 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for Day Forecasts from Sparse Observations
Jun 12, 2023



Deep neural networks offer an alternative paradigm for modeling weather conditions. The ability of neural models to make a prediction in less than a second once the data is available and to do so with very high temporal and spatial resolution, and the ability to learn directly from atmospheric observations, are just some of these models' unique advantages. Neural models trained using atmospheric observations, the highest fidelity and lowest latency data, have to date achieved good performance only up to twelve hours of lead time when compared with state-of-the-art probabilistic Numerical Weather Prediction models and only for the sole variable of precipitation. In this paper, we present MetNet-3 that extends significantly both the lead time range and the variables that an observation based neural model can predict well. MetNet-3 learns from both dense and sparse data sensors and makes predictions up to 24 hours ahead for precipitation, wind, temperature and dew point. MetNet-3 introduces a key densification technique that implicitly captures data assimilation and produces spatially dense forecasts in spite of the network training on extremely sparse targets. MetNet-3 has a high temporal and spatial resolution of, respectively, up to 2 minutes and 1 km as well as a low operational latency. We find that MetNet-3 is able to outperform the best single- and multi-member NWPs such as HRRR and ENS over the CONUS region for up to 24 hours ahead setting a new performance milestone for observation based neural models. MetNet-3 is operational and its forecasts are served in Google Search in conjunction with other models.
Continuous Control With Ensemble Deep Deterministic Policy Gradients
Nov 30, 2021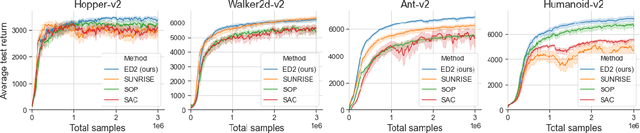
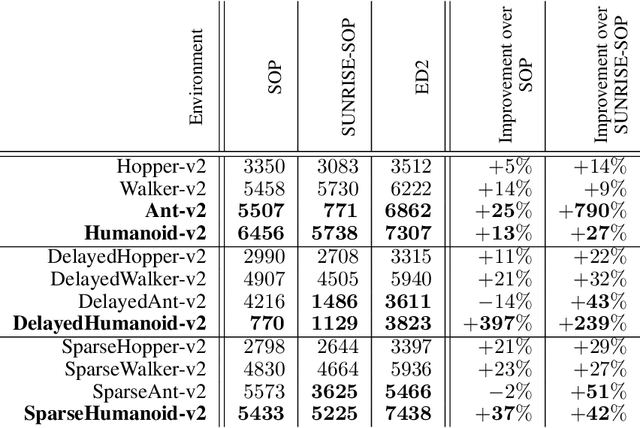
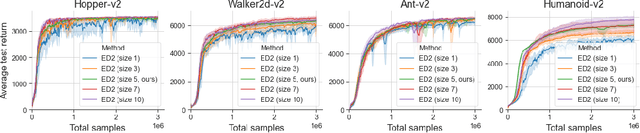

The growth of deep reinforcement learning (RL) has brought multiple exciting tools and methods to the field. This rapid expansion makes it important to understand the interplay between individual elements of the RL toolbox. We approach this task from an empirical perspective by conducting a study in the continuous control setting. We present multiple insights of fundamental nature, including: an average of multiple actors trained from the same data boosts performance; the existing methods are unstable across training runs, epochs of training, and evaluation runs; a commonly used additive action noise is not required for effective training; a strategy based on posterior sampling explores better than the approximated UCB combined with the weighted Bellman backup; the weighted Bellman backup alone cannot replace the clipped double Q-Learning; the critics' initialization plays the major role in ensemble-based actor-critic exploration. As a conclusion, we show how existing tools can be brought together in a novel way, giving rise to the Ensemble Deep Deterministic Policy Gradients (ED2) method, to yield state-of-the-art results on continuous control tasks from OpenAI Gym MuJoCo. From the practical side, ED2 is conceptually straightforward, easy to code, and does not require knowledge outside of the existing RL toolbox.
Implicitly Regularized RL with Implicit Q-Values
Aug 16, 2021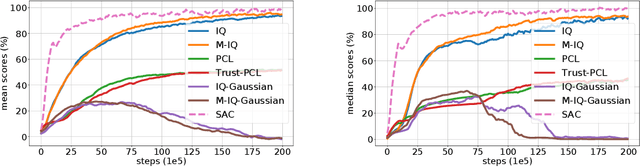
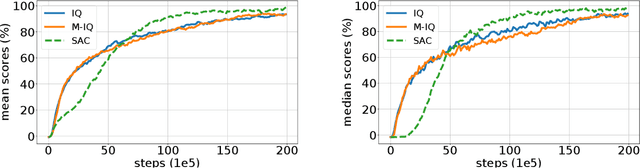

The $Q$-function is a central quantity in many Reinforcement Learning (RL) algorithms for which RL agents behave following a (soft)-greedy policy w.r.t. to $Q$. It is a powerful tool that allows action selection without a model of the environment and even without explicitly modeling the policy. Yet, this scheme can only be used in discrete action tasks, with small numbers of actions, as the softmax cannot be computed exactly otherwise. Especially the usage of function approximation, to deal with continuous action spaces in modern actor-critic architectures, intrinsically prevents the exact computation of a softmax. We propose to alleviate this issue by parametrizing the $Q$-function implicitly, as the sum of a log-policy and of a value function. We use the resulting parametrization to derive a practical off-policy deep RL algorithm, suitable for large action spaces, and that enforces the softmax relation between the policy and the $Q$-value. We provide a theoretical analysis of our algorithm: from an Approximate Dynamic Programming perspective, we show its equivalence to a regularized version of value iteration, accounting for both entropy and Kullback-Leibler regularization, and that enjoys beneficial error propagation results. We then evaluate our algorithm on classic control tasks, where its results compete with state-of-the-art methods.
What Matters for Adversarial Imitation Learning?
Jun 01, 2021


Adversarial imitation learning has become a popular framework for imitation in continuous control. Over the years, several variations of its components were proposed to enhance the performance of the learned policies as well as the sample complexity of the algorithm. In practice, these choices are rarely tested all together in rigorous empirical studies. It is therefore difficult to discuss and understand what choices, among the high-level algorithmic options as well as low-level implementation details, matter. To tackle this issue, we implement more than 50 of these choices in a generic adversarial imitation learning framework and investigate their impacts in a large-scale study (>500k trained agents) with both synthetic and human-generated demonstrations. While many of our findings confirm common practices, some of them are surprising or even contradict prior work. In particular, our results suggest that artificial demonstrations are not a good proxy for human data and that the very common practice of evaluating imitation algorithms only with synthetic demonstrations may lead to algorithms which perform poorly in the more realistic scenarios with human demonstrations.
Hyperparameter Selection for Imitation Learning
May 25, 2021
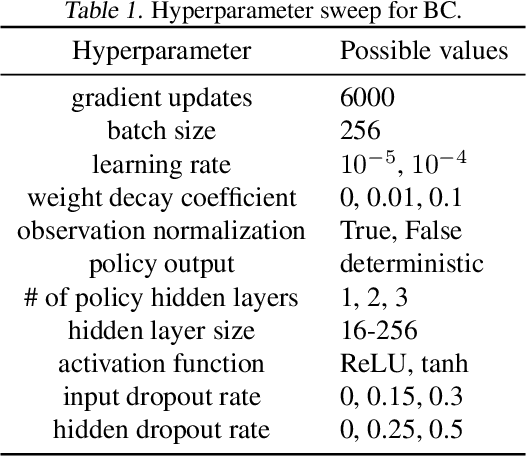
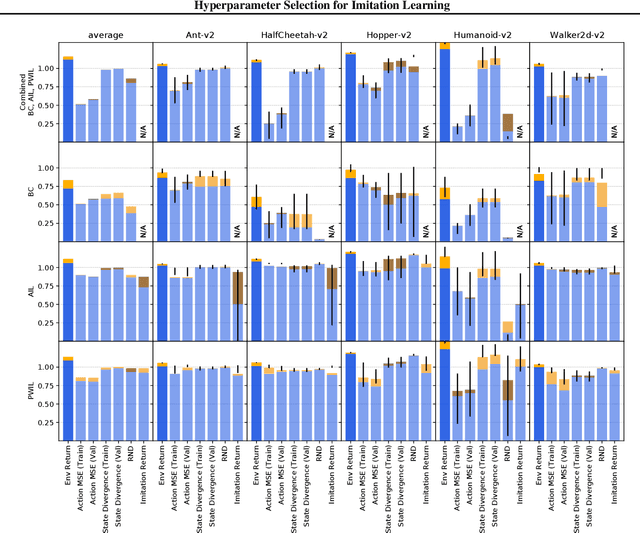
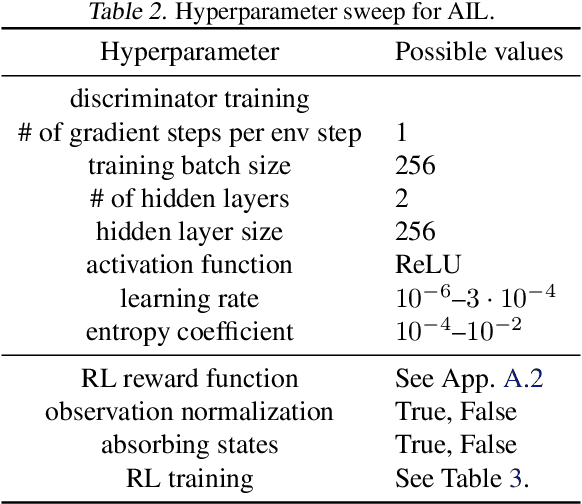
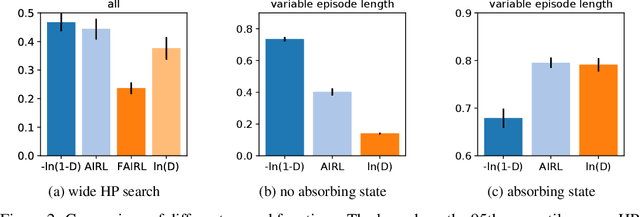
We address the issue of tuning hyperparameters (HPs) for imitation learning algorithms in the context of continuous-control, when the underlying reward function of the demonstrating expert cannot be observed at any time. The vast literature in imitation learning mostly considers this reward function to be available for HP selection, but this is not a realistic setting. Indeed, would this reward function be available, it could then directly be used for policy training and imitation would not be necessary. To tackle this mostly ignored problem, we propose a number of possible proxies to the external reward. We evaluate them in an extensive empirical study (more than 10'000 agents across 9 environments) and make practical recommendations for selecting HPs. Our results show that while imitation learning algorithms are sensitive to HP choices, it is often possible to select good enough HPs through a proxy to the reward function.
What Matters In On-Policy Reinforcement Learning? A Large-Scale Empirical Study
Jun 10, 2020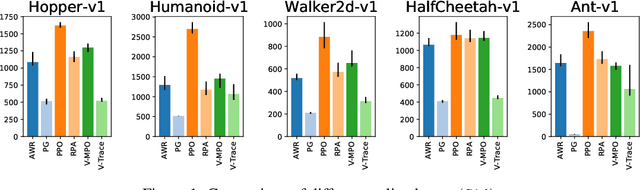

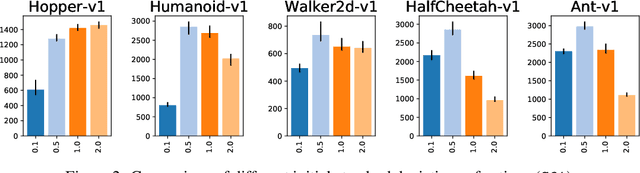

In recent years, on-policy reinforcement learning (RL) has been successfully applied to many different continuous control tasks. While RL algorithms are often conceptually simple, their state-of-the-art implementations take numerous low- and high-level design decisions that strongly affect the performance of the resulting agents. Those choices are usually not extensively discussed in the literature, leading to discrepancy between published descriptions of algorithms and their implementations. This makes it hard to attribute progress in RL and slows down overall progress [Engstrom'20]. As a step towards filling that gap, we implement >50 such ``choices'' in a unified on-policy RL framework, allowing us to investigate their impact in a large-scale empirical study. We train over 250'000 agents in five continuous control environments of different complexity and provide insights and practical recommendations for on-policy training of RL agents.
Solving Rubik's Cube with a Robot Hand
Oct 16, 2019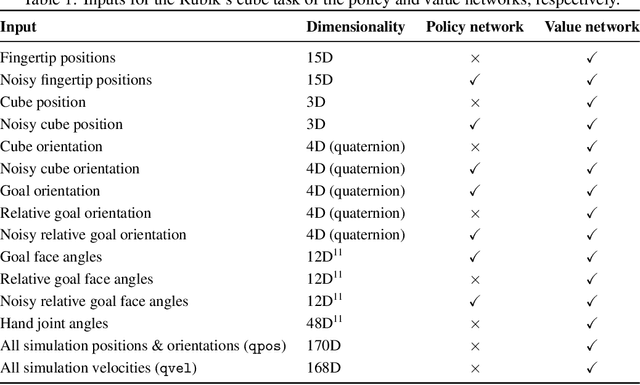
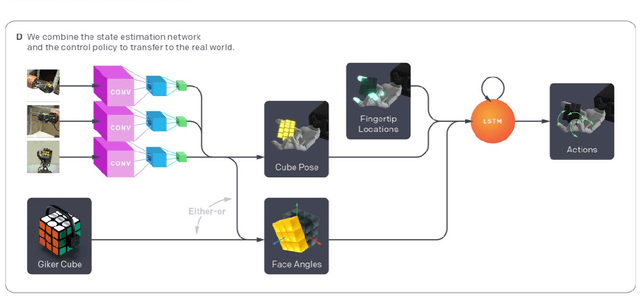
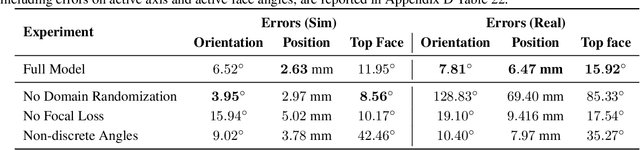

We demonstrate that models trained only in simulation can be used to solve a manipulation problem of unprecedented complexity on a real robot. This is made possible by two key components: a novel algorithm, which we call automatic domain randomization (ADR) and a robot platform built for machine learning. ADR automatically generates a distribution over randomized environments of ever-increasing difficulty. Control policies and vision state estimators trained with ADR exhibit vastly improved sim2real transfer. For control policies, memory-augmented models trained on an ADR-generated distribution of environments show clear signs of emergent meta-learning at test time. The combination of ADR with our custom robot platform allows us to solve a Rubik's cube with a humanoid robot hand, which involves both control and state estimation problems. Videos summarizing our results are available: https://openai.com/blog/solving-rubiks-cube/
Learning Dexterous In-Hand Manipulation
Jan 18, 2019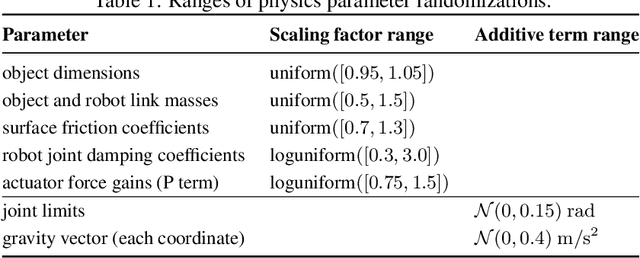
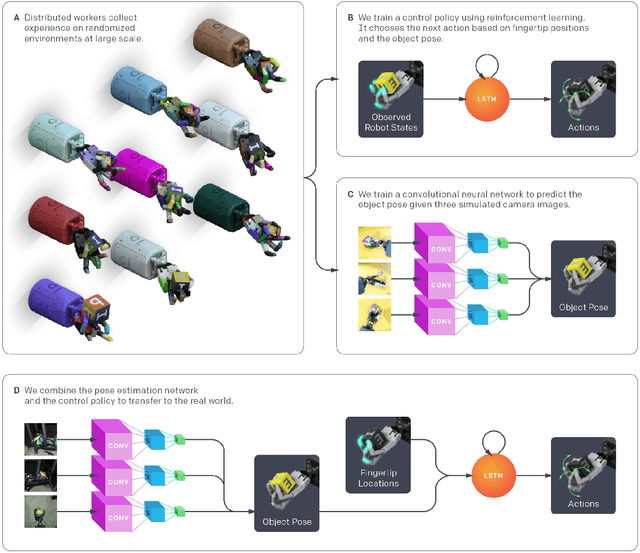
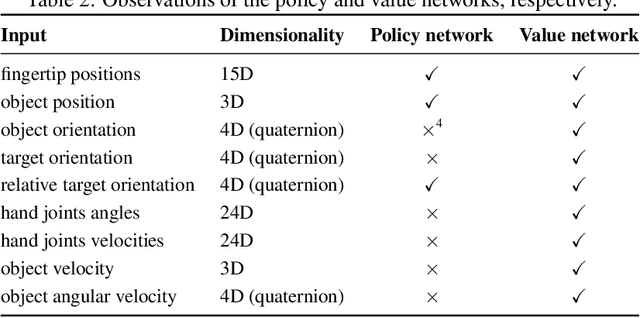

We use reinforcement learning (RL) to learn dexterous in-hand manipulation policies which can perform vision-based object reorientation on a physical Shadow Dexterous Hand. The training is performed in a simulated environment in which we randomize many of the physical properties of the system like friction coefficients and an object's appearance. Our policies transfer to the physical robot despite being trained entirely in simulation. Our method does not rely on any human demonstrations, but many behaviors found in human manipulation emerge naturally, including finger gaiting, multi-finger coordination, and the controlled use of gravity. Our results were obtained using the same distributed RL system that was used to train OpenAI Five. We also include a video of our results: https://youtu.be/jwSbzNHGflM
Domain Randomization and Generative Models for Robotic Grasping
Apr 03, 2018
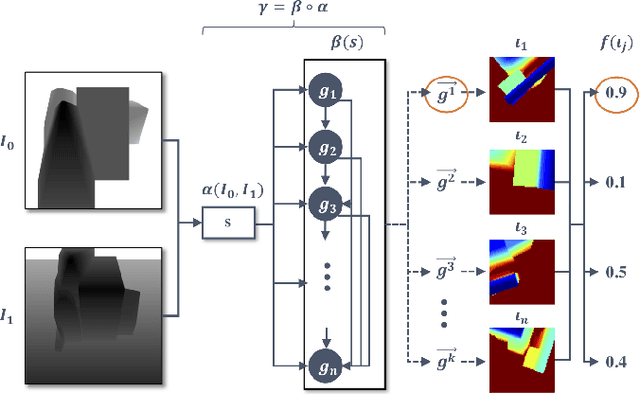
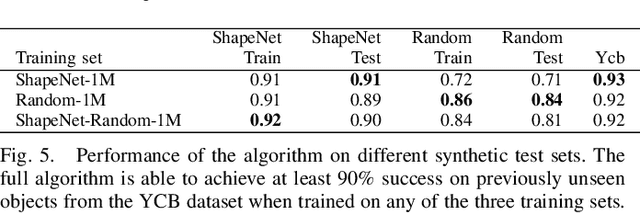
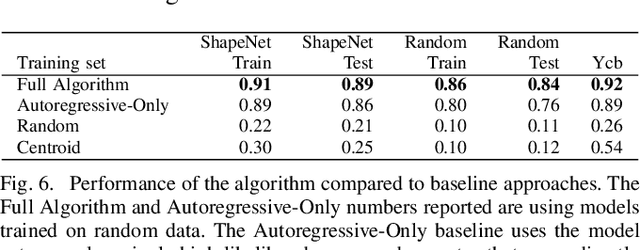
Deep learning-based robotic grasping has made significant progress thanks to algorithmic improvements and increased data availability. However, state-of-the-art models are often trained on as few as hundreds or thousands of unique object instances, and as a result generalization can be a challenge. In this work, we explore a novel data generation pipeline for training a deep neural network to perform grasp planning that applies the idea of domain randomization to object synthesis. We generate millions of unique, unrealistic procedurally generated objects, and train a deep neural network to perform grasp planning on these objects. Since the distribution of successful grasps for a given object can be highly multimodal, we propose an autoregressive grasp planning model that maps sensor inputs of a scene to a probability distribution over possible grasps. This model allows us to sample grasps efficiently at test time (or avoid sampling entirely). We evaluate our model architecture and data generation pipeline in simulation and the real world. We find we can achieve a $>$90% success rate on previously unseen realistic objects at test time in simulation despite having only been trained on random objects. We also demonstrate an 80% success rate on real-world grasp attempts despite having only been trained on random simulated objects.
Multi-Goal Reinforcement Learning: Challenging Robotics Environments and Request for Research
Mar 10, 2018

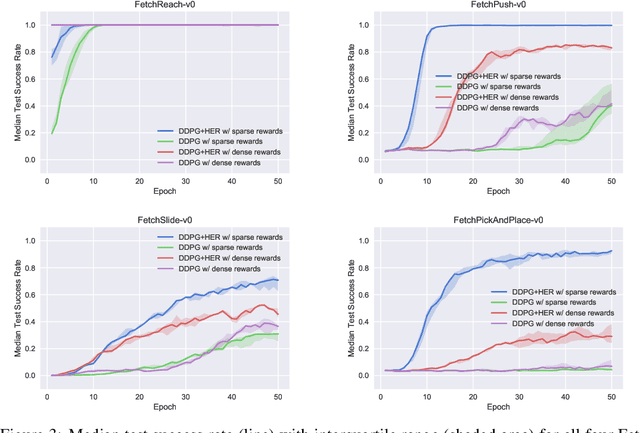
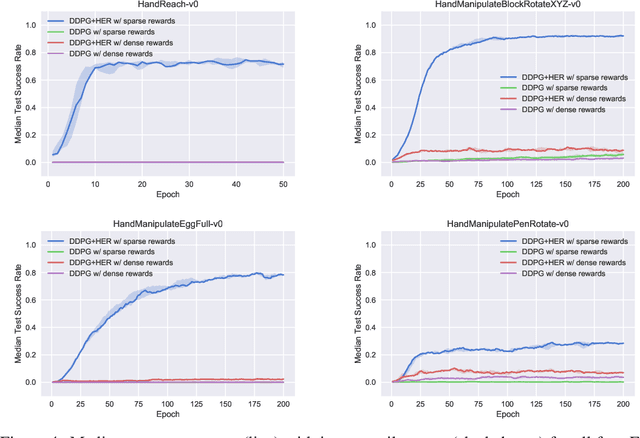
The purpose of this technical report is two-fold. First of all, it introduces a suite of challenging continuous control tasks (integrated with OpenAI Gym) based on currently existing robotics hardware. The tasks include pushing, sliding and pick & place with a Fetch robotic arm as well as in-hand object manipulation with a Shadow Dexterous Hand. All tasks have sparse binary rewards and follow a Multi-Goal Reinforcement Learning (RL) framework in which an agent is told what to do using an additional input. The second part of the paper presents a set of concrete research ideas for improving RL algorithms, most of which are related to Multi-Goal RL and Hindsight Experience Replay.