 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWelfarist Formulations for Diverse Similarity Search
Feb 09, 2026Nearest Neighbor Search (NNS) is a fundamental problem in data structures with wide-ranging applications, such as web search, recommendation systems, and, more recently, retrieval-augmented generations (RAG). In such recent applications, in addition to the relevance (similarity) of the returned neighbors, diversity among the neighbors is a central requirement. In this paper, we develop principled welfare-based formulations in NNS for realizing diversity across attributes. Our formulations are based on welfare functions -- from mathematical economics -- that satisfy central diversity (fairness) and relevance (economic efficiency) axioms. With a particular focus on Nash social welfare, we note that our welfare-based formulations provide objective functions that adaptively balance relevance and diversity in a query-dependent manner. Notably, such a balance was not present in the prior constraint-based approach, which forced a fixed level of diversity and optimized for relevance. In addition, our formulation provides a parametric way to control the trade-off between relevance and diversity, providing practitioners with flexibility to tailor search results to task-specific requirements. We develop efficient nearest neighbor algorithms with provable guarantees for the welfare-based objectives. Notably, our algorithm can be applied on top of any standard ANN method (i.e., use standard ANN method as a subroutine) to efficiently find neighbors that approximately maximize our welfare-based objectives. Experimental results demonstrate that our approach is practical and substantially improves diversity while maintaining high relevance of the retrieved neighbors.
Linear Contextual Bandits with Hybrid Payoff: Revisited
Jun 14, 2024We study the Linear Contextual Bandit problem in the hybrid reward setting. In this setting every arm's reward model contains arm specific parameters in addition to parameters shared across the reward models of all the arms. We can reduce this setting to two closely related settings (a) Shared - no arm specific parameters, and (b) Disjoint - only arm specific parameters, enabling the application of two popular state of the art algorithms - $\texttt{LinUCB}$ and $\texttt{DisLinUCB}$ (Algorithm 1 in (Li et al. 2010)). When the arm features are stochastic and satisfy a popular diversity condition, we provide new regret analyses for both algorithms, significantly improving on the known regret guarantees of these algorithms. Our novel analysis critically exploits the hybrid reward structure and the diversity condition. Moreover, we introduce a new algorithm $\texttt{HyLinUCB}$ that crucially modifies $\texttt{LinUCB}$ (using a new exploration coefficient) to account for sparsity in the hybrid setting. Under the same diversity assumptions, we prove that $\texttt{HyLinUCB}$ also incurs only $O(\sqrt{T})$ regret for $T$ rounds. We perform extensive experiments on synthetic and real-world datasets demonstrating strong empirical performance of $\texttt{HyLinUCB}$.For number of arm specific parameters much larger than the number of shared parameters, we observe that $\texttt{DisLinUCB}$ incurs the lowest regret. In this case, regret of $\texttt{HyLinUCB}$ is the second best and extremely competitive to $\texttt{DisLinUCB}$. In all other situations, including our real-world dataset, $\texttt{HyLinUCB}$ has significantly lower regret than $\texttt{LinUCB}$, $\texttt{DisLinUCB}$ and other SOTA baselines we considered. We also empirically observe that the regret of $\texttt{HyLinUCB}$ grows much slower with the number of arms compared to baselines, making it suitable even for very large action spaces.
Optimal Regret with Limited Adaptivity for Generalized Linear Contextual Bandits
Apr 11, 2024We study the generalized linear contextual bandit problem within the requirements of limited adaptivity. In this paper, we present two algorithms, B-GLinCB and RS-GLinCB, that address, respectively, two prevalent limited adaptivity models: batch learning with stochastic contexts and rare policy switches with adversarial contexts. For both these models, we establish essentially tight regret bounds. Notably, in the obtained bounds, we manage to eliminate a dependence on a key parameter $\kappa$, which captures the non-linearity of the underlying reward model. For our batch learning algorithm B-GLinCB, with $\Omega\left( \log{\log T} \right)$ batches, the regret scales as $\tilde{O}(\sqrt{T})$. Further, we establish that our rarely switching algorithm RS-GLinCB updates its policy at most $\tilde{O}(\log^2 T)$ times and achieves a regret of $\tilde{O}(\sqrt{T})$. Our approach for removing the dependence on $\kappa$ for generalized linear contextual bandits might be of independent interest.
Provably Sample Efficient RLHF via Active Preference Optimization
Feb 16, 2024



Reinforcement Learning from Human Feedback (RLHF) is pivotal in aligning Large Language Models (LLMs) with human preferences. While these aligned generative models have demonstrated impressive capabilities across various tasks, the dependence on high-quality human preference data poses a costly bottleneck in practical implementation of RLHF. Hence better and adaptive strategies for data collection is needed. To this end, we frame RLHF as a contextual preference bandit problem with prompts as contexts and show that the naive way of collecting preference data by choosing prompts uniformly at random leads to a policy that suffers an $\Omega(1)$ suboptimality gap in rewards. Then we propose $\textit{Active Preference Optimization}$ ($\texttt{APO}$), an algorithm that actively selects prompts to collect preference data. Under the Bradley-Terry-Luce (BTL) preference model, \texttt{APO} achieves sample efficiency without compromising on policy performance. We show that given a sample budget of $T$, the suboptimality gap of a policy learned via $\texttt{APO}$ scales as $O(1/\sqrt{T})$. Next, we propose a compute-efficient batch version of $\texttt{APO}$ with minor modification and evaluate its performance in practice. Experimental evaluations on a human preference dataset validate \texttt{APO}'s efficacy as a sample-efficient and practical solution to data collection for RLHF, facilitating alignment of LLMs with human preferences in a cost-effective and scalable manner.
Inverse Reinforcement Learning With Constraint Recovery
May 14, 2023In this work, we propose a novel inverse reinforcement learning (IRL) algorithm for constrained Markov decision process (CMDP) problems. In standard IRL problems, the inverse learner or agent seeks to recover the reward function of the MDP, given a set of trajectory demonstrations for the optimal policy. In this work, we seek to infer not only the reward functions of the CMDP, but also the constraints. Using the principle of maximum entropy, we show that the IRL with constraint recovery (IRL-CR) problem can be cast as a constrained non-convex optimization problem. We reduce it to an alternating constrained optimization problem whose sub-problems are convex. We use exponentiated gradient descent algorithm to solve it. Finally, we demonstrate the efficacy of our algorithm for the grid world environment.
A View Independent Classification Framework for Yoga Postures
Jun 27, 2022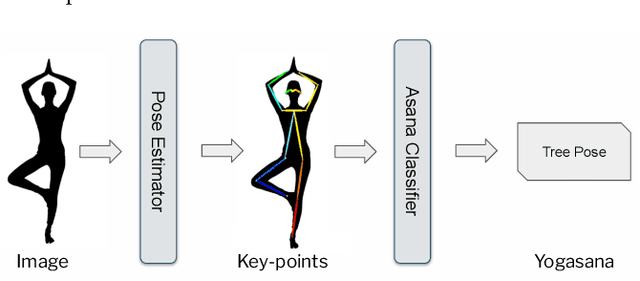
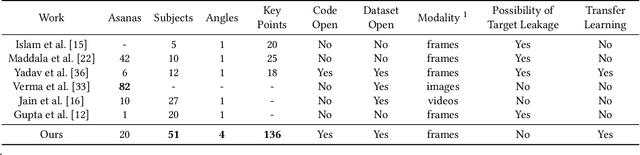
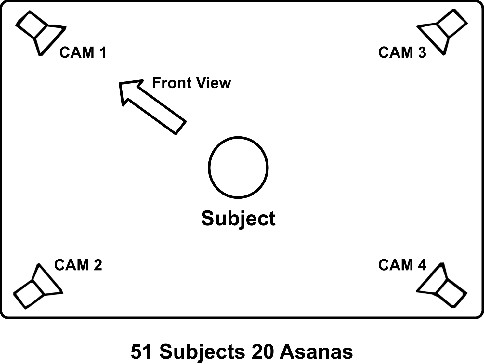
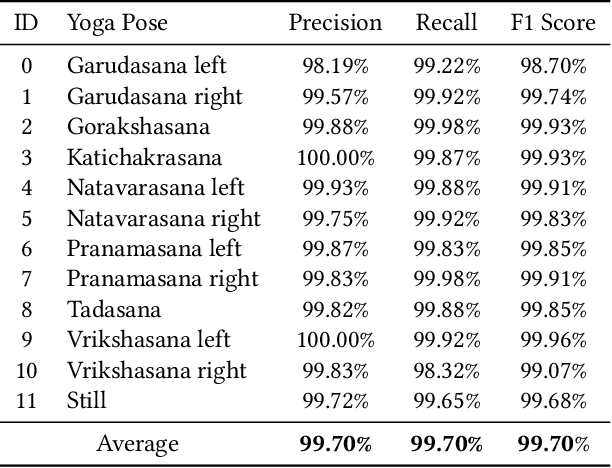
Yoga is a globally acclaimed and widely recommended practice for a healthy living. Maintaining correct posture while performing a Yogasana is of utmost importance. In this work, we employ transfer learning from Human Pose Estimation models for extracting 136 key-points spread all over the body to train a Random Forest classifier which is used for estimation of the Yogasanas. The results are evaluated on an in-house collected extensive yoga video database of 51 subjects recorded from 4 different camera angles. We propose a 3 step scheme for evaluating the generalizability of a Yoga classifier by testing it on 1) unseen frames, 2) unseen subjects, and 3) unseen camera angles. We argue that for most of the applications, validation accuracies on unseen subjects and unseen camera angles would be most important. We empirically analyze over three public datasets, the advantage of transfer learning and the possibilities of target leakage. We further demonstrate that the classification accuracies critically depend on the cross validation method employed and can often be misleading. To promote further research, we have made key-points dataset and code publicly available.