 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General Calibrated Regret Metric for Detecting and Mitigating Human-Robot Interaction Failures
Mar 07, 2024



Robot decision-making increasingly relies on expressive data-driven human prediction models when operating around people. While these models are known to suffer from prediction errors in out-of-distribution interactions, not all prediction errors equally impact downstream robot performance. We identify that the mathematical notion of regret precisely characterizes the degree to which incorrect predictions of future interaction outcomes degraded closed-loop robot performance. However, canonical regret measures are poorly calibrated across diverse deployment interactions. We extend the canonical notion of regret by deriving a calibrated regret metric that generalizes from absolute reward space to probability space. With this transformation, our metric removes the need for explicit reward functions to calculate the robot's regret, enables fairer comparison of interaction anomalies across disparate deployment contexts, and facilitates targetted dataset construction of "system-level" prediction failures. We experimentally quantify the value of this high-regret interaction data for aiding the robot in improving its downstream decision-making. In a suite of closed-loop autonomous driving simulations, we find that fine-tuning ego-conditioned behavior predictors exclusively on high-regret human-robot interaction data can improve the robot's overall re-deployment performance with significantly (77%) less data.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
What Matters to You? Towards Visual Representation Alignment for Robot Learning
Oct 11, 2023



When operating in service of people, robots need to optimize rewards aligned with end-user preferences. Since robots will rely on raw perceptual inputs like RGB images, their rewards will inevitably use visual representations. Recently there has been excitement in using representations from pre-trained visual models, but key to making these work in robotics is fine-tuning, which is typically done via proxy tasks like dynamics prediction or enforcing temporal cycle-consistency. However, all these proxy tasks bypass the human's input on what matters to them, exacerbating spurious correlations and ultimately leading to robot behaviors that are misaligned with user preferences. In this work, we propose that robots should leverage human feedback to align their visual representations with the end-user and disentangle what matters for the task. We propose Representation-Aligned Preference-based Learning (RAPL), a method for solving the visual representation alignment problem and visual reward learning problem through the lens of preference-based learning and optimal transport. Across experiments in X-MAGICAL and in robotic manipulation, we find that RAPL's reward consistently generates preferred robot behaviors with high sample efficiency, and shows strong zero-shot generalization when the visual representation is learned from a different embodiment than the robot's.
Quantifying Agent Interaction in Multi-agent Reinforcement Learning for Cost-efficient Generalization
Oct 11, 2023



Generalization poses a significant challenge in Multi-agent Reinforcement Learning (MARL). The extent to which an agent is influenced by unseen co-players depends on the agent's policy and the specific scenario. A quantitative examination of this relationship sheds light on effectively training agents for diverse scenarios. In this study, we present the Level of Influence (LoI), a metric quantifying the interaction intensity among agents within a given scenario and environment. We observe that, generally, a more diverse set of co-play agents during training enhances the generalization performance of the ego agent; however, this improvement varies across distinct scenarios and environments. LoI proves effective in predicting these improvement disparities within specific scenarios. Furthermore, we introduce a LoI-guided resource allocation method tailored to train a set of policies for diverse scenarios under a constrained budget. Our results demonstrate that strategic resource allocation based on LoI can achieve higher performance than uniform allocation under the same computation budget.
Towards Modeling and Influencing the Dynamics of Human Learning
Jan 02, 2023



Humans have internal models of robots (like their physical capabilities), the world (like what will happen next), and their tasks (like a preferred goal). However, human internal models are not always perfect: for example, it is easy to underestimate a robot's inertia. Nevertheless, these models change and improve over time as humans gather more experience. Interestingly, robot actions influence what this experience is, and therefore influence how people's internal models change. In this work we take a step towards enabling robots to understand the influence they have, leverage it to better assist people, and help human models more quickly align with reality. Our key idea is to model the human's learning as a nonlinear dynamical system which evolves the human's internal model given new observations. We formulate a novel optimization problem to infer the human's learning dynamics from demonstrations that naturally exhibit human learning. We then formalize how robots can influence human learning by embedding the human's learning dynamics model into the robot planning problem. Although our formulations provide concrete problem statements, they are intractable to solve in full generality. We contribute an approximation that sacrifices the complexity of the human internal models we can represent, but enables robots to learn the nonlinear dynamics of these internal models. We evaluate our inference and planning methods in a suite of simulated environments and an in-person user study, where a 7DOF robotic arm teaches participants to be better teleoperators. While influencing human learning remains an open problem, our results demonstrate that this influence is possible and can be helpful in real human-robot interaction.
Simple Recurrence Improves Masked Language Models
May 23, 2022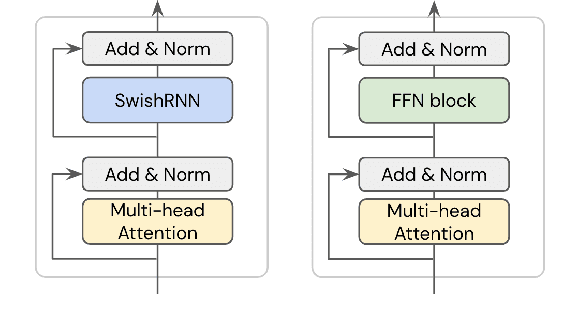
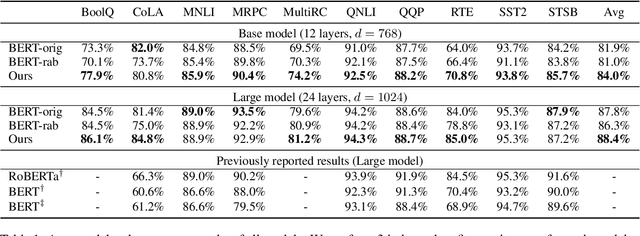
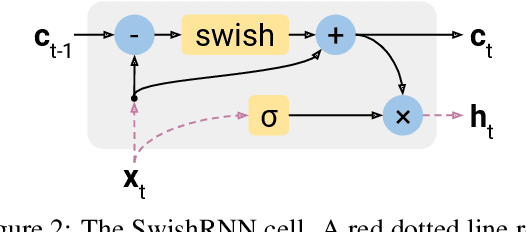
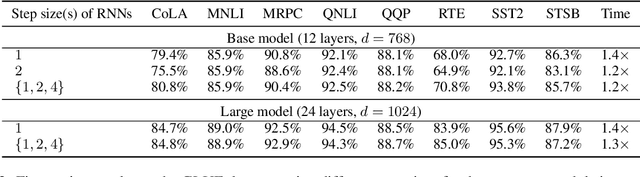
In this work, we explore whether modeling recurrence into the Transformer architecture can both be beneficial and efficient, by building an extremely simple recurrent module into the Transformer. We compare our model to baselines following the training and evaluation recipe of BERT. Our results confirm that recurrence can indeed improve Transformer models by a consistent margin, without requiring low-level performance optimizations, and while keeping the number of parameters constant. For example, our base model achieves an absolute improvement of 2.1 points averaged across 10 tasks and also demonstrates increased stability in fine-tuning over a range of learning rates.
Safety Assurances for Human-Robot Interaction via Confidence-aware Game-theoretic Human Models
Sep 29, 2021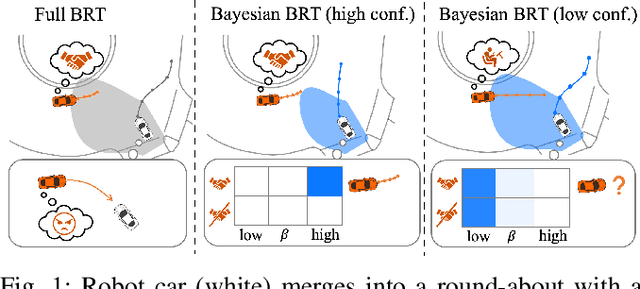
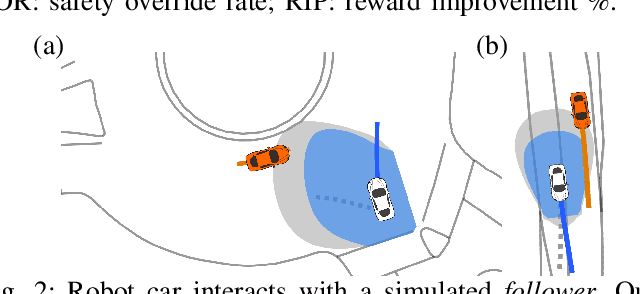
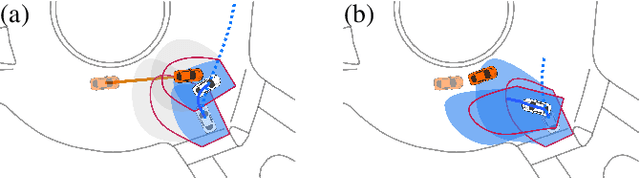
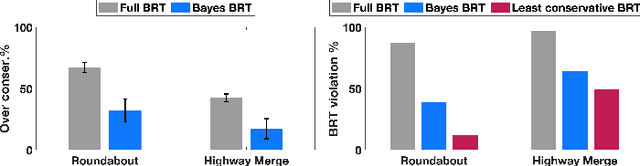
An outstanding challenge with safety methods for human-robot interaction is reducing their conservatism while maintaining robustness to variations in human behavior. In this work, we propose that robots use confidence-aware game-theoretic models of human behavior when assessing the safety of a human-robot interaction. By treating the influence between the human and robot as well as the human's rationality as unobserved latent states, we succinctly infer the degree to which a human is following the game-theoretic interaction model. We leverage this model to restrict the set of feasible human controls during safety verification, enabling the robot to confidently modulate the conservatism of its safety monitor online. Evaluations in simulated human-robot scenarios and ablation studies demonstrate that imbuing safety monitors with confidence-aware game-theoretic models enables both safe and efficient human-robot interaction. Moreover, evaluations with real traffic data show that our safety monitor is less conservative than traditional safety methods in real human driving scenarios.
Anytime Game-Theoretic Planning with Active Reasoning About Humans' Latent States for Human-Centered Robots
Sep 26, 2021
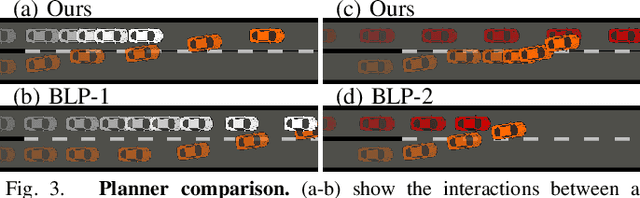

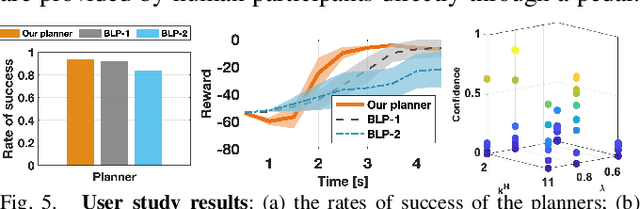
A human-centered robot needs to reason about the cognitive limitation and potential irrationality of its human partner to achieve seamless interactions. This paper proposes an anytime game-theoretic planner that integrates iterative reasoning models, a partially observable Markov decision process, and chance-constrained Monte-Carlo belief tree search for robot behavioral planning. Our planner enables a robot to safely and actively reason about its human partner's latent cognitive states (bounded intelligence and irrationality) in real-time to maximize its utility better. We validate our approach in an autonomous driving domain where our behavioral planner and a low-level motion controller hierarchically control an autonomous car to negotiate traffic merges. Simulations and user studies are conducted to show our planner's effectiveness.
Shatter: An Efficient Transformer Encoder with Single-Headed Self-Attention and Relative Sequence Partitioning
Aug 30, 2021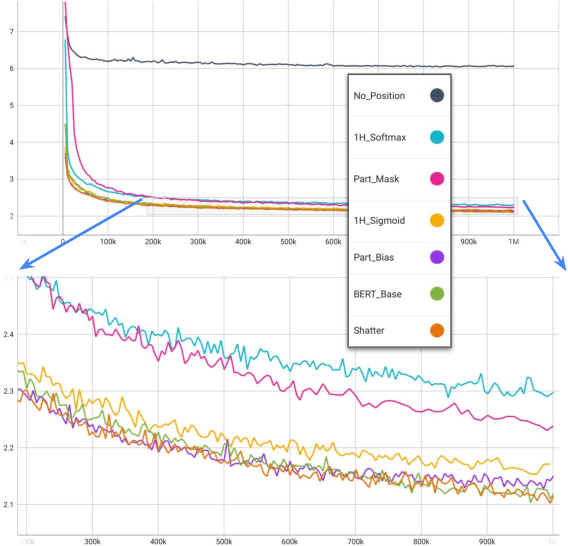
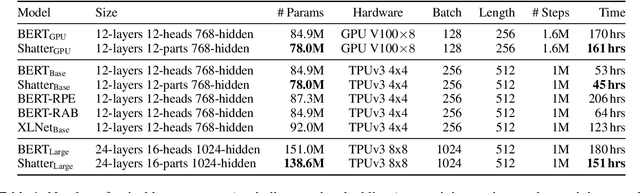

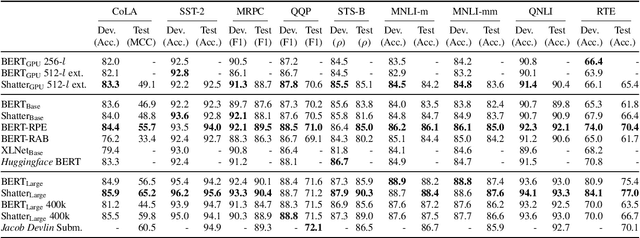
The highly popular Transformer architecture, based on self-attention, is the foundation of large pretrained models such as BERT, that have become an enduring paradigm in NLP. While powerful, the computational resources and time required to pretrain such models can be prohibitive. In this work, we present an alternative self-attention architecture, Shatter, that more efficiently encodes sequence information by softly partitioning the space of relative positions and applying different value matrices to different parts of the sequence. This mechanism further allows us to simplify the multi-headed attention in Transformer to single-headed. We conduct extensive experiments showing that Shatter achieves better performance than BERT, with pretraining being faster per step (15% on TPU), converging in fewer steps, and offering considerable memory savings (>50%). Put together, Shatter can be pretrained on 8 V100 GPUs in 7 days, and match the performance of BERT_Base -- making the cost of pretraining much more affordable.
Negotiation-Aware Reachability-Based Safety Verification for AutonomousDriving in Interactive Scenarios
Jun 04, 2021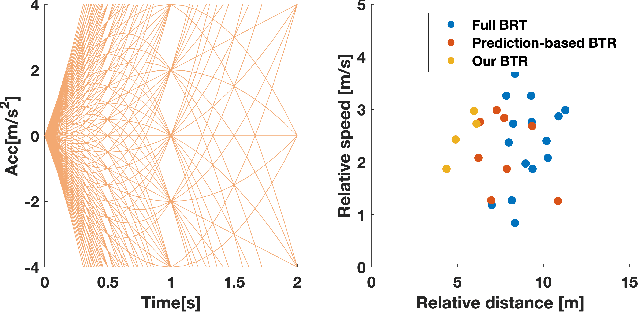
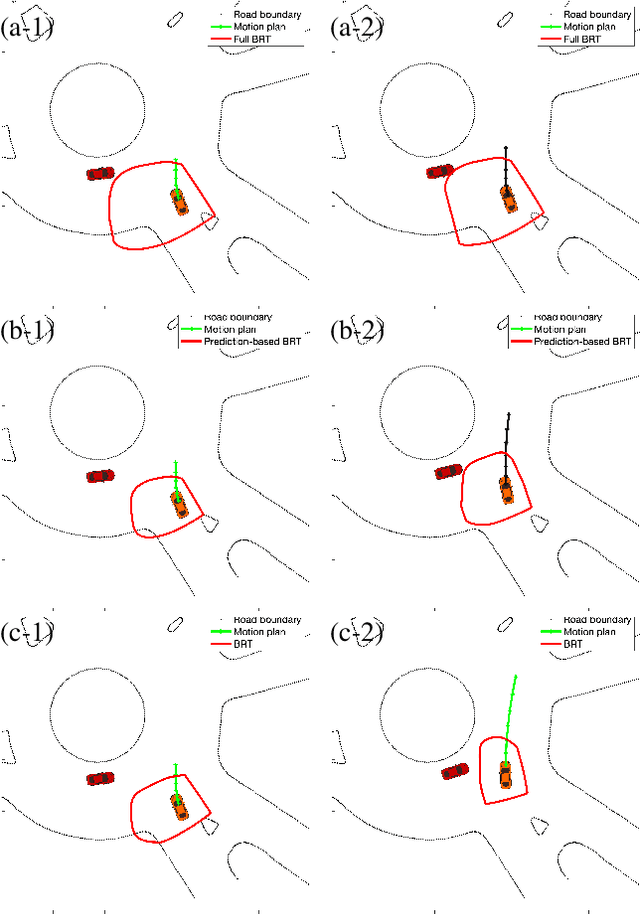
Safety assurance is a critical yet challenging aspect when developing self-driving technologies. Hamilton-Jacobi backward-reachability analysis is a formal verification tool for verifying the safety of dynamic systems in the presence of disturbances. However, the standard approach is too conservative to be applied to self-driving applications due to its worst-case assumption on humans' behaviors (i.e., guard against worst-case outcomes). In this work, we integrate a learning-based prediction algorithm and a game-theoretic human behavioral model to online update the conservativeness of backward-reachability analysis. We evaluate our approach using real driving data. The results show that, with reasonable assumptions on human behaviors, our approach can effectively reduce the conservativeness of the standard approach without sacrificing its safety verification ability.