StrObe reuses computations from previous packets and iteratively updates a latent spatial representation of the scene, which acts as a memory, as new evidence comes in, resulting in accurate low-latency perception. We demonstrate the effectiveness of our approach on a large scale real-world dataset, showing that StrObe far outperforms the state-of-the-art when latency is taken into account, and matches the performance in the traditional setting.